







文章目录
- 【内联函数与(带参宏)宏定义的区别】
- 【C++ 内存回收】
- 【指针和引用的区别】
- 【传指针和传引用的区别】
- 【关键字 static】
- 【结构体不同于类的地方】
- 【常用容器及其底层实现】
- 【迭代器失效问题】
- 【为何 map 和 set 的插入删除效率比用其他序列容器高】
- 【对 map 和 set,为何每次 insert 之后,以前保存的 iterator 不会失效】
- 【获取字符串指定下标元素】
- 【整数转换为字符串】
- 【统计 vector 中指定对象元素出现的次数】
- 【vector 转 set】
- 【vector 转 string】
- 【vector 插入删除的时间复杂度】
- 【map 和 unordered_map 的其区别】
- 【boost 库中的四种智能指针】
该笔记摘记了《21 天学通 C++》等几本书的内容,从中你可以了解到关于 C++ 语言的基本使用,同时也会深入讨论一些编码上的细节问题。此外,该笔记也穿插记录了关于 C++ 语言的诸多面试问题
3 使用变量和常量
3.1 常量
字面常量
比如 int FirstNumber = 0,这里的零是代码的一部分,将编译到应用程序中,且不可修改,因此称为字面常量。字面常量可以是任何类型:布尔型、整型、字符串等
使用 constexpr 声明常量
constexpr 主要用于常量表达式, 如 constexpr double GetPi() { return 22.0/7; },其有一个好处就在于上面的语句是在编译阶段计算该表达式的值,这提高了应用程序的运行速度
枚举常量
可以使用枚举常量来指定变量的类型,这样声明等的变量只能取特定的值
枚举类型的定义格式为 enum<类型名>{<枚举常量表>};
枚举常量代表该枚举类型的变量可能取的值,编译系统为每个枚举常量指定一个整数值,默认状态下,这个整数就是所列举元素的序号,序号从 0 开始。 可以在定义枚举类型时为部分或全部枚举常量指定整数值,在指定值之前的枚举常量仍按默认方式取值,而指定值之后的枚举常量按依次加1的原则取值。 各枚举常量的值可以重复
enum fruit_set {apple, orange, banana=1, peach, grape}
//枚举常量 apple=0,orange=1, banana=1,peach=2,grape=3
enum week {Sun=7, Mon=1, Tue, Wed, Thu, Fri, Sat};
//枚举常量Sun,Mon,Tue,Wed,Thu,Fri,Sat的值分别为 7、1、2、3、4、5、6。
另外,枚举常量只能以标识符形式表示,而不能是整型、字符型等文字常量。例如,以下定义非法:
enum letter_set {'a','d','F','s','T'}; //枚举常量不能是字符常量
enum year_set{2000,2001,2002,2003,2004,2005}; //枚举常量不能是整型常量
enum letter_set {a, d, F, s, T}; // is ok
enum year_set{y2000, y2001, y2002, y2003, y2004, y2005}; // is ok
使用 #define 定义常量
# define 其实是一个预处理器宏,但是使用# define 定义常量的做法已经摈弃,因此不应采用这种做法
『全局变量和静态变量』
1. 全局变量具有全局作用域,只在一个源文件中定义就可以作用于所有的源文件
2. 静态变量又分静态全局变量和静态局部变量
静态全局变量和全局变量的区别在于如果程序包含多个文件的话,静态全局变量只作用于定义它的文件里,不能作用到其他文件,即具有文件作用域
静态局部变量仅作用于定义自己的函数体,对该函数体始终可见
3. 全局变量和静态变量都存放在静态存储区
5 使用表达式、语句和运算符
sizeof(...) 看起来像函数调用,但它并不是函数,而是运算符。同时,程序员不能定义这个运算符,因此不能重载它
6 控制程序流程
7 使用函数组织代码
7.1 函数重载
名称和返回类型相同,但参数不同的函数被称为重载函数
7.2 内联函数
常规函数调用被转换为 call 指令,这会导致栈操作、微处理器跳转到函数处执行等。大多数情况下,这个过程速度都是非常快的,但是我们总会碰到一些很简单的函数,例如
double getpi() { return 3.1415; }
但是这样子执行函数调用的开销可能非常高,这就是 C++ 编译器允许程序员将这样的函数声明为内联的原因
inline double getpi() { return 3.1415; }
将函数声明为内联的会导致代码急剧膨胀,在声明数为内联的函数做了大量复杂处理时尤其如此。应尽可能少用关键字 inline,仅当函数非常简单,需要降低其开销时,才应使用该关键字
【内联函数与(带参宏)宏定义的区别】
1.内联函数在编译过程展开,而宏定义在预编译过程展开
2.宏定义是简单的文本替换,而内联函数是直接被嵌入到目标代码中去的
3.使用宏定义时要小心处理宏参数,一般要用括号括起来,否则容易出现二义性。而内联函数没有这种二义性
4.宏展开是不作参数类型检查的,而内联函数是会作参数类型检查且还有返回值的类型检查
7.3 lambda 函数
lambda 函数的语法如下:
[optional parameters](parameter list){ statements; }
8 阐述指针和引用
8.1 指针
使用解除引用运算符(*)访问指向的数据
有了包含合法地址的指针后,如何访问这个地方,即如何获取或设置这个地方的数据呢?答案是使用解除引用运算符(*),如果有合法的指针 pData,要访问它包含的地址出存储的值,可使用 *pData
将 sizeof() 用于指针的结果
指针是包含内存地址的变量,因此无论指针指向哪种类型的变量,其内容都是一个地址,在特定的系统中,存储地址所需的字节数是固定的
因此,将 sizeof() 用于指针时,结果取决于编译程序时使用的编译器和针对的操作系统,与指针指向的变量类型无关
8.2 动态内存分配
使用 new 和 delete 动态地分配和释放内存
通常情况下,如果成功,new 将返回指向一个指针,指向分配的内存,否则将引发异常
【检查使用 new 发出的分配请求是否得到满足】
C++ 提供了两种确保返回指针有效的方法:
1. 默认方法是使用异常,即如果内存分配失败,将引发 std::bad_alloc 异常

2. 有一个 new 的变种——new(nothrow),它不引发异常,而返回 NULL,让你能够在使用指针前检查其有效性

使用 new 时,需要指定要为哪种数据类型分配内存 Type* Pointer = new Type
需要为多个元素分配内存时,Type* Pointer = new Type[maxsize]
使用 new 分配的内存最终都需要使用对应的 delete 进行释放,delete Pointer;对应多个元素分配的内存的释放,有 delete[] Pointer
new 和 delete 分配和释放自由存储区中的内存。自由存储区是一种内存抽象,表现为一个内存池,应用程序可分配(预留)和释放其中的内存
【C++ 内存回收】
(1)栈对象
栈一般用于存放局部变量和对象,如我们在函数中用类似下面语句声明一个对象
Type stack_obj;
stack_obj 便是一个栈对象,它的生命期是从定义点开始,当所在函数返回时,生命结束
另外,几乎所有的临时对象都是栈对象,比如下面的函数定义
Type fun(Type object);
这个函数至少产生两个临时对象,首先,参数是按值传递的,所以会调用拷贝构造函数生成一个临时对象 object_copy1 ,在函数内部使用的使用的不是 object,而是 object_copy1,自然,object_copy1 是一个栈对象,它在函数返回时被释放;还有这个函数是值返回的,在函数返回时,如果我们不考虑返回值优化,那么也会产生一个临时对象 object_copy2,这个临时对象会在函数返回后一段时间内被释放
看到了吗?编译器在我们毫无知觉的情况下,为我们生成了这么多临时对象,而生成这些临时对象的时间和空间的开销可能是很大的,所以,你也许明白了,为什么对于 “ 大 ” 对象最好用 const 引用传递代替按值进行函数参数传递了
(2)堆对象
堆,又叫自由存储区,它是在程序执行的过程中动态分配的,所以它最大的特性就是动态性。在C++中,所有堆对象的创建和销毁都要由程序员负责,所以,如果处理不好,就会发生内存问题。如果分配了堆对象,却忘记了释放,就会产生内存泄漏;而如果已释放了对象,却没有将相应的指针置为 NULL,该指针就是所谓的 “ 悬挂指针 ”,再度使用此指针时,就会出现非法访问,严重时就导致程序崩溃
分配堆对象的唯一方法是用 new,只要使用new,就会在堆中分配一块内存,并且返回指向该堆对象的指针
(3)静态对象
所有的静态对象、全局对象都于静态存储区分配。关于全局对象,是在 main() 函数执行前就分配好了的。其实,在 main() 函数中的显示代码执行之前,会调用一个由编译器生成的 _main() 函数,而 _main() 函数会进行所有全局对象的的构造及初始化工作。而在 main() 函数结束之前,会调用由编译器生成的 exit() 函数,来释放所有的全局对象
int main()
{
… …// 显式代码
}
// 实际上被转化成这样
int main()
{
_main(); //隐式代码,由编译器产生,用以构造所有全局对象
… … // 显式代码
… …
exit(); // 隐式代码,由编译器产生,用以释放所有全局对象
}
所以,知道了这个之后,便可以由此引出一些技巧,如,假设我们要在 main() 函数执行之前做某些准备工作,那么我们可以将这些准备工作写到一个自定义的全局对象的构造函数中,这样,在 main() 函数的显式代码执行之前,这个全局对象的构造函数会被调用,执行预期的动作
到此为止,我们谈论的都是静态存储区中的全局对象,那么,局部静态对象呢?局部静态对象通常也是在函数中定义的,就像栈对象一样,只不过,其前面多了个 static 关键字。局部静态对象的生命期是从其所在函数第一次被调用,更确切地说,是当第一次执行到该静态对象的声明代码时,产生该静态局部对象,直到整个程序结束时,才销毁该对象
还有一种静态对象,那就是它作为 class 的静态成员,要分两种情况讨论
1. class 的静态成员对象的生命期
class的静态成员对象随着第一个class object的产生而产生,在整个程序结束时消亡。也就是有这样的情况存在,在程序中我们定义了一个class,该类中有一个静态对象作为成员,但是在程序执行过程中,如果我们没有创建任何一个该class object,那么也就不会产生该class所包含的那个静态对象。还有,如果创建了多个class object,那么所有这些object都共享那个静态对象成员
2. 继承下的静态成员对象
(3)三种内存对象的比较
栈对象的优势是在适当的时候自动生成,又在适当的时候自动销毁,不需要程序员操心;而且栈对象的创建速度一般较堆对象快,因为分配堆对象时,会调用 new 操作,new 会采用某种内存空间搜索算法,而该搜索过程可能是很费时间的,产生栈对象则没有这么麻烦,它仅仅需要移动栈顶指针就可以了。但是要注意的是,通常栈空间容量比较小,一般是 1MB~2MB,所以体积比较大的对象不适合在栈中分配。特别要注意递归函数中最好不要使用栈对象,因为随着递归调用深度的增加,所需的栈空间也会线性增加,当所需栈空间不够时,便会导致栈溢出,这样就会产生运行时错误
堆对象,其产生时刻和销毁时刻都要程序员精确定义,也就是说,程序员对堆对象的生命具有完全的控制权。我们常常需要这样的对象,比如,我们需要创建一个对象,能够被多个函数所访问,但是又不想使其成为全局的,那么这个时候创建一个堆对象无疑是良好的选择,然后在各个函数之间传递这个堆对象的指针,便可以实现对该对象的共享。另外,相比于栈空间,堆的容量要大得多。实际上,当物理内存不够时,如果这时还需要生成新的堆对象,通常不会产生运行时错误,而是系统会使用虚拟内存来扩展实际的物理内存
接下来看看static对象
首先是全局对象。全局对象为类间通信和函数间通信提供了一种最简单的方式,虽然这种方式并不优雅。一般而言,在完全的面向对象语言中,是不存在全局对象的,比如C#,因为全局对象意味着不安全和高耦合,在程序中过多地使用全局对象将大大降低程序的健壮性、稳定性、可维护性和可复用性。C++也完全可以剔除全局对象,但是最终没有,我想原因之一是为了兼容C。
其次是类的静态成员,上面已经提到,基类及其派生类的所有对象都共享这个静态成员对象,所以当需要在这些class之间或这些class objects之间进行数据共享或通信时,这样的静态成员无疑是很好的选择。
接着是静态局部对象,主要可用于保存该对象所在函数被屡次调用期间的中间状态,其中一个最显著的例子就是递归函数,我们都知道递归函数是自己调用自己的函数,如果在递归函数中定义一个 nonstatic 局部对象,那么当递归次数相当大时,所产生的开销也是巨大的。这是因为 nonstatic 局部对象是栈对象,每递归调用一次,就会产生一个这样的对象,每返回一次,就会释放这个对象,而且,这样的对象只局限于当前调用层,对于更深入的嵌套层和更浅露的外层,都是不可见的。每个层都有自己的局部对象和参数
因此,在递归函数设计中,可以使用 static 对象替代 nonstatic 局部对象(即栈对象),这不仅可以减少每次递归调用和返回时产生和释放 nonstatic 对象的开销,而且 static 对象还可以保存递归调用的中间状态,并且可为各个调用层所访问
将递增和递减运算符用于指针的结果
假设一个指向 int 类型变量的指针为 0x002EFB34,int 占 4 字节,因此占用 0x002EFB34 ~ 0x002EFB37 的内容,将递增运算符作用于该指针后,它指向的并不是 0x002EFB35,因为指向 int 中间毫无意义
如果对指针执行递增或递减运算,编译器将认为你要指向内存块中相邻的值(并假设这个值的类型与前一个值相同),而不是相邻的字节
小结:将指针递增或递减时,其包含的地址将增加或减少指向的数据类型的 sizeof
如果声明了如下指针:Type* pType = Address,执行 ++pType 后,pType 将指向 Address + sizeof(Type)
将关键字 const 用于指针
const 指针有三种:
-
指针指向的数据为常量,不能修改,但可以修改指针包含的地址,即指针可以指向其他地方

