






一、错误和异常
Python 有两种错误很容易辨认:语法错误和异常。
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
1.1、语法错误
Python 的语法错误或者称之为解析错,是初学者经常碰到的,如下实例
>>> while True print('Hello world')
File "<stdin>", line 1, in ?
while True print('Hello world')
^
SyntaxError: invalid syntax
这个例子中,函数 print() 被检查到有错误,是它前面缺少了一个冒号 : 。
语法分析器指出了出错的一行,并且在最先找到的错误的位置标记了一个小小的箭头。
1.2、异常
即便 Python 程序的语法是正确的,在运行它的时候,也有可能发生错误。运行期检测到的错误被称为异常。
大多数的异常都不会被程序处理,都以错误信息的形式展现在这里:
>>> 10 * (1/0) # 0 不能作为除数,触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ZeroDivisionError: division by zero
>>> 4 + spam*3 # spam 未定义,触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in ?
NameError: name 'spam' is not defined
>>> '2' + 2 # int 不能与 str 相加,触发异常
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str
异常以不同的类型出现,这些类型都作为信息的一部分打印出来: 例子中的类型有 ZeroDivisionError,NameError 和 TypeError。
错误信息的前面部分显示了异常发生的上下文,并以调用栈的形式显示具体信息。
1.3、异常处理
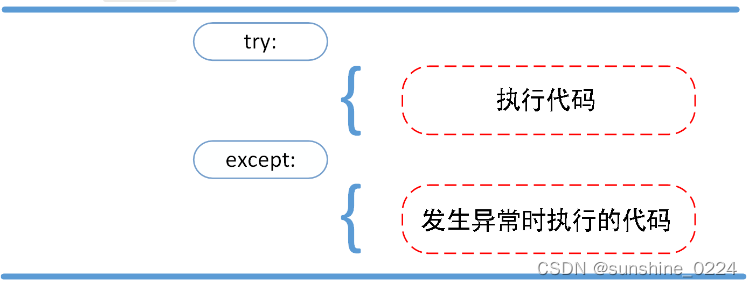
13.1、异常捕捉可以使用 try/except 语句。
以下例子中,让用户输入一个合法的整数,但是允许用户中断这个程序(使用 Control-C 或者操作系统提供的方法)。用户中断的信息会引发一个 KeyboardInterrupt 异常。
while True:
try:
x = int(input("请输入一个数字: "))
break
except ValueError:
print("您输入的不是数字,请再次尝试输入!")
try 语句按照如下方式工作;
-
首先,执行 try 子句(在关键字 try 和关键字 except 之间的语句)。
-
如果没有异常发生,忽略 except 子句,try 子句执行后结束。
-
如果在执行 try 子句的过程中发生了异常,那么 try 子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的 except 子句将被执行。
-
如果一个异常没有与任何的 except 匹配,那么这个异常将会传递给上层的 try 中。
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。
处理程序将只针对对应的 try 子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。
一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组,例如:
except (RuntimeError, TypeError, NameError):
pass
最后一个except子句可以忽略异常的名称,它将被当作通配符使用。你可以使用这种方法打印一个错误信息,然后再次把异常抛出。
import sys
try:
f = open('myfile.txt')
s = f.readline()
i = int(s.strip())
except OSError as err:
print("OS error: {0}".format(err))
except ValueError:
print("Could not convert data to an integer.")
except:
print("Unexpected error:", sys.exc_info()[0])
raise
1、sys.exc_info()方法
使用 sys 模块中的 exc_info() 方法获取异常信息
exc_info() 方法会将当前的异常信息以元组的形式返回,该元组中包含 3 个元素,分别为 type、value 和 traceback,它们的含义分别是:
type:异常类型的名称,它是 BaseException 的子类
value:捕获到的异常实例。
traceback:是一个 traceback 对象。
举例:
#使用 sys 模块之前,需使用 import 引入
import sys
try:
x = int(input("请输入一个被除数:"))
print("30除以",x,"等于",30/x)
except:
print(sys.exc_info())
print("其他异常...")
当输入 0 时,程序运行结果为:
请输入一个被除数:0
(<class 'ZeroDivisionError'>, ZeroDivisionError('division by zero',), <traceback object at 0x000001FCF638DD48>)
其他异常...
