







转自https://www.joinquant.com/view/community/detail/2843
kdtree(k dimensional tree)是一个包含空间信息的二叉树数据结构,它是用来计算KNN(K Nearest Neighbours)的非常有用的工具。如果特征的维度是D,样本的数量是N,那么一般讲KD树算法的复杂度是O(DlogN),相比于穷算的O(DN)省去了很多的计算量。
本章将详细介绍KD树的构造以及kdtree上的kNN算法。
一、KD树的结构
kd树是一个二叉树结构,它的每一个节点记载了:特征坐标、切分轴、指向左枝的指针、指向右枝的指针。
其中,1)特征坐标是线性空间Rn中的一个点(x1,x2,...,xn)。
2)切分轴由一个整数r表示,这里1<=r<=n,意思为在n维空间中沿第r维进行一次分割。
3)节点的左枝和右枝分别是KD树,并且满足:如果y是左枝的一个特征坐标,那么yr≤xr;如果z是右枝的一个特征坐标,那么zr≥xr。
给定一个数据样本集S和切分轴r,以下递归将构建一个基于该数据集的kd树,每一次循环制作一个节点:
如果|S|=1,记录集中唯一的一个点为当前节点的特征数据,并且不设左枝和右枝。(|S|表示数据集中的元素的个数)
如果|S|>1:
1)将S中的点按照第r个维度的坐标大小进行排序;
2)选出排列后的中位元素(如果一共有偶数个元素,则选择中位左边或右边的元素,左右并无影响),并把包含此元素的坐标作为当前节点的特征坐标,并且记录切分轴r。
3)将Sl设为在S中所有排在中位元素前面的元素;Sr设为排在中位元素后面的元素。
4)当前节点的左枝设为以 Sl 为数据集并且 r为切分轴制作出的 kd 树;当前节点的右枝设为以 Sr为数据集并且 r 为切分轴制作出的 kd 树。再设 r←(r+1) modn。(这里,我们想轮流沿着每一个维度进行分割;modn 是因为一共有 n个维度,在沿着最后一个维度进行分割之后再重新回到第一个维度。)
二、制造KD树的例子
首先随机在 R2中随机生成 13 个点作为我们的数据集。起始的切分轴 r=0;这里 r=0对应x轴,而r=1 对应 y轴。

首先先沿 x 坐标进行切分,我们选出 x 坐标的中位点,获取最根部节点的坐标:

并且按照该点的x坐标将空间进行切分,所有 x 坐标小于 6.27 的数据用于构建左枝,x坐标大于6.27 的点用于构建右枝。

在下一步中 r=0+1=1 mod2对应 y轴,左右两边再按照 y 轴的排序进行切分,中位点记载于左右枝的节点。得到下面的树,左边的x 是指这该层的节点都是沿 x 轴进行分割的。

空间的切分如下:

下一步中 r≡1+1≡0 mod2,对应 x 轴,所以下面再按照 x 坐标进行排序和切分,有:


最后每一部分都只剩一个点,将他们记在最底部的节点中。因为不再有未被记录的点,所以不再进行切分。


就此完成了 kd 树的构造。
三、KD树上的KNN算法
给定一个构建于一个样本集的 kd 树,下面的算法可以寻找距离某个点p最近的k个样本。
1、设L为一个有k个空位的列表,用于保存已搜寻到的最近点。
2、根据p的坐标和每个节点的切分向下搜索(也即是说,如果树的节点是按xr=a进行切分的,并且p的r坐标小于a,则向左枝进行搜索,反之向右枝)。
3、当达到一个底部节点时,将其标记为访问过。如果L里不足k个点,则将当前节点的特征坐标加入L;如果L不为空并且当前节点的特征与p的距离小于L里面最长的距离,则用当前特征替换掉L中离p最远的特征。
4、如果当前节点不是整棵树最顶端节点,执行(a);反之。输出L,算法完成。
(a)向上爬一个节点。如果当前节点(向上爬之后的)未被访问过,将其标记为访问过,然后执行(1)和(2);如果被访问过,则执行(a)。
(1)如果此时L中不足k个点,则将节点特征放入L中;如果L中已满k个点,且当前节点与p距离小于L中最长的距离,则用当前节点特征替换掉最长距离点。
(2)计算p和当前节点切分线的距离,如果该距离大于等于L中距离p最远的距离并且L中已有k个点,则在切分线另一边不会有更近的点,执行4。如果该距离小于L中最远的距离或者L中不足k个点,则切分线另一边有可能存在更近的点,因此在当前节点的另一个枝从2开始执行。
四、KNN例子
设我们想查询的点为 p=(−1,−5),设距离函数是普通的 L2 距离,我们想找距离问题点最近的 k=3个点。如下:

