







 本文深入探讨了zRAM内存压缩技术,包括其出现背景、软件架构、实现分析以及性能调优方法。zRAM通过利用空闲CPU周期在RAM中压缩数据,有效缓解内存瓶颈。在Android和部分Linux发行版中,默认启用该技术以优化内存使用。文章还讨论了zRAM的压缩算法选择、预读策略和去重功能,提供了性能调优的多个角度,以实现更高效的内存管理。
本文深入探讨了zRAM内存压缩技术,包括其出现背景、软件架构、实现分析以及性能调优方法。zRAM通过利用空闲CPU周期在RAM中压缩数据,有效缓解内存瓶颈。在Android和部分Linux发行版中,默认启用该技术以优化内存使用。文章还讨论了zRAM的压缩算法选择、预读策略和去重功能,提供了性能调优的多个角度,以实现更高效的内存管理。
目录
1. zRAM出现的背景
阿姆达尔定律告诉我们,任何计算机操作系统总是存在瓶颈。从历史上看,许多系统上工作负载的瓶颈是 CPU,因此系统设计人员致力于 CPU 运行更快、更高效,不断增加 CPU 内核的数量。 慢慢地,RAM 越来越成为瓶颈。当数据从磁盘加载到 RAM时,CPU会闲置地等待。增大 RAM 并不总是一个具有成本效益的选择,有时甚至根本不是一个选择。更快的 I/O 总线和固态磁盘SSD减少了瓶颈,但并没有消除它。于是工程师们想,假如可以增加存储在 RAM 中的有效数据量,那不是很好吗?而且,由于这些 CPU 无论如何都在等待,也许我们可以使用这些空闲的 CPU 周期来做一些事情实现这一目标?这是内核压缩的目标:我们在 RAM 中保留更多压缩数据,并使用空闲的 CPU 周期来执行压缩和解压缩算法。
zRAM于2014 年进入 Linux 3.14 内核主线,但由于 Linux 用途十分广泛,这一技术并非没有默认启用,只有 Android 移动终端设备和少部分的 Linux 桌面发行版如 Fedora 默认启用了这一技术,以保证多任务场景下内存的合理分层存储。
举个具体的例子,你在android手机上连续打开了10个应用,系统空闲内存持续下降,通过zRAM内存压缩会把最近最少使用的页面压缩起来, 如淘宝的页面已最近最少使用的,原来占用100M的匿名页会压缩起来存放,压缩后占用40M,通过这个压缩就节省了60M内存。从而过到内存压缩保留更多数据在RAM中的目的, 让用户体验更佳。
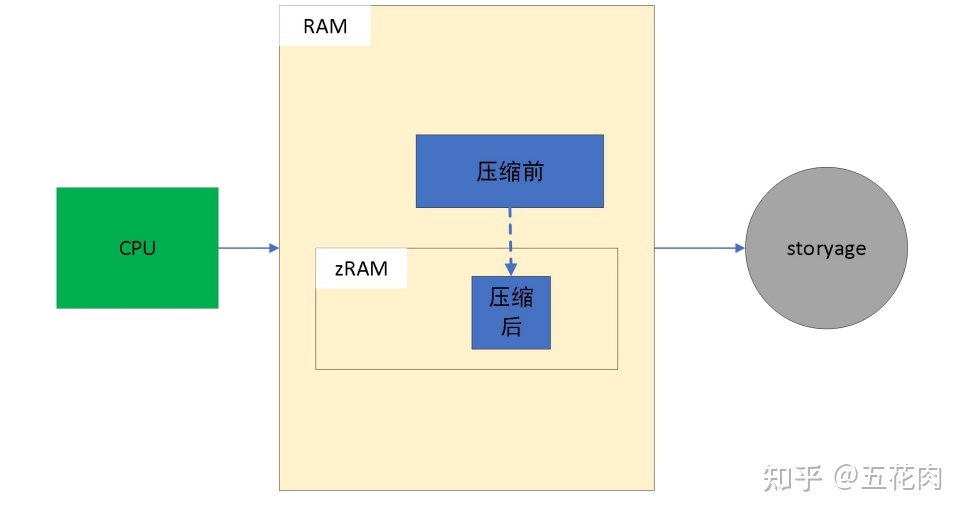
2. zRAM软件架构
zRAM本质是一个块设备驱动,它使用内存模拟block device的做法。它把内存回收的策略交给内存管理,把压缩和解压缩交给压缩库,把自身内存分配交给zsmalloc, zRAM自身就是一个简单的驱动。
zRAM的软件架构主要包含3部分:

3. zRAM实现分析
3.1 zRAM驱动模块
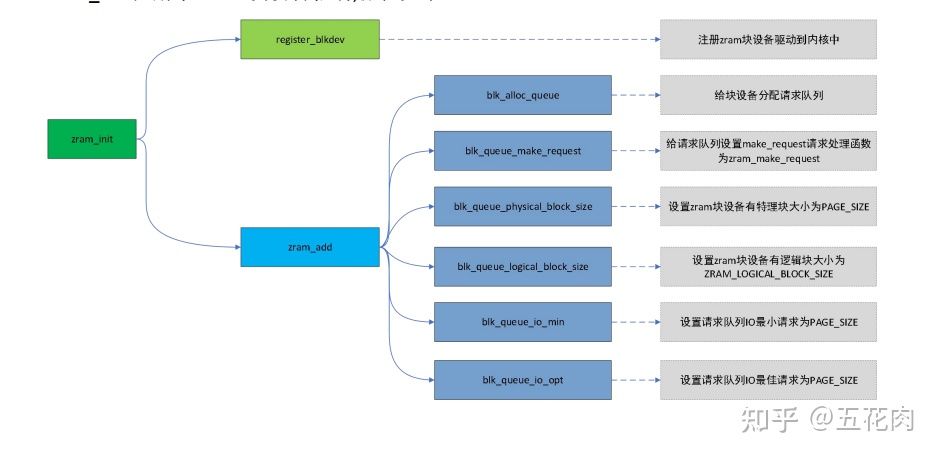
- zram_init
zram_init注册了zram块设备驱动,流程如下:
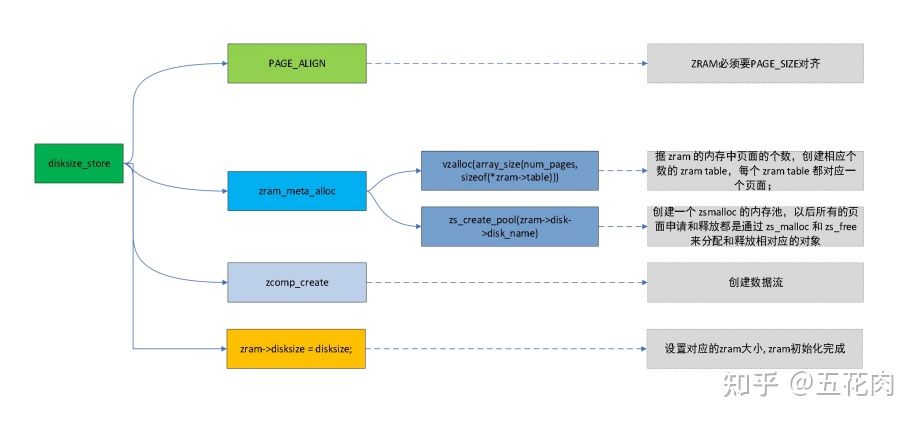