输出结果中,第 2 行是抛出异常的全部信息,这是一个元组,有 3 个元素,第一个元素是一个 ZeroDivisionError 类;第 2 个元素是异常类型 ZeroDivisionError 类的一个实例;第 3 个元素为一个 traceback 对象。其中,通过前 2 个元素可以看出抛出的异常类型以及描述信息,对于第 3 个元素,是一个 traceback 对象,无法直接看出有关异常的信息,还需要对其做进一步处理。
2、traceback .print_tb 方法
要查看 traceback 对象包含的内容,需要先引进 traceback 模块,然后调用 traceback 模块中的 print_tb 方法,并将 sys.exc_info() 输出的 traceback 对象作为参数参入。例如:
#使用 sys 模块之前,需使用 import 引入
import sys
#引入traceback模块
import traceback
try:
x = int(input("请输入一个被除数:"))
print("30除以",x,"等于",30/x)
except:
#print(sys.exc_info())
traceback.print_tb(sys.exc_info()[2])
print("其他异常...")
输入 0,程序运行结果为:
请输入一个被除数:0
File "C:\Users\mengma\Desktop\demo.py", line 7, in <module>
print("30除以",x,"等于",30/x)
其他异常...
可以看到,输出信息中包含了更多的异常信息,包括文件名、抛出异常的代码所在的行数、抛出异常的具体代码。
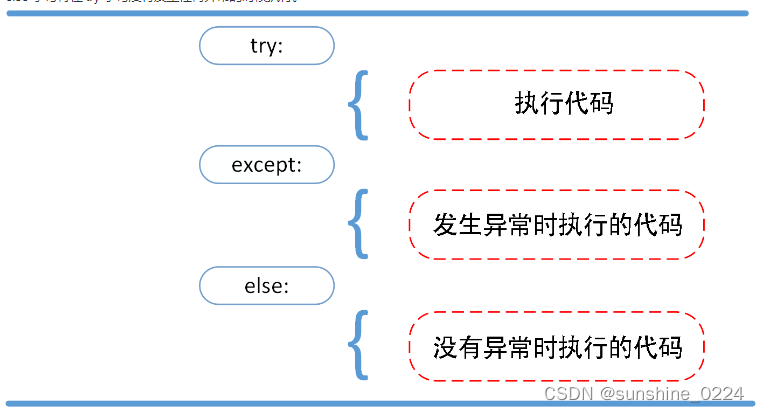
1.3.2、try/except...else
try/except 语句还有一个可选的 else 子句,如果使用这个子句,那么必须放在所有的 except 子句之后。
else 子句将在 try 子句没有发生任何异常的时候执行。
使用 else 包裹的代码,只有当 try 块没有捕获到任何异常时,才会得到执行;反之,如果 try 块捕获到异常,即便调用对应的 except 处理完异常,else 块中的代码也不会得到执行。
以下实例在 try 语句中判断文件是否可以打开,如果打开文件时正常的没有发生异常则执行 else 部分的语句,读取文件内容:
for arg in sys.argv[1:]:
try:
f = open(arg, 'r')
except IOError:
print('cannot open', arg)
else:
print(arg, 'has', len(f.readlines()), 'lines')
f.close()
使用 else 子句比把所有的语句都放在 try 子句里面要好,这样可以避免一些意想不到,而 except 又无法捕获的异常。
异常处理并不仅仅处理那些直接发生在 try 子句中的异常,而且还能处理子句中调用的函数(甚至间接调用的函数)里抛出的异常。
1.3.3、try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。

1.3.4、抛出(引发)异常
Python 使用 raise 语句抛出一个指定的异常。
raise语法格式如下:
raise [Exception [, args [, traceback]]]
以下实例如果 x 大于 5 就触发异常:
x = 10
if x > 5:
raise Exception('x 不能大于 5。x 的值为: {}'.format(x))
执行以上代码会触发异常:
Traceback (most recent call last):
File "test.py", line 3, in <module>
raise Exception('x 不能大于 5。x 的值为: {}'.format(x))
Exception: x 不能大于 5。x 的值为: 10
raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。
如果你只想知道这是否抛出了一个异常,并不想去处理它,那么一个简单的 raise 语句就可以再次把它抛出。
>>> try:
raise NameError('HiThere') # 模拟一个异常。
except NameError:
print('An exception flew by!')
raise
An exception flew by!
