






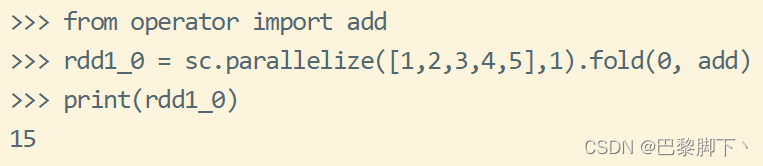
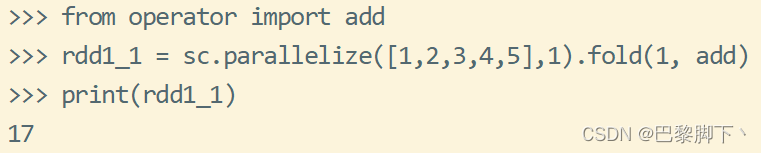
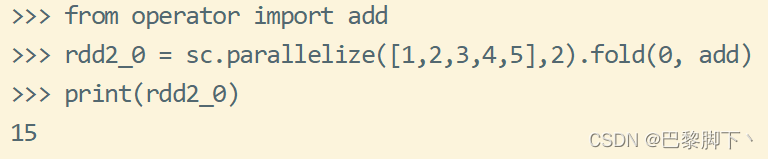

以上几个rdd中的分区数分别为1、1、2、2,相应的fold()函数给出的初始值为0、1、0、1,用到的add是求和函数;
可以这样理解,fold()函数是对rdd的数据分别求和,fold的中文意思为折叠,那么就是先将各个分区的数据折叠(求和),最后分区分别折叠完成后,再整体折叠一下,对应的总结一个公式就是《(分区数+1)×初始值+各元素数据的求和值》。
运用这个自己总结的公式可以再试一次,如下所示:

分区数为20,初始值为3,各元素的和为1+2+3+4+5=15
通过公式理解就是《(20+1)×3+15》,结果为78。
希望可以帮助大家理解!















 181
181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









