







原理
静态散列要求桶的数目始终固定,那么在确定桶数目和选择散列函数时,如果桶数目过小,随着数据量增加,性能会降低;如果留一定余量,又会带来空间的浪费;或者定期重组散列索引结构,但这是一项开销大且耗时的工作。为了应对这些问题,为此提出了几种动态散列(dynamic
hashing)技术,可扩展动态散列(extendable hashing)便是其一。
一、可扩展动态散列
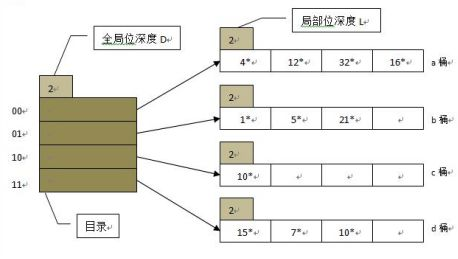
A)用一个数组来存储桶指针的目录,数组的位数为2的D次方,桶的容量为2的L次方,D和L分别称为全局位深度和局部位深度。每次发生桶溢出时,溢出桶分裂,容量变为2的L+1次方,其它桶的容量保持不变,同时数据目录的深度变为D+1。扩展容量时,只是调整了局部的桶容量和目录的容量,性能开销比较小。
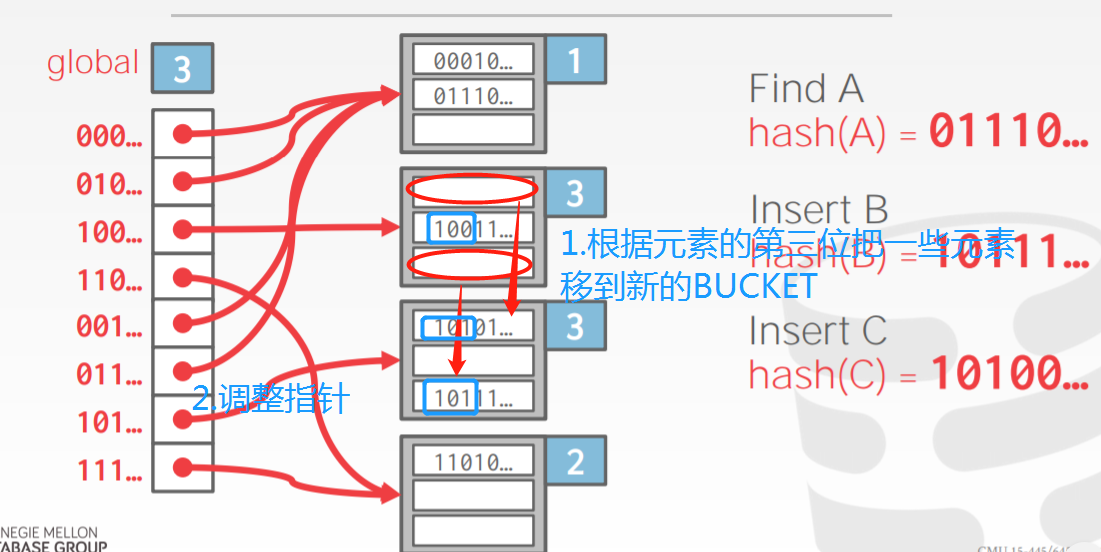
上图中,目录深度为2,目录项有4个。然后开始插入数据d1和d2,假定h(d1)=13、h(d2)=20,由于13=1101,且全局位深度为2,则根据后两位01确定应插入b桶,b桶有空间,可直接插入。20=10100,应插入a桶,但a桶以及满了,于是开始分裂,a桶的局部位深度变为3,容量扩展为8,如果扩展后的局部位深度超过了全局位深度,则全局位深度等于这个最大的局部位深度,于是全局位深度也随之变为3。
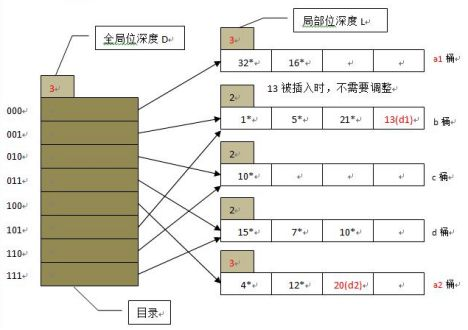
如上图所示,a桶分裂为a1、a2,目录变为三位,对原来a桶中的元素进行重组,由于目录位多了一位,要根据000、100来分别存储到a1、a2桶。虽然目录发生了翻倍,但未进行分裂的桶的局部深度仍然为2,所以会有多个目录项指向这些桶,比如001、101的后两位都是01,都指向b桶。
B)对于查找操作,根据当前的全局位深度,通过目录直接定位到桶地址,随后在桶内部逐一查找。
C)对于删除操作,与查找操作类似,删除元素后,如果发现桶变为空,可与其兄弟桶进行合并,并使局部位深度减一。如果所有的局部位深度都小于全局位深度,则目录数组也进行收缩。
二、静态散列与动态散列对比
与静态散列相比,动态散列的主要优势在于其性能不会随着记录数增长而下降,另外还具有最小的空间占用。缺点在于它会额外增加一次查询定位,因为在查询bucket本身前,需要先查找目录来定位bucket。
另一种动态散列技术-线性散列(linear hashing)可以避免额外的查询定位,但可能这种方式需要更多的溢出桶,日后学习。
三、顺序索引与散列的适用场景
每种索引结构都有其优缺点。如果是select * from a where b=c这样的定值查询,散列比顺序索引跟适合,顺序索引会随着记录数的增加而性能降低,散列则相对稳定。而对于where b>c and b
例子
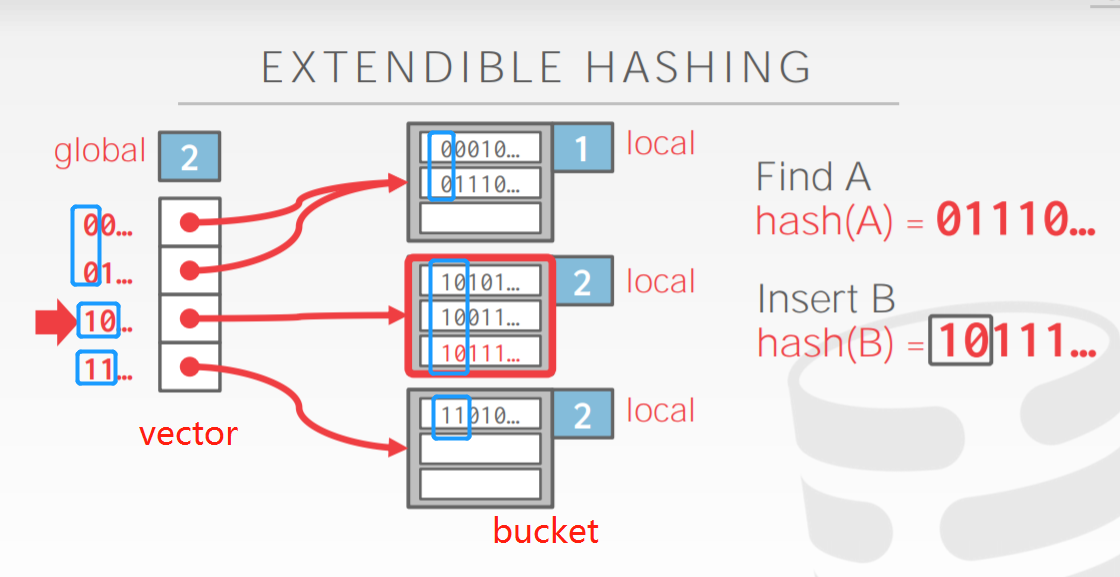

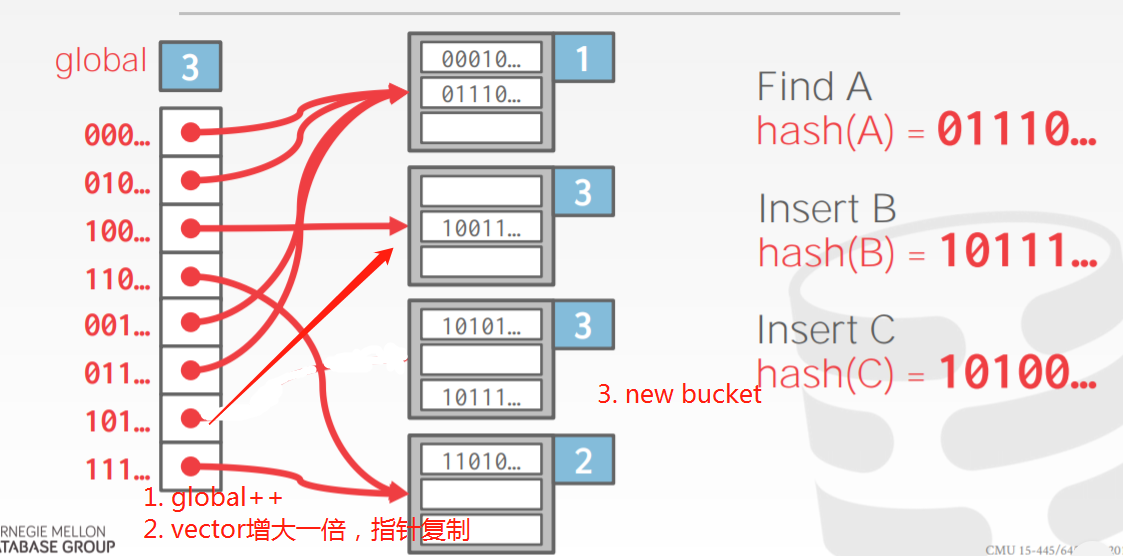
这个扩容可能一次还解决不了问题。比如BUCKET SIZE是2.
有一个BUCKET里有 00110,00100(local depth 是2),你要插入的是00101
先扩容一次,LOCAL DEPTH 变为3了,但是3个元素的头3位都是001,所以还是挤在一起了。所以要用WHILE 循环。
直到有足够的空间可以放了为止。
实现
抽象类
template <typename K, typename V> class HashTable {
public:
HashTable()a {}
virtual ~HashTable() {}
// lookup and modifier
virtual bool Find(const K &key, V &value) = 0;
virtual bool Remove(const K &key) = 0;
virtual void Insert(const K &key,const V &value) = 0;
};
头文件
template <typename K, typename V>
