









内部排序包括:插入排序、选择排序、交换排序、归并排序、基数排序。其中插入排序包括:直接插入排序、希尔排序;选择排序包括:简单选择排序,堆排序;交换排序包括:冒泡排序、快速排序。
1.直接插入排序
排序思路
假设待排序的元素存放在数组 a[0..n-1] 中,排序过程中的某一时刻,a 被划分成两个子区间 a[0..i-1] 和a[i..n-1](刚开始时 i=1,有序区只有 Data[0] 一个元素),其中,前一个子区间是已排好序的有序区,后一个子区间则是当前未排序的部分,称其为无序区。直接插入排序的一趟操作是将当前无序区的开头元素 a[i] (1 <= i <= n-1)插入到有序区 Data[0..i-1] 中适当的位置上,使 Data[0..i] 变为新的有序区,
特性总结
时间复杂度:最坏情况;最好情况O(n);
空间复杂度:O(1);
稳定性:稳定
示例
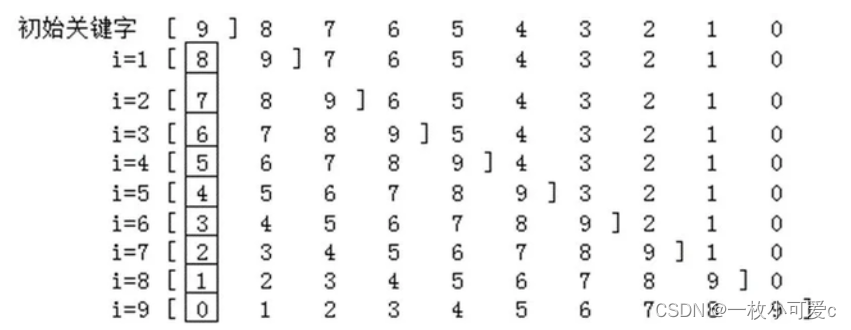
下图是直接插入排序的一个实例,图中用方括号表示每趟操作后的有序区。每趟向有序区中插入一个元素(用方框表示),并保持有序区中的元素仍有序。
Java代码实现
//直接插入排序,从小到大排,把一个数组的前一部分当作是有序的,后面的当作是无序的
public static void insertSort(int[] a){
int j, temp;
for (int i = 0; i < a.length; i++) {
temp = a[i];
j = i - 1;
while (j >= 0 && temp < a[j]) {
a[j + 1] = a[j];
j--;
}
a[j + 1] = temp;
}
}2.希尔排序
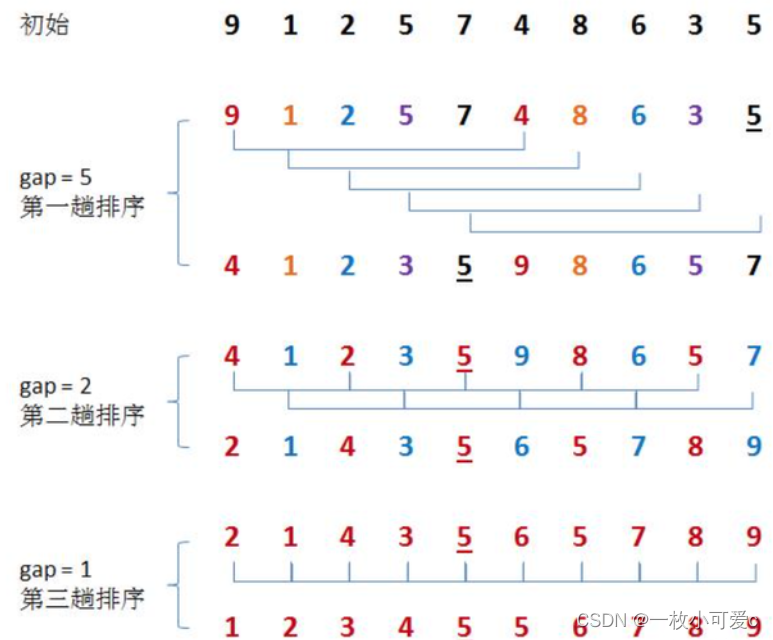
希尔排序法又称缩小增量法。
基本思想:
先选定一个整数gap,把待排序文件中所有记录分成gap个组,所有距离为gap的记录分在同一组内,并对每一组内的元素进行排序。
然后将gap逐渐减小重复上述分组和排序的工作。
当到达gap=1时,所有元素在统一组内排好序。
希尔排序的特性总结:
- 希尔排序是对直接插入排序的优化。
- 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。
- 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,这里不深究。
- 时间复杂度O(N^1.5)
- 空间复杂度O(1)
- 稳定性:不稳定
示例
Java代码实现
//希尔排序 该函数的输入是数组和数组的长度
public void shellSort(int[] array, int n) {
int i, j, gap;
int temp;
for (gap = n / 2; gap > 0; gap /= 2) {// 计算gap大小
for (i = gap; i < n; i++) {// 将数据进行分组
for (j = i - gap; j >= 0 && array[j] > array[j + gap]; j -= gap) {// 对每组数据进行插入排序
temp = array[j];
array[j] = array[j + gap];
array[j + gap] = temp;
}
}
}
}3.选择排序
基本思想:
第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始(末尾)位置,
然后选出次小(或次大)的一个元素,存放在最大(最小)元素的下一个位置,
重复这样的步骤直到全部待排序的数据元素排完 。
