







目录
一、pandas简介
1.1 为什么学习pandas
numpy已经可以帮助我们进行数据的处理了,那么学习pandas的目的是什么呢?
numpy能够帮助我们处理的是数值型的数据,当然在数据分析中除了数值型的数据还有好多其他类型的数据(字符串,时间序列),那么pandas就可以帮我们很好的处理除了数值型的其他数据!
1.2 什么是pandas?
首先先来认识pandas中的两个常用的类
- Series
- DataFrame
1.3 环境搭建
pip install pandas二、Series(一维)
Series是一种类似与一维数组的对象,由下面两个部分组成:
- values:一组数据(ndarray类型)
- index:相关的数据索引标签
2.1 Series的创建
- 由列表或numpy数组创建
- 由字典创建
from pandas import Series
import numpy as np
# 1、列表创建Series
s = Series(data=[1, 2, 3, 'four'])
print(s)
# 2、numpy创建Series
s1 = Series(data=np.random.randint(0, 100, size=(3,)))
print(s1)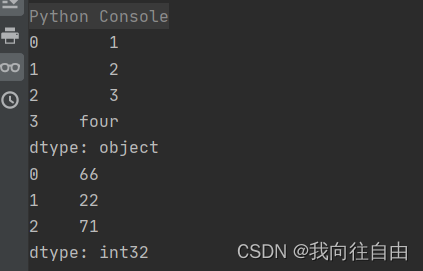
2.2 Series索引和切片
from pandas import Series
# index用来指定显示索引
s = Series(data=[1, 2, 3, 'four'], index=['a', 'b', 'c', 'd'])
print(s)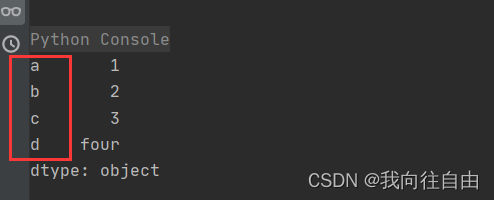
为什么需要有显示索引?
显示索引可以增强Series的可读性。
比如:
from pandas import Series
dic = {
'语文': 100,
'数学': 99,
'英语': 80
}
s = Series(data=dic)
print(s)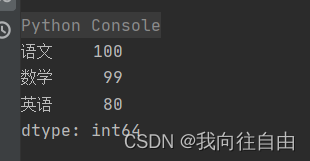
from pandas import Series
dic = {
'语文': 100,
'数学': 99,
'英语': 80
}
s = Series(data=dic)
print(s.语文)
print(s[0])
print(s[0:2])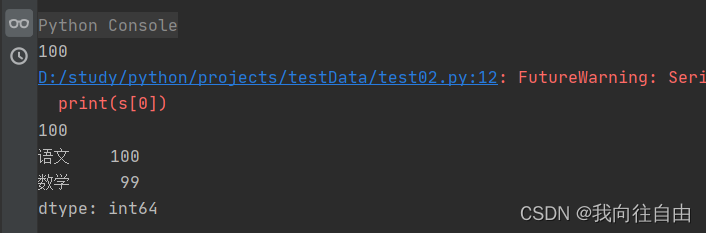
2.3 Series的常用属性
- shape:返回形状
- size:返回元素个数
- index:返回索引
- values:返回值
- dtype:返回元素类型
from pandas import Series
dic = {
'语文': 100,
'数学': 99,
'英语': 80
}
s = Series(data=dic)
print(s.values)
2.4 Series的常用方法
- head(),tail()
- unique()
- isnull(),notnull()
- add() sub() mul() div()
from pandas import Series
import numpy as np
s = Series(data=np.random.randint(60, 100, size=(10,)))
# 显示前3个数据
print(s.head(3))
# 显示后3个数据
print(s.tail(3))
# 去重
print(s.unique())
# 判断每一个元素是否为空,为空返回True,否则返回False
print(s.isnull())
三、DataFrame(多维)
DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values
3.1 DataFrame的创建
- ndarray创建
- 字典创建