class ExtendibleHash : public HashTable<K, V> {
struct Bucket {
explicit Bucket(int depth):localDepth(depth) {};
int localDepth;
std::map<K, V> items;
};
public:
// constructor
ExtendibleHash(size_t size);
// helper function to generate hash addressing
size_t HashKey(const K &key) const;
// helper function to get global & local depth
int GetGlobalDepth() const;
int GetLocalDepth(int bucket_id) const;
int GetNumBuckets() const;
// lookup and modifier
bool Find(const K &key, V &value) override;
bool Remove(const K &key) override;
void Insert(const K &key, const V &value) override;
private:
// add your own member variables here
int getBucketIndex(const K &key) const;
int globalDepth;
size_t bucketMaxSize;
int numBuckets;
std::vector<std::shared_ptr<Bucket>> bucketTable;
std::mutex mutex;
};
template <typename K, typename V>
class ExtendibleHash : public HashTable<K, V> {
struct Bucket {
explicit Bucket(int depth):localDepth(depth) {};
int localDepth;
std::map<K, V> items;
};
public:
// constructor
ExtendibleHash(size_t size);
// helper function to generate hash addressing
size_t HashKey(const K &key) const;
// helper function to get global & local depth
int GetGlobalDepth() const;
int GetLocalDepth(int bucket_id) const;
int GetNumBuckets() const;
// lookup and modifier
bool Find(const K &key, V &value) override;
bool Remove(const K &key) override;
void Insert(const K &key, const V &value) override;
private:
// add your own member variables here
int getBucketIndex(const K &key) const;
int globalDepth;
size_t bucketMaxSize;
int numBuckets;
std::vector<std::shared_ptr<Bucket>> bucketTable;
std::mutex mutex;
};
具体实现
/*
* constructor
* array_size: fixed array size for each bucket
*/
template <typename K, typename V>
ExtendibleHash<K, V>::ExtendibleHash(size_t size)