-
指针包含的地址是常量,不能修改,但可改变指针指向的数据

-
指针包含的地址以及它指向的值都是常量,不能修改

将指针传递给函数
将指针作为函数参数时,确保函数只能修改你希望它修改的参数,对于那些不允许修改的使用 const Type* const pType
数组和指针的相似之处
对数组元素的访问 nums[i] 等价于 *(pNums+i)
8.3 使用指针时常犯的错误
内存泄露
这可能是 C++ 应用程序最常见的问题之一:运行时间越长,占用内存越多,系统越慢
如果在使用 new 动态分配的内存不再需要后,程序员没有使用配套的 delete 释放,通常就会出现这种情况
指针指向无效的内存单元
使用运算符 * 对指针解除引用,以访问指向的值时,务必确保指针指向了有效的内存单元,否则程序要么崩溃,要么行为不端
悬浮指针
使用 delete 释放后,任何有效指针都将无效,此时的指针不应再使用,所以最好是在释放指针后将其置为 NULL(初始化指针的时候,也最好顺手置为 NULL)
8.4 引用
引用是变量的别名。声明引用时,需要将其初始化为一个变量,因此引用只是另一种访问相应变量存储的数据的方式,如 varType ori = value; varTpye& ref = ori;
将关键字 const 用于引用
可能需要禁止通过引用修改它指向的变量的值,为此可在声明引用时使用关键字 const,如 const varType& ref = ori;
按引用向函数传递参数
引用的优点之一是,可避免将实参复制给形参,从而极大地提高性能
【指针和引用的区别】
1. 指针有自己的一块空间,而引用只是一个别名
2. 使用sizeof看一个指针的大小是4,而引用则是被引用对象的大小
3. 指针可以被初始化为NULL,而引用必须被初始化且必须是一个已有对象的引用
4. 作为参数传递时,指针需要被解引用才可以对对象进行操作,而直接对引用的修改都会改变引用所指向的对象
5. 指针在使用中可以指向其它对象,但是引用只能是一个对象的引用,不能被改变
6. 指针可以有多级指针(**p),而引用至多一级
7. 指针和引用使用++运算符的意义不一样,可以参考 指针和引用的自增(++)运算意义不一样?
怎么个不同法?请举例说明
8. 如果返回动态内存分配的对象或者内存,必须使用指针,引用可能引起内存泄露
【传指针和传引用的区别】
① 理论部分:
传指针因为传地址是把实参地址的拷贝传递给形参,因为传地址是把实参地址的拷贝传递给形参。复制完毕后实参的地址和形参的地址没有任何联系,对形参地址的修改不会影响到实参, 但是对形参地址所指向对象的修改却直接反应在实参中,因为形参指向的对象就是实参的对象
传引用本质没有任何实参的拷贝,就是两个变量指向同一个对象。如果对形参的修改,必然反映到实参上
② 操作部分:
根据上面的描述,如果不希望在函数中改变形参的地址,可以进如下的操作 void Func(type* const pData),此时如果在函数内执行 pData = &AnotherVar 编译器将会报错
而将 const 用于引用时,将不允许修改引用所指对象
9 类和对象
9.1 类和对象
如果对象是使用 new 在自由存储区中实例化的,或者有指向对象的指针,则可使用指针运算符(->)来访问成员属性

9.2 关键字 public 和 private
C++ 让我们能够将类属性和方法声明为公有的,这意味着有了对象后就可以获得他们;也可以将其声明为私有的,这意味着只能在类的内部(或其友元)中访问

9.3 构造函数
构造函数是一种特殊的函数(方法),在创建对象时被调用。与函数一样,构造函数也可以被重载
Human 类的构造函数的声明类似于下面这样:

也可以在类声明外定义构造函数的代码,如下:

:: 被称为作用域解析运算符,如 Human::Age 指的是在 Human 类中声明的变量 Age,而 ::DateofBirth 表示全局作用域中的变量 DataofBirth
何时及如何使用构造函数
构造函数总是在创建对象时被调用,这让构造函数是将成员变量初始化为已知值的理想场所

重载构造函数

我们可以选择不实现默认构造函数,从而要求实例化对象时必须提供某些参数
带默认值的构造函数参数
就像函数可以由带默认值的参数一样,构造函数也可以

包含初始化列表的构造函数
另一种初始化成员的方式是使用初始化列表

初始化列表由包含在括号中的参数声明后面的冒号标识,冒号后面列出了各个成员变量及其初始值
9.4 析构函数
析构函数在对象销毁时自动被调用
Human 类的析构函数的声明类似于下面这样:

何时及如何使用析构函数
每当对象不再在作用域内或通过 delete 被删除,进而被销毁时,都将调用析构函数,这使得析构函数是重置变量以及释放动态分配的内存和其他资源的理想场所
比如,我们创建一个简单类,用来封装 C 风格字符串

【注】析构函数不能重载,每个类都只能有一个析构函数,如果你忘记了实现析构函数,编译器将创建一个伪析构函数并调用它,伪析构函数为空,即不释放动态分配的内存
9.5 复制构造函数
浅复制及其存在的问题
例如,上面的 MyString 类包含一个指针成员,它指向动态分配的内存,复制这个类的对象时,将复制其指针成员,但不复制指向的缓冲区,其结果是,两个对象指向同一块动态分配的内存,这就称为浅复制
我们看下面这个函数,运行它会发生什么事情呢?
#include <iostream>
#include <cstring>
using namespace std;
class MyString{
private:
char* buffer;
public:
MyString(const char* InitialInput){
if(InitialInput!=NULL)
{
buffer = new char [strlen(InitialInput)+1];
strcpy(buffer, InitialInput);
}
else buffer = NULL;
}
~MyString(){
cout << "Invoking destructor, clearing up" << endl;
if(buffer!=NULL) delete [] buffer;
}
const char* getString(){
return buffer;
}
};
void UseMyString(MyString Input){
cout << "buffer contains: " << Input.getString() << endl;
}
int main()
{
MyString SayHello("Hello, world!");
UseMyString(SayHello);
}

什么意思?两次调用析构函数后,程序崩溃了?
在主函数中运行 UseMyString() 时,对象 SayHello 被复制到形参 Input,此时是按值传递,对于整型、字符和原始指针等 POD 数据,编译器执行二进制复制,因此 SayHello.buffer 包含的指针被复制到 Input 中,于是发生了上面我们说的浅复制的情况

