







对应论文:Understanding and Diagnosing Visual Tracking Systems
对于目前的追踪系统评估系统主要有Online tracking benchmark (OTB),the Visual object tracking challenge (VOT)等,这些评估系统主要评估追踪系统的准确率和鲁棒性等。但是,这些评价标准却很难理解和诊断追踪系统的强项与弱点。比如说,追踪系统A采用HOG作为特征,采用SVM作为observation model,追踪系统B直接采用未处理过的像素作为特征,采用logistic regression作为observation model。如果追踪系统A在VOT等挑战中效果比追踪系统B好,那么我们能说在追踪中,SVM要比logistic regression好?这个疑问明显是否定的,因为HOG特征要比纯像素有更强的特征表现力。
针对上述问题,作者提出一个框架,用于理解与诊断追踪系统。
作者将一个追踪系统分成了五个部分,分别为:motion model,feature extractor,observation model,model updater和ensemble post-processor。框架如下图:
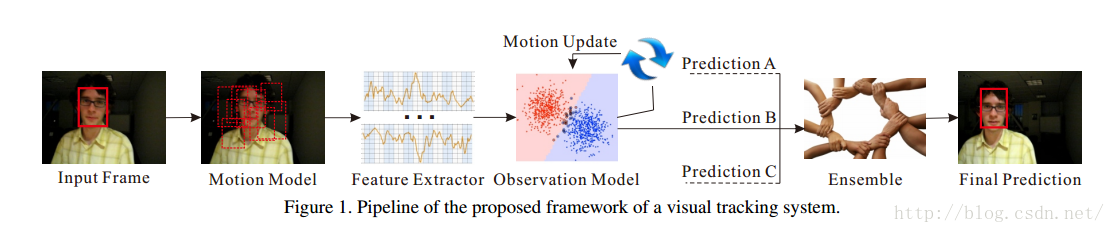
1. motion model:基于对前面帧的估计,该模型会产生一些在当前帧可能包含目标物体的候选的区域或者bounding boxes。
2. feature extractor:特征提取器表示每个候选区域使用的特征。
3. observation model:基于从候选区域提取出的特征,该模型判断候选区域是否为目标物体。
4. model updater:该模型控制着更新observation model策略以及频率。
5. ensemble post-processor:当一个追踪系统包含多个追踪器时,该模型会综合各个追踪器的预测,输出最终的预测结果。
一个追踪系统的通常工作方式如下:首先,在第一帧,用给定的目标区域(一般是由用户框出来的或者事先指定好目标区域坐标)初始化observation model;然后在接下来的每一帧中,motion model根据对前面帧的估计,先产生候选区域框,然后observation model计算出每个候选区域框是目标物体的概率,计算得到的最高概率的候选区域框将被选择为当前帧的估计结果(即目标所在的区域)。基于observation model的输出,model updater决定observation model是否需要更新,如果需要,更新频率是什么。最后,如果一个追踪系统中如果有好几个追踪器,ensemble post-processor会将各个追踪器产生的预测结果综合/融合成一个更加精确地预测作为结果输出来。
下面,作者使用VTB1.0进行实验。
作者采用两种度量标准。第一个是,AUC重合率曲线(AUC of the overlap rate curve)。在每一帧中,追踪系统预测出的目标物体位置区域A与真实的目标物体位置B,重合率a=(A∩B)/(A∪B),设定一个阈值(0~1之内变化),当重合率大于阈值时,则该帧为Success,对于整个视频所有的帧,我们便可以计算出成功率(Success rate)。
另一个度量标准是位置误差曲线。追踪系统预测出的目标物体位置区域与真实的目标位置区域的中心点的距离,以像素为单位。