Traceback (most recent call last):
File "<stdin>", line 2, in ?
NameError: HiThere
1.3.5、用户自定义异常
你可以通过创建一个新的异常类来拥有自己的异常。异常类继承自 Exception 类,可以直接继承,或者间接继承,例如:
>>> class MyError(Exception):
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)
>>> try:
raise MyError(2*2)
except MyError as e:
print('My exception occurred, value:', e.value)
My exception occurred, value: 4
>>> raise MyError('oops!')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
__main__.MyError: 'oops!'
在这个例子中,类 Exception 默认的 __init__() 被覆盖。
当创建一个模块有可能抛出多种不同的异常时,一种通常的做法是为这个包建立一个基础异常类,然后基于这个基础类为不同的错误情况创建不同的子类:
class Error(Exception):
"""Base class for exceptions in this module."""
pass
class InputError(Error):
"""Exception raised for errors in the input.
Attributes:
expression -- input expression in which the error occurred
message -- explanation of the error
"""
def __init__(self, expression, message):
self.expression = expression
self.message = message
class TransitionError(Error):
"""Raised when an operation attempts a state transition that's not
allowed.
Attributes:
previous -- state at beginning of transition
next -- attempted new state
message -- explanation of why the specific transition is not allowed
"""
def __init__(self, previous, next, message):
self.previous = previous
self.next = next
self.message = message
大多数的异常的名字都以"Error"结尾,就跟标准的异常命名一样。
1.3.6、定义清理行为
try 语句还有另外一个可选的子句,它定义了无论在任何情况下都会执行的清理行为。 例如:
>>> try:
... raise KeyboardInterrupt
... finally:
... print('Goodbye, world!')
...
Goodbye, world!
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
KeyboardInterrupt
以上例子不管 try 子句里面有没有发生异常,finally 子句都会执行。
如果一个异常在 try 子句里(或者在 except 和 else 子句里)被抛出,而又没有任何的 except 把它截住,那么这个异常会在 finally 子句执行后被抛出。
1.3.7、预定义的清理行为
一些对象定义了标准的清理行为,无论系统是否成功的使用了它,一旦不需要它了,那么这个标准的清理行为就会执行。
下面这个例子展示了尝试打开一个文件,然后把内容打印到屏幕上:
for line in open("myfile.txt"):
print(line, end="")
以上这段代码的问题是,当执行完毕后,文件会保持打开状态,并没有被关闭。
关键词 with 语句就可以保证诸如文件之类的对象在使用完之后一定会正确的执行他的清理方法:
with open("myfile.txt") as f:
for line in f:
print(line, end="")
以上这段代码执行完毕后,就算在处理过程中出问题了,文件 f 总是会关闭。
二、面向对象
2.1、面向对象技术简介
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 方法:类中定义的函数。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
Python中的类提供了面向对象编程的所有基本功能:类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法。
对象可以包含任意数量和类型的数据。
2.2、类定义
语法格式如下:
class ClassName:
<statement-1>
. . .
<statement-N>
类实例化后,可以使用其属性,实际上,创建一个类之后,可以通过类名访问其属性。
2.3、类对象
类对象支持两种操作:属性引用和实例化。
属性引用使用和 Python 中所有的属性引用一样的标准语法:obj.name。
类对象创建后,类命名空间中所有的命名都是有效属性名。所以如果类定义是这样:
class MyClass:
"""一个简单的类实例"""
i = 12345
def f(self):
return 'hello world'
# 实例化类
x = MyClass()
# 访问类的属性和方法
print("MyClass 类的属性 i 为:", x.i)
print("MyClass 类的方法 f 输出为:", x.f())
以上创建了一个新的类实例并将该对象赋给局部变量 x,x 为空的对象。
执行以上程序输出结果为:
MyClass 类的属性 i 为: 12345 MyClass 类的方法 f 输出为: hello world
类有一个名为 __init__() 的特殊方法(构造方法),该方法在类实例化时会自动调用,像下面这样:
def __init__(self):
self.data = []
类定义了 __init__() 方法,类的实例化操作会自动调用 __init__() 方法。如下实例化类 MyClass,对应的 __init__() 方法就会被调用:
x = MyClass()
当然, __init__() 方法可以有参数,参数通过 __init__() 传递到类的实例化操作上。例如:
class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.r, x.i)
# 输出结果:3.0 -4.5
self代表类的实例,而非类
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self。
class Test:
def prt(self):
print(self)
print(self.__class__)
t = Test()
t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x100771878>
__main__.Test
从执行结果可以很明显的看出,self 代表的是类的实例,代表当前对象的地址,而 self.class 则指向类。
self 不是 python 关键字,我们把他换成 runoob 也是可以正常执行的:
class Test:
def prt(runoob):
print(runoob)
print(runoob.__class__)
t = Test()
t.prt()
以上实例执行结果为:
<__main__.Test instance at 0x100771878>
__main__.Test
2.4、类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self, 且为第一个参数,self 代表的是类的实例。
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
#定义类的方法
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
# 实例化类
p = people('runoob',10,30)
p.speak()
执行以上程序输出结果为:
runoob 说: 我 10 岁。
2.5、继承
Python 同样支持类的继承,如果一种语言不支持继承,类就没有什么意义。派生类的定义如下所示:
class DerivedClassName(BaseClassName):
<statement-1>
.
