







Adaboost 算法
- 算法简介
(1)adaboost是有监督的分类算法
- 有监督 无监督的区别,直观来看,区别在于训练集中,是否需要包括因变量Y。
例如:
无监督算法 —— K-means聚类算法,只需要自变量X1,X2 … ,就能够对数据集分类。(通过数据之间的距离分类,距离近的归为一类)
有监督算法 —— 例如回归算法,需要自变量X1,X2 … 和因变量 Y,在训练集中,通过已知的Y,才能计算出每个X的最优系数。
(2)算法特点
对adaboost算法特点的描述,网络上有很多,这里归纳为两个关键词:
-
集成分类算法 —— 最终得到的分类器,是所有分类器的加权综合。
类似的思维有随机森林,但是与随机森林不同的是:
随机森林的分类器是并行的,例如:分类器1、2可以同时训练数据,训练出结果后,再确定权重综合为最终的分类树。
adaboost的分类器不是并行的,下一轮的分类器,它所运用的数据,会受到上一轮分类器的影响。 -
权重 —— 权重这一特点,涉及到分类器的权重,和数据的权重。也是adaboost被称为自适应算法的原因。
- 分类器的权重:最终的分类器,是由每一轮得到的弱分类器,加权求和得到。
- 数据的权重:每一轮的训练数据,都有各自的权重,且在下一轮会改变,错分的数据权重增大,正确分类的数据权重减少。
(3)算法优点
分类算法很多,比如SVM可以满足线性/非线性分类;聚类算法是无监督算法,决策树算法逻辑简单,且不用归一化。
下面我们来关注Adaboost作为分类算法的优点:
- 精度较高 —— 即用adaboost分类,分类结果的准确率较高。
原因:综合多个弱分类器得到的结果,且根据上文描述可知,每一步迭代,adaboost都会重点关注上一次被错分的训练数据,所以在下一次迭代中会让对这些错分的数据,进行重新分类。因此精度总体而言较高。
- 算法逻辑
先举一个例子,不谈具体推导,在看例子的过程中,了解算法的逻辑。
(1)给出训练样本。
样本介绍:10个训练样本,一个自变量X,取值范围0-9,因变量为Y,取值为1/-1。

(2)算法过程
第一步:初始情况设定
- 给定一个基本分类器,例如:

- 给定每个训练数据初始权重,令每个权值W1i = 1/N = 0.1,即10个样本所占的权重是一样的
第二步:进入迭代过程
- 计算分类器的误差率(被G1(x)误分类样本的权值之和),得到这一分类器的权重(即在最终分类器中的占比)
例如:G1(x)的误差率为0.3 ——
- 0 1 2对应的类(Y)是1,因它们本身都小于2.5,所以被G1(x)分在了相应的类“1”中,分对了。
- 3 4 5本身对应的类(Y)是-1,因它们本身都大于2.5,所以被G1(x)分在了相应的类“-1”中,分对了。
- 但6 7 8本身对应类(Y)是1,却因它们本身大于2.5而被G1(x)分在了类"-1"中,所以这3个样本被分错了。
- 9本身对应的类(Y)是-1,因它本身大于2.5,所以被G1(x)分在了相应的类“-1”中,分对了。
- 从而得到G1(x)在训练数据集上的误差率(被G1(x)误分类样本“6 7 8”的权值之和)e1=P(G1(xi)≠yi) = 3*0.1 = 0.3。
- 根据误差率e1计算G1的系数:(该公式推导在后文)
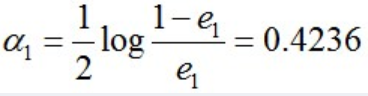
这个a1代表G1(x)在最终的分类函数中所占的权重,为0.4236。
- 接着计算训练数据的新的权重,让错分的样本的权重增加,正确分类的样本的权重减少,这样会尽量错分的样本在下轮不被分错,提高准确率
- 新的样本权重为:
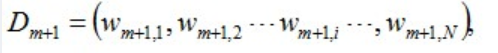
计算方式为: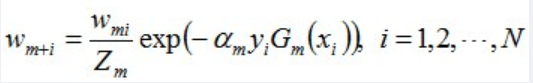
其中,Zm是规范化因子,使得Dm+1成为一个概率分布(即让Dm+1各项相加等于概率值1):
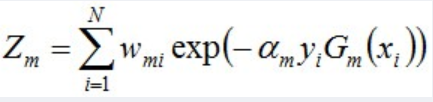
- 计算结果为:
D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)。
被分错的样本“3 4 5”的权值变大,其它被分对的样本的权值变小。 - 根据误差率,找到此时的较好的分类器。例如:
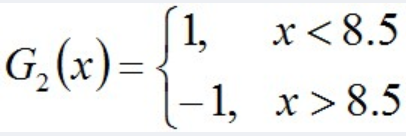
- 接着如上文所述,计算这一分类器的权重,同时更新训练数据的权重。
进入下一轮迭代,迭代结束的条件,可以定为误差率降低到某个阈值。
最后通过线性组合方式,组合各个分类器。
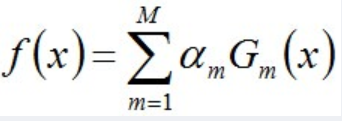
例如第二轮得到的分类器为:
f2(x)=0.4236G1(x) + 0.6496G2(x)
- 算法推导
上文中可以看到,adaboost中的重要的公式为:
- 每个分类器的权重
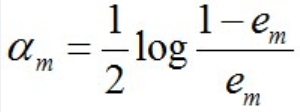
- 每轮训练数据权重的更新:
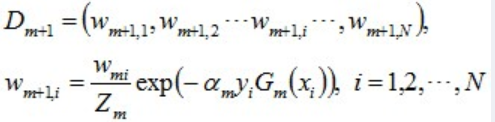
- 组合各个分类器,是线性组合方式
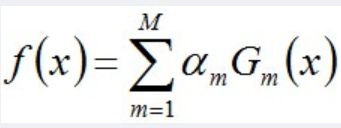
下文通过推导,得到这几个公式。
(1)分类器权重更新:


