







 本文详细介绍了如何在Windows和Ubuntu环境下安装Pyaudio,并提供了使用Pyaudio进行录音和播音的具体代码实现。从安装过程到具体操作步骤,再到代码优化,全面解析Pyaudio的使用技巧。
本文详细介绍了如何在Windows和Ubuntu环境下安装Pyaudio,并提供了使用Pyaudio进行录音和播音的具体代码实现。从安装过程到具体操作步骤,再到代码优化,全面解析Pyaudio的使用技巧。
Python开发之路(1)— 使用Pyaudio进行录音和播音
一、安装Pyaudio
1、在Windows10的PyCharm集成开发环境里安装Pyaudio
打开【Settings】,选择【Project Interpreter】,然后点击右侧的【+】号
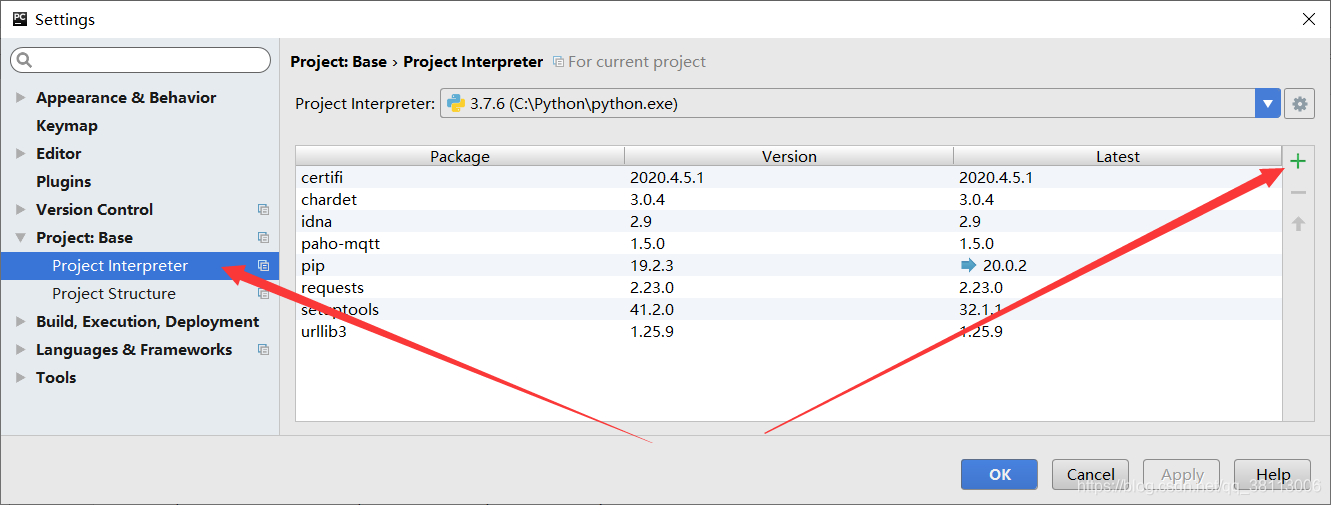
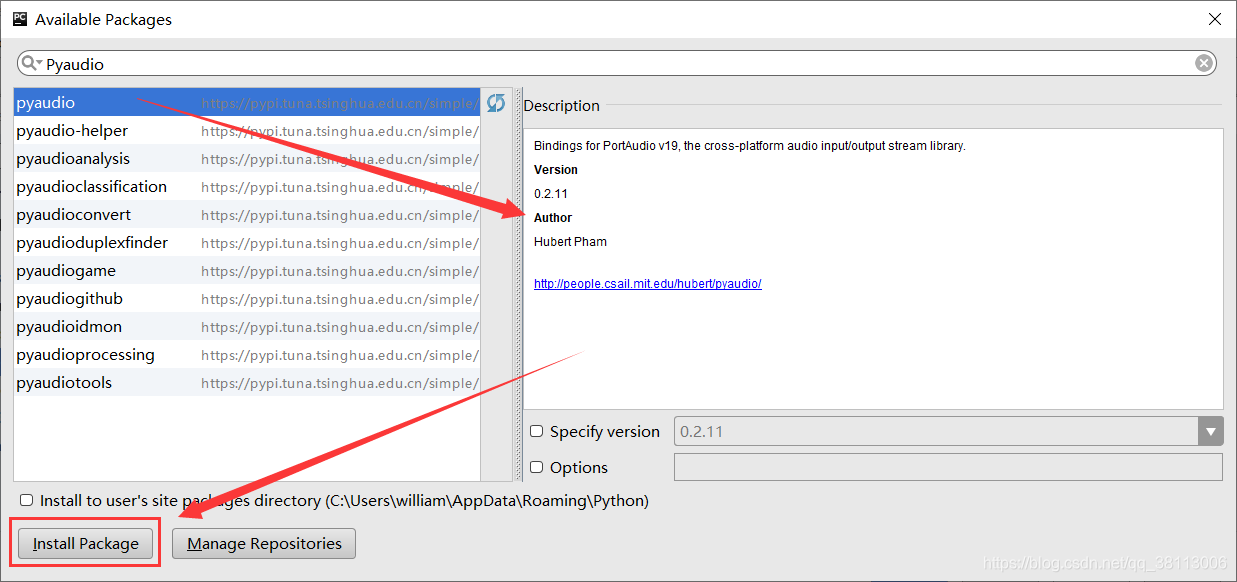
搜索pyaudio,点击安装
2、在ubuntu16下使用pip3安装Pyaudio
如果ubuntu下没有安装pip3,使用如下命令安装
sudo apt-get install python3-pip
我们需要安装一些依赖库
sudo apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
sudo apt-get install swig
sudo apt-get install libatlas-base-dev
sudo apt-get install alsa-utils alsa-tools alsa-tools-gui alsamixergui -y
然后使用pip3命令安装pyaudio即可
pip3 install pyaudio