.
.
<statement-N>
子类(派生类 DerivedClassName)会继承父类(基类 BaseClassName)的属性和方法。
BaseClassName(实例中的基类名)必须与派生类定义在一个作用域内。除了类,还可以用表达式,基类定义在另一个模块中时这一点非常有用:
class DerivedClassName(modname.BaseClassName):
#!/usr/bin/python3
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
# 调用父类的构函
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
s = student('ken',10,60,3)
s.speak()
执行以上程序输出结果为:
ken 说: 我 10 岁了,我在读 3 年级
2.6、多继承
Python同样有限的支持多继承形式。多继承的类定义形如下例:
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
.
.
<statement-N>
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
#类定义
class people:
#定义基本属性
name = ''
age = 0
#定义私有属性,私有属性在类外部无法直接进行访问
__weight = 0
#定义构造方法
def __init__(self,n,a,w):
self.name = n
self.age = a
self.__weight = w
def speak(self):
print("%s 说: 我 %d 岁。" %(self.name,self.age))
#单继承示例
class student(people):
grade = ''
def __init__(self,n,a,w,g):
#调用父类的构造方法
people.__init__(self,n,a,w)
self.grade = g
#覆写父类的方法
def speak(self):
print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))
#另一个类,多继承之前的准备
class speaker():
topic = ''
name = ''
def __init__(self,n,t):
self.name = n
self.topic = t
def speak(self):
print("我叫 %s,我是一个演说家,我演讲的主题是 %s"%(self.name,self.topic))
#多继承
class sample(speaker,student):
a =''
def __init__(self,n,a,w,g,t):
student.__init__(self,n,a,w,g)
speaker.__init__(self,n,t)
test = sample("Tim",25,80,4,"Python")
test.speak() #方法名同,默认调用的是在括号中参数位置排前父类的方法
执行以上程序输出结果为:
我叫 Tim,我是一个演说家,我演讲的主题是 Python
2.7、方法重写
如果你的父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法,实例如下:
class Parent: # 定义父类
def myMethod(self):
print ('调用父类方法')
class Child(Parent): # 定义子类
def myMethod(self):
print ('调用子类方法')
c = Child() # 子类实例
c.myMethod() # 子类调用重写方法
super(Child,c).myMethod() #用子类对象调用父类已被覆盖的方法
super() 函数是用于调用父类(超类)的一个方法。
执行以上程序输出结果为:
调用子类方法 调用父类方法
2.8、类属性与方法
2.8.1、类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
2.8.2、类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数,self 代表的是类的实例。
self 的名字并不是规定死的,也可以使用 this,但是最好还是按照约定使用 self。
2.8.3、类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
实例
类的私有属性实例如下:
class JustCounter:
__secretCount = 0 # 私有变量
publicCount = 0 # 公开变量
def count(self):
self.__secretCount += 1
self.publicCount += 1
print (self.__secretCount)
counter = JustCounter()
counter.count()
counter.count()
print (counter.publicCount)
print (counter.__secretCount) # 报错,实例不能访问私有变量