//选择排序 从小到大排,先选出最大的数放到数组的最后面,然后选取第二大的数放数组的倒数第二个
public static void SelectSort(int[] array){
for (int j = array.length; j >0 ; j--) {
int max = array[0];//记录当前循环中最大的数
int maxIndex=0;//记录当前循环中最大的数的下边
for (int i = 0; i < j; i++) {
if (max<array[i]){
max=array[i];
maxIndex=i;
}
}
array[maxIndex]=array[j-1];
array[j-1]=max;
}
}特性总结:
- 直接选择排序思考非常好理解,但是效率不是很好(不论数组是否有序都会执行原步骤)。实际中很少使用
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:不稳定
前置知识:
1.二叉堆:(1)是完全二叉树或近似完全二叉树(2)父节点键值均大于子节点键值或父节点键值均小于子节点键值(3)子树也是二叉堆
2.大顶堆:父节点键值均大于子节点键值的二叉堆
3.小顶堆:父节点键值均小于子节点键值的二叉堆
堆排序思路:
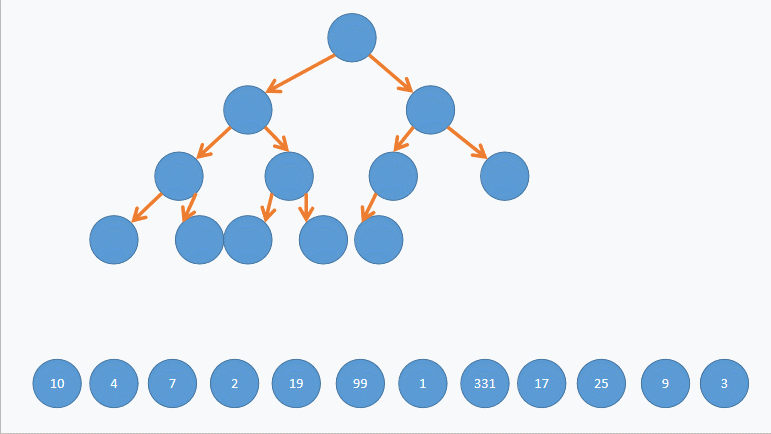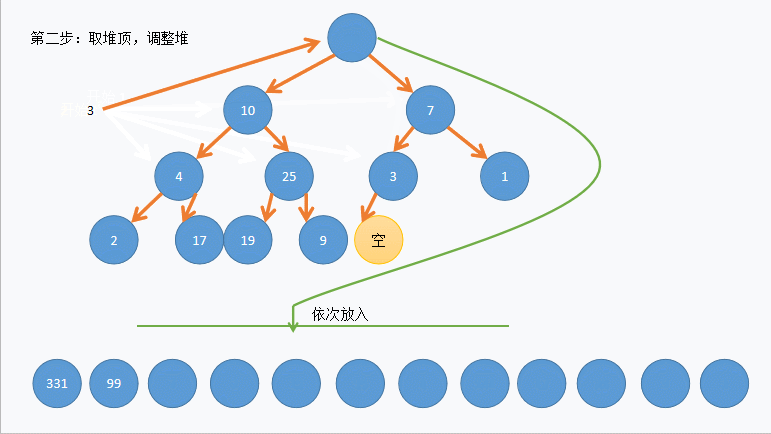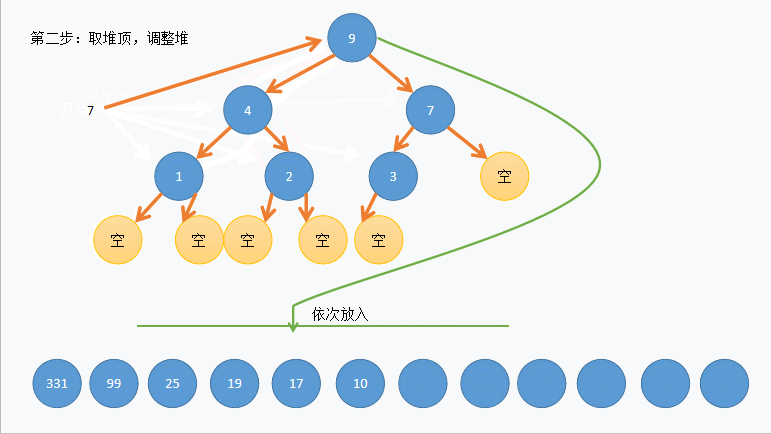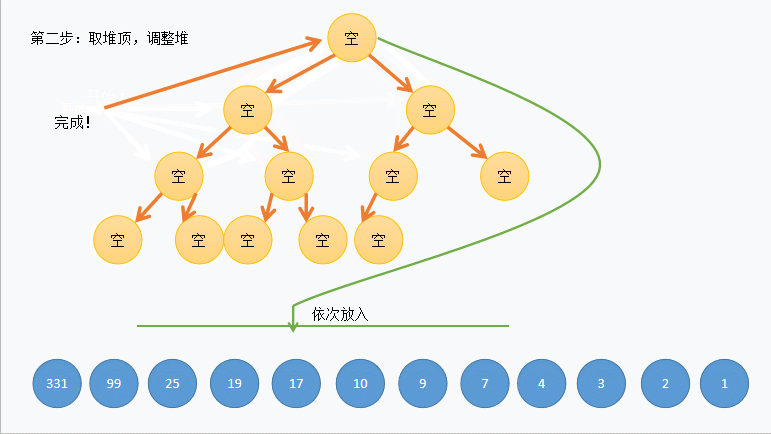
给定了一个杂乱无章的数组,可以将其转化成一个完全二叉树或近似完全二叉树。然后再堆化(可以转成大顶堆也可以转化成小顶堆);以大顶堆为例:大顶堆顶点元素必然是所有元素中最大的,先将其与当前数组(也是当前大顶堆最后一个元素)进行交换;交换完之后数组最后一个元素为所有数中最大值;除去此时二叉堆最后一个元素(最大值)再进行大顶堆化,一直循环到最后一个元素,这便是一次次将本趟最大值放到了本趟数组最后位置,也就排好了序。
示例
这里以升序为例:
- 首先应该建一个大堆,不能直接使用堆来实现。可以将需要排序的数组看作是一个堆,但需要将数组结构变成堆。
- 我们可以从堆从下往上的第二行最右边开始依次向下调整直到调整到堆顶,这样就可以将数组调整成一个堆,且如果建立的是大堆,堆顶元素为最大值。
- 然后按照堆删的思想将堆顶和堆底的数据交换,但不同的是这里不删除最后一个元素。
- 这样最大元素就在最后一个位置,然后从堆顶向下调整到倒数第二个元素,这样次大的元素就在堆顶,重复上述步骤直到只剩堆顶时停止。
动图演示:
注意:实际中并没有删除堆中元素,图中为了方便表示,将交换后的位置画成了空。
Java代码实现
大顶堆化为例:
public class small {
public static void main(String[] args) {
int []a= {12,7,11,3,6,8,9};
HeapSort(a);//堆排序
System.out.println("堆排序后");
for(int i=0;i<a.length;i++)
{
System.out.print(a[i]+" ");
}
}
private static void HeapSort(int[] a) {
// TODO Auto-generated method stub
//1.堆化成大顶堆
MaxHeap(a);
int n=a.length;//数组长度
//2.排序
for(int i=n-1;i>=0;i--)