(2)数据权重更新:

- python代码
import numpy as np
class ThreshClassifier(): # 分类器
def __init__(self):
self.v = 0
self.direction = 0
def train(self, x, y, w): # w为样本权重
loss = 0
min_loss = 1
for v in np.arange(0.5,10,1): # 寻找分类器最好的阈值
for direction in [0,1]:
if direction == 0:
mis = (((x < v) - 0.5)*2 != y) # 分类器的公式形式
else:
mis = (((x > v) - 0.5)*2 != y)
loss = sum(mis * w) # 计算损失函数, 选取最低的损失函数对应的分类器
if loss < min_loss:
min_loss = loss
self.v = v
self.direction = direction
return min_loss
def predict(self, x):
if self.direction == 0:
return ((x < self.v) - 0.5)*2
else:
return ((x > self.v) - 0.5)*2
class AdaBoost(): # adaboost
def __init__(self, classifier = ThreshClassifier):
self.classifier = classifier
self.classifiers = []
self.alphas = []
def train(self, x, y):
n = x.shape[0]
M = 3
w_m = np.array([1 / n] * n) # 给定初始权重,权重均等
for m in range(M):
classifier_m = self.classifier()
e_m = classifier_m.train(x, y, w_m) # 给出该轮最优分类器的错误率
print(e_m)
alpha_m = 1 / 2 * np.log((1-e_m)/e_m) # 给出该轮分类器的权重
w_m = w_m * np.exp(-alpha_m*y*classifier_m.predict(x)) # 更新数据权重
z_m = np.sum(w_m)
w_m = w_m / z_m # 数据权重/规范因子,让概率相加为1
print(w_m)
self.classifiers.append(classifier_m)
self.alphas.append(alpha_m)
def predict(self, x):
n = x.shape[0]
results = np.zeros(n)
for alpha, classifier in zip(self.alphas, self.classifiers):
results += alpha * classifier.predict(x)
return ((results > 0) - 0.5) * 2
- 参考文章
Adaboost 算法的原理与推导_结构之法 算法之道-CSDN博客_adaboost算法
https://blog.csdn.net/v_july_v/article/details/40718799
机器学习笔记2:AdaBoost算法原理和推导详解_zhuzuwei的博客-CSDN博客_adaboost算法详解
https://blog.csdn.net/zhuzuwei/article/details/80538060?utm_medium=distribute.pc_relevant.none-task-blog-baidujs-9
Adaboost原理及简单的Python实现_SilverBullet-CSDN博客_adaboost python
https://blog.csdn.net/u013859301/article/details/79483126














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









