







 本文介绍了一种使用Webdriver和BeautifulSoup技术,针对指定机构获取2016-2021年专利申请量、授权量、专利家族数及被引频次的方法,包括模拟登录、智能搜索、数据抓取与解析关键信息的过程。
本文介绍了一种使用Webdriver和BeautifulSoup技术,针对指定机构获取2016-2021年专利申请量、授权量、专利家族数及被引频次的方法,包括模拟登录、智能搜索、数据抓取与解析关键信息的过程。
(一)目标
针对一系列机构名,获取2016-2021年间的每年申请专利数目以及总数、专利家族数、专利授权量、专利被引频次。
(二)方法
1、使用Webdriver模拟人工访问浏览器
步骤为:
(1)定义检索情况:
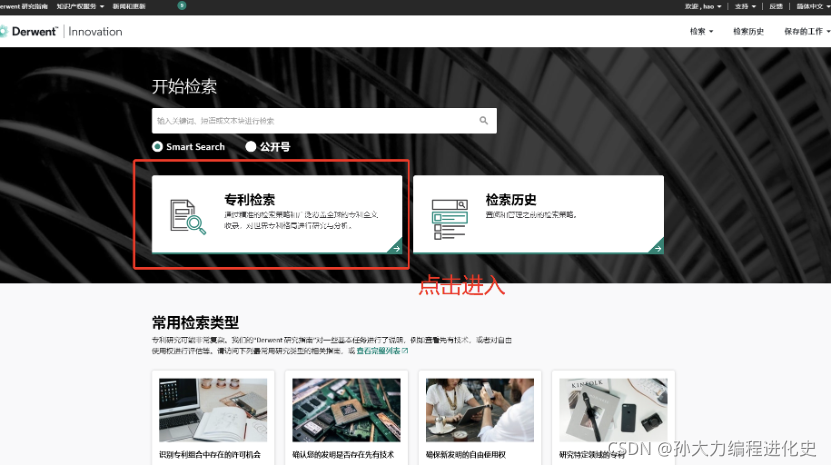
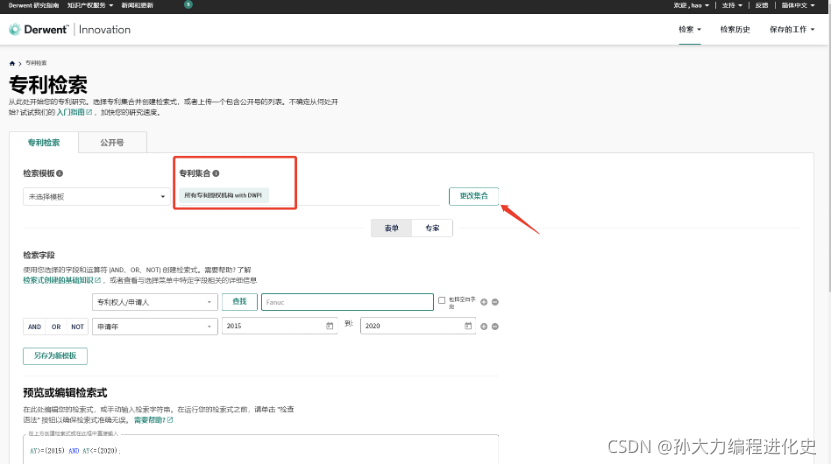
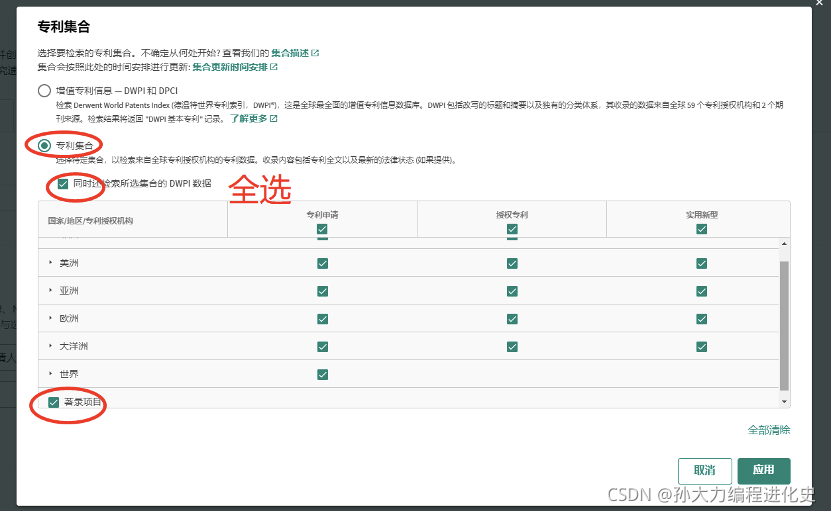

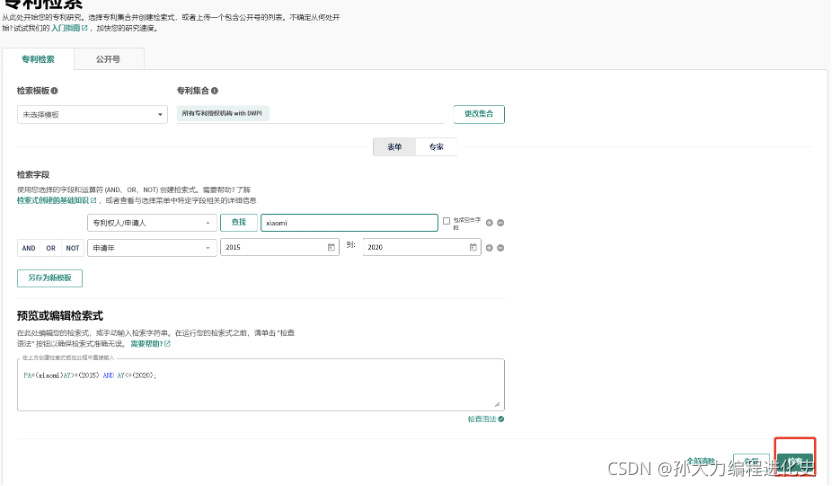
