







题目如下:
1.基础材料说明
1)训练集training.txt文件
该文件是一个大小为75.8MB的文本数据集,并包含了20,000,000条数据记录,每行数据中包含的信息为“评价结论\t 评价内容”。其中,“评价内容”是若干词语组合而成,词语之间是空格隔开,词语包括中文、英文以及其他特殊符号,即其内容为“word1 word2 word3 word4 …… wordn”,其中wordi表示当前文本描述中的第i个词,n为当前文本描述中包含的总词数。
2)测试集test.txt文件
给定“test.data”数据集,该数据集包含了2000条记录,每行记录中包含的信息为“评价内容”,该“评价内容”的具体表现形式与前文描述的“training.txt”数据集相同。
2.课程任务说明(每一步均有一项提交的材料)
1)基于Vmware安装CentOS Linux/ubunt环境(三台及以上),并在此基础之上安装Hadoop集群环境,整个安装过程涉及到的配置文件修改,需要写在“学号_Hadoop配置.docx”文件中。(共一项任务,共10分)
2)在命令行环境下上传training.data文件,在Web界面上传test.txt文件,文件上传至hdfs的“input_学号”目录下,将整个过程写在“学号_上传文件.docx”文件中。(共一项任务,共10分)
3)在命令行环境下,查看数据集是否上传成功,将使用的命令写在“学号_上传文件检查.docx”文件中。(共一项任务,共5分)
4)基于Eclipse创建Hadoop工程,需提交工程代码,工程的命名:“NB_学号”,工程中应该应包含一个名”NB.java”的程序,该程序是整合工程的执行入口(包括main(),程序可直接运行)。 (共一项任务,共5分)
5)编写Java程序,使其能够实现基于上传至hdfs的“学号_上传文件.txt”数据集训练情感分类器的目的。在训练的过程中,应过滤包含非中文字符或全部由非中文字符构成的词语。保存模型文件至“学号_模型.txt”文件中。格式要求:(共一项任务,共20分)
| 类标_词语1\t计数 类标_词语2\t计数 类标_词语3\t计数 …… 类标1\t计数 类标2\t计数 |
6)基于训练得到的模型参数(即Nc和Ncw,其中,c表示情感标签类别,c∈{好评,差评},w∈V,V是“学号_上传文件.data”数据集包含的中文词典集合),对“test.txt”数据集中的各条记录进行“情感标签”判别。判别结果输出至“学号_预测结果.txt”文件中。“学号_预测结果.txt”文件中的每行是行号及“test.txt”中预测的“情感标签”:格式要求: (共一项任务,共20分)
| 1 情感标签 2 情感标签 3 情感标签 …… 2000 情感标签 |
7)以小组为单位提交总报告,将整个实验过程和结论以总报告的形式,命名为“学号_总报告.docx”。(共一项任务,共10分)
我经过编写代码之后得到的结果:


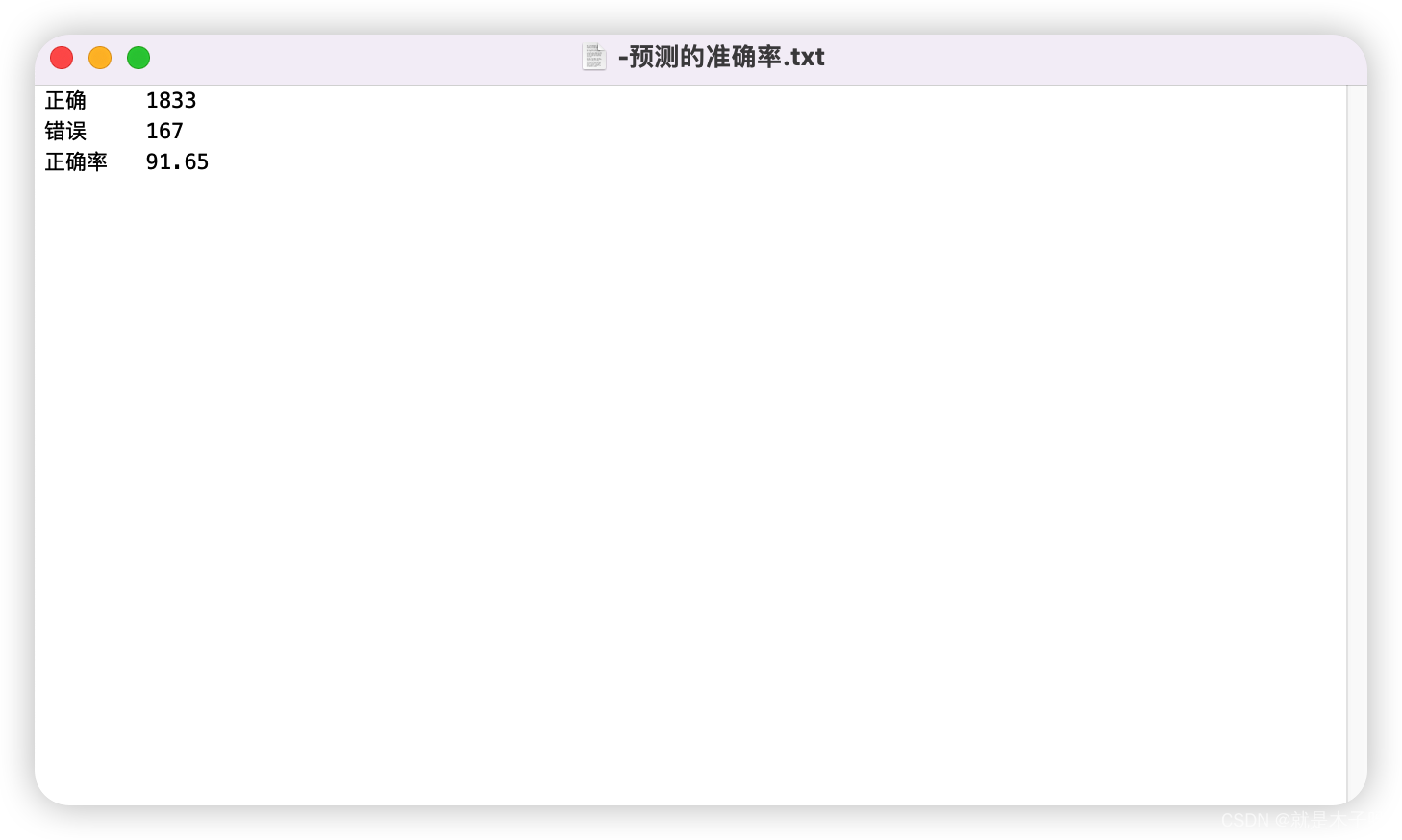
提交的所有文件:

部分代码:
NB.java
package com.gong.fusion.NB_2020081200;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.BasicConfigurator;
public class NB {
public static void main(String[] args) throws Exception {
BasicConfigurator.configure(); //自动快速地使用缺省Log4j环境。不使用则控制台不打印信息
Configuration configuration = new Configuration();
//启动job1任务
Job job1 = Job.getInstance(configuration, "task1");
job1.setJarByClass(NB.class); //指定jar打包主类
job1.setMapperClass(MyMapper.class); //指定mapper
