







一.使用决策树预测隐形眼镜类型
这里实现一个例子,即利用决策树预测一个患者需要佩戴的隐形眼镜类型。以下是整个预测的大体步骤:
收集数据:使用书中提供的小型数据集
准备数据:对文本中的数据进行预处理,如解析数据行
分析数据:快速检查数据,并使用
createPlot()函数绘制最终的树形图训练决策树:使用
createTree()函数训练测试决策树:编写简单的测试函数验证决策树的输出结果&绘图结果
使用决策树:这部分可选择将训练好的决策树进行存储,以便随时使用
此处新建脚本文件
saveTree.py,将训练好的决策树保存在磁盘中,这里需要使用Python模块的pickle序列化对象。storeTree()函数负责把tree存放在当前目录下的filename(.txt)文件中,而getTree(filename)则是在当前目录下的filename(.txt)文件中读取决策树的相关数据。
"""
Created on Fri Mar 09 10:36 2018
@author: AlanSmith
"""
import pickle
def storeTree(tree, filename):
fw = open(filename, 'w')
pickle.dump(tree, fw)
fw.close()
def getTree(filename):
fr = open(filename)
return pickle.load(fr)以下代码实现了决策树预测隐形眼镜模型的实例,使用的数据集是隐形眼镜数据集,它包含很多患者的眼部状况的观察条件以及医生推荐的隐形眼镜类型,其中隐形眼镜类型包括:硬材质(hard)、软材质(soft)和不适合佩戴隐形眼镜(no lenses) , 数据来源于UCI数据库。数据集包含下面几个特征:age(年龄), prescript(近视还是远视), astigmatic(散光), tearRate(眼泪清除率)。代码最后调用了之前准备好的createPlot()函数绘制树形图。
"""
Created on Fri Mar 09 10:50 2018
@author: AlanSmith
"""
import DecisionTree_Tree1
import DecisionTree_PlotTree2
import DecisionTree_SaveTree3
fr = open('/Users/Administrator/Desktop/MLiA_SourceCode/machinelearninginaction/Ch03/lenses.txt')
lensesData = [data.strip().split('\t') for data in fr.readlines()]
lensesLabel = ['age', 'prescript', 'astigmatic', 'tearRate']
lensesTree = DecisionTree_Tree1.createTree(lensesData, lensesLabel)
print(lensesData)
print(lensesTree)
print(DecisionTree_PlotTree2.createPlot(lensesTree))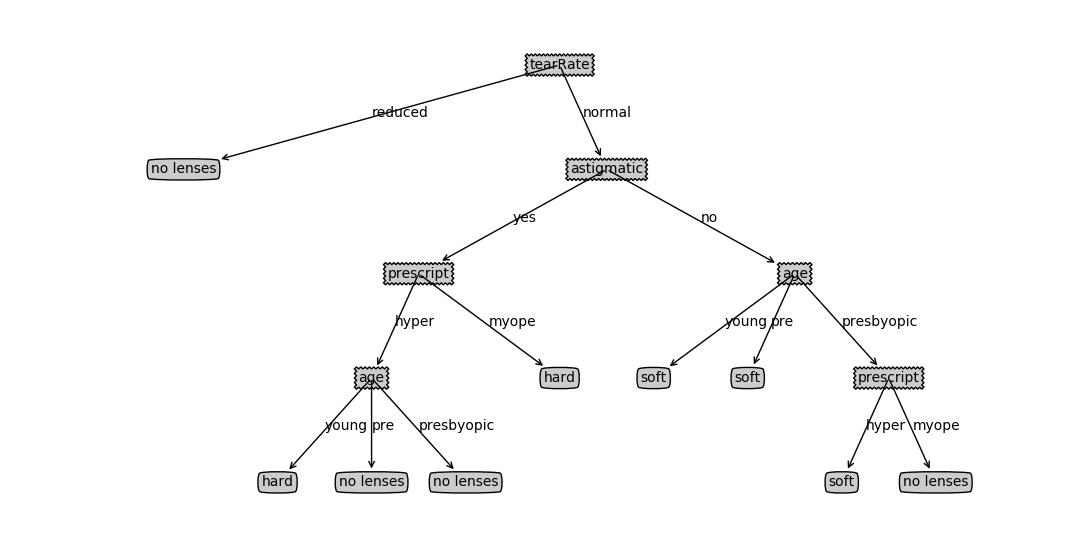
二.关于本章使用的决策树的总结
以上代码的实现基于ID3决策树构造算法,它是一个非常经典的算法,然而实际上决策树的使用中常常会遇到一个问题,即“过度匹配”。有时候,过多的分支选择或匹配选项会给决策带来负面的效果。为了减少过度匹配的问题,通常算法设计者会在一些实际情况中选择“剪枝”。简单说来,如果叶子节点只能增加少许信息,则可以删除该节点。















 396
396











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









