







1.准备
1.1 把之前在192.168.10.51服务器上解压的jdk推到192.168.10.52,192.168.10.53服务器上去。

在hadoop51上执行 xsync model/ 同步脚本命令
``
2.安装
3.配置环境变量
4.安装Hadoop
5.配置环境变量
在192.168.10.51,192.168.10.52,192.168.10.53分别安装hadoop和jdk
6.配置集群
2)hadoop配置文件分为两大类
-
默认配置文件

-
自定义配置文件

只有用户想修改某一默认配置值时,才修改自定义配置文件

7.核心配置文件
7.1)核心配置 core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定HDFS中NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.10.51:8020</value>
</property>
<!-- 指定 hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 root-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
7.2)核心配置 hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>192.168.10.51:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.10.53:9868</value>
</property>
</configuration>
7.3)核心配置 yarn-site.xml
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.10.52</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>
7.4)核心配置 mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

7.5 配置workers
vim /opt/model/hadoop-3.1.1/etc/hadoop/workers
把几个机器都配置进来
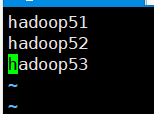
然后进行每台机器进行分发 xsync workers
8.启动集群
8.1)如果集群是第一次启动,需要在 192.168.10.51 节点格式化 NameNode
(注意:格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找
不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停 止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式
化。)
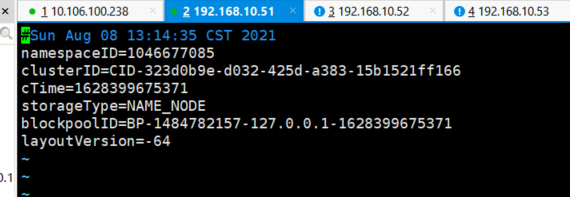
[root@localhost hadoop-3.1.3]# hdfs namenode -format
然后会出现两个文件 data就是在core-site.xml中配置的路径目录

打开data里面有个 cd /opt/model/hadoop-3.1.3/data/dfs/name/current
有个 VERSION文件,显示的是当前服务器的版本号
8.2)启动HDFS(在hadoop51服务器上启动的)
如果里面文件显示是白色的不是这样绿色的表明没有授权
然后给文件授权
chmod -R 777 /opt/model/hadoop-3.1.1/
初始化之后我们正式开始启动集群执行文件目录在/opt/model/hadoop-3.1.1/sbin
./start-dfs.sh #启动集群
启动如果报错显示没权限需要在

在启动的这个.sh文件里面顶上加上这句话
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在重新分发一下xsync start-dfs.sh然后在启动就好啦

启动成功跟我们的集群规划对比
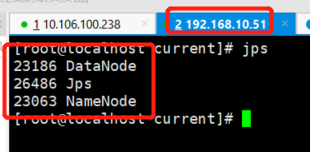
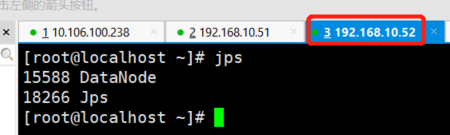
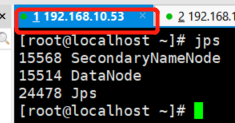
测试HDFS界面化
打开我们配的一个格式化页面 http://192.168.10.51:9870/

这个界面他里面有一些简介什么的

8.3)启动YARN(在hadoop52服务器上启动的)
因为我们配置的YARN实在192.168.10.52服务器上所以启动YARN是在192.168.10.52这台服务器上启动 第一次启动报错

在start-yarn.sh 文件里面加上这句话
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
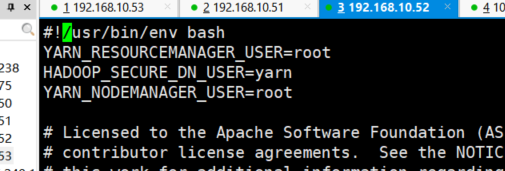
然后再次启动