job1.setReducerClass(MyReduce.class); //指定reduce
job1.setOutputKeyClass(Text.class); //指定输出的k格式
job1.setOutputValueClass(LongWritable.class); //指定输出的v格式
FileInputFormat.addInputPath(job1, new Path("file:///Users/mac/Desktop/input/training.txt")); //本地测试模式的读取路径
FileOutputFormat.setOutputPath(job1, new Path("file:///Users//mac//Desktop//output")); //本地测试模式的输出路径
//FileInputFormat.addInputPath(job1, new Path("hdfs://localhost:9020/input_2020081200/training.txt")); //指定文件读取路径
//FileOutputFormat.setOutputPath(job1,new Path("hdfs://localhost:9020/output"));//指定文件输出路径
job1.waitForCompletion(true); //等待任务完成
//启动job2任务
Job job2 = Job.getInstance(configuration, "task2");
job2.setJarByClass(NB.class); //指定jar打包主类
job2.setMapperClass(PredictMapper.class); //指定mapper
job2.setReducerClass(PredictReduce.class); //指定reduce
job2.setOutputKeyClass(IntWritable.class); //指定输出的k格式
job2.setOutputValueClass(Text.class); //指定输出的v格式
FileInputFormat.addInputPath(job2, new Path("file:///Users/mac/Desktop/input/test.txt")); //本地测试模式的读取路径
FileOutputFormat.setOutputPath(job2, new Path("file:///Users//mac//Desktop//output1")); //本地测试模式的输出路径
//FileInputFormat.addInputPath(job2, new Path("hdfs://localhost:9020/input_2020081200/test.txt")); //指定文件读取路径
//FileOutputFormat.setOutputPath(job2,new Path("hdfs://localhost:9020/output1")); //指定文件输出路径
job2.waitForCompletion(true); //等待任务完成
//启动job3任务
Job job3 = Job.getInstance(configuration, "task3");
job3.setJarByClass(NB.class); //指定jar打包主类
job3.setMapperClass(CountMapper.class); //指定mapper
job3.setReducerClass(CountReduce.class); //指定reduce
job3.setOutputKeyClass(Text.class); //指定输出的k格式
job3.setOutputValueClass(LongWritable.class); //指定输出的v格式
FileInputFormat.addInputPath(job3, new Path("file:///Users/mac/Desktop/input/test.txt")); //本地测试模式的读取路径