from pandas import Series, DataFrame
import numpy as np
df = DataFrame(data=[[1, 2, 3], [4, 5, 6]])
print(df)
# 创建6行4列的二维数组
df_1 = DataFrame(data=np.random.randint(0, 100, size=(6, 4)))
print(df_1)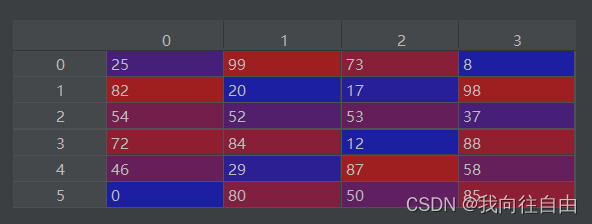
dic = {
'name': ['苏格拉底', '柏拉图', '亚里士多德'],
'salary': [1000, 2000, 3000]
}
df_2 = DataFrame(data=dic)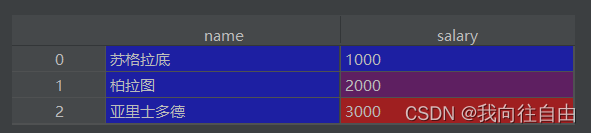
3.2 DataFrame的属性
- values
- columns
- index
- shape
3.3 索引&切片
创建二维数组
from pandas import Series, DataFrame
import numpy as np
df = DataFrame(data=np.random.randint(60, 100, size=(8, 4)), columns=['a', 'b', 'c', 'd'])
取单列
df = DataFrame(data=np.random.randint(60, 100, size=(8, 4)), columns=['a', 'b', 'c', 'd'])
# 取单列,如果df有显示的索引,通过索引机制去行或者列的时候可以使用显示索引
df['a']
取多列
df[['a', 'c']] # 取多列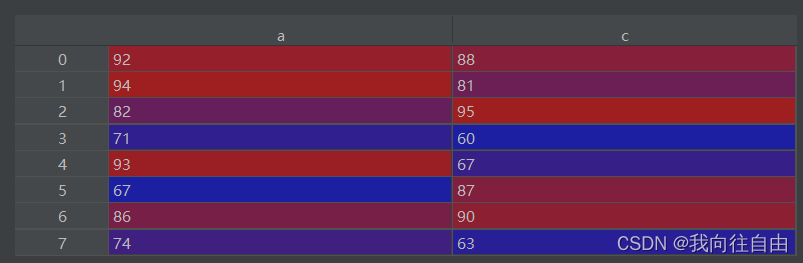
取单行
- iloc:
- 通过隐式索引取行
- loc:
- 通过显示索引取行
df.iloc[0]
取多行
df.iloc[[0, 3, 5]]
获取指定行列数据
# 取0行3列的数据
df.iloc[0,3]对行进行切片
源数据
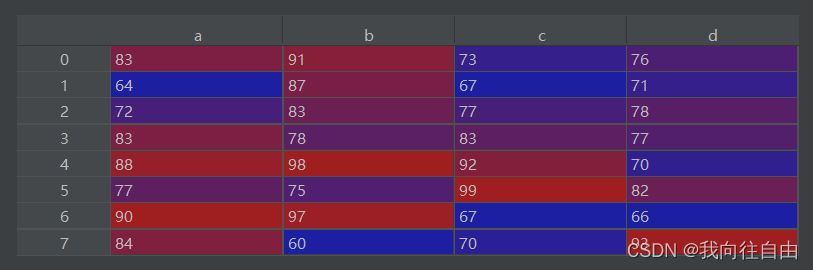
# 取前两行
df[0:2]对列进行切片
# 取前两列
df.iloc[:,0:2]
总结
df索引和切片操作
- 索引:
- df[col]:取列
- df.loc[index]:取行
- df.iloc[index,col]:取元素
- 切片:
- df[index1:index3]:切行
- df.iloc[:,col1:col3]:切列
时间类型
时间数据类型的转换
- pd.to_datetime(col)
from pandas import Series, DataFrame
import pandas as pd
dic = {
'time': ['2020-10-10', '2011-11-20', '2020-01-05'],
'temp': [33, 31, 30]
}
df = DataFrame(data=dic)
# 将time列的字符串类型转成时间类型
df['time'] = pd.to_datetime(df['time'])
print(df['time'].dtype)

将某一列设置为行索引
- df.set_index()
from pandas import Series, DataFrame
import pandas as pd
dic = {
'time': ['2020-10-10', '2011-11-20', '2020-01-05'],
'temp': [33, 31, 30]
}
df = DataFrame(data=dic)
# 将time列的作为源数据的行索引
df.set_index('time', inplace=True)

















 8775
8775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