3、安装失败
无论是在windows还是Ubuntu下安装失败,我们可以直接使用whl安装,
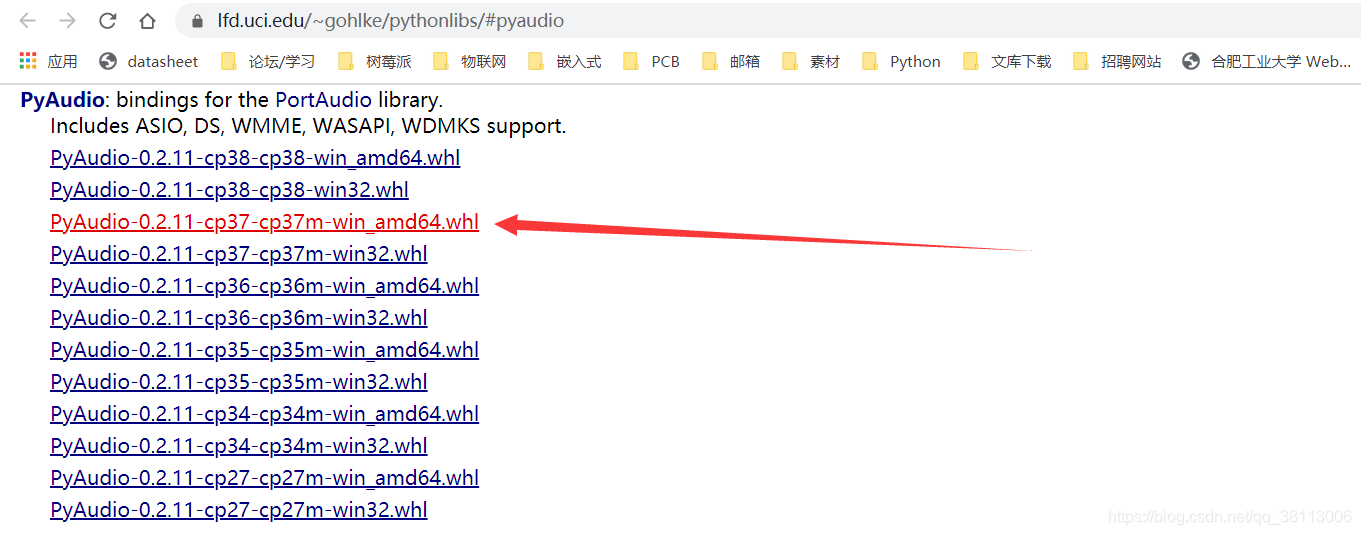
下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio
选择和直接系统位数及python版本对应的下载,例如我的是Python 3.7.6,64为的Windows系统,就选择PyAudio‑0.2.11‑cp37‑cp37m‑win_amd64.whl
下载好后打开命令行进入到那个文件夹下,使用命令安装即可:
pip install PyAudio-0.2.11-cp37-cp37m-win_amd64.whl #windows下
在Ubuntu下就使用
pip3 install PyAudio-0.2.11-cp37-cp37m-win_amd64.whl #Ubuntu下
如下所示,安装成功