执行以上程序输出结果为:
1
2
2
Traceback (most recent call last):
File "test.py", line 16, in <module>
print (counter.__secretCount) # 报错,实例不能访问私有变量
AttributeError: 'JustCounter' object has no attribute '__secretCount'
注意:类实例化后,实例化对象只要没释放,是同一个,该对象多次调用类的方法时,类的属性的值是叠加的,不清空的。
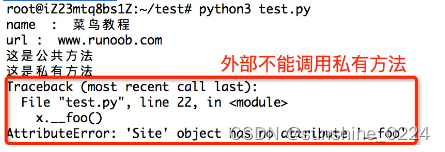
类的私有方法实例如下:
class Site:
def __init__(self, name, url):
self.name = name # public
self.__url = url # private
def who(self):
print('name : ', self.name)
print('url : ', self.__url)
def __foo(self): # 私有方法
print('这是私有方法')
def foo(self): # 公共方法
print('这是公共方法')
self.__foo()
x = Site('菜鸟教程', 'www.runoob.com')
x.who() # 正常输出
x.foo() # 正常输出
x.__foo() # 报错
以上实例执行结果:
2.8.4、类的专有方法
- __init__ : 构造函数,在生成对象时调用
- __del__ : 析构函数,释放对象时使用
- __repr__ : 打印,转换; 转化为供解释器读取的形式
简单的调用方法 : repr(obj) - __str__ : 用于将值转化为适于人阅读的形式
简单的调用方法 : str(obj) - __setitem__ : 按照索引赋值
- __getitem__: 按照索引获取值
- __len__: 获得长度
- __cmp__: 比较运算
- __call__: 函数调用
- __add__: 加运算
- __sub__: 减运算
- __mul__: 乘运算
- __truediv__: 除运算
- __mod__: 求余运算
- __pow__: 乘方
2.8.5、运算符重载
Python同样支持运算符重载,我们可以对类的专有方法进行重载。
1、__add__(self, other):用于加法操作(+)的重载。当两个对象相加时会调用该方法。
class Vector:
def __init__(self, a, b):
self.a = a
self.b = b
def __str__(self): # 重载了类的str方法
return 'Vector (%d, %d)' % (self.a, self.b)
def __add__(self,other): # 重载了类的加运算方法
return Vector(self.a + other.a, self.b + other.b)
v1 = Vector(2,10)
v2 = Vector(5,-2)
print (v1 + v2) # 此句就会调用add方法
以上代码执行结果如下所示:
Vector(7,8)
2、__sub__(self, other):用于减法操作(-)的重载。当两个对象相减时会调用该方法。
2.9、类属性的作用域
class MyClass: class_var = 0 # 类变量 def __init__(self): self.instance_var = 1 # 实例变量 def inc_class_var(self): MyClass.class_var += 1 # 访问类变量 def inc_instance_var(self): self.instance_var += 1 # 访问实例变量 my_object = MyClass() my_object.inc_class_var() my_object.inc_instance_var() print(MyClass.class_var) # Output: 1,访问的是类变量 print(my_object.instance_var) # Output: 2,访问的是实例变量
在上述例子中:
`class_var`是一个类变量(class variable),它可以被该类的所有实例和方法访问,变量的可见性是全局的;
`instance_var`是实例变量(instance variable),它只能被对应的实例访问,变量的可见性是局部的。
2.10、对象的销毁
销毁实例通常是通过垃圾回收机制来实现的,而不是通过程序员显示调用进行销毁的。
2.10.1、垃圾回收机制
垃圾回收机制是自动进行的,负责检测和销毁不再使用的对象,当一个对象不再被使用时,垃圾回收机制就会 自动将其标记为“垃圾”,并在适当的时候进行销毁,这个过程成为“垃圾回收”。
工作原理:通过引用计数器来实现。每个对象都有一个引用计数器,用来记录有多少个引用指向它。当引用计数减少到0时,说明该对象没有被引用,可以被销毁。垃圾回收机制会定期检查引用计数为0的对象,并将其销毁。
2.10.2 销毁实例时机