二进制复制并不深复制指向的内存单元,这导致两个 MyString 对象指向同一个内存单元。函数 UseMyString() 返回时,变量 Input 不再在作用域内,因此被销毁,调用一次析构函数。当主函数执行完时,销毁 SayHello 对象再次调用析构函数,但是此时指针所指的内存单元早已被释放,所以导致错误发生
【大白羊提醒您,深/浅复制是面向对象编程中常考的问题片哦,可能会出现在您的面试题中】
使用复制构造函数确保深复制
复制构造函数是一个特殊的重载构造函数,编写类的程序员必须提供它。每当对象被复制(包括对象按值传参)时,编译器都将调用复制构造函数
为 MyString 类声明复制构造函数:

复制构造函数接收一个以引用方式传入的当前类的对象作为参数,如果在这里使用按值传参同样还是会导致浅复制的发生。另外,通过 const 的使用可确保复制构造函数不会修改指向的源对象
修改后的完整代码如下
#include <iostream>
#include <cstring>
using namespace std;
class MyString{
private:
char* buffer;
public:
MyString(const char* InitialInput){
if(InitialInput!=NULL)
{
cout << "Constructor:creating new MyString" << endl;
buffer = new char [strlen(InitialInput)+1];
strcpy(buffer, InitialInput);
cout << "Buffer points to: 0x" << hex;
cout << (unsigned int*)buffer << endl;
}
else buffer = NULL;
}
MyString(const MyString& CopySource){
cout << "Copy constructer: copying from MyString" << endl;
if(CopySource.buffer!=NULL)
{
buffer = new char [strlen(CopySource.buffer)+1];
strcpy(buffer, CopySource.buffer);
cout << "Buffer points to: 0x" << hex;
cout << (unsigned int*)buffer << endl;
}
}
~MyString(){
cout << "Invoking destructor, clearing up" << endl;
if(buffer!=NULL) delete [] buffer;
}
const char* getString(){
return buffer;
}
};
void UseMyString(MyString input){
cout << "buffer contains: " << input.getString() << endl;
}
int main()
{
MyString SayHello("Hello, world!");
UseMyString(SayHello);
}
此时运行程序将不会崩溃,因为深复制将指针指向的内容复制到当前对象新分配的缓冲区中

我们这里讨论的是将类作为函数参数时发生的浅复制,如果在没有重载 = 的情况下,将一个 MyString 对象通过 = 赋值给另外一个 MyString 对象时,同样会导致浅复制的发生,所以这时需要重载运算符
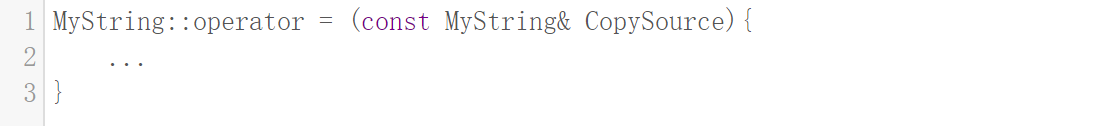
【用于高性能编程的移动构造函数和移动赋值运算符】
移动构造函数和移动赋值运算符旨在避免赋值不必要的临时值,对于那些管理动态分配资源的类,如动态数组类或字符串类很有用处
① 不必要的复制带来的问题
考虑前面在 MyString 类中重载运算符 +,它会创建并返回一个拷贝

创建 sayHello 时,需要执行加法运算符两次,而每一次都将创建一个按值返回的临时拷贝,导致执行复制构造函数。复制构造函数执行深复制,而生成的临时拷贝在该表达式执行完毕后就不再存在。这个 C++ 性能上带来了很大的瓶颈
C++11 利用移动构造函数解决了这个问题:编译器意识到需要创建临时拷贝时,将转而使用移动构造函数
② 声明移动构造函数和移动赋值运算符
相比于常规复制构造函数和复制赋值运算符的声明,移动构造h函数和移动赋值运算符的不同之处在于,输入参数的类型为 MyClass&&
class MyClass
{
private:
Type* ptrResource;
public:
MyClass(); // default constructor
MyClass(const MyClass& CopySource); // copy constructor
MyClass& operator = (const MyClass& CopySource); // copy assignment operator
MyClass(MyClass&& MoveSource) // move constructor
{
ptrResource = MoveSource.ptrResource;
MoveSource.ptrResource = NULL;
}
MyClass& operator = (MyClass&& MoveSource) // move assignment opereator
{
if(this!=&MoveSource)
{
delete [] ptrResource;
ptrResource = MoveSource.ptrResource;
MoveSource.ptrResource = NULL;
}
}
};
我们最终来看一下使用了移动构造函数和移动赋值运算符的 MyString 类



总的说来,C++11 引入移动构造函数和移动赋值运算符是为了避免临时拷贝时总进行深复制而导致的性能瓶颈
9.6 构造函数和析构函数的其他用途
不允许复制的类

如果不声明复制构造函数,C++ 将自动添加一个公有的默认复制构造函数,于是就出现上面代码中的情况——出现了我们并不希望发生的复制
要禁止对象被复制,可声明一个私有的复制构造函数,这样在编译时 DoSomething(OurPresident) 无法通过编译。为禁止赋值,可声明一个私有的赋值运算符

只有一个实例的单类
我们知道每个国家都只有一位总统,即使上面的代码实现了 President 类的对象不可复制,但还是存在一个缺陷:无法禁止通过实例化多个对象类创建多名总统
如果我们要确保 President 类有且只有一个化身,即有一个 President 对象后,就禁止创建其他的 President 对象。要实现这种功能强大的模式,可以使用单例的概念,它使用私有构造函数、私有复制运算符和静态实例成员
要创建单例类,关键字 static 必不可少
#include <iostream>
#include <string>
using namespace std;
class President
{
private:
// private default constructor(prohibits creation from outside)
President(){};
// private copy constructor(prohibits copy creation)
President(const President&);
// private assignment operator(prohibits assignment)
const President& operator = (const President&);
string name;
public:
static President& getInstance(){
static President OnlyInstance;
return OnlyInstance;
}
string getName(){
return name;
}
void setName(string inputname){
name = inputname;
}
};
int main()
{
President& OnlyPresident = President::getInstance();
OnlyPresident.setName("Abraham Lincoln");
// President Second; // cannot access constructor
// President* Third = new President(); // cannot access constructor
// President Fourth = OnlyPresident; // cannor access copy constructor
// OnlyPresident = President::getInstance(); // cannot access operator;
cout << "The name of the President is: " << OnlyPresident.getName() << endl;
}
【注】可以使用 类名::静态函数名() 引用静态成员函数,如上 President::getInstance(),但不能用 :: 调用非静态成员函数
【关键字 static】
1. 全局/局部静态变量
- 在全局变量前加上关键字 static 将形成一个全局静态变量,全局今天变量仅在定义其的文件中始终存在,对其他文件不可见
- 将 static 用于函数中声明的局部变量时,该变量即称为局部静态变量,其值将在两次调用之间保持不变
2. 类的静态成员和静态函数
- 将 static 用于类的数据成员时,该数据成员将在所有实例之间共享
- 将 static 用于成员函数(方法)时,该方法将在所有成员之间共享
禁止在栈中实例化的类
栈空间通常是有限的。如果编写一个数据库类,其内部结构包含 1GB 数据,可能应该禁止在栈上实例化它,而只允许在堆上创建其实例。为此,关键在于将析构函数声明为私有的

这样,便不能像下面创建 MonsterDB() 类的实例

上述代码试图在栈上创建实例。编译器知道,当 MyDataBase 不再在作用域内时,需要将其销毁,因此编译器自动在 main() 末尾调用析构函数,但是该析构函数是私有的,不可用,因此将导致上述语句编译失败
然而,将析构函数声明为私有的并不能禁止在堆中实例化

但是这个代码会导致内存泄露,由于在 main 中不能调用析构函数,因此也不等调用 delete,为解决这个问题,需要在 MonsterDB 类中提供一个销毁实例的静态共有函数(作为类成员,它能够调用析构函数)

9.7 this 指针
在类中,关键字 this 包含当前对象的地址,换句换说,其值为 &object
当在类成员方法中调用其他类成员方法时,编译器将隐式地传递 this 指针
如,

这里,方法 IntroduceSelf() 使用私有成员函 Talk(),编译器将在调用 Talk 时嵌入 this 指针,即 Talk(this, "bala bala");
我们也可以这样使用 this 指针,

【注】调用静态方法时,不会隐式地传递 this 指针,因为静态函数不与类实例相关联,而由所有实例共享
如果要在静态函数中使用实例变量(即非静态成员变量),应显示地声明一个形参,让调用者将实参设置为 this 指针
9.8 将 sizeof() 用于类
用于类时,sizeof() 只考虑成员变量,不考虑成员函数及其定义的局部变量
9.9 结构体不同于类的地方
结构体与类极其相似,差别在于程序员未指定时,默认的访问限定符不同:
- 除非指定,否则结构体中的成员默认为公有的,而类成员默认为私有的
- 除非指定,否则结构体以公有方式继承基结构,而类为私有继承
【结构体不同于类的地方】
在面试中问到这个问题,最关键的是回答到上面的两点
下面是其他的一些区别,了解即可:
- 结构体是一种值类型,而类是引用类型。值类型用于存储数据的值,引用类型用于存储对实际数据的引用
- 结构使用栈存储,而类使用堆存储
9.10 声明友元
不能从外部访问类的私有数据成员和方法,但这条规则不适用于友元类和友元函数
#include <iostream>
#include <string>
using namespace std;
class Human
{
private:
string name;
int age;
friend void getAge(const Human& Person);
public:
Human(string inputname, int inputage){
name = inputname;
age = inputage;
}
};
void getAge(const Human& Person){
cout << Person.age << endl;
}
int main()
{
Human somebody("Adam", 25);
cout << "Accessing private member age via friend: ";
getAge(somebody);
}
与函数一样,也可以将外部类指定为可信任的朋友
#include <iostream>
#include <string>
using namespace std;
class Human
{
private:
string name;
int age;
friend class FriendCls;
public:
Human(string inputname, int inputage){
name = inputname;
age = inputage;
}
};
class FriendClass
{
public:
static void getAge(const Human& Person)
{
cout << Person.age << endl;
}
};
int main()
{
Human somebody("Adam", 25);
cout << "Accessing private member age via friend class: ";
FriendClass::getAge(somebody);
}
10 继承
10.1 继承基础
C++ 派生语法如下:

access-specifier 可以是 public (表示派生类是一个基类)、private 或 protected(表示派生类有一个基类)
访问限定符 protected
将属性声明为 protected 时,相当于允许派生类和友元类访问它,但禁止在继承层次结构外部(包括 main)访问它
class Fish
{
protected:
bool FreshWaterFish; // accessible only to derived classes
public:
void Swim()
{
if(FreshWaterFish) cout << "Swims in lake" << endl;
else cout << "Swims in sea" << endl;
}
};
class Tuna: public Fish
{
public:
Tuna(){FreshWaterFish = false;}
};
class Carp: public Fish
{
public:
Carp(){FreshWaterFish = true;}
};
int main()
{
Carp onefish;
// onefish.FreshWaterFish = false; // compile error
}
基类初始化——向基类传递参数
如果基类包含重载的构造函数,需要在实例化时给它提供实参,怎么办?创建派生对象时,又将如何实例化这样的基类?
方法是使用初始化列表,并通过派生类的构造函数调用合适的基类构造函数

