






Conv1d
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
in_channels(int) – 输入信号的通道。在文本分类中,即为词向量的维度
out_channels(int) – 卷积产生的通道。有多少个out_channels,就需要多少个1维卷积
kernel_size(int or tuple) - 卷积核的尺寸,卷积核的大小为(k,),第二个维度是由in_channels来决定的,所以实际上卷积大小为kernel_size*in_channels
stride(int or tuple, optional) - 卷积步长
padding (int or tuple, optional)- 输入的每一条边补充0的层数
dilation(int or tuple, `optional``) – 卷积核元素之间的间距
groups(int, optional) – 从输入通道到输出通道的阻塞连接数
bias(bool, optional) - 如果bias=True,添加偏置
举个例子:
conv1 = nn.Conv1d(in_channels=256,out_channels=100,kernel_size=2)
input = torch.randn(32,35,256)
batch_size x text_len x embedding_size -> batch_size x embedding_size x text_len
input = input.permute(0,2,1)
out = conv1(input)
print(out.size())
这里32为batch_size,35为句子最大长度,256为词向量
再输入一维卷积的时候,需要将3235256变换为3225635,因为一维卷积是在最后维度上扫的,最后out的大小即为:32100(35-2+1)=3210034
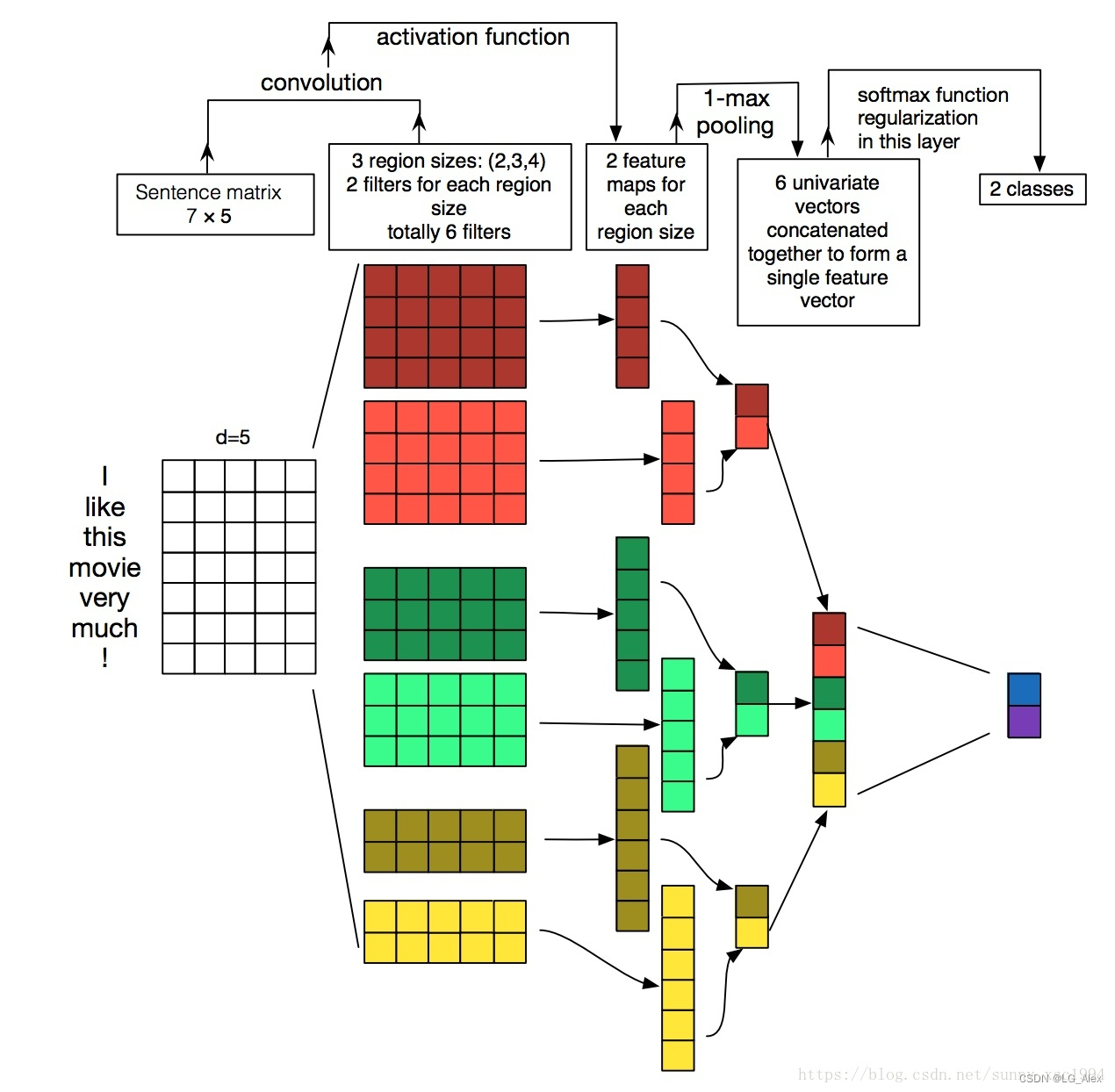
附上一张图,可以很直观的理解一维卷积是如何用的:
图片来源:Keras之文本分类实现
图中输入的词向量维度为5,输入大小为7*5,一维卷积核的大小为2、3、4,每个都有两个,总共6个特征。
对于k=4,见图中红色的大矩阵,卷积核大小为4*5,步长为1。这里是针对输入从上到下扫一遍,输出的向量大小为((7-4)/1+1)1=41,最后经过一个卷积核大小为4的max_pooling,变成1个值。最后获得6个值,进行拼接,在经过一个全连接层,输出2个类别的概率。
附上一个代码来详解:














 7195
7195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









