







版权声明:本文为我很帅的原创文章,想要转载联系我哦。 https://blog.csdn.net/u010111016/article/details/50821071 </div>
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-cd6c485e8b.css">
<div id="content_views" class="markdown_views prism-atom-one-dark">
<!-- flowchart 箭头图标 勿删 -->
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;">
<path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path>
</svg>
<p>目前推荐系统中用的最多的就是矩阵分解方法,在Netflix Prize推荐系统大赛中取得突出效果。以用户-项目评分矩阵为例,矩阵分解就是预测出评分矩阵中的缺失值,然后根据预测值以某种方式向用户推荐。常见的矩阵分解方法有基本矩阵分解(basic MF),正则化矩阵分解)(Regularized MF),基于概率的矩阵分解(PMF)等。今天以“用户-项目评分矩阵R(N×M)”说明三种分解方式的原理以及应用。</p>
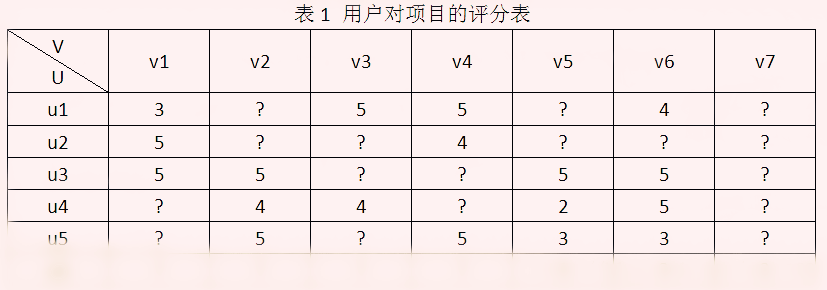
Basic MF:
Basic MF是最基础的分解方式,将评分矩阵R分解为用户矩阵U和项目矩阵S, 通过不断的迭代训练使得U和S的乘积越来越接近真实矩阵,矩阵分解过程如图:
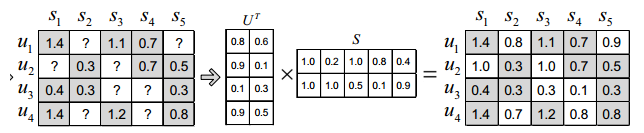
预测值接近真实值就是使其差最小,这是我们的目标函数,然后采用梯度下降的方式迭代计算U和S,它们收敛时就是分解出来的矩阵。我们用损失函数来表示误差(等价于目标函数):
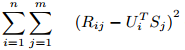
公式1中R_ij是评分矩阵中已打分的值,U_i和S_j相当于未知变量。为求得公式1的最小值,相当于求关于U和S二元函数的最小值(极小值或许更贴切)。通常采用梯度下降的方法:
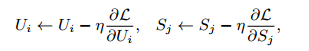
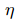
Regularized MF
正则化矩阵分解是Basic MF的优化,解决MF造成的过拟合问题。其不是直接最小化损失函数,而是在损失函数基础上增加规范化因子,将整体作为损失函数。
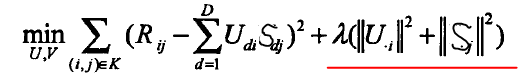
红线表示正则化因子,在求解U和S时,仍然采用梯度下降法,此时迭代公式变为:(图片截取自相关论文,S和V等价)
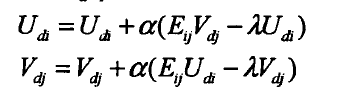
其中, 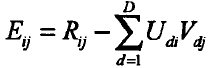
梯度下降结束条件:f(x)的真实值和预测值小于自己设定的阈值(很小的值,之前一直理解为是变量U和V的迭代值差小于阈值就行,弄了一天才懂。)
- PMF
基于概率的矩阵分解,在下一篇博文里。














 722
722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