{
int term=a[i];
a[i]=a[0];
a[0]=term;
MaxHeapFixDown(a, 0, i);//向下堆化
}
}
//大顶堆化
private static void MaxHeap(int[] a) {
// TODO Auto-generated method stub
int n=a.length;
for(int i=n/2-1;i>=0;i--)//从倒数第二层的最后一个节点开始往上不断调整,因为最底的一层是叶子节点,不需要调整
{
MaxHeapFixDown(a,i,n);
}
}
//大顶堆化向下调整
private static void MaxHeapFixDown(int[] a, int i, int n) {
// TODO Auto-generated method stub
int left=2*i+1;//左儿子
int right=2*i+2;//右儿子
if(left>=n)
{
return;//下标越界,意味着没有儿子
}
//走到这里了,意味着有左儿子
int max=left;//暂时定此时两者中数值较大的是左儿子下标
if(right>=n)
{
max=left;//此时不存在右儿子,所以两者中较大的那个数的下标是左儿子---------实锤
}
else {//此时左右儿子都存在
if(a[right]>a[left])
{
max=right;//如果右儿子大,便取代max
}
}
//至此,儿子中数值最大的儿子已经求出
if(a[max]>a[i])//儿子中较大的那个与本来顶部比较,有比顶部大的才交换
{
int term=a[i];
a[i]=a[max];
a[max]=term;
}
MaxHeapFixDown(a, max, n);//递归地将此棵树下面的子树也调整一下,因为你调换之后,只能保证最近的三个节点满足大顶堆
}
}
小顶堆化为例:
public class Big {
public static void main(String[] args) {
int []a= {12,7,11,3,6,8,9};
HeapSort(a);
System.out.println("堆排序后");
for(int i=a.length-1;i>=0;i--)
{
System.out.print(a[i]+" ");
}
}
private static void HeapSort(int[] a) {
// TODO Auto-generated method stub
MinHeap(a);
int n=a.length;
for(int i=n-1;i>=0;i--)
{
int term=a[i];
a[i]=a[0];
a[0]=term;
MinHeapFixDown(a, 0, i);//每次都是从0开始向下堆化
}
}
//小顶堆化
private static void MinHeap(int[] a) {
// TODO Auto-generated method stub
int n=a.length;
for(int i=n/2-1;i>=0;i--)
{
MinHeapFixDown(a,i,n);//向下小顶堆化
}
}
private static void MinHeapFixDown(int[] a, int i, int n)
{
// TODO Auto-generated method stub
//先找左右孩子
int left=2*i+1;
int right=2*i+2;
if(left>=n)//没有左孩子
{
return;
}