在Python中,销毁实例的时机是不缺定的,它取决于垃圾回收机制的具体实现。一般来说,一个对象不再被引用时,垃圾回收机制在适当的时候会将其进行销毁,但是,不是每一次对象不在被引用时会立即被销毁,而是垃圾回收机制在下一次检查时才会销毁。
2.10.3 注意事项
1、循环引用
当存在循环引用事,即两个及以上对象互相引用,他们的引用计数永远不会减少到0,这样就会导致内存泄露。为了避免循环引用,可使用weakref模块提供的弱引用功能。
2、显示销毁
在一些特殊的情况下,我们可能需要显示地销毁一些实例。可以通过__del()__方法来实现,在该方法中执行一些清理工作。但是,应该注意的是,__del()__方法不是唯一的销毁实例的方式,而且在一般情况下不建议使用该方式销毁实例。
3、内存管理
虽然python的垃圾回收机制会自动的销毁不再使用的对象,但是我们如果创建了大量的对象且长时间持有他们的引用更,就可能导致内存占用过高。因此我们应该及时释放不再使用的对象,以减少内存的占用。
2.10.4 弱引用 weakref
弱引用弱引用是一种指向对象的引用,但并不会阻止该对象被垃圾回收。在Python中,可以使用weakref模块实现弱引用。_weakref_是一种特殊的属性,用于访问对象的弱引用。
使用__weakref__实现弱引用的示例:
import weakref
class A:
def __init__(self, value):
self.value = value
def __repr__(self):
return str(self.value)
a = A(10)
r = weakref.ref(a)
print(a)
print(r())
del a
print(r())
输出:
10
10
None 在这个示例中,a是一个类A的实例,r是a的弱引用。r()可以获取到对a的引用。当del a时,a被垃圾回收,而r()返回None,因为a已经不存在了。
三、命名空间和作用域
3.1、命名空间
命名空间(Namespace)是从名称到对象的映射,大部分的命名空间都是通过 Python 字典来实现的。
1、一般有三种命名空间:
- 内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
- 全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量。
- 局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是)
2、命名空间查找顺序:
假设我们要使用变量 runoob,则 Python 的查找顺序为:局部的命名空间 -> 全局命名空间 -> 内置命名空间。
如果找不到变量 runoob,它将放弃查找并引发一个 NameError 异常:
NameError: name 'runoob' is not defined。
3、命名空间的生命周期:
命名空间的生命周期取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束。因此,我们无法从外部命名空间访问内部命名空间的对象。
# var1 是全局名称
var1 = 5
def some_func():
# var2 是局部名称
var2 = 6
def some_inner_func():
# var3 是内嵌的局部名称
var3 = 7
3.2、作用域
作用域就是一个 Python 程序可以直接访问命名空间的正文区域。
在一个 python 程序中,直接访问一个变量,会从内到外依次访问所有的作用域直到找到,否则会报未定义的错误。
Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。
变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。Python 的作用域一共有4种,分别是:
有四种作用域:
- L(Local):最内层,包含局部变量,比如一个函数/方法内部。
- E(Enclosing):包含了非局部(non-local)也非全局(non-global)的变量。比如两个嵌套函数,一个函数(或类) A 里面又包含了一个函数 B ,那么对于 B 中的名称来说 A 中的作用域就为 nonlocal。
- G(Global):当前脚本的最外层,比如当前模块的全局变量。
- B(Built-in): 包含了内建的变量/关键字等,最后被搜索。
规则顺序: L –> E –> G –> B。
在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内置中找。

g_count = 0 # 全局作用域
def outer():
o_count = 1 # 闭包函数外的函数中
def inner():
i_count = 2 # 局部作用域
内置作用域是通过一个名为 builtin 的标准模块来实现的,但是这个变量名自身并没有放入内置作用域内,所以必须导入这个文件才能够使用它。
可以使用以下的代码来查看到底预定义了哪些变量:
>>> import builtins >>> dir(builtins)
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这些语句内定义的变量,外部也可以访问,如下代码:
>>> if True:
... msg = 'I am from Runoob'
...
