







参考博客
(4条消息) 堆排序_guanlovean的博客-CSDN博客_堆排序![]() https://blog.csdn.net/qq_28063811/article/details/93034625
https://blog.csdn.net/qq_28063811/article/details/93034625
1、首先了解堆是什么
堆是一种数据结构,一种叫做完全二叉树的数据结构。
2、堆的性质
这里我们用到两种堆,其实也算是一种。
大顶堆:每个节点的值都大于或者等于它的左右子节点的值。
小顶堆:每个节点的值都小于或者等于它的左右子节点的值。


根据大顶堆的性质,每个节点的值都大于或者等于它的左右子节点的值。所以我们需要找到所有包含子节点的节点,也就是非叶子节点,然后调整他们的父子关系,非叶子节点遍历的顺序应该是从下往上,这比从上往下的顺序遍历次数少很多,因为,大顶堆的性质要求父节点的值要大于或者等于子节点的值,如果从上往下遍历,当某个节点即是父节点又是子节点并且它的子节点仍然有子节点的时候,因为子节点还没有遍历到,所以子节点不符合大顶堆性质,当子节点调整后,必然会影响其父节点需要二次调整。但是从下往上的方式不需要考虑父节点,因为当前节点调整完之后,当前节点必然比它的所有子节点都大,所以,只会影响到子节点二次调整。相比之下,从下往上的遍历方式比从上往下的方式少了父节点的二次调整。
那么,该如何知道最后一个非叶子节点的位置,也就是索引值?
对于一个完全二叉树,在填满的情况下(非叶子节点都有两个子节点),每一层的元素个数是上一层的二倍,根节点数量是1,所以最后一层的节点数量,一定是之前所有层节点总数+1,所以,我们能找到最后一层的第一个节点的索引,即节点总数/2(因为我们根节点索引记为0),
最后一层节点数量用M表示,最后一层节点之前所有层节点的数量用MQ表示,则
MQ+1=M(画二叉树自己数一数关系即可得到)
所以总结点数除以2,即是最后一层的第一个节点的索引,即节点总数/2(因为我们根节点索引记为0),这也就是第一个叶子节点,所以第一个非叶子节点的索引就是第一个叶子结点的索引-1。那么对于填不满的二叉树呢?这个计算方式仍然适用,当我们从上往下,从左往右填充二叉树的过程中,第一个叶子节点,一定是序列长度/2,所以第一个非叶子节点的索引就是arr.length / 2 -1。
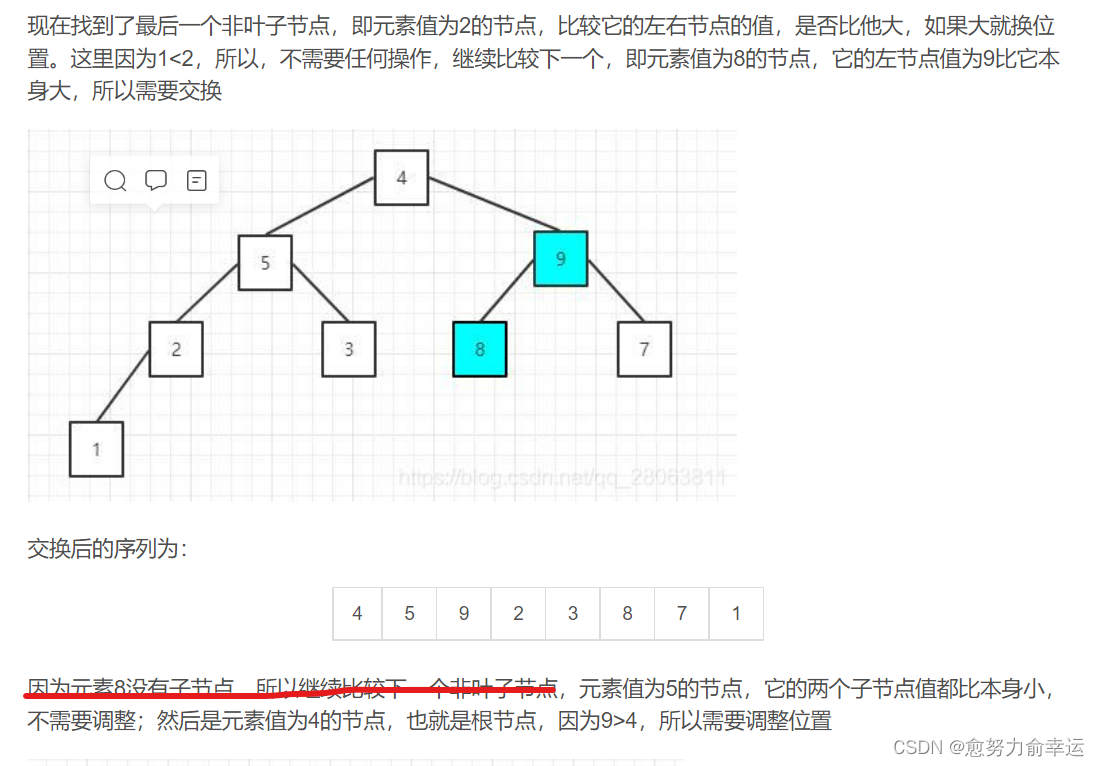
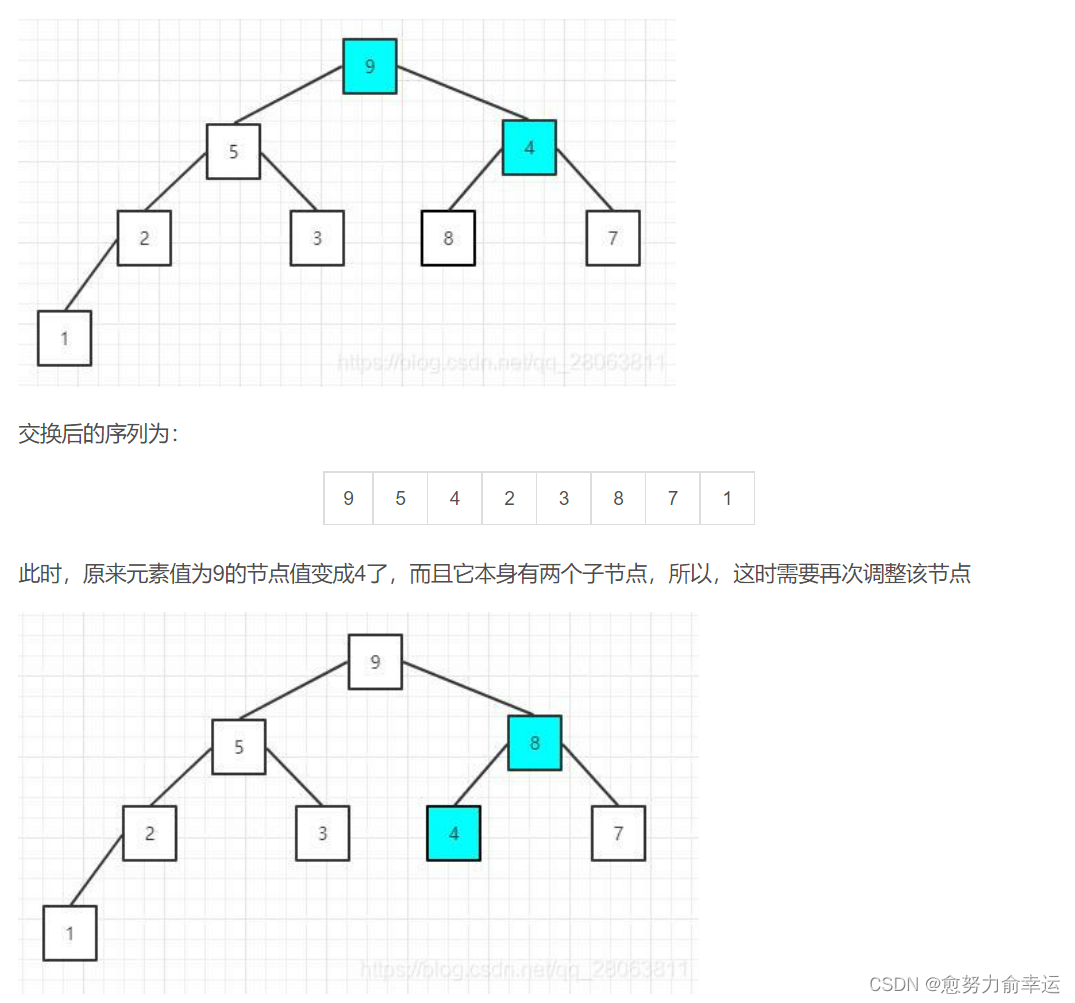