首先执行2,我们按照切分找到最底部节点。首先,我们在顶部开始:

和这个节点的 x轴比较一下:

p 的 x 轴更小。因此我们向左枝进行搜索:

这次对比 y 轴:

p 的 y 值更小,因此向左枝进行搜索:

这个节点只有一个子枝,就不需要对比了。由此找到了最底部的节点 (−4.6,−10.55):

在二维图上是:

此时我们执行 3。将当前结点标记为访问过,并记录下 L=[(−4.6,−10.55)]。啊,访问过的节点就在二叉树上显示为被划掉的好了。
然后执行 4,嗯,不是最顶端节点。好,执行 (a),我爬。上面的是 (−6.88,−5.4)。


执行 (1),因为我们记录下的点只有一个,小于 k=3,所以也将当前节点记录下,有 L=[(−4.6,−10.55),(−6.88,−5.4)]。再执行 (2),因为当前节点的左枝是空的,所以直接跳过,回到步骤 4。4看了一眼,好,不是顶部,交给你了(a)。于是乎 (a) 又往上爬了一节:


(1) 说,由于还是不够三个点,于是将当前点也记录下,有 L=[(−4.6,−10.55),(−6.88,−5.4),(1.24,−2.86)]。当然,当前结点变为被访问过的。
(2) 又发现,当前节点有其他的分枝,并且经计算得出 p 点和 L 中的三个点的距离分别是 6.62,5.89,3.10,但是 p 和当前节点的分割线的距离只有 2.14,小于与 L 的最大距离:

因此,在分割线的另一端可能有更近的点。于是我们在当前结点的另一个分枝从头执行 2。好,我们在红线这里:

要用 p 和这个节点比较 x 坐标:

p 的 x 坐标更大,因此探索右枝 (1.75,12.26),并且发现右枝已经是最底部节点,因此启动3。

经计算,(1.75,12.26)与 pp 的距离是 17.48,要大于 p 与 L 的距离,因此我们不将其放入记录中。

然后 4判断出不是顶端节点,呼出 (a),爬。

(1) 出来一算,这个节点与 p 的距离是 4.91,要小于 p 与 L 的最大距离 6.62。

因此,我们用这个新的节点替代 L 中离 p 最远的 (−4.6,−10.55)。

然后 (2) 又来了,我们比对 p 和当前节点的分割线的距离,
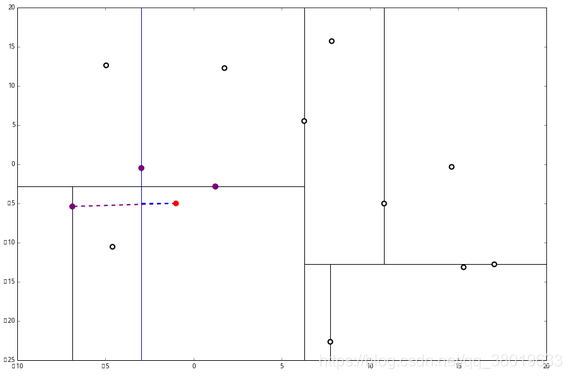
这个距离小于 L 与 p 的最小距离,因此我们要到当前节点的另一个枝执行2。当然,那个枝只有一个点,直接到3。

计算距离发现这个点离 p 比 L 更远,因此不进行替代。

4发现不是顶点,所以呼出 (a)。我们向上爬,

这个是已经访问过的了,所以再来(a)
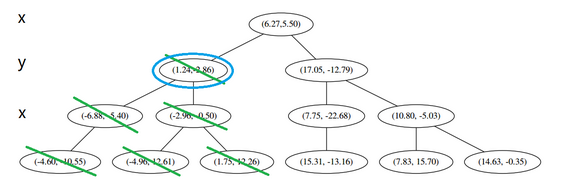
好,(a)再爬,

啊!到顶点了。所以完了吗?当然不,还没轮到4呢。现在是 (1) 的回合。
我们进行计算比对发现顶端节点与p的距离比L还要更远,因此不进行更新。

然后是 (2),计算 p 和分割线的距离发现也是更远。

因此也不需要检查另一个分枝。
然后执行 4,判断当前节点是顶点,因此计算完成!输出距离 p 最近的三个样本是 L=[(−6.88,−5.4),(1.24,−2.86),(−2.96,−2.5)]。














 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









