






等级不够无法自定义标签 VexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlowVexFlow
心血来潮学了点新东西,用了点时间学会初步使用,但是后续需要的专业知识不太懂,这里留个纪念
vexflow, 一个可以灵活编辑五线谱的好东西(除了index.js是我自己新建的,其余js都可以找到)
html
<!DOCTYPE html>
<html>
<head>
<meta charset="ISO-8859-1">
<title>wu</title>
</head>
<script type="text/javascript" src="js/vexflow-min.js"></script>
<script type="text/javascript" src="js/jquery.js"></script>
<script type="text/javascript" src="js/index.js"></script>
<script type="text/javascript" src="js/qunit.js"></script>
<script type="text/javascript" src="js/raphael.js"></script>
<script type="text/javascript" src="js/vexflow-debug.js"></script>
<body>
<div id="boo">
</div>
</body>
</html>
index.js
function demo(){
var div1 = document.getElementById("boo");
var VF = Vex.Flow;
var renderer = new VF.Renderer(div1, VF.Renderer.Backends.SVG);
renderer.resize(500, 500);
var context = renderer.getContext();
var stave = new VF.Stave(10, 40, 400);
stave.addClef("treble").addTimeSignature("4/4");
stave.setContext(context).draw();
var notes = [
new VF.StaveNote({clef: "treble", keys: ["c/4"], duration: "q"}),
new VF.StaveNote({clef: "treble", keys: ["d/4"], duration: "q"}),
new VF.StaveNote({clef: "treble", keys: ["b/4"], duration: "qr"}),
new VF.StaveNote({clef: "treble", keys: ["c/4", "e/4", "g/4"], duration: "q"})
];
var notes2 = [
new VF.StaveNote({clef: "treble", keys: ["c/4"], duration: "w" })
];
var voices = [
new VF.Voice({num_beats: 4, beat_value: 4}).addTickables(notes),
new VF.Voice({num_beats: 4, beat_value: 4}).addTickables(notes2)]
var formatter = new VF.Formatter().joinVoices(voices).format(voices, 400);
// Render voices
voices.forEach(function(v) { v.draw(context, stave); })
}
window.onload = demo;效果
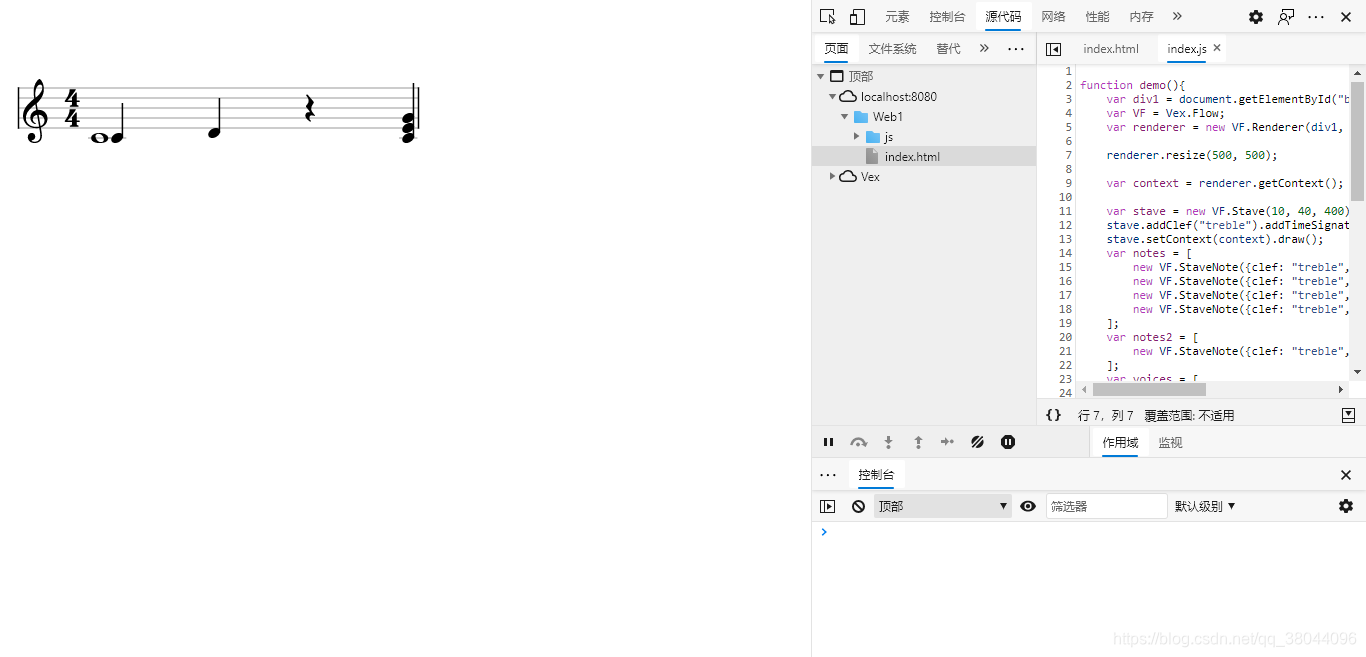

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