博主觉得比较重要的已写,剩下的可以去上边博客里看
def heapify(arr,i,len):
#这段代码用来保证每个节点的值都大于等于它的左右节点的值
largest = i#默认当前节点是最大的
left = 2*i + 1
right = 2*i + 2
if left < len and arr[i] < arr[left]:
#如果有左节点且左节点的值更大更新索引
largest = left
if right < len and arr[largest] < arr[right]:
#如果有右节点且右节点的值更大更新索引
largest = right
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i] # 交换
#因为互换之后,子节点的值变了,如果该子节点也有自己的子节点,仍需要再次调整。
heapify(arr,largest,len)
def heapSort(arr):
lenn= len(arr)
#构建一个大顶堆
#从最后一个非叶节点开始向前遍历,调整节点性质,使之成为大顶堆
for i in range(lenn//2-1, -1, -1):
heapify(arr,i,lenn)
#交换堆顶和当前末尾的节点,重置大顶堆
for i in range(lenn-1, 0, -1):
arr[i], arr[0] = arr[0], arr[i] # 交换
#将剩余的元素重新构建大顶堆,
#其实就是调整根节点以及其调整后影响的子节点,
# 因为其他节点之前已经满足大顶堆性质。
heapify(arr,0,i)
arr = [12, 11, 13, 5, 6, 7]
heapSort(arr)
n = len(arr)
print("排序后")
for i in range(n):
print("%d" % arr[i]),














 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









