







一、X-BERT:eXtreme Multi-label Text Classification using BERT
本篇论文数据、代码和预训练模型获取地址: [https://github.com/OctoberChang/X-BERT]
Abstract
Extreme multi-label text classification (XMC)超级多标签的文本分类问题,简称XMC,是从一个超级大的标签集中选取与文本最相关的子标签集的问题。在互联网呈井喷式发展的背景下,数据信息爆发式增长下,标签集中的标签数目可以达到几百万个甚至更多。
该篇论文介绍了最近的预训练语言模型如BERT模型所取得的出色的成绩,并提出了把BERT应用到XMC问题上所需面对的挑战:
1.如何提取标签与标签之间的依赖性和相关性,这些特征可能来自不同的方面;
2.
为了解决这些挑战,作者提出了X-BERT,第一个对BERT模型进行微调应用在XMC问题上的可伸缩的解决方案。X-BERT的核心是利用微调的BERT来提取文本与标签聚类群之间的上下文关系。最后,集成在不同标签群上训练的不同BERT模型,形成我们最终的表现最好的模型,并且成为了解决XMC问题的最新的方法。
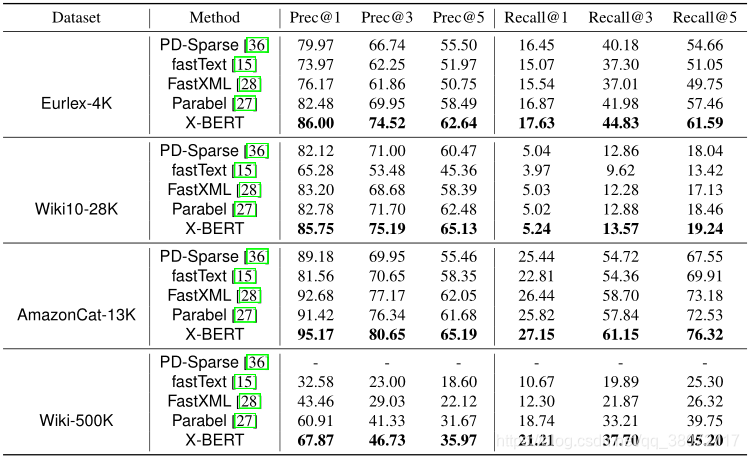
在拥有将近五十万个标签的Wiki数据集上,X-BERT的precision@1达到67.87%,在神经网络基线模型fastText(32.58%)和最新的Parabel方法(60.91%)上取得了巨大的提升。
Introduction
作者概括了本论文所作出的贡献:
- 提出了第一个具有可伸缩性的微调BERT模型X-BERT用于XMC问题。X-BERT包括一个标签语义标序部分、一个深度神经网络的匹配部分和一个集成排序部分。
- List item
- X-BERT取得了最新的结果。
Related Work
介绍了处理XMC问题的历史研究,并将其大致分为四大类:
- One-Vs-All(OVA) approaches
- Partitioning methods
- Embedding-based Approaches
- Deep Learning Approaches
Proposed Algorithm: X-BERT
这篇论文的部分灵感来自于信息检索(IR),
Empirical Results
二、How to Fine-Tune BERT for Text Classification?
本篇论文介绍了














 1859
1859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









