







count()函数是用来返回在给定的选择中被选的行数,经常与group by一起使用即
select count(*) from db_name group by row_name;现在有如下的表(db_test)中的数据:
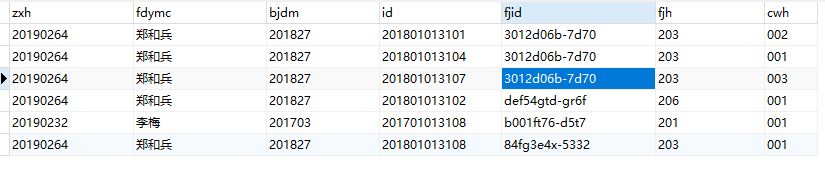
其中字段含义:zxh(职工号);fdymc(辅导员名称);bjdm(班级代码);id(主键);fjid(房间id);fjh(房间号);cwh(床位号)。
现在需要统计各个辅导员所拥有的房间总数,从数据可以看出,郑和兵有3间,李梅有1间。所以首先需要通过“zgh”进行分组,然后在根据“fjid”进行分组,最终的sql:
SELECT db.fdymc,COUNT(1) AS fjs FROM db_test db GROUP BY db.zxh, db.fjid 运行结果为:
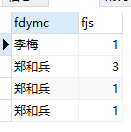
结果与我们到数的不一致,为什么会出现这种情况哪?
先看两条sql:
第一条:
SELECT db.fdymc,COUNT(1) AS fjs FROM db_test db GROUP BY db.zxh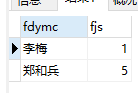
第二条:
SELECT db.fdymc,COUNT(1) AS fjs FROM db_test db WHERE db.zxh ='20190264'
GROUP BY db.fjid
从这两条sql的查询结果可以看出,将第一条的结果李梅的数据拼接到第二条的结果上正好是上面运行结果,group by 多字段分组时会分步执行,首时先会根据第一个字段进行分组统计出数据,这个数据在根据第二个字段再次进行分组统计。
那么怎么才能获取正确的统计数据呐?这就需要用到DISTINCT 进行去重,数据可以发现,以“zxh”分组之后发现,在以"fjid"分组会出现三个重复的数据,如果把这三个数据去重,恰好就是需要的统计数据,在count()中可以写成COUNT(DISTINCT db.fjid),,即sql就是这样的:
SELECT db.fdymc,COUNT(DISTINCT db.fjid) AS fjs FROM db_test db
GROUP BY db.zxh这段执行的顺序就是先以“zxh”进行分组,然后统计时会根据去重后的“fjid”进行统计。先简单介绍一下count(*),count(1)以及count(row)的区别:
在执行过程中count(1)和count(*)的区别并不大,在性能方面用时区别不是太大,都不会忽略null,但count(row)则只包括列名那一列,在统计结果的时候,会忽略列值为null的计数。当row为主键时则性能更优。
所以当COUNT(DISTINCT row)时,统计的则是这一列名中去重后忽略值为null的计数。















 6961
6961











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