例如,
class Fish
{
protected:
bool FreshWaterFish; // accessible only to derived classes
public:
Fish(bool isFreshWater):FreshWaterFish(isFreshWater){}
};
class Tuna: public Fish
{
public:
Tuna():Fish(false){}
};
class Carp: public Fish
{
public:
Carp():Fish(true){}
};
在派生类中覆盖基类的方法
如果派生类实现了从基类继承的函数,且返回值和特征标相同,就相当于覆盖了基类的这个方法

如果使用 Derived 类的实例调用方法 DoSomething(),调用的将不再是 Base 类中的这个方法
调用基类中被覆盖的方法
假设此时 Tuna 类和 Carp 类都定义了自己的 Swim(),如果想要在 main() 中调用 Fish::Swim(),需要使用作用域解析运算符( :: ),如 onefish.Fish::Swim()
在派生类中调用基类的方法
通常,Fish::Swim() 包含适用于所有鱼类的通用实现。如果要在 Tuna::Swim() 和 Carp::Swim() 的实现中重用 Fish::Swim() 的通用实现,可以使用作用域解析运算符( :: )

在派生类中隐藏基类的方法
覆盖的一种极端情形是,Tuna::Swim() 可能隐藏 Fish::Swim() 的所有重载版本,使得调用这些重载版本会导致编译错误
#inclue <iostream>
using namespace std;
class Fish
{
public:
void Swim(){
cout << "Fish swims ...!" << endl;
}
void Swim(bool FreshWaterFish){
if(FreshWaterFish) cout << "Swims in lake" << endl;
else cout << "Swims in sea" << endl;
}
};
class Tuna: public Fish
{
public:
void Swim(){
cout << "Tuna swims real fast" << endl;
}
};
int main()
{
Tuna onefish;
// onefish.Swim(false); // compile failure: Fish::Swim(bool) is hidden
onefish.Swim();
}
上述代码的运行结果,就只输出 Tuna swims real fast,由于 Tuna 实现了自己的 Tuna::Swim(),这使得编译器隐藏了 Fish::Siwm(bool)
要通过 Tuna 实例调用 Fish::Swim(bool),可采用如下解决方法
- 使用作用域解析运算符,
onfish.Fish::Swim(); - 在 Tuna 类中,使用关键字 using 解除对
Fish::Swim()的隐藏

- 在 Tuna 类中,覆盖
Fish::Swim()的所有重载版本

构造顺序
基类对象在派生类对象之前被实例化,因此,首先构造 Tuna 对象的 Fish 部分,这样实例化 Tuna 部分时,成员属性(具体地说是 Fish 的保护和公有属性)已准备就绪,可以使用了
实例化 Fish 部分和 Tuna 部分时,先实例化成员属性,在调用构造函数,确保成员属性准备就绪,可供构造函数使用
析构顺序
Tuna 实例不再在作用域内时,析构顺序与构造顺序相反
【继承中的构造顺序和析构顺序是笔试、面试中常考的问题,现做如下总结】
当派生类中不含对象成员时
- 在创建派生类对象时,构造函数的执行顺序是:基类的构造函数 → 派生类的构造函数
- 在撤消派生类对象时,析构函数的执行顺序是:派生类的构造函数 → 基类的构造函数
派生类中含有对象成员时
- 在定义派生类对象时,构造函数的执行顺序:基类的构造函数 → 对象成员的构造函数 → 派生类的构造函数
- 在撤消派生类对象时,析构函数的执行顺序:派生类的构造函数 → 对象成员的构造函数 → 基类的构造函数
10.2 私有继承
私有继承意味着在派生类的实例中,基类的所有公有成员和方法都是私有的——不能从外部访问

例如上面的代码,即便是 Base 类的公有成员和方法,也只能被 Derive 类使用,而无法通过 Derived 实例来使用他们
从继承层次结构外部看,私有继承并非 is-a 的关系,私有继承使得只有之类才能使用基类的属性和方法,因此也被称为 has-a 的关系
假如现在我们再定义一个 Derived2 类,它继承了 Derived 类,则不管 Derived2 和 Derived 之间的继承关系是什么样的,Derived2 都不能访问基类 Base 的公有成员和方法
10.3 保护继承
保护继承与私有继承有如下的相似之处:
- 保护继承也是 has-a 的关系
- 保护继承也让派生类 能够访问基类的所有公有成员和保护成员
- 在继承层次结构外面,也不能通过派生类实例访问基类的公有成员

但是随着继承层次的加深,保护继承与私有继承有些不同

在保护继承层次结构中,子类的子类能够访问基类的公有成员
组合(聚合)
将 Base 对象作为 Derived 类的私有成员被称为组合或聚合,这是一种不错的设计,让人能够轻松地在子类中添加基类成员,而无需改变继承层次机构

10.4 切除问题
如果我们有下面的代码,执行的结果如何?

如果我们有下面的代码,执行的结果又将如何?

两个代码都将 Derived 对象复制给 Base 对象,第一个代码是通过显示复制,第二个代码是通过传递参数。在这些情况下,编译器将只复制 objDerived 的 Base 部分,即不是整个对象,而是 Base 能容纳的部分
这种无意间裁减数据,导致 Derived 变成 Base 的行为称为切除
要避免切除问题,不要按值传递参数,而应以指向基类的指针或 const 引用的方式传递
10.5 多继承
例如,

#include <iostream>
using namespace std;
class Mammal
{
public:
void FeedBabyMilk(){
cout << "Mammal: baby says glug!" << endl;
}
};
class Reptile
{
public:
void SpitVenom(){
cout << "Reptile: shoo enemy! Spits venom" << endl;
}
};
class Bird
{
public:
void LayEggs(){
cout << "Bird: laid my eggs!" << endl;
}
};
class Platypus: public Mammal, public Reptile, public Bird
{
public:
void Swim(){
cout << "Platypus: Voila, I can swim!" << endl;
}
};
int main()
{
Platypus realFreak;
realFreak.FeedBabyMilk();
realFreak.SpitVenom();
realFreak.LayEggs();
realFreak.Swim();
}
11 多态
11.1 多态基础
使用虚函数实现多态行为
可以通过 Fish 指针或 Fish 引用来访问 Fish 对象,这种指针或引用可指向 Fish、Tuna、Carp 对象。如果希望通过这种指针或引用调用 Swim() 时,如果它们指向的是 Tuna 对象,则可像 Tuna 那样游泳;如果指向的是 Carp 对象,则可像 Carp 那样游泳;如果指向的是 Fish,则可像 Fish 那样游泳
为此,可在基类 Fish 中将 Swim() 声明为虚函数

例如,
#include <iostream>
using namespace std;
class Fish
{
public:
virtual void Swim(){cout << "Fish swims!" << endl;}
};
class Tuna: public Fish
{
public:
// override Fish::Swim
void Swim(){cout << "Tuna swims!" << endl;}
};
class Carp: public Fish
{
public:
// override Fish::Swim
void Swim(){cout << "Carp swims!" << endl;}
};
void FishSwim(Fish& fish){fish.Swim();}
int main()
{
Tuna onefish;
Carp twofish;
FishSwim(onefish);
FishSwim(twofish);
}
运行结果为

『重载和重写的区别』
1. 重载:在同一个类中,函数名相同,参数列表不同,编译器会根据这些函数的不同参数列表,将同名的函数名称做修饰,从而生成一些不同名称的预处理函数,没有体现多态
2. 重写:子类重新定义父类中有相同名称相同参数的虚函数,主要体现在继承关系中,被重写的必须是虚函数,体现了多态
为何需要虚构造函数
#include <iostream>
using namespace std;
class Fish
{
public:
void Swim(){cout << "Fish swims!" << endl;}
};
class Tuna: public Fish
{
public:
// override Fish::Swim
void Swim(){cout << "Tuna swims!" << endl;}
};
void FishSwim(Fish& fish){fish.Swim();}
int main()
{
Tuna onefish;
onefish.Swim();
FishSwim(onefish);
}
运行结果为

将派生类对象传递给基类参数时,并通过该参数调用函数时,将执行基类的函数。然而,还存在一个问题:如果基类指针指向的是派生类对象,通过该指针调用运算法 delete 时,将会调用哪个析构函数呢?
#include <iostream>
using namespace std;
class Fish
{
public:
Fish(){cout << "Constructed Fish" << endl;}
~Fish(){cout << "Destroyed Fish" << endl;}
};
class Tuna: public Fish
{
public:
Tuna(){cout << "Constructed Tuna" << endl;}
~Tuna(){cout << "Destroyed Tuna" << endl;}
};
void DeleteFishMemory(Fish* pFish){delete pFish;}
int main()
{
cout << "Allocating a Tuna on the free store:" << endl;
Tuna* pTuna = new Tuna;
cout << "Deleting the Tuna:" << endl;
DeleteFishMemory(pTuna);
cout << "Instantiating a Tuna on the stack:" << endl;
Tuna onefish;
cout << "Automatic destruction as it goes out of scope:" << endl;
}
运行结果为