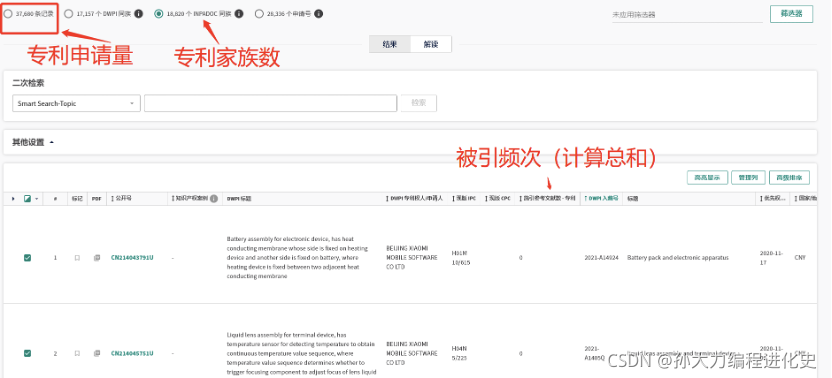
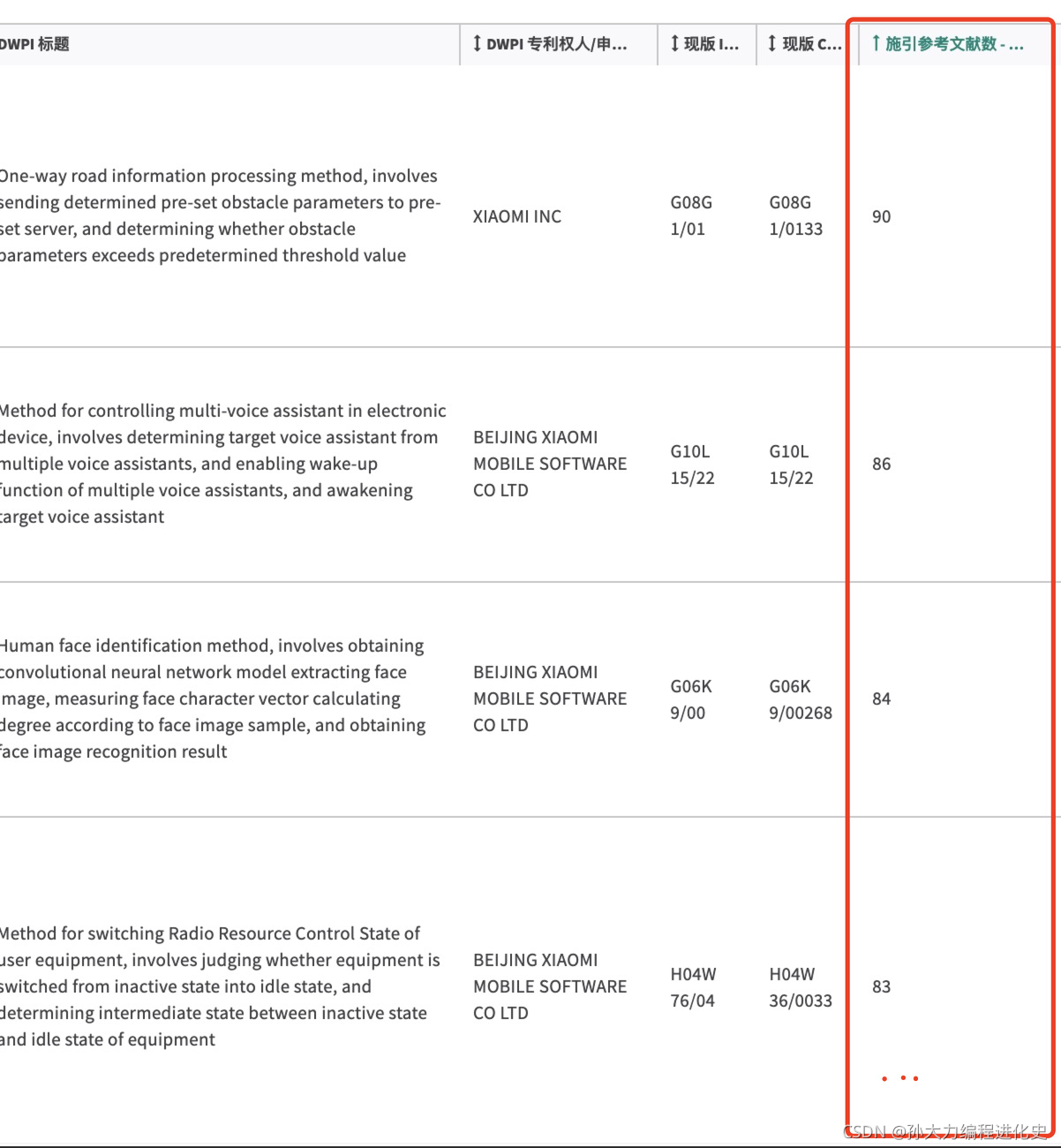
(2)定位、计算总被引量
从检索结果中定位每个专利的被引量,降序排列后加和所有专利的被引量得到总的被引量
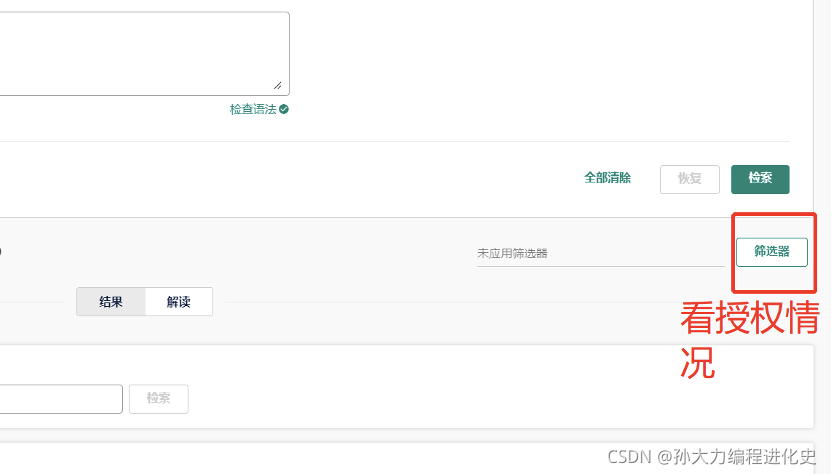
(3)从筛选器中获取每年的申请量:
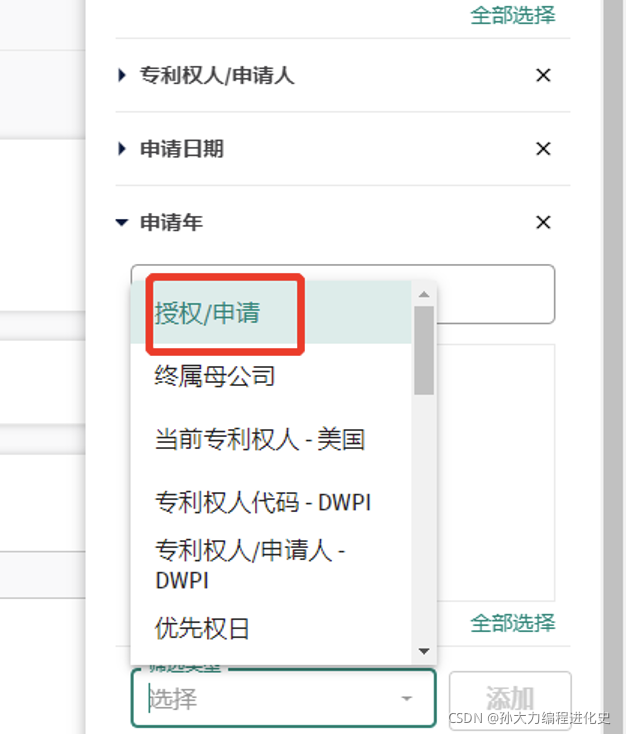
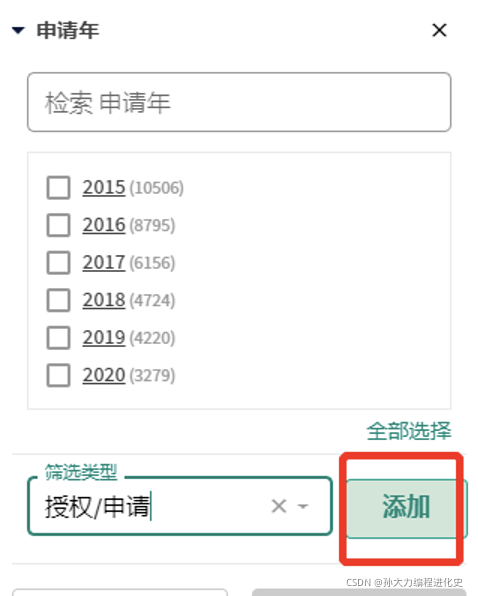
(3)从筛选器中查看授权/申请状况
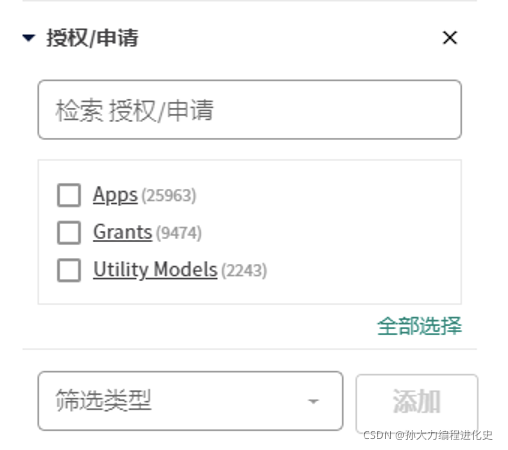
2、BeautifulSoup解析页面
这里,有个坑就是“一定要在点击完页面所有操作的按钮之后再进行解析”,这样会避免后面点击的内容解析不出来的情况。
(三)代码实现
from selenium import webdriver
import time
import json
from pprint import pprint
import requests
import redis
import json
import re
import random
from bs4 import BeautifulSoup
import xlwt
work_book = xlwt.Workbook()
driver = webdriver.Chrome()
driver.get(url='https://derwentinnovation.clarivate.com.cn/login/')
time.sleep(2)
driver.find_element_by_xpath('//*[@id="tr-login-username"]').click()
driver.find_element_by_xpath('//*[@id="tr-login-username"]').clear()
driver.find_element_by_xpath('//*[@id="tr-login-username"]').send_keys('pengh@mail.las.ac.cn')
driver.find_element_by_xpath('//*[@id="tr-login-password"]').click()
driver.find_element_by_xpath('//*[@id="tr-login-password"]').clear()
driver.find_element_by_xpath('//*[@id="tr-login-password"]').send_keys('pengh2018#')
time.sleep(2)
driver.find_element_by_xpath('//*[@id="tr-email-form"]/div/div/div/input').click()
time.sleep(10)
#机构名
lists = [
...
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2866
2866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