int min=left;//目前暂定两个儿子当中最小下标是左孩子
if(right>=n)
{
min=left;
}
else
{
if(a[right]<a[left])
{
min=right;
}
}
//到此已经找到了两个儿子中较小的那一个的下标
if(a[min]<a[i])
{
int term=a[min];
a[min]=a[i];
a[i]=term;
}
//交换之后,当前以i为父节点的子树便成了小顶堆
MinHeapFixDown(a, min, n);//看看min为父节点的树是否满足小顶堆,继续递归调整
}
}
4.冒泡排序
排序思想:
两两元素相比,前一个比后一个大就交换,直到将最大的元素交换到末尾位置。这是第一趟
一共进行n-1趟这样的交换将可以把所有的元素排好。
(n-1趟是因为只剩两个元素时只需要一趟就可以完成)
特性总结
时间复杂度:最好情况是O(n),最坏情况是O(n^2)
稳定性:稳定
示例
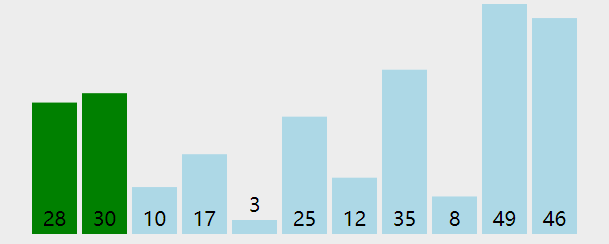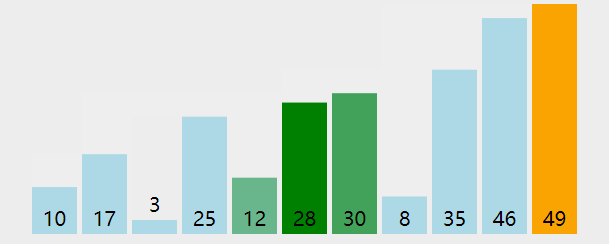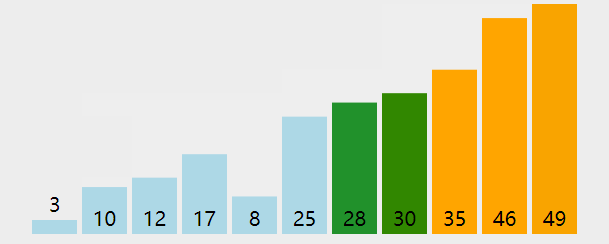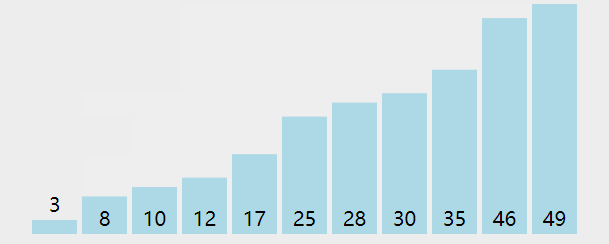
Java代码实现
public static void maopao(int [] a){
for (int i = 0; i < a.length-1; i++) {
for (int j = 0; j < a.length - i-1; j++) {
if(a[j+1]<a[j]){
int temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
}
}
}
}5.快速排序
基本思想
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
特性总结
稳定性:不稳定
示例
以一个数组作为示例,取区间第一个数为基准数。
初始时,left = 0; right = 9; temp = a[i] = 72
由于已经将 a[0] 中的数保存到 temp 中,可以理解成在数组 a[0] 上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比temp小或等于temp的数。当right=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; left++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于temp的数,当left=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; right–;
数组变为:

left = 3; right = 7; temp=72
再重复上面的步骤,先从后向前找,再从前向后找。
从right开始向前找,当right=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; left++;
从i开始向后找,当left=5时,由于left==right退出。
此时,left = right = 5,而a[5]刚好又是上次挖的坑,因此将temp填入a[5]。
数组变为:
可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了。
对挖坑填数进行总结:
1.left =L; right = R; 将基准数挖出形成第一个坑a[left]。