>>> msg
'I am from Runoob'
>>>
实例中 msg 变量定义在 if 语句块中,但外部还是可以访问的。
如果将 msg 定义在函数中,则它就是局部变量,外部不能访问:
>>> def test():
... msg_inner = 'I am from Runoob'
>>> msg_inner
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'msg_inner' is not defined
>>>
从报错的信息上看,说明了 msg_inner 未定义,无法使用,因为它是局部变量,只有在函数内可以使用。
3.2.1、全局变量和局部变量
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
局部变量只能在其被声明的函数内部访问,而全局变量可以在整个程序范围内访问。调用函数时,所有在函数内声明的变量名称都将被加入到作用域中。如下实例:
total = 0 # 这是一个全局变量
# 可写函数说明
def sum( arg1, arg2 ):
#返回2个参数的和."
total = arg1 + arg2 # total在这里是局部变量.
print ("函数内是局部变量 : ", total)
return total
#调用sum函数
sum( 10, 20 )
print ("函数外是全局变量 : ", total)
以上实例输出结果:
函数内是局部变量 : 30 函数外是全局变量 : 0
3.2.2、global 和 nonlocal关键字
当内部作用域想修改外部作用域的变量时,就要用到 global 和 nonlocal 关键字了。
1、以下实例修改全局变量 num,需要使用global关键字
num = 1
def fun1():
global num # 需要使用 global 关键字声明
print(num)
num = 123
print(num)
fun1()
print(num)
以上实例输出结果:
1 123 123
2、如果要修改嵌套作用域(enclosing 作用域,外层非全局作用域)中的变量则需要 nonlocal 关键字了,如下实例:
def outer():
num = 10
def inner():
nonlocal num # nonlocal关键字声明
num = 100
print(num)
inner()
print(num)
outer()
以上实例输出结果:
100 100
3、特殊情况:局部作用域引用错误
假设下面这段代码被运行:
a = 10
def test():
a = a + 1
print(a)
test()
以上程序执行,报错信息如下:
Traceback (most recent call last):
File "test.py", line 7, in <module>
test()
File "test.py", line 5, in test
a = a + 1
UnboundLocalError: local variable 'a' referenced before assignment
错误信息为局部作用域引用错误,因为 test 函数中的 a 使用的是局部,未定义,无法修改。
修改 a 为全局变量:
a = 10
def test():
global a
a = a + 1
print(a)
test()
执行输出结果为:
11
也可以通过函数参数传递
a = 10
def test(a):
a = a + 1
print(a)
test(a)
执行输出结果为:
11
四、标准库概览
Python 标准库非常庞大,所提供的组件涉及范围十分广泛,使用标准库我们可以让您轻松地完成各种任务。
以下是一些 Python3 标准库中的模块:
-
os 模块:os 模块提供了许多与操作系统交互的函数,例如创建、移动和删除文件和目录,以及访问环境变量等。
-
sys 模块:sys 模块提供了与 Python 解释器和系统相关的功能,例如解释器的版本和路径,以及与 stdin、stdout 和 stderr 相关的信息。
-
time 模块:time 模块提供了处理时间的函数,例如获取当前时间、格式化日期和时间、计时等。
-
datetime 模块:datetime 模块提供了更高级的日期和时间处理函数,例如处理时区、计算时间差、计算日期差等。
-
random 模块:random 模块提供了生成随机数的函数,例如生成随机整数、浮点数、序列等。
-
math 模块:math 模块提供了数学函数,例如三角函数、对数函数、指数函数、常数等。
-
re 模块:re 模块提供了正则表达式处理函数,可以用于文本搜索、替换、分割等。
-
json 模块:json 模块提供了 JSON 编码和解码函数,可以将 Python 对象转换为 JSON 格式,并从 JSON 格式中解析出 Python 对象。
-
urllib 模块:urllib 模块提供了访问网页和处理 URL 的功能,包括下载文件、发送 POST 请求、处理 cookies 等。
4.1、操作系统接口
os模块提供了不少与操作系统相关联的函数。
>>> import os
>>> os.getcwd() # 返回当前的工作目录
'C:\\Python34'
>>> os.chdir('/server/accesslogs') # 修改当前的工作目录
>>> os.system('mkdir today') # 执行系统命令 mkdir
0
建议使用 "import os" 风格而非 "from os import *"。这样可以保证随操作系统不同而有所变化的 os.open() 不会覆盖内置函数 open()。
import 库名和from 库名 import 函数名的区别:
import 库名和from 库名 import 函数名这两种方式都可以导入库,但是两者是有区别的。