:globalDepth(0), bucketMaxSize(size), numBuckets(1) {
bucketTable.push_back(std::make_shared<Bucket>(0));
}
/*
* helper function to calculate the hashing address of input key
*/
template <typename K, typename V>
size_t ExtendibleHash<K, V>::HashKey(const K &key) const {
return std::hash<K>{}(key);
}
/*
* helper function to return global depth of hash table
* NOTE: you must implement this function in order to pass test
*/
template <typename K, typename V>
int ExtendibleHash<K, V>::GetGlobalDepth() const {
return globalDepth;
}
/*
* helper function to return local depth of one specific bucket
* NOTE: you must implement this function in order to pass test
*/
template <typename K, typename V>
int ExtendibleHash<K, V>::GetLocalDepth(int bucket_id) const {
if (!bucketTable[bucket_id] || bucketTable[bucket_id]->items.empty()) return -1;
return bucketTable[bucket_id]->localDepth;
}
/*
* helper function to return current number of bucket in hash table
*/
template <typename K, typename V>
int ExtendibleHash<K, V>::GetNumBuckets() const {
return numBuckets;
}
/*
* lookup function to find value associate with input key
*/
template <typename K, typename V>
bool ExtendibleHash<K, V>::Find(const K &key, V &value) {
//https://en.cppreference.com/w/cpp/thread/mutex
std::lock_guard<std::mutex> guard(mutex);
auto index = getBucketIndex(key);
std::shared_ptr<Bucket> bucket = bucketTable[index];
if (bucket != nullptr && bucket->items.find(key) != bucket->items.end()) {
value = bucket->items[key];
return true;
}
return false;
}
/*
* delete <key,value> entry in hash table
* Shrink & Combination is not required for this project
*/
template <typename K, typename V>
bool ExtendibleHash<K, V>::Remove(const K &key) {
std::lock_guard<std::mutex> guard(mutex);
auto index = getBucketIndex(key);