FileOutputFormat.setOutputPath(job3, new Path("file:///Users//mac//Desktop//output2")); //本地测试模式的输出路径
//FileInputFormat.addInputPath(job2, new Path("hdfs://localhost:9020/input_2020/test.txt")); //指定文件读取路径
//FileOutputFormat.setOutputPath(job2,new Path("hdfs://localhost:9020/output1")); //指定文件输出路径
job3.waitForCompletion(true); //等待任务完成
}
}
Mymapper.java
package com.gong.fusion.NB_2020081200;
import java.io.IOException;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
LongWritable one = new LongWritable(1); //one是一个固定的值1
String split[] = value.toString().split("\t"); //源文件以制表符隔开,得到一个数组
if(split.length==2){ //此处保证了选取的每行数据都是带有总评价(好或者坏)的
String label = split[0]; //好或者坏标签
context.write(new Text(label), one); //标签先放入上下文
String[] words = split[1].split(" "); //将评价词汇以空格为分隔符进行切分
for(String word : words) {
if(containsNonChineseCharacters(word)){ //筛选只含有中文的词汇
word="_"+word ; //每个词汇前面加上_来与标签分隔开
context.write(new Text(label+word), one); //写入上下文
}
}
}
}
public boolean containsNonChineseCharacters(String str) {
// 创建一个正则表达式,用于匹配中文字符
String pattern = "[\\u4E00-\\u9FA5]+";
// 如果字符串中包含非中文字符,则返回false,否则返回true
return str.matches(pattern);
}
}
MyReduce.java
package com.gong.fusion.NB_2020081200;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class MyReduce extends Reducer<Text, LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count=0l;
//1.遍历集合,将集合中数字相加,得到V3
for (LongWritable value : values) {
count+=value.get();
}
//2.将K2和V3写入上下文中
context.write(key,new LongWritable(count));
}
}
剩下的代码太多,需要的同学可以到我的资源那里去下载,点击我的头像关注一下,然后进到我的主页,查看我的资源下载。
也可以点击下面的链接快速跳转到我的资源进行下载!
hadoop大实验源码
https://download.csdn.net/download/qq_38136372/87373323?spm=1001.2014.3001.5503

















 344
344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