二、使用pyaudio播音
首先我们要确认声卡是否能够使用在Ubuntu 上输入alsaloop命令,即在扬声器听到你说话的声音。
我们要导入需要用到的pyaudio包
import pyaudio,wave
首先,打开我们要播放的文件
# 打开我们要播放的文件
wf=wave.open(r"01.wav",'rb')
然后就可以实例化一个PyAudio对象了
# 实例化一个PyAudio对象
pa = pyaudio.PyAudio()
然后使用这个对象去打开声卡,设置 采样深度、通道数、采样率、输入和采样点缓存数量
# 打开声卡
stream = pa.open(format=pa.get_format_from_width(wf.getsampwidth()), # 从wf中获取采样深度
channels=wf.getnchannels(), # 从wf中获取声道数
rate=wf.getframerate(), # 从wf中获取采样率
output=True) # 设置为输出
然后将得到的音频数据播放出来即可
count = 0
while count < 8*5:
audio_data = stream.read(2048) # 读出声卡缓冲区的音频数据
record_buf.append(audio_data) # 将读出的音频数据追加到record_buf列表
count += 1
print('*')
播放完成后关闭声卡,终止PyAudio
# 关闭声卡
stream.close()
pa.terminate()
在Windows下直接使用录音机录音,然后将名字修改成"01.wav",并复制到python脚本所在的文件夹下;
在ubuntu下,可以使用命令录制一段5秒的声音进行测试;
arecord -D "plughw:0,0" -f S16_LE -r 16000 -d 5 -t wav 01.wav
参数是意义
| 指令 | 含义 | 本指令含义 |
|---|---|---|
| -D | 选择设备名称 | 使用系统自带声卡plughw:0,0 |
| -f | 录音格式 | S16_LE代表有符号16位小端序 |
| -r | 采样率 | 16000是16KHz采样 |
| -d | 录音时长 | 录音5秒 |
| -t | 录音格式 | wav格式 |
| 01.wav | 文件名,可以包含路径 | 文件名字叫 01.wav |
然后运行python程序即可播放声音
三、使用pyaudio录音
首先我们要确认声卡是否能够使用,在windows上直接使用windows自带的录音机即可;在Ubuntu 上输入alsaloop命令,即在扬声器听到你说话的声音。保证声卡可以使用后我们就可以开始编写代码进行录音了。
首先,我们要导入需要用到的pyaudio包
import pyaudio,wave
接下来就可以实例化一个PyAudio对象了
# 实例化一个PyAudio对象
pa = pyaudio.PyAudio()