作者设计了一个基础的追踪系统。该系统采用particle filter框架作为motion model,将灰度图像的像素作为特征,将logistic regression作为observation model。对于model updater,作者采用一个简单的规则:候选区域框中的最高得分如果在阈值之下,那么该模型将会更新。该基础的追踪系统只有一个追踪器,因此不包含ensemble post-processor部分。该模型的效果如下(下图黑色曲线):
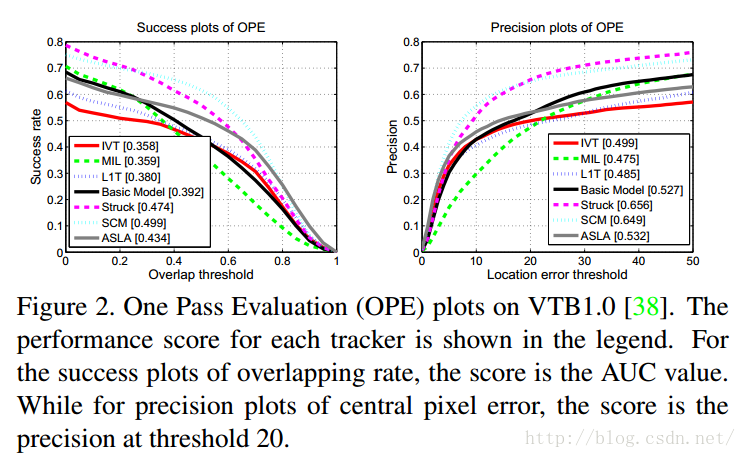
接下来,作者对上述5个部分分别进行了对比实验。
Feature Extractor
作者采用了如下5种特征进行实验。1. Raw Grayscale(未处理的灰度图):简单地将图像重新调整到固定大小,然后将其转换为灰度图,然后使用像素值作为特征。
2. Raw Color(未处理的彩色图):图像采用CIE Lab颜色空间作为特征。
3. Haar-like Features(类Haar特征):
4. HOG
5. HOG + Raw Color
最后实验结果如下:
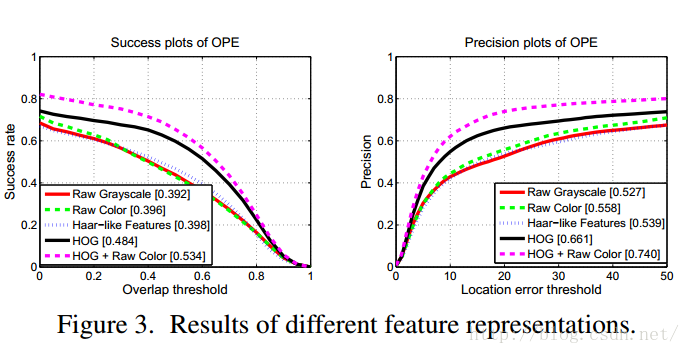
可以看出“HOG + Raw Color”为特征的追踪系统表现最好。
结论:在一个追踪系统中,特征是非常重要的。使用好的特征可以提高追踪系统的准确率。如何提取出一个具有强表现力的特征目前还需要更加深入的研究。
Observation Model
采用了如下4个模型进行对比实验。1. Logistic Regression
2. Ridge Regression
3. SVM
4. Structured Output SVM (SO-SVM)
实验结果如下:
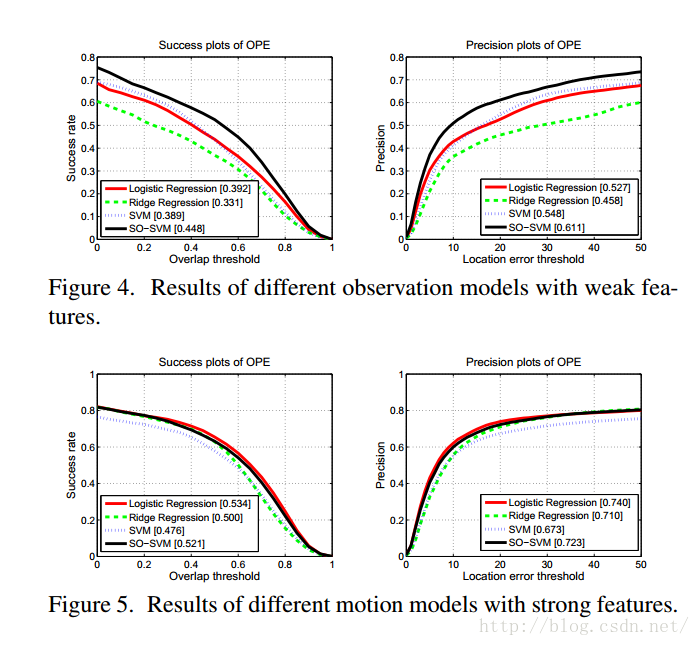
Figure 4是在弱特征(raw grayscale)下进行的实验,Figure 5是在强特征(HOG + raw color)下进行的实验。可以看出,在使用弱特征时,一个强大分类器(比如说SO-SVM)对追踪系统的提高作用比较大,但是在使用一个强特征时,上图可以看出,使用Logistic regression作为分类器的效果最好。
结论:当特征比较弱时,分类的好坏对最后结果的影响比较大;当特征比较强时,分类器的好坏对最后的结果影响较小,甚至用简单的分类器便可以达到很好的效果。
Motion Model
采用了如下3个模型进行实验。1. Particle Filter(粒子滤波):https://en.wikipedia.org/wiki/Particle_filter
2. Sliding Window:
3. Radius Sliding Window:
particle filter与sliding window两者的区别主要有以下两点:第一,particle filter可以维持每一帧的概率估计。因此当若干个候选区域有高的概率成为目标时,它们将会被保存用于接下来的帧。该方法对跟踪失败后重新跟踪是有帮助的。而sliding window只选择最高概率的那个候选区域框,并舍弃其他的候选区域框。第二,particle filter框架可以更容易处理如尺度变化,长宽比变化,甚至旋转和歪斜等情况。
实验结果如下:
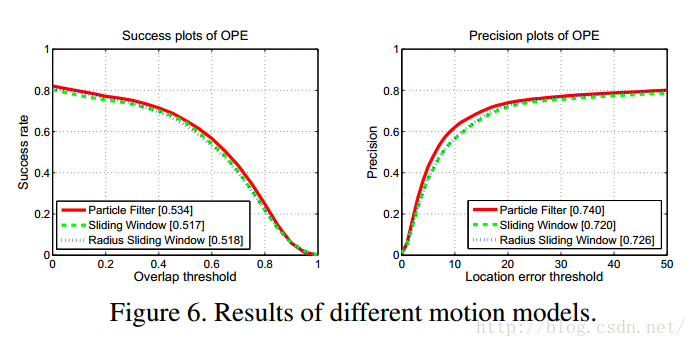