通过该例子表明,对于使用 new 在自由存储区中实例化的派生对象,如果将其赋给基类指针,并通过该指针调用 delete,将不会调用派生类的析构函数。这可能导致资源未释放、内存泄露等问题
要避免这种问题,可将析构函数声明为虚函数
#include <iostream>
using namespace std;
class Fish
{
public:
Fish(){cout << "Constructed Fish" << endl;}
virtual ~Fish(){cout << "Destroyed Fish" << endl;}
};
class Tuna: public Fish
{
public:
Tuna(){cout << "Constructed Tuna" << endl;}
~Tuna(){cout << "Destroyed Tuna" << endl;}
};
void DeleteFishMemory(Fish* pFish){delete pFish;}
int main()
{
cout << "Allocating a Tuna on the free store:" << endl;
Tuna* pTuna = new Tuna;
cout << "Deleting the Tuna:" << endl;
DeleteFishMemory(pTuna);
cout << "Instantiating a Tuna on the stack:" << endl;
Tuna onefish;
cout << "Automatic destruction as it goes out of scope:" << endl;
}
务必像下面这样将基类的析构函数声明为虚函数,这可避免将 delete 用于 Base 指针时不会调用派生类的析构函数

虚函数的工作原理——虚函数表

编译器见到这种继承层次结构后,知道 Base 定义了一些虚函数,并在Derived中覆盖了它们。在这种情况下,编译器将为实现了虚函数的基类和覆盖了虚函数的派生类分别创建一个虚函数表(Virtual FunctionTable,VFT)。换句话说,Base 和 Derived 类都将有自己的虚函数表
实例化这些类的对象时,将创建一个隐藏的指针(VFT*),它指向相应的 VFT
可将 VFT 视为一个包含函数指针的静态数组,其中每个指针都指向相应的虚函数,如下图所示

每个虚函数表都是由函数指针组成,其中每个指针都指向相应虚函数的实现。在 Derived 的虚函数表中,除 Func2 的函数指针外,其他所有函数指针都指向 Derived 本地的虚函数实现。Derived 没有覆盖 Base::Func2() ,因此相应的函数指针指向 Base 类的 Func2() 实现
在 C++ 中,可使用类型转换运算符 dynamic_cast 确定 Base 指针指向的是否是 Derived 对象,再根据结果执行额外的操作。这被称为运行阶段类型识别(RTTI)
抽象基类和纯虚函数
不能实例化的基类被称为抽象基类,这样的基类只有一个用途,那就是从它派生出其他的类
在 C++ 中,要创建抽象基类,可声明纯虚函数

AbstractBase 类要求 Derived 类必须提供虚方法 Dosomething() 的实现。这让基类可指定派生类中方法的名称和特征,即指定派生类的接口

例如,
#include <iostream>
using namespace std;
class Fish
{
public:
virtual void Swim() = 0;
};
class Tuna: public Fish
{
public:
void Swim(){cout << "Tuna swims fast in the sea!" << endl;}
};
class Carp: public Fish
{
public:
void Swim(){cout << "Carp swims fast in the lake!" << endl;}
};
void FishSwim(Fish& fish){fish.Swim();}
int main()
{
Tuna onefish;
Carp twofish;
FishSwim(onefish);
FishSwim(twofish);
}
抽象基类常被简称为 ABC,ABC 有助于约束程序的设计
11.2 使用虚继承解决菱形问题
鸭嘴兽具备哺乳动物、鸟类和爬行类动物的特征,这意味着 Platypus 类需要继承 Mammal、Bird 和 Reptile 类。然而,这类类都是从同一个类 Animal 派生来的

考虑下面这个代码呈现的问题,

我们创建一个 Platypus 的实例,自动创建了三个 Animal 实例。如果你想运行 duckBilledP.Age=25; 编译器会报错,应为它不知道你要设置的是 Mammal::Animal::Age、Bird::Animal::Age 还是 Reptile::Animal::Age,更有意思的是你还能分别执行下面三条代码,简直不要太乱来
duckBilledP.Mammal::Animal.Age=25;
duckBilledP.Bird::Animal.Age=25;
duckBilledP.Reptile::Animal.Age=25;
要解决这个问题可以使用虚继承,如果派生类可能被用作基类,派生它时最好使用关键字 virtual

所以针对上面的代码,修改如下
#include <iostream>
using namespace std;
class Animal
{
public:
int Age;
Animal(){cout << "Animal constructor" << endl;}
};
class Mammal: public virtual Animal
{
};
class Bird: public virtual Animal
{
};
class Reptile: public virtual Animal
{
};
class Platypus: public Mammal, public Bird, public Reptile
{
public:
Platypus(){cout << "Platypus constructor" << endl;}
};
int main()
{
Platypus duckBilledP;
duckBilledP.Age = 25;
}
在继承层次结构中,继承多个从同一个类派生而来的基类时,如果这些基类没有采用虚继承,将导致二义性,这种二义性就称为菱性问题
11.3 可将复制构造函数声明为虚函数吗
要实现虚复制构造函数是不可能的,因为在基类方法声明中使用关键字 virtual 时,表示它将被派生类的实现覆盖,这种多态行为是在运行阶段实现的。而构造函数只能创建固定类型的对象,不具备多态性,因此 C++ 不允许使用虚复制构造函数
虽然如此,还是存在一种不错的解决方案,就是定义自己的克隆函数来实现虚复制构造函数的目的

虚函数 Clone 模拟了虚复制构造函数,但需要显示地调用,如下代码所示
#include <iostream>
using namespace std;
class Fish
{
public:
virtual Fish* Clone() = 0;
virtual void Swim() = 0;
};
class Tuna: public Fish
{
public:
Fish* Clone(){return new Tuna(*this);}
void Swim(){cout << "Tuna swims fast in the sea" << endl;}
};
class Carp: public Fish
{
public:
Fish* Clone() {return new Carp(*this);}
void Swim(){cout << "Carp swims slow in the lake" << endl;}
};
int main()
{
const int ARRAY_SIZE = 4;
Fish* myFishes[ARRAY_SIZE] = {NULL};
myFishes[0] = new Tuna();
myFishes[1] = new Carp();
myFishes[2] = new Tuna();
myFishes[3] = new Carp();
Fish* myNewFishes[ARRAY_SIZE];
for(int i=0;i<ARRAY_SIZE;i++)
myNewFishes[i] = myFishes[i]->Clone();
for(int i=0;i<ARRAY_SIZE;i++)
myNewFishes[i]->Swim();
for(int i=0;i<ARRAY_SIZE;i++)
{
delete myFishes[i];
delete myNewFishes[i];
}
}
12 运算符类型与运算符重载
12.1 C++ 运算符
运算符声明看起来与函数声明极其相似:return_type operator operator_symbl (...parameter list...)
12.2 单目运算符
单目递增与单目递减运算符
要在类声明中编写单目前缀递增运算符,可采用如下语法

而后缀递增运算符(++)的返回值不同,且有一个输入参数

在上述后缀运算符的实现中,首先复制了当前对象,再将当前对象执行递增或递减,之后返回复制的对象
class Date
{
private:
int day, month, year;
public:
Date(int _d, int _m, int _y) : day(_d), month(_m), year(_y);
Date& operator ++ (){
++day;
return *this;
}
Date& operator -- (){
--day;
return *this;
}
Date operator ++ (int){
Date Copy(day, month, year);
++day;
return Copy;
}
Date operator -- (int){
Date Copy(day, month, year);
--day;
return Copy;
}
void display(){
cout << day << "/" << month << "/" << year << endl;
}
};
转换运算符
如果对于上面 Date 类的实例 holiday,使用如下的输出方式:cout << holiday,会导致编译错误,因为 cout 不知道如何解读 Date 实例,因为 Date 类不支持相关的运算符
然而,cout 能够很好地显示 const char*,例如,std::cout << "hello word";
因此,要让 cout 能够显示 Date 对象,只需添加一个返回 const char* 的运算符

通过上面的代码,我们甚至可以将 Date 对象直接赋给 string 对象

解除引用运算符(*)和成员选择运算符(->)
解除引用运算符和成员选择运算符在智能指针类编程中应用最广。智能指针 是封装常规指针的类,旨在通过管理所有权和复制问题简化内存管理
在下面的程序中使用了 std::unique_ptr,它使用了运算符 * 和 ->,让我们能够像使用普通指针那样使用智能指针
#include <iostream>
#include <memory> // include this to use std::unique_ptr
using namespace std;
class Date
{
private:
int day, month, year;
string DateInString;
public:
Date(int _d, int _m, int _y) : day(_d), month(_m), year(_y);
void display(){
cout << day << "/" << month << "/" << year << endl;
}
};
int main()
{
unique_ptr<int> p(new int);
*p = 42;
// use smart pointer like an int*
cout << "Integer value is:" << *p << endl;
unique_ptr<Date> pHoliday(new Date(25, 11, 2021));
cout << "The new instance of date contains:";
pHoliday->display();
// no need to do the following when using unique_ptr
// delete p;
// delete pHoliday;
}
我们也可以自己实现一个简单的智能指针
#include <iostream>
using namespace std;
template <typename T>
class smart_pointer
{
private:
T* m_pRawPointer;
public:
smart_pointer(T* pData) : m_pRawPointer (pData) {} // constructor
~smart_pointer(){delete m_pRawPointer;} // destructor
T& operator * () const{return *(m_pRawPointer_);} // dereferencing operator
T* operator -> () const{return m_pRawPointer;} // member selection operator
};
class Date
{
private:
int day, month, year;
string DateInString;
public:
Date(int _d, int _m, int _y) : day(_d), month(_m), year(_y);
void display(){
cout << day << "/" << month << "/" << year << endl;
}
};
int main()
{
smart_pointer<int> p(new int(42));
cout << "Integer value is:" << *p << endl; // use smart pointer like an int*
smart_pointer<Date> pHoliday(new Date(25, 11, 2021));
cout << "The new instance of date contains:";
pHoliday->display();
}
12.3 双目运算符
双目加法与双目减法运算符
我们还是以 Date 类为例,