2.right–由后向前找比它小的数,找到后挖出此数填前一个坑a[left]中。
3.left++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[right]中。
4.再重复执行2,3二步,直到 left==right,将基准数填入a[left]中。
Java代码实现
/**
* 快速排序算法
*/
public class QuickSort {
public static void quickSort(int[] array){
if (array == null || array.length < 2) {
return; //array为空或者该数组元素为一,没有排序的意义
}
quickSort(array, 0, array.length - 1);
}
private static void quickSort(int[] array, int l, int r) {
if ( l >= r){
return; //数据不合法,退出程序
}
//要向使l --> r中有序,先找到一个基准数,取数组的最后一个数为基准数
int num = array[r];
//找到基准数在数组中的位置,使得 < 基准数的在左边 ,等于基准数的在中间, > 基准数的在右边。
int[] index = quick_sort(array, l, r,num); //此时中间的 = sum的已经拍好序了
quickSort(array,l,index[0]); //使左边的有序
quickSort(array,index[1],r); //使右边的有序
}
private static int[] quick_sort(int[] array, int l, int r, int num) {
//找到基准数在数组中的位置,使得 < 基准数的在左边 ,等于基准数的在中间, > 基准数的在右边。
int p1 = l - 1;
int p2 = r + 1;
while (l < p2) {
if (array[l] < num){
//1.第一种情况,如果小于num的时候,将该元素与 < 范围的前一个交换,i++
int temp = array[l];
array[l] = array[p1 + 1];
array[p1 + 1] = temp;
l++;
p1++;
}else if (array[l] == num){
//2.第二种情况,如果[l]==sum的时候,l++
l++;
}else {
//3.第三种情况,如果[l] > sum的时候,[l] 与 > 范围的前一个元素交换
int temp = array[l];
array[l] = array[p2 - 1];
array[p2 - 1] = temp;
p2--;
}
}
return new int[]{p1,p2}; //此时中间的 = sum的已经拍好序了、
}
public static void main(String[] args) {
int[] array = new int[]{1,5,3,6,3,5,8,10,3};
quickSort(array);
for (int i : array) {
System.out.println(i);
}
}
}
归并排序
归并排序的思想是分治
示例
下面详细讲解归并排序
假设又这样一个数组,

当我们要排序这个数组的时候,归并排序法首先将这个数组分成一半。
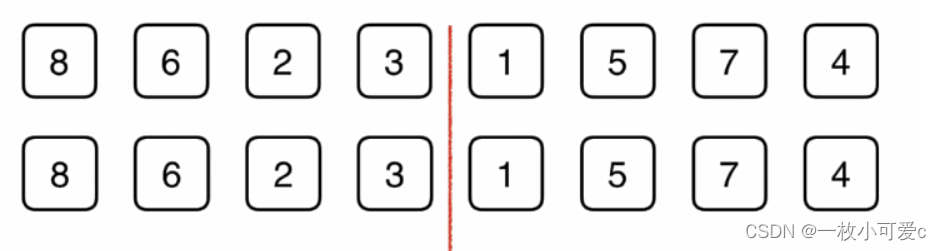