然后使用这个对象去打开声卡,设置 采样深度、通道数、采样率、输入和采样点缓存数量
# 打开声卡,设置 采样深度为16位、声道数为2、采样率为16、输入、采样点缓存数量为2048
stream = pa.open(format=pyaudio.paInt16, channels=2, rate=16000, input=True, frames_per_buffer=2048)
新建一个列表,用来存储采样到的数据
# 新建一个列表,用来存储采样到的数据
record_buf = []
然后就通过声卡循环采用,采样到一定数据后即可停止采样
count = 0
while count < 8*5:
audio_data = stream.read(2048) # 读出声卡缓冲区的音频数据
record_buf.append(audio_data) # 将读出的音频数据追加到record_buf列表
count += 1
print('*')
采样完成后将数据写入一个wav文件,首先我们要创建一个音频文件,然后设置 声道数、采样深度、采样率
wf = wave.open('01.wav', 'wb') # 创建一个音频文件,名字为“01.wav"
wf.setnchannels(2) # 设置声道数为2
wf.setsampwidth(2) # 设置采样深度为
wf.setframerate(16000) # 设置采样率为16000
# 将数据写入创建的音频文件
wf.writeframes("".encode().join(record_buf))
# 写完后将文件关闭
wf.close()
然后我们需要要停止声卡,关闭声卡,终止pyaudio
# 停止声卡
stream.stop_stream()
# 关闭声卡
stream.close()
# 终止pyaudio
pa.terminate()
运行程序,可以看到脚本目录下多出来一个大约5秒的音频文集,windows下直接使用默认播放器麻烦即可,在ubuntu下可以使用命令播放
aplay 01.wav
四、优化
为了更好的使用体验,我们可以在录音的过程中添加一个进度条。
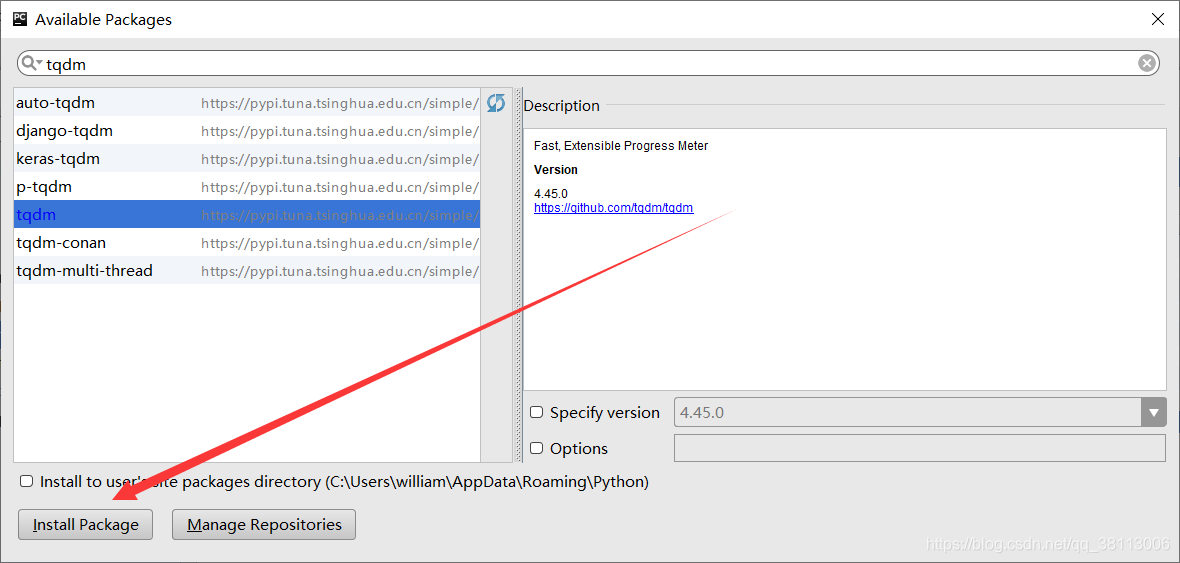
要使用进度条,我们需要导入tqdm模块,在Pycharm里之间搜索然后安装即可:
在ubuntu里使用命令安装即可:
pip3 install tqdm

然后就可以导入tqdm模块
from tqdm import tqdm
将录音python 代码中的循环采样中的while count < 8 * 5 :

修改为for i in tqdm(range( 8 * 5 )):即可:

然后可以看到:


















 2152
2152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