上述结果表明,三者的区别其实很小,particle filter并没有比另外两个表现更好。其中一个原因就是,这是在普通场景下做的实验。在复杂场景,相机有抖动的情况下,particle filter效果可能会更好。
然后,作者又在快速移动和尺度变化的情况做了实验(Figure 7上半部分为快速运动的实验结果,下半部分为尺度变化的实验结果)。
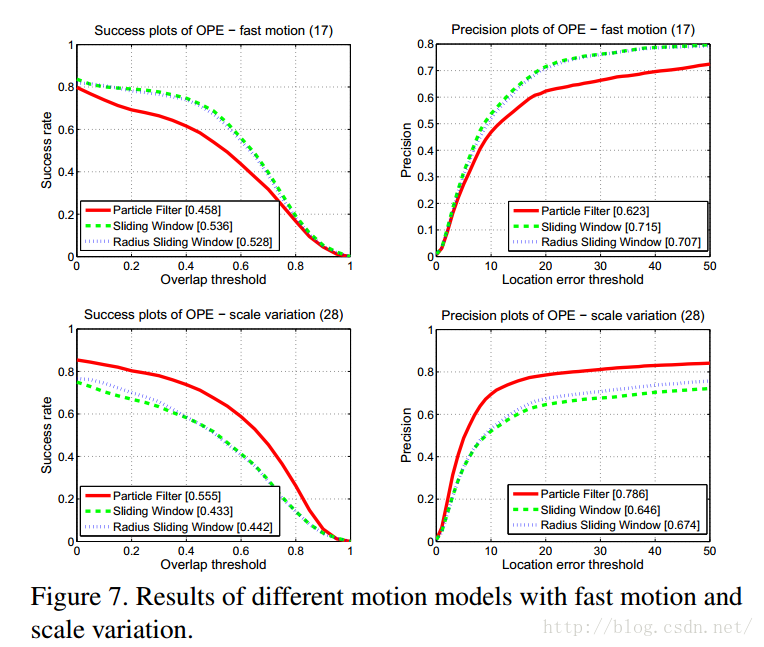
从上图可以看出,particle filter对尺度变化的处理能力比较好,但是对快速运动的情况处理能力比较差。particle filter可以在两种情况下同时处理好么?为了回答这个问题,作者首先查看了particle filter中的translation参数(控制追踪器的搜索区域),当搜索区域太小的时候,追踪器在快速移动的情况下容易丢失目标;当搜索区域大的时候,容易使追踪器产生漂移(由于背景的干扰)。另外,作者也注意到一个问题,在参数的设置上,是以像素的个数为单元的,这样,由于不同的视频有不同的分辨率,使用绝对的像素个数可能会造成不同的搜索区域。一个简单的解决方法就是通过视频的分辨率比例化参数,相当于重新调整视频的大小到一些固定的尺度(原文是:A simple solution is to scale the parameters by the video resolution which, equivalently, resizes the video to some fixed scale.)。结果如下:

从上图可以看出,一个简单正规化步骤可以提高效果,尤其是在快速移动的情况下。通过这么一个简单的操作,particle filter可以很好的同时处理尺度变化和快速移动的情况。同时也验证了motion model的参数应该与视频的分辨率相适应。
结论:motion model对于追踪系统有一个比较小的影响。然而,合适地设置参数对获得一个好的效果是非常重要的。
Model Updater
一般来说,由于每个observation model的更新都是不同的,所以model updater一般说明model update什么时候应该做,还有其频率。作者采用了如下两种模型:
1. 只要当目标的置信度低于阈值时,就更新模型。这样做的目的是确保目标总是有高的置信度。这个也是作者实验的默认的更新模型。
2. 当目标的置信度与背景置信度的差值低于阈值时,更新模型。这种技巧简单的维持了正样本与负样本之前较大的差距,而不是使目标有一个比较高的置信度。这个方法对遮挡或者目标消失的情况比较有帮助。
实验结果如下(Figure 9是第一种模型的结果,Figure 10是第二种模型的结果):
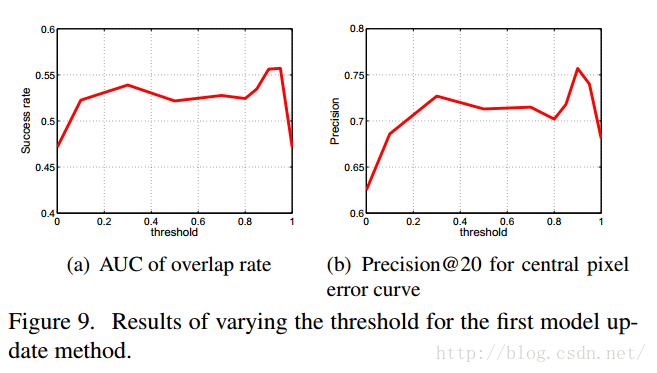

可以看出,不同的阈值,对结果的影响超过了10%。两种方法的最好的结果都差不多,但是模型二好的结果的范围比较宽一点。
结论:尽管模型的更新经常被视为工程上的技巧(treated as engineering tricks),但是对结果的影响仍然是很重要的,需要更加深入的研究。
Ensemble Post-processor
从上面的分析中可以看出来,单个追踪器有时候由于参数的设置等原因,结果会变得不是很稳定。而ensemble post-processor这部分就可以解决这一局限。在这一部分测试中,包括6个追踪器,分别是Logistic Regression、Ridge Regression、SVM、SO-SVM、DSST和TGPR。这几个初始效果如下: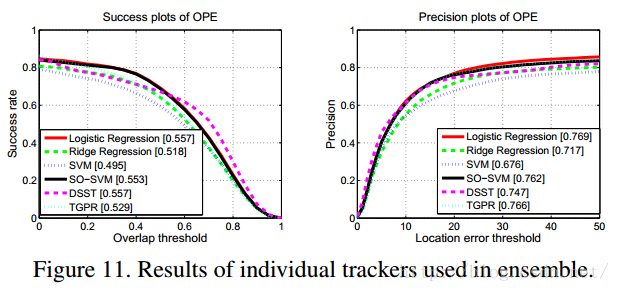