然后想办法把左边的数组给排序,右边的数组给排序,之后呢再将它们归并起来。当然了当我们对左边的数组和右边的素组进行排序的时候,再分别将左边的数组和右边的数组分成一半,然后对每一个部分先排序,再归并。

对于上面的每一个部分呢,我们依然是先将他们分半,再归并
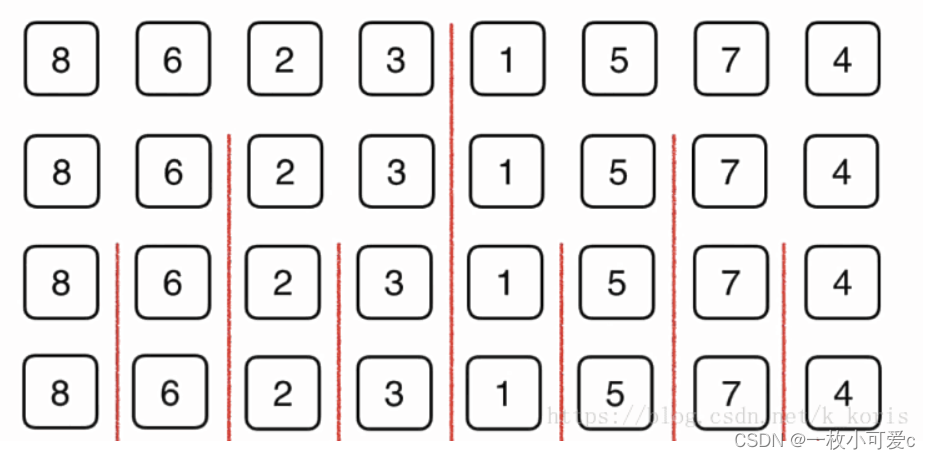
分到一定细度的时候,每一个部分就只有一个元素了,那么我们此时不用排序,对他们进行一次简单的归并就好了。

归并到上一个层级之后继续归并,归并到更高的层级
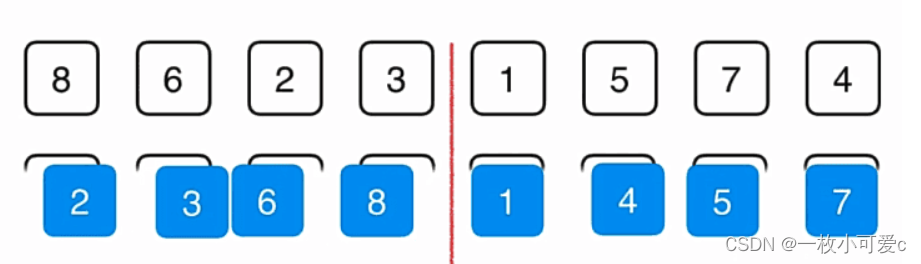
直至最后完成归并

Java归并排序代码
import java.util.Arrays;
/**
* 归并排序
*/
public class MergeSort {
// 将arr[l...mid]和arr[mid+1...r]两部分进行归并
private static void merge(Comparable[] arr, int l, int mid, int r) {
Comparable[] aux = Arrays.copyOfRange(arr, l, r + 1);
// 初始化,i指向左半部分的起始索引位置l;j指向右半部分起始索引位置mid+1
int i = l, j = mid + 1;
for (int k = l; k <= r; k++) {
if (i > mid) { // 如果左半部分元素已经全部处理完毕
arr[k] = aux[j - l];
j++;
} else if (j > r) { // 如果右半部分元素已经全部处理完毕
arr[k] = aux[i - l];
i++;
} else if (aux[i - l].compareTo(aux[j - l]) < 0) { // 左半部分所指元素 < 右半部分所指元素
arr[k] = aux[i - l];
i++;
} else { // 左半部分所指元素 >= 右半部分所指元素
arr[k] = aux[j - l];
j++;
}
}
}
// 递归使用归并排序,对arr[l...r]的范围进行排序
private static void sort(Comparable[] arr, int l, int r) {
if (l >= r) {
return;
}
int mid = (l + r) / 2;
sort(arr, l, mid);
sort(arr, mid + 1, r);
// 对于arr[mid] <= arr[mid+1]的情况,不进行merge
// 对于近乎有序的数组非常有效,但是对于一般情况,有一定的性能损失
if (arr[mid].compareTo(arr[mid + 1]) > 0)
merge(arr, l, mid, r);
}
public static void sort(Comparable[] arr) {
int n = arr.length;
sort(arr, 0, n - 1);
}
// 测试MergeSort
public static void main(String[] args) {
int N = 20;
Integer[] arr = SortTestHelper.generateRandomArray(N, 0, 100000);
sort(arr);
//打印数组
SortTestHelper.printArray(arr);
}
}基排序
基本思想
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。
具体做法是:将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