std::shared_ptr<Bucket> bucket = bucketTable[index];
if (bucket == nullptr || bucket->items.find(key) == bucket->items.end()) {
return false;
}
bucket->items.erase(key);
return true;
}
template <typename K, typename V>
int ExtendibleHash<K, V>::getBucketIndex(const K &key) const {
return HashKey(key) & ((1 << globalDepth) - 1);
}
/*
* insert <key,value> entry in hash table
* Split & Redistribute bucket when there is overflow and if necessary increase
* global depth
*/
template <typename K, typename V>
void ExtendibleHash<K, V>::Insert(const K &key, const V &value) {
std::lock_guard<std::mutex> guard(mutex);
auto index = getBucketIndex(key);
std::shared_ptr<Bucket> targetBucket = bucketTable[index];
while (targetBucket->items.size() == bucketMaxSize) {
if (targetBucket->localDepth == globalDepth) {
size_t length = bucketTable.size();
for (size_t i = 0; i < length; i++) {
bucketTable.push_back(bucketTable[i]);
}
globalDepth++;
}
int mask = 1 << targetBucket->localDepth;
numBuckets++;
auto zeroBucket = std::make_shared<Bucket>(targetBucket->localDepth + 1);
auto oneBucket = std::make_shared<Bucket>(targetBucket->localDepth + 1);
for (auto item : targetBucket->items) {
size_t hashkey = HashKey(item.first);
if (hashkey & mask) {
oneBucket->items.insert(item);
} else {
zeroBucket->items.insert(item);
}
}
for (size_t i = 0; i < bucketTable.size(); i++) {
if (bucketTable[i] == targetBucket) {
if (i & mask) {
bucketTable[i] = oneBucket;
} else {
bucketTable[i] = zeroBucket;
}
}
}
index = getBucketIndex(key);
targetBucket = bucketTable[index];
} //end while
targetBucket->items[key] = value;
}
这里只给出桶溢出时的原理和实现,另外桶缩减到一定程度时也要合并,需要考虑这种情况
参考链接:https://www.jianshu.com/p/2d816f41966c

















 1990
1990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









