







'''
单层单向RNN 实现文本分类
文本生成
'''
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
#数据集,电影的评论,被分为positive and
imdb = keras.datasets.imdb
vocab_size = 10000
index_from = 3
#载入数据
(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words = vocab_size,index_from = index_from)
#载入词表
word_index = imdb.get_word_index()
word_index = {k:(v+3) for k, v in word_index.items()}#把所有的id往上偏移 3
#几个特殊字符
word_index['<PAD>'] = 0
word_index['START'] = 1
word_index['UNK'] = 2
word_index['END'] = 3
reverse_word_index = dict([(value, key) for key, value in word_index.items()])
#解码看一下文本是什么:构建词表索引
def decode_review(text_ids):
return ''.join([reverse_word_index.get(word_id,"UNK") for word_id in text_ids])
decode_review(train_data[0])#解码显示句子
#对数据进行补全(padding)
max_length = 500 #句子长度低于500的句子会被补全,高于500 的会被截断
train_data = keras.preprocessing.sequence.pad_sequences(
train_data,#list of list
value = word_index['<PAD>'],
padding = 'post',#post是把padding安在句子的后面,pre是把padding安在句子的前面
maxlen = max_length
)
test_data = keras.preprocessing.sequence.pad_sequences(
test_data,#list of list
value = word_index['<PAD>'],
padding = 'post',#post是把padding安在句子的后面,pre是把padding安在句子的前面
maxlen = max_length
)
#打印第一个样本
print(train_data[0])
#定义模型
embedding_dim = 16#每个word都embedding成长度为16的向量
batch_size = 128
single_rnn_model = keras.models.Sequential([
#1.定义一个矩阵大小为:(vocab_size,embedding_dim)
#2.每个样本的值[1,2,3,4...]都会去查matrix里去查,把1变成1对应的向量、2变成2对应的向量,每个句子都变成了一个max_length * embedding_dim的矩阵
#3.最后的数据是batch_size * max_length * embedding_dim 的三维矩阵
keras.layers.Embedding(vocab_size,embedding_dim,input_length = max_length),#第一层是embedding层
#-----------实现RNN的部分-------------------#
keras.layers.SimpleRNN(units = 64,return_sequences = False),#return_sequence决定返回的是最后一层输出还是所有的输出,False代表只取最后一个输出
#全连接层
keras.layers.Dense(64,activation="relu"),
keras.layers.Dense(1,activation="sigmoid"),
])
single_rnn_model.summary()
single_rnn_model.compile(optimizer = "adam", loss = "binary_crossentropy", metrics = ['accuracy'])
#开始训练,加上batch信息,从训练集里划分出20%作为验证集
history_single_rnn = single_rnn_model.fit(train_data,
train_labels,
epochs = 30,
batch_size = batch_size,
validation_split = 0.2
)
def plot_learning_curves(history,label,epochs,min_value,max_value):
data = {}
data[label] = history.history[label]
data['val_'+label] = history.history['val_'+label]
pd.DataFrame(data).plot(figsize = (8,5))
plt.grid(True)
plt.axis([0,epochs,min_value,max_value])
plt.show()
plot_learning_curves(history_single_rnn, 'accuracy', 30, 0, 1)
plot_learning_curves(history_single_rnn, 'loss', 30, 0, 1)
#在测试集上验证一下
single_rnn_model.evaluate(test_data, test_labels,batch_size = batch_size,)
运行结果:

在测试集上准确度也只有50.8%
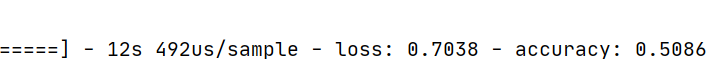
accuracy几乎不变

loss曲线几乎不变

对于二分类问题来说其实是没有分类进展的,说明普通的单层RNN并没有很好的效果。















 1163
1163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