另外一个值得讨论的例子是在 MyString 类中实现利用加号将两个字符串拼接起来(MyString 类封装 C 风格字符串)

运算符 += 与 -=
我们还是以 Date 类为例,

等于运算符和不等于运算符
我们还是以 Date 类为例,

大于运算符和大于等于运算符(小于和小于等于)
我们还是以 Date 类为例,

复制赋值运算符
与复制构造函数一样,为确保进行深复制,我们需要提供复制赋值运算符

如果编写的类管理着动态分配的资源、动态数组等,除构造函数和析构函数外,必须实现复制构造函数和复制赋值运算
要创建不允许复制的类,可将复制构造函数和复制赋值运算符都声明为私有的。 这样声明(甚至都不用提供实现)就足以让编译器在遇到试图复制对象的代码时引发错误
下标运算符
下标运算符让我们能够像访问数组那样访问类,其典型语法如下:return_type& operator [] (subscript_type& subscript)
编写封装了动态数组的类时,通过实现下标运算符,可轻松地随机访问缓冲区中的各个字符。例如,在 MyString 类中重载下标运算符

我们来看一下上面的两个 const,第一个将下标运算符的返回类型声明成了 const char&,主要是考虑禁止从外部通过运算符 [] 直接修改成员 MyString::buffer,如

第二个将该运算符的函数类型设置为 const,这将禁止该运算符修改类的成员属性
【const 放函数前后有什么区别呢?】
int Func() const; 该函数为只读函数,不允许修改其中的数据成员的值
const int* Func(); 修饰的是返回值,表示返回的是指针所指向值是常量。所以,上面代码中,SayHello[2] 返回的是一个常量字符数组,所以不能修改该字符数组
但是我们也可以同时实现两个下标运算符,其中一个为 const 函数,另外一个为非 const 函数

编译器很聪明,能够在读取 MyString 对象时调用 const 函数,而在对 MyString 执行写入操作时调用非 const 函数。因此,如果愿意,可在两个下标函数函数中实现不同的功能。例如,一个运算符记录对容器的写入操作,而另一个记录对容器的读取操作
12.4 函数运算数 operator()
operator() 让对象像函数一样,被称为函数运算符。函数运算符用于标准模板库中,通常是 STL 算法。根据使用的操作数数量,这样的函数对象通常称为单目谓词或双目谓词
我们看一个例子,很容易就理解
#include <iostream>
using namespace std;
class CDisplay
{
public:
void operator () (string Input) const{
cout << Input << endl;
}
};
int main()
{
CDisplay obj;
obj("Display this string!");
return 0;
}
12.5 不能重载的运算符

13 类型转换运算符
13.1 为何需要类型转换
如果 C++ 应用程序都编写的很完善 且处于类型是安全的且是强类型的世界,则没有必要进行类型转换,也不需要类型转换运算符。然而,在现实世界中不同模块往往有使用不同环境的个人和厂商编写,他们需要相互协作。因此,程序员经常需要让编译器按其所需的方式解释数据,让应用程序能够成功编译并正确执行
13.2 为何有些 C++ 程序员不喜欢 C 风格类型转换
实际上,大多数 C++ 编译器都不会让下面这样的语句通过编译

C++ 编译器仍需向后兼容,以确保遗留代码能够通过编译,因此支持下面这样的语法

然而,C 风格类型转换实际上强迫编译器根据程序员的选择来解释目标对象。就上述代码而言,程序员并不认为编译器报告的错误是合理的,因此强迫编译器遵从自己的医院。然而,对于不希望因类型转换而破坏 C++ 类型安全的程序员来说,这是无法接受的
13.3 C++ 类型转换运算符
C++ 有 4 个类型转换运算符:
- static_cast
- dynamic_cast
- reinterpret_cast
- const_cast
这 4 个类型转换运算符的使用语法相同:destination_type result = cast_type <destination_type> (obj_to_be_casted)
使用 static_cast
static_cast 用于在相关类型的指针之间进行转换,还可显示地执行标准数据类型的类型转换
用于指针时,static_cast 实现了基本的编译阶段检查,确保指针被转换为相关类型。这改进了 C 风格类型转换,在 C 语言中可将指向一个对象的指针转化为完全不相关的类型,而编译器不会报错。使用 static_cast 可将指针向上转化为基类类型,也可向下转化为派生类型

将 Derived* 转换为 Base* 就称为向上转换,无需使用任何显示类型转换运算符就能进行。而将 Base* 转换为 Derived* 称为向下转换,如果不使用显示类型转换运算符,就无法进行

然而,staic_cast 只验证指针类型是否相关,而不会执行任何运行阶段检查。因此,程序员可以使用 static_cast 编写如下代码,而编译器不会报错

其中 pDerived 实际上指向一个不完整的 Derived 对象,因为它指向的对象实际上是 Base() 类型。由于 static_cast 只在编译阶段检查转换类型是否先关,而不执行运行阶段检查。因此,pDerived->someDerivedClassFunc() 能够通过编译,但在运行阶段却可能导致意外结果
除用于向上/向下转换,static_cast 还可在很多情况下将隐式类型转换为显示类型,以引起编码人员的注意

使用 dynamic_cast
顾名思义,与静态类型转换相反,动态类型转换在运行阶段执行类型转换。使用 dynamic_cast 运算符的典型语法如下
destination_type* pDest = dynamic_cast<class_type*>(pSource);
if(pDest) // check for success of the casting before using
pDest->Func();
如果 dynamic_static 的返回值为 NULL,则说明转换失败
使用 reinterpret_cast
reinterpret_cast 是 C++ 中与 C 风格类型转换最接近的类型转换运算符,它让程序员能够将一种对象类型转换为另一种,不管它们是否相关

这种类型转换实际上是强制编译器接受 static_ cast 通常不允许的类型转换,通常用于低级程序(如驱动程序),在这种程序中,需要将数据转换为 API 能够接收的简单类型(如某些 API 只能使用字节流,即 unsigned char*)
使用 const_cast
const_cast 让程序员能够关闭对象的访问修饰符 const
但是可能会有一个问题:为何要进行这种转换?我们来看一下下面的这个例子

在这种情况下,const_cast 就成为了我们的救星

但是除非不到万不得已,否则不要使用 const_cast 来调用非 const 函数。一般而言,使用 const_cast 来修改 const 对象可能导致不可预料的行为
另外,const_cast 也可用于指针

13.4 C++ 类型转换运算符存在的问题
我们来比较一下下面的代码

在这 3 种方法中,程序员得到的结果都相同。在实际情况下,第二种方法可能最常见,但几乎没有人使用第一种方法
同样,static_cast 的其他用途也可使用使用 C 风格类型转换进行处理,而且更简单

因此,使用 static_cast 的优点常常被其拙劣的语法所掩饰
再看看其他运算符。在不能使用 static_cast 时,可使用 reinterpret_cast 强制进行转换;同样,可以使用 const_cast 修改访问修饰符 const
但是,在现代 C++ 中,除 dynamic_cast 外的类型转换都是可以避免的。仅当需要满足遗留应用程序的需求时,才需要使用其他类型转换运算符。在这种情况下,程序员通常倾向于使用 C 风格类型转换而不是 C++ 类型转换运算符
重要的是,应尽量避免使用类型转换。而一旦使用类型转换,务必要知道幕后发生的情况
14 模板
14.1 模板声明语法
关键字 template 标志着模板声明的开始,接下来是模板参数列表,该参数列表哦包含关键字 typename,它定义了模板参数 objectType,objectType 是一个占位符,针对对象实例化模板时,将使用对象的类型替换它
template <typename T1, typename T2=T1>
bool TemplateFunc(const T1& param1, const T2& param2);
template <typename T1, typename T2=T1>
class Template
{
private:
T1 m_obj1;
T2 m_obj2;
public:
T1 getobj1(){return m_obj1;}
};
上述代码演示了一个模板函数和一个模板类,它们都接受两个模板参数:T1 和 T2, 其中 T2 的类型默认为 T1
14.2 模板函数
我们定义一个适用于不同类型参数的取较大值函数
template <typename objectType>
const objectType& getmax(const objectType& value1, const objectType& value2)
{
if(value1 > value2) return value1;
else return value2;
}
下面是一个使用该模板的示例
int num1 = 25;
int num2 = 40;
int maxvalue1 = getmax<int>(num1, num2);
double num3 = 1.1;
double num4 = 1.001;
double maxvalue2 = getmax<double>(num3, num4);
上述代码将会导致编译器生成模板函数 getmax 的两个版本,如下所示
const int& getmax(const int& value1, const int& value2)
{
...
}
const int& getmax(const int& value1, const int& value2)
{
...
}
然而,实际上调用模板函数时并非一定要指定类型,因此下面的函调用没有任何问题
int maxvalue = getmax(num1, num2);
在这种情况下,编译器很聪明,知道这是针对整型调用模板函数。然而,对于模板类,必须显示地指定类型
14.3 模板类
template <typename T>
class MyTemplateClass
{
private:
T value;
public:
void setvalue(const T& newvalue){value = newvalue;}
const T& getvalue() const {rerurn value;}
};
下面给出该模板类的一种用法:
MyTemplateClass<int> HoldInteger;
HoldInteger.setvalue(5);
std::cout << HoldInteger.getvalue();
这里使用该模板类来存储和检索类型为 int 的对象,同样,这个类也可以用于处理字符串
MyTemplateClass<char*> HoldString;
HoldString.setvalue("Hello world");
std::cout << HoldInteger.getvalue();
14.4 模板的实例化和具体化
对于模板,术语实例化的含义稍稍不同。用于类时,实例化通常值的是根据类创建对象。但是用于模板时,实例化指的是根据模板声明一个或多个参数创建特定的类型
对于下面的模板声明
template <typename T>
class TemplateClass
{
T m_member;
};
使用该模板时将编写这样的代码
TemplateClass<int> IntClass;
这种实例化创建的特定类型称为具体化
14.5 声明包含多个参数的模板
模板参数列表可以包含多个参数,参数之间用逗号分隔。因此,如果要声明一个泛型类用于存储两个类型可能不同的对象,可以使用如下所示的代码
template<typename T1, typename T2>
class Pairs
{
private:
T1 value1;
T2 value2;
public:
Pairs(const T1& x, const T2& y ){
value1 = x;
value2 = y;
}
};
在这里,类 Pairs 接受两个模板参数,参数名分别为 T1 和 T2,可使用这个类来存储两个类型相同或不同的对象
Pairs<int, double> PairIntDouble(6, 1.99);
Pairs<int, int> PairInt(6, 500);
14.6 声明包含默认参数的模板
可以修改前面的 Pairs,将模板参数的默认类型指定为 int
template<typename T1=int, typename T2=int>
class Pairs
{
...
};
14.7 模板类和静态成员
我们知道在类中,将成员声明为静态的,该成员将由类的所有实例共享。那么在模板类中,声明静态成员呢?
模板类的静态成员与之类似,由特定具体化的所有实例共享。也就是说,如果模板类 T 包含静态成员 x,该成员将在针对 int 具体化的所有实例之间共享
#include <iostream>
using namespace std;
template <typename T>
class TestStatic
{
public:
static int StaticValue;
};
template<typename T> int TestStatic<T>::StaticValue;
int main()
{
TestStatic<int> Int_Year;
TestStatic<int> Int_2;
cout << "Setting StaticValue for Int_Year to 2021" << endl;
Int_Year.StaticValue = 2021;
TestStatic<double> Double_1;
TestStatic<double> Double_2;
cout << "Setting StaticValue for Double_2 to 1011" << endl;
Double_2.StaticValue = 1011;
cout << "Iny_2.StaticValue = "<< Int_2.StaticValue << endl;
cout << "Double_1.StaticValue = " << Double_1.StaticValue << endl;
}

