







版权声明:如果对大家有帮助,大家可以自行转载的。原文链接:
监督学习分为:
回归——预测出的标签连续(房价、股票预测);
分类——预测出的标签离散。
线性回归
是一种通过属性的线性组合来进行预测的线性模型,其目的是找到一条直线或者一个平面或者更高维的超平面,使得预测值和真实值之间的误差最小化。
线性回归的符号约定
- m代表训练集中样本的数量
- n代表特征的数量
- x代表特征/输入变量
- y代表目标变量/输出变量
- (x,y)达标训练集中的样本

x和y的关系
h(x) = w0+w1x1+…+wnxn
可以设x0=1,则:
h(x) = w0x0+w1x1+w2x2+…+wnxn = wTx(w0为偏置项)——机器学习中默认向量为列向量
损失函数(loss function)
度量单样本预测的错误程度,损失函数值越小,模型越好。常用的损失函数包括:
0-1损失函数:0-1损失是指预测值和目标值不相等为1, 否则为0:
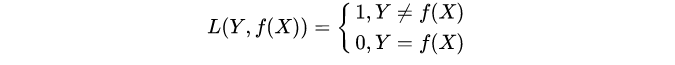
特点:
(1)0-1损失函数直接对应分类判断错误的个数,但是它是一个非凸函数,不太适用.
(2)感知机就是用的这种损失函数。但是相等这个条件太过严格,因此可以放宽条件,即满足 |Y-f(x)|,T时认为相等,
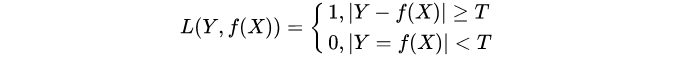
平方损失函数(常用):平方损失函数标准形式如下: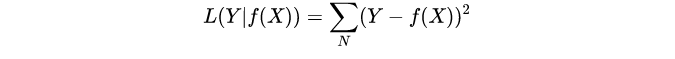
特点:经常应用与回归问题
绝对值损失函数:绝对值损失函数是计算预测值与目标值的差的绝对值: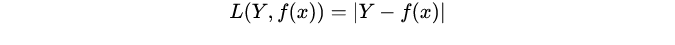
对数损失函数:log对数损失函数的标准形式如下: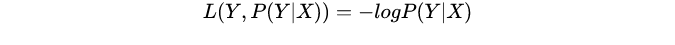
特点:
(1) log对数损失函数能非常好的表征概率分布,在很多场景尤其是多分类,如果需要知道结果属于每个类别的置信度,那它非常适合。
(2)健壮性不强,相比于hinge loss对噪声更敏感。
(3)逻辑回归的损失函数就是log对数损失函数。
指数损失函数:
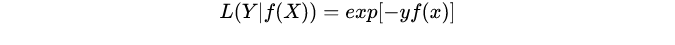
特点:对离群点、噪声非常敏感。经常用在AdaBoost算法中。
Hinge损失函数:

代价函数
度量全部样本集的平均误差。常用的代价函数包括均方误差、均方根误差、平均绝对误差等。
最小二乘法
要找到一组w(w0,w1,w2…wn),使得J(w)的残差平方和最小,即最小化。 (J(w)为代价函数)
J ( w ) = 1 2 m ∑ i = 1 m ( h ( x ( i ) ) − y ( i ) ) 2 J\left( w \right)=\frac{1}{2m}\sum\limits_{i=1}^{m}{
{
{\left( {h}\left( {x^{(i)}} \right)-{y^{(i)}} \right)}^{2}}} J(w)=2m1i=1∑m(h(x(i))−y(i))2
其中: h ( x ) = w T X = w 0 x 0 + w 1 x 1 + w 2 x 2 + . . . + w n x n {h}\left( x \right)={w^{T}}X={w_{0}}{x_{0}}+{w_{1}}{x_{1}}+{w_{2}}{x_{2}}+...+{w_{n}}{x_{n}} h(x)=wTX=w0x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