前者会将整个模块导入,并创建一个新的命名空间,访问模块中的函数或变量时,需要使用模块名作为前缀,如module.function()或module.variable;
后者是将指定的函数或变量导入当前工作空间,不需要使用模块名作为前缀,可以直接访问函数或变量,如function()或variable。
在使用 os 这样的大型模块时内置的 dir() 和 help() 函数非常有用:
>>> import os >>> dir(os) <returns a list of all module functions> >>> help(os) <returns an extensive manual page created from the module's docstrings>
针对日常的文件和目录管理任务,:mod:shutil 模块提供了一个易于使用的高级接口:
>>> import shutil >>> shutil.copyfile('data.db', 'archive.db') >>> shutil.move('/build/executables', 'installdir')
4.2、文件通配符
glob模块提供了一个函数用于从目录通配符搜索中生成文件列表:
>>> import glob
>>> glob.glob('*.py')
['primes.py', 'random.py', 'quote.py']
4.3、命令行参数
通用工具脚本经常调用命令行参数。这些命令行参数以链表形式存储于 sys 模块的 argv 变量。
命令行参数可以通过sys模块中的argv属性来获取。argv是一个字符串列表,包含了命令行参数。其中,argv[0]表示程序本身的名称,argv[1:]表示程序接收到的命令行参数列表。
例如在命令行中执行 "python demo.py one two three" 后可以得到以下输出结果:
>>> import sys >>> print(sys.argv) ['demo.py', 'one', 'two', 'three']
除了使用sys.argv属性获取命令行参数外,还可以使用argparse模块来更方便地解析命令行参数。argparse模块提供了更多的选项和参数解析功能,使得命令行参数的解析更加简单和灵活。
4.4、错误输出重定向和程序终止
sys 还有 stdin,stdout 和 stderr 属性,即使在 stdout 被重定向时,后者也可以用于显示警告和错误信息。
>>> sys.stderr.write('Warning, log file not found starting a new one\n')
Warning, log file not found starting a new one
大多脚本的定向终止都使用 "sys.exit()"。
五、编程
5.1、debug操作
设置好断点,debug运行,然后 F8 单步调试;遇到想进入的函数 F7 进去;想出来再shift + F8;跳过不想看的地方,直接设置下一个断点,然后 F9 过去。
5.2、内置函数
5.2.1、print()
1、语法:
print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)
objects – 复数,表示可以一次输出多个对象。输出多个对象时,需要用 , 分隔。
sep – 用来间隔多个对象,默认值是一个空格。
end – 用来设定以什么结尾。默认值是换行符 \n,我们可以换成其他字符串。
file – 要写入的文件对象。
flush – 输出是否被缓存通常决定于 file,但如果 flush 关键字参数为 True,流会被强制刷新。
2、 print( )函数的4种用法
# 括号内没有引号
print( )
#括号内有单引号
print('')
#括号内有双引号
print(" ")
#括号内有三引号
print(''' ''')
print(""" """)
①【无引号】输出数字和公式。
②【单引号】输出不含单引号的字符。
③【双引号】输出任意字符。
④【三引号】输出有换行的字符。
5.2.2、map()
1、语法:
map(function,iterable,...)
第一个参数接受一个函数名,后面的参数接受一个或多个可迭代的序列,返回的是一个集合。
2、使用
把函数依次作用在list中的每一个元素上,得到一个新的list并返回。
注意,map不改变原list,而是返回一个新list。
5.2.3、round()
1、语法:
round( x [, n] ) 方法返回浮点数x的四舍五入值。
- x -- 数值表达式。
- n -- 数值表达式,表示从小数点位数。
2、使用
当参数n不存在时,round()函数的输出为整数。
当参数n存在时,即使为0,round()函数的输出也会是一个浮点数。
n的值可以是负数,表示在整数位部分四舍五入,但结果仍是浮点数。
print(round(123.45)) print(round(123.45,0)) print(round(123.45,-1))
结果是:
123 123.0 120.0
5.3、递归函数
1、概念:函数直接或间接的调用函数本身,则称该函数为递归函数。也就是说,如果在一个函数内部,调用自身本身,那么这个函数就称为递归函数。
2、递归函数的优点是逻辑简单清晰,缺点是过深的递归容易导致栈溢出
3、 尾递归:为了解决递归调用栈溢出的问题。尾递归是指,在函数返回的时候,调用自身,并且 return 语句中不能包含表达式。
def foo(x):
if x == 1:
return 1
else:
return x+foo(x-1)
print(foo(4))
结果:10
5.4、相关语法
1、函数定义和调用函数之间应该空两行















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