尤其注意第 11 行的代码不可或缺,它初始化模板类的静态成员,通用的初始化语法如下
template<typename parameters> Statictype ClassName<Template Arguments>::StaticVarName;
【使用 static_assert 执行编译阶段检查】
static_assert 是 C++11 新增的一项功能,让我们能够在不满指定条件时禁止编译。例如,可能我们想要禁止针对 int 实例化模板类,为此可以使用 static_assert,它是一种编译阶段断言,可用于在控制台中显示一条自定义的消息:
static_assert(expression being validated, "Erroer message when check fails");
要禁止针对类型 int 实例化模板类,可使用 static_assert(),并将 sizeof(T) 与 sizeof(int) 进行比较,如果相等,就显示一条错误消息
static_assert(sizeof(T)!=sizeof(int), "No int please!");
15 标准模板库简介
15.1 STL 容器
【常用容器及其底层实现】
1. std::vector,底层实现:动态数组
2. std::deque,底层实现:

详细可以参考 C++ STL deque容器底层实现原理(深度剖析)
3. std::list,底层实现:双向链表
详细可以参考 C++ STL list容器底层实现(详解版)
4. std::set,底层实现:红黑树
5. std::map,底层实现:红黑树
6. std::unorder_map,底层实现:哈希表,处理冲突的方法就是在相同哈希值的元素位置下面挂上桶,当数据量在
8
8
8 以内使用链表来实现桶,当数据量大于
8
8
8 则自动转换为红黑树结构
15.2 STL 迭代器
【迭代器失效问题】
STL容器根据迭代器的失效问题,其实可以分为两类容器:
(1)数组型容器的插入删除操作:vector、string、deque(均为顺序存储)
由于这类容器的插入或删除都会使所有迭代器失效,因此每次插入删除后都需要重新定位
(2)结点型数据容器的插入删除操作:list(使用链表存储)、map(使用红黑树存储)、set(使用红黑树存储)
由于这类容器只有删除时会失效当前迭代器,而插入时不会使任何迭代器失效, 因此插入时不需重新定位,但是删除时需重新定位
接着上面的讨论,我们再通过下面两个问题来深入理解一下迭代器的工作原理
【为何 map 和 set 的插入删除效率比用其他序列容器高】
很简单,因为对于关联容器来说,不需要做内存拷贝和内存移动
说对了,确实如此,map和 set 容器内所有元素都是以节点的方式来存储,其节点结构和链表差不多,指向父节点和子节点。因此插入的时候只需要稍做变换,把节点的指针指向新的节点就可以了。删除的时候类似,稍做变换后把指向删除节点的指针指向其他节点就 OK 了。这里的一切操作就是指针换来换去,和内存移动没有关系
【对 map 和 set,为何每次 insert 之后,以前保存的 iterator 不会失效】
iterator 这里就相当于指向节点的指针,内存没有变,指向内存的指针怎么会失效呢(当然被删除的那个元素本身已经失效了)
相对于vector来说,每一次删除和插入,指针都有可能失效,调用push_back在尾部插入也是如此。因为为了保证内部数据的连续存放,iterator指向的那块内存在删除和插入过程中可能已经被其他内存覆盖或者内存已经被释放了。即使是push_back,容器内部空间可能不够,需要一块新的更大的内存,只有把以前的内存释放,申请新的更大的内存,复制已有的数据元素到新的内存,最后把需要插入的元素放到最后,那么以前的内存指针自然就不可用了。
16 STL string 类
【获取字符串指定下标元素】
有两种方式可以获取字符串中某一位置元素:
1. 下标操作符 [] 在使用时不检查索引的有效性,如果下标超出字符的长度范围,会示导致未定义行为
2. 函数 at() 在使用时会检查下标是否有效。如果给定的下标超出字符的长度范围,系统会抛出 out_of_range 异常
【整数转换为字符串】
int a = xxx;
stringstream ss;
ss << a;
string s = ss.str();
17 STL 动态数组
【统计 vector 中指定对象元素出现的次数】
1. count()
count(vec.begin(), vec.end(), value) 统计容器中等于 value 元素的个数
vector<int> vec{1, 2, 3, 1, 1};
cout << count(vec.begin(), vec.end(), 1) << endl;
2. count_if()
如果我们希望统计 1-10 中奇数的个数,这时该怎么做呢?
bool cmp(int num){return num%2;}
int main()
{
vector<int> vec;
for(int i=1;i<=10;i++) vec.push_back(i);
cout << count_if(vec.begin(), vec.end(), cmp) << endl;
}
cmp 比较函数是整个 count_if() 函数的核心,返回值是一个布尔型。count_if() 函数通过传递一个函数对象来作出比 count() 函数更加复杂的比较以确定一个对象是否应该被计数
【vector 转 set】
有些时候我们需要用到 set 完成去重的工作,然后再转回数组完成后续操作,此时可以按照如下代码进行
set<int> st(vec.begin(), vec.end());
vec.assign(st.begin(), st.end());
【vector 转 string】
类似于 Python 中利用 join() 将一个字符列表连接为字符串
string s;
vector<char> vec;
vec.assign(s.begin(), s.end());
s.assign(vec.begin(), vec.end());
【vector 插入删除的时间复杂度】
插入:push_back KaTeX parse error: Undefined control sequence: \mathcalO at position 1: \̲m̲a̲t̲h̲c̲a̲l̲O̲(1),insert O ( n ) \mathcal O(n) O(n);删除:pop_back O ( 1 ) \mathcal O(1) O(1),erase O ( n ) \mathcal O(n) O(n);访问 O ( 1 ) \mathcal O(1) O(1)
考虑数组的插入删除很容易理解每个操作的时间复杂度,但是考虑到 vector 会动态增长,push_back() 的时间复杂度为什么还是 O ( 1 ) \mathcal O(1) O(1) 呢?
考虑 vector 每次内存扩充两倍的情况
如果我们插入 N N N个元素, 则会引发 l g N lgN lgN次的内存扩充,而每次扩充引起的元素拷贝次数为 2 0 , 2 1 , 2 2 , . . . , 2 l g N 2^0, 2^1, 2^2, ..., 2^{lgN} 20,21,22,...,2lgN
再把所有的拷贝次数相加得到 2 0 + 2 1 + 2 2 + . . . + 2 l g N = 2 ∗ 2 l g N − 1 2^0 + 2^1 + 2^2 + ... + 2^{lgN} = 2 * 2^{lgN} - 1 20+21+22+...+2lgN=2∗2lgN−1 约为 2 N 2N 2N 次
共拷贝了 N N N次最后一个元素, 所以总的操作大概为 3 N 3N 3N,所以, 每个push_back操作分摊 3 次, 是 O ( 1 ) \mathcal O(1) O(1) 的复杂度
那么,为什么取 2 倍进行扩充呢?
我们先思考一个问题:为什么是成倍增长,而不是每次增长一个固定大小的容量呢?
解析如上一个问题,对比可以发现采用成倍方式扩容,可以保证常数的时间复杂度,而增加指定大小的容量会达到 O ( n ) O(n) O(n)的时间复杂度,因此,使用成倍的方式扩容更好
windows 下 vector 的扩充是 1.5 倍,linux 是 2 倍
那么问题又来了,为什么是以 2 倍或者 1.5 倍增长,而不是以 3 倍或者 4 倍等增长呢?主要考虑是空间和时间的权衡,简单来说,空间分配的多,均摊时间复杂度低,但是浪费空间多
到此为止,基本上就回答了为什么取 2 倍。如果想再深入一些,我们来看看 1.5 倍和 2 倍有什么区别呢?
以 2 倍的方式扩容,导致下一次申请的内存必然大于之前分配内存的总和,导致之前分配的内存不能再被使用,如下所示