然后,ensemble post-processor有如下两种测试模型:
1. 来自论文“A superior tracking approach: Building a strong tracker through fusion.”的方法。(大致的方法为:This paper first proposed a loss function for bounding box majority voting and then extended it to incorporate tracker weights, trajectory continuity and removal of bad trackers.)作者采用该文章里面的basic model和online trajectory optimization这两个模型。
2. 来自论文“Ensemble-based tracking: Aggregating crowdsourced structured time series data.”的方法。(大致的方法为:The authors formulated the ensemble learning problem as a structured crowdsourcing problem which treats the reliability of each tracker as a hidden variable to be inferred. Then they proposed a factorial hidden Markov model that considers the temporal smoothness between frames.)作者采用该文章里面的ensemble based tracking (EBT) without self-correction模型。
由于前四种追踪器(Logistic Regression、Ridge Regression、SVM、SO-SVM)都是采用相同的特征和motion model,因此多样性受到了限制。增加后两个追踪器(DSST和TGPR)的一个主要的原因就是增加追踪系统的多样性,因为多样性在提升效果上有比较重要的作用。为了研究多样性是如何影响最后的效果的,作者做了两个实验,一个是只有前四个追踪器结合的效果(Figure 12),另一个是所有6个追踪器结合的效果(Figure 13)。结果如下:

从上述的结果中可以看出来,多样性确实提升了追踪系统的效果。上述两个系统都可以很好的提升最终的效果(相比于单个追踪器的效果)。
结论:ensemble post-processor模块可以提高追踪系统的效果,尤其是当追踪器多样性比较高的时候
结论
1. 特征的提取在追踪系统中是最重要的2. 如果特征很强大,那么observation model其实并没什么那么重要。
3. motion model、model updater和ensemble post-processor对追踪系统也有一定的影响,研究好这三个模块也很重要。















 4728
4728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