- disksize_store
创建zram设备驱动后,通过用户态节点配置zram块设备大小, 对应disksize_store函数。
流程如下:
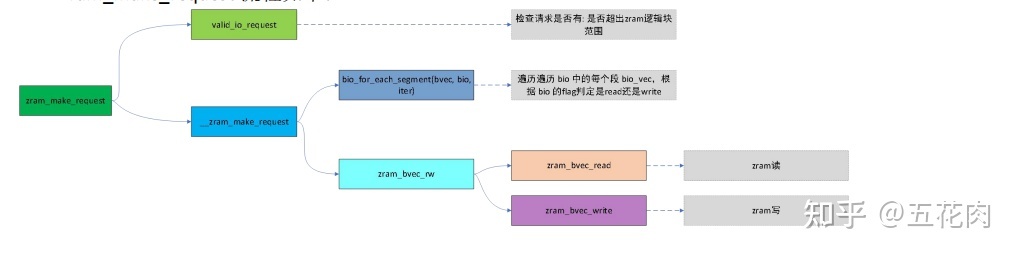
- zram_make_request
所有zram的块设备请求都是通过zram_make_request进行的。
zram_make_request流程如下:
3.2 数据流模块
内核使用zcomp_strm结构描述压缩数据流,buffer用于存放压缩后的临时数据。
struct zcomp_strm {
/* compression/decompression buffer */
void *buffer;
struct crypto_comp *tfm;
};以前的3.15老版本内核提供了接口给上层设置最大压缩流。笔者从4.19内核中已经看到,尽管还是保留这个接口,但其实设置已经没有意义了,因为底层内核会针对各个CPU都配置一个压缩数据流。内核zram.txt有描述:
Set max number of compression streams Regardless the value passed to this attribute, ZRAM will always allocate multiple compression streams - one per online CPUs - thus allowing several concurrent compression operations. The number of allocated compression streams goes down when some of the CPUs become offline. There is no single-compression-stream mode anymore, unless you are running a UP system or has only 1 CPU online.
我们看下设置下来的值内核怎么处理,代码如下,它直接什么都不做,直接给返回了,所以新版本这里即便设置了也是设置了个寂寞,哈哈。
static ssize_t max_comp_streams_store(struct device *dev,
struct device_attribute *attr, const char *buf, size_t len)
{
return len;
}创建压缩数据流程如下:
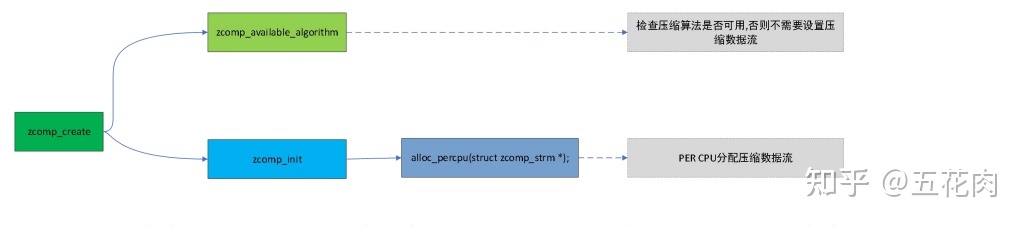
之所以要针对每个在线CPU都创建一个压缩数据流,主要是优化系统中并发的情况。每个写压缩操作都独享一个压缩数据流,通过多个压缩数据流,使得系统允许多个并发压缩操作。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9805
9805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