示例
通过基数排序对数组{53, 3, 542, 748, 14, 214, 154, 63, 616},它的示意图如下

在上图中,首先将所有待比较数值统一为统一位数长度,接着从最低位开始,依次进行排序。
1. 按照个位数进行排序。
2. 按照十位数进行排序。
3. 按照百位数进行排序。
排序后,数列就变成了一个有序序列。
特性总结
时间复杂度:平均O(n*k),最好O(n*k),最坏O(n*k)
空间复杂度:O(n+k)
稳定性:稳定
Java实现代码
public class RadixSort {
public static void main(String[] args) {
// int[] arr = {53, 3, 542, 748, 14, 214};
int[] arr = new int[8];
for (int i = 0; i < 8; i++) {
arr[i] = (int) (Math.random() * 8000000);
}
radixSOrt(arr);
System.out.println(Arrays.toString(arr));
}
public static void radixSOrt(int[] arr) {
//1.得到数组中最大的数的位数
//假设第一个数是最大的数
int max = arr[0];
for (int i = 1; i < arr.length; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
int maxLength = String.valueOf(max).length();
/*
定义一个二维数组,表示10个桶,每个桶就是一个一维数组
1.二维数组包好10个一维数组
2.为了防止放入数据时溢出,规定每个桶的大小为 arr.length
3.基数排序是使用空间换时间的经典算法
*/
int[][] bucket = new int[10][arr.length];
//为了记录每个桶中实际上放了多少个数据,定义一个一维数组来记录各个桶的每次放入
//数据的个数
int[] bucketElementCounts = new int[10];
for (int i = 0, n = 1; i < maxLength; i++, n *= 10) {
//往桶中存数据,第一次是个位,第二次是十位,依次类推
for (int j = 0; j < arr.length; j++) {
//取对应位置上的数
int digitOfElement = arr[j] / n % 10;
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];
bucketElementCounts[digitOfElement]++;
}
//按照桶的顺序取数据
int index = 0;
for (int k = 0; k < bucketElementCounts.length; k++) {
//当桶中有数据
if (bucketElementCounts[k] != 0) {
for (int l = 0; l < bucketElementCounts[k]; l++) {
arr[index++] = bucket[k][l];
}
}
//从桶中取完数据后将其数据个数置为0
bucketElementCounts[k] = 0;
}
}
}
}















 842
842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









