







 本文是学习《Kubernetes权威指南》的笔记,主要探讨了Pod的定向调度(NodeSelector)和亲和性调度(NodeAffinity、PodAffinity)。通过示例展示了如何使用kubectl命令给节点打标签,以及如何创建Deployment实现定向调度。还介绍了NodeAffinity的硬限制和软限制,以及PodAffinity和PodAntiAffinity在实现Pod间亲和与互斥调度的作用。
本文是学习《Kubernetes权威指南》的笔记,主要探讨了Pod的定向调度(NodeSelector)和亲和性调度(NodeAffinity、PodAffinity)。通过示例展示了如何使用kubectl命令给节点打标签,以及如何创建Deployment实现定向调度。还介绍了NodeAffinity的硬限制和软限制,以及PodAffinity和PodAntiAffinity在实现Pod间亲和与互斥调度的作用。
此文为学习《Kubernetes权威指南》的相关笔记
学习笔记:
RC等副本控制器使用了系统自动调度算法完成一组Pod的部署,在完成对Pod的定义后,交由调度器scheduler根据各工作节点情况,以负载均衡的原则进行分配,在这种模式下,Pod副本可能被调度到任意一个可用的工作节点。
阿里云大学云原生公开课上,对Deployment给出的介绍如下:
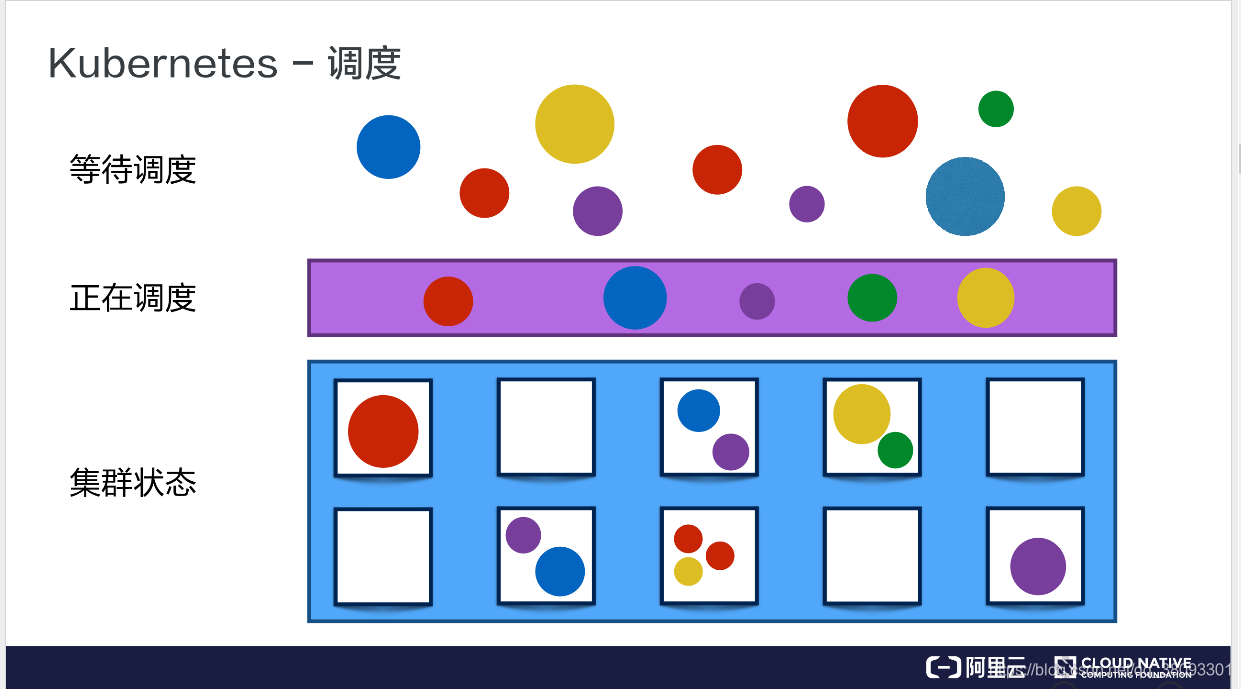
但在某些场景下, 设计者希望Pod副本能被调度到特定的工作节点上,需要更加细粒度的调度策略设置,完成对Pod的精准调度
NodeSelector为一种定向调度策略,在给工作节点打上标签后,可以在副本控制器创建时通过节点选择器来指定可调度的节点范围,这种方式足够精准,但一定程度上缺乏灵活性。
亲和性策略进一步扩展了Pod调度能力,正如“亲和性”这个定义所表达的,设计者希望这种策略能更细粒度,同时更灵活的去寻找最合适的调度结点,该策略包括节点亲和性和Pod亲和性,亲和性调度机制的优点如下:
- 更具表达力(不仅仅是死板的“必需满足”)
- 可以存在软限制,即有优先级策略,可以存在“退而求其次”的情况
- 可以延伸出Pod之间的亲和或互斥关系,依据节点上正在运行的其他Pod的标签进行限制
Node亲和性与NodeSelector类似,增强了上述两点优势,Pod的亲和性和互斥限制则通过Pod标签而不是节点标签来实现
不难想象上述策略的应用场景,下面是两种策略的运行实例。
一、NodeSelector:定向调度
1、通过kubectl label命令给目标Node打上一些标签
kubectl label nodes <node-name> <label-key>=<label-value>
给xu.node1节点打上标签zone=north
# kubectl label nodes xu.node1 zone=north
node/xu.node1 labeled
查看xu.Node1,可以看到新增加的标签列表,与此同时,可以看到K8s给Node提供的预定义标签
# kubectl describe node xu.node1
Name: xu.node1
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=xu.node1
kubernetes.io/os=linux
zone=north......
创建配置文件redis-master-controller.yaml
原书给出的是创建一个RC,这里修改为创建Deployment
可以看到nodeSelector域在spec.spec域之下,是对Pod属性的定义(毕竟Pod是调度基本单位
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-master
labels:
name: redis-master
spec:
replicas: 1
selector:
matchLabels:
name: redis-mas
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5817
5817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