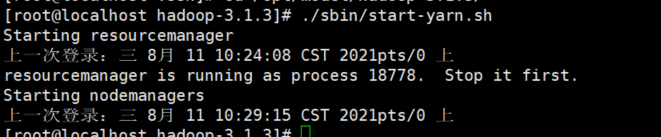
现在出这个问题,发现启动完没有用这个是我们52服务器不发直接访问53,51我们把这个密钥访问配置下怎么配置这个可以参考我的hadoop学习第一篇里面的3.1传送门
配置完之后我们再次启动
然后我们去53服务器收入jps 发现多了一个NodeManager
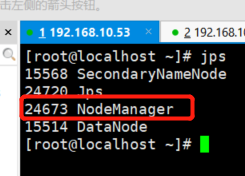
51,52服务器也多了1个
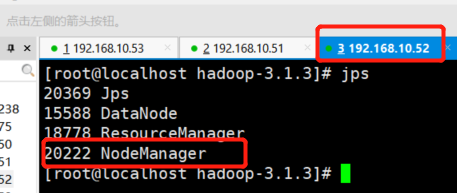
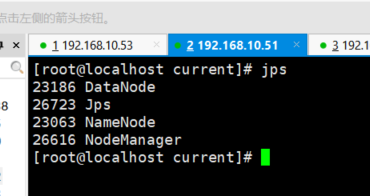
然后YARN有个图形化界面我们可以直接访问http://192.168.10.52:8088/
我的访问显示无法访问看下自己另一台机器的防火墙,看看这个端口是不是有所暴漏或者把防火墙关了

9.集群并测试集群
9.1)上传文件到集群
上传小文件
在服务器 192.168.10.51服务器上传文件 hadoop fs -put wcinput/word.txt /wciput

然后登录http://192.168.10.51:9870/explorer.html#/可以查看到我们上传的文件,

他会把这个文件分发到51,52,53这三台机子上(实际是存储在dataNode节点)
可以把他下载下来可以看到就是我们的服务器上的文件

这个是hdfs的一个基本操作
这个是hadoop数据存储目录
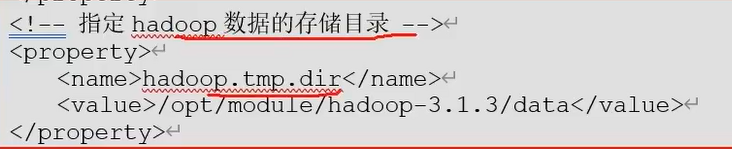
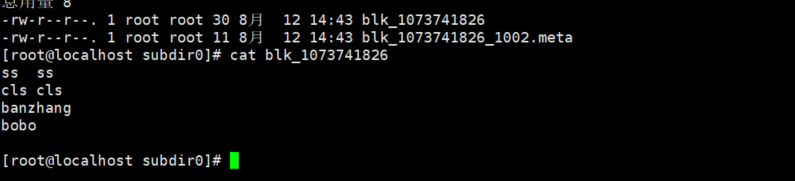
上传数据是存在这个目录下/opt/model/hadoop-3.1.3/data/dfs/data然后一层一层的往下拨一直拨到这一层
/opt/model/hadoop-3.1.3/data/dfs/data/current/BP-1484782157-127.0.0.1-1628399675371/current/finalized/subdir0/subdir0

然后我们cat 一下这个文件就是我们上传的那个文件
10配置删除权限
10.1 我们发现当我们点删除的时候报错无法删除是因为我们没有权限

我们在hadoop中这个文件加入这句话这个是配置静态网页段的权限文件地址在/opt/model/hadoop-3.1.3/etc/hadoop 文件是core-site.xml执行完然后在分发到各各集群上就好啦
<!-- 配置 HDFS 网页登录使用的静态用户为 atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
然后重新关闭再启动就能好啦然后就能删除掉了。
















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