看不懂为啥吧 ((*・∀・)ゞ→→
来再解释一遍,为啥不直接追加在原来的 vector 后面呢?因为一般分配器不支持 realloc(),因此,在应用层面只能分配一块新内存,然后再把旧的数据复制过去,释放之前的内存
那么,我们的理想分配方案就是在第 N N N 次 resize() 的时候能复用之前 N − 1 N-1 N−1 次释放的内存,但选择2倍的增长比如像这样 1,2,4,8,16,32,…
可以看到第三次 resize() 的时候,需要 4 个单位大小的空间,而前面释放的总和只有 1+2 = 3 个单位,到第四次 resize() 的时候,需要 8 个单位大小的空间,而前面释放的总和只有 1+2+4 = 7 个单位,每次需要申请的空间都无法用到前面释放的内存。所以,以 2 倍的方式扩容,导致下一次申请的内存必然大于之前分配内存的总和,导致之前分配的内存不能再被使用
同理,可以分析 1.5 倍下 vector 扩容的情况
18 STL list 和 forward_list
19 STL 集合类
【map 和 unordered_map 的其区别】
1. map 的内部实现为红黑树,unordere_map 的内部实现为哈希表
2. 介于 map 的内部实现是红黑树,所以 map 是有序的,且大部分操作在对数时间复杂度下就可以实现,但缺点就是为了维护红黑树的性质而造成空间占用率较大
3. unordered_map 的内部实现为哈希表,所以元素的排列是无序的,但是哈希表查找的时间复杂度只有 O ( 1 ) \mathcal O(1) O(1),因此很适用于有关查找的问题
20 STL 映射类
21 理解函数对象
22 lambda 表达式
23 STL 算法
24 栈和队列
25 STL 位标志
26 理解智能指针
26.1 什么是智能指针
鉴于使用常规指针以及常规的内存管理方法存在的问题,当 C++ 程序要需要管理堆(自由存储区)中的数据时,并非一定要使用它们,而可在程序中使用智能指针,以更智能的方式分配和管理内存
智能指针的行为类似常规指针,但通过重载的运算符和析构函数确保动态分配的数据能够及时地销毁
26.2 智能指针时如何实现的
智能指针重载了解除引用运算符(*)和成员选择运算符(->),让程序员可以像使用常规指针那样使用它们
另外,为了能够在堆中管理各种类型,几乎所有良好的智能指针都是模板类,包含其功能的泛型实现
下面,我们看一下智能指针类最基本的组成部分
template <typename T>
class smart_pointer
{
private:
T* m_pRawPointer;
public:
smart_pointer(T* pData): m_pRawPointer(pData){}
~smart_pointer(){delete pData};
smart_pointer(const smart_pointer& anotherSP);
smart_pointer& operator = (const smart_pointer& anotherSP);
T& operator * () const {return *(m_pRawPointer);}
T* operator -> () const {return m_pRawPointer};
};
构造函数接受一个指针,并将其保存到该智能指针类内部的一个指针对象中,析构函数释放该指针,从而实现了自动内存释放
使智能指针真正智能的是复制构造函数、复制运算符和析构函数的实现,他们决定了智能指针对象被传递给函数、赋值或离开作用域时的行为
26.3 智能指针类型
深复制
在实现深复制的智能指针中,每个智能指针实例都保存一个它管理的对象的完整副本。每当智能指针被复制时,将复制它指向的对象;每当智能指针离开作用域时,将释放它指向的内存
使用基于深复制的智能指针,解决切除问题
template <typename T>
class deepcopy_smart_pointer
{
private:
T* m_pObject;
public:
// copy constructor of the deepcopy pointer
deepcopy_smart_pointer(const deepcopy_smart_pointer& source){
// Clone() is virtual: ensures deep copy of Derived class object
m_pObject = source->Clone();
}
// copy assignment operator
deepcopy_smart_pointer& operator = (const deepcopy_smart_pointer& source){
if(m_pObject) delete m_pObject;
m_pObject = source->Clone();
}
};
下面是 deepcopy_smart_pointer 的一种用法
void MakeFishSwim(Fish fish){
fish.Swim(); // virtual fucntion
}
Carp onefish;
MakeFishSwim(onefish); // Carp will be sliced to Fish
// Slicing: only the Fish part of Carp is sent to MakeFishSwim()
deepcopy_smart_pointer<Carp> onefish(new Carp);
MakeFishSwim(onefish); // Carp will not be sliced
写时复制机制
写时复制机制(Copy on Write, COW)试图对深复制智能指针的性能进行优化,它共享指针,直到首次写入对象
首次调用非 const 函数时,COW 指针通常为该非 const 函数操作的对象创建一个副本,而其他指针实例仍共享源对象
实现 const 和非 const 版本的运算符 * 和 ->,是实现 COW 指针功能的关键
引用计数智能指针
引用计数是一种记录对象的用户数量的机制。当计数降低到零后,并将对象释放。因此引用技术提供了一种优良的机制,使得可共享对象而无法对其进行复制
这种智能指针被复制时,需要将对象的引用计数+1,至少有两种常用的方法来跟踪计数:
- 在对象中维护应用计数
- 引用计数由共享对象中的指针类维护
前者称为入侵式引用计数,因为需要修改对象,以维护和递增引用计数,并将其提供给管理对象的智能指针,COM 采用的就是这种方法
后者是智能指针类将计数保存在自由存储区,复制时复制构造函数将这个值+1
因此使用引用计数机制,程序员只应通过智能指针来处理对象。在使用智能指针管理对象的同时让原始指针指向它是一种糟糕的做法,因为智能指针将在它维护的引用计数减为零时释放对象,而原始指针将继续指向已不属于当前应用进程的内存
引用计数还有一个独特的问题:如果两个对象分别存储指向对方的指针,这两个对象将永远不会被释放,因为它们的生命周期依赖性导致其引用计数最少为 1
引用链接智能指针
引用链接智能指针,不主动维护对象的引用计数,而只需知道计数什么时候变为零,以便能够释放对象
之所以被称为引用链接,是因为其实现是基于双向链表的。通过复制智能指针来创建新智能指针时,新指针将被插入到链表中;当智能指针离开作用与进而被销毁时,虚构函数,将它从链表中删除。与引用计数的指针一样,引用链接指针也存在生命周期依赖性导致的问题
破坏性复制
破坏性复制是这样一种机制,即在智能指针被复制时,将对象的所有权转交给目标指针并重置原来的指针
destructive_copy_smartptr <SampleClass> pSmartPtr(new SampleClass());
Func(pSmartPtr); // Ownership transferred to Func
// Don't use pSmartPtr in the caller any more
虽然破坏性复制机制使用起来并不直观,但它有一个优点,即可确保任何时刻只有一个活动指针指向对象
template <typename T>
class destructive_copy_pointer
{
private:
T* pObject;
public:
destructive_copy_pointer(T* pInput):pObject(pInput){}
~destructive_copy_pointer(){delete pObject;}
destructive_copy_pointer(destructive_copy_pointer& source){
pObject = source.pObject;
source.pObject = 0;
}
destructive_copy_pointer& operator = (destructive_copy_pointer& source){
if(pObject!=source.pObject)
{
delete pObject;
pObject = source.pObject;
source.pObject = 0;
}
}
};
int main()
{
destructive_copy_pointer<int> pNum(new int);
destructive_copy_pointer<int> pCopy = pNum;
// now, pNum is invalid
}
std::auto_ptr 是最流行的破坏性复制指针,被传递给函数或复制给另一个指针后,这种智能智能指针就没有用了。C++11 摒弃了 std::auto_ptr,而使用 std::unique_ptr,这种指针不能按值传递,而只能按引用传递,因为其复制构造函数和复制赋值运算符都是私有的
【使用 std::unique_ptr】
std::unique_ptr 是 C++11 新增的,与 auto_ptr 稍有不同,因为它不允许复制和赋值,即不能将其按值传递给函数,也不能将其赋给其他指针
要使用 std::unique_ptr,必须包含头文件 #include <memory>
#include <iostream>
#include <memory>
using namespace std;
class Fish
{
public:
Fish(){cout << "Fish: Constructed!" << endl;}
~Fish(){cout << "Fish: Destructed!" << endl;}
void Swim() const {cout << "Fish swims in water" << endl;}
};
void MakeFishSwim(const unique_ptr<Fish>& inFish){
inFish->Swim();
}
int main()
{
unique_ptr<Fish> smartFish(new Fish);
smartFish->Swim();
MakeFishSwim(smartFish); // ok, as MakeFishSwim accepts reference
unique_ptr<Fish> copySmartFish;
// copySmartFish = smartFish; // error: operator = is private
}

从输出可知,虽然 smartFish 指向的对象是在 main() 中创建的,但它被自动销毁,无需调用 delete 运算符。这是 uniqu_ptr 的行为:当指针离开作用域时,将通过析构函数释放它拥有的对象。注意到第 22 行将 smartFish 作为参数传递给了 MakeFishSwim(),这样做不会导致复制,因为 MakeFishSwim() 的参数为引用。如果删除第14 行的引用符号 &,将出现编译错误,因为复制构造函数是私有的。同样,不能像第 25 行那样将一个 uniqu_ptr 对象赋给另外一个 unique_ptr 对象赋给另一个 unique_str 对象,因为复制赋值运算符是私有的
【boost 库中的四种智能指针】
boost 库中的智能指针有 4 种,auto_ptr、unique_ptr、shared_ptr 和 weak_ptr
如上所述,auto_ptr 是最流行的破坏性复制指针,被传递给函数或复制给另一个指针后,这种智能智能指针就没有用了。C++11 摒弃了 auto_ptr,而使用 unique_ptr,这种指针不能按值传递,而只能按引用传递,因为其复制构造函数和复制赋值运算符都是私有的
shared_ptr 即是一种引用计数智能指针,多个智能指针可以指向相同对象,该对象和其相关资源会在最后一个引用被销毁时释放
weak_ptr 是一种不控制对象生命周期的智能指针,它指向一个 shared_ptr 管理的对象。进行该对象的内存管理的是那个强引用的 shared_ptr,weak_ptr只是提供了对管理对象的一个访问手段。weak_ptr 设计的目的是为配合 shared_ptr 而引入的一种智能指针来协助 shared_ptr 工作,它只可以从一个 shared_ptr 或另一个 weak_ptr 对象构造,它的构造和析构不会引起引用记数的增加或减少。weak_ptr 是用来解决shared_ptr 相互引用时的死锁问题, 如果说两个shared_ptr 相互引用,那么这两个指针的引用计数永远不可能下降为0,资源永远不会释放。它是对对象的一种弱引用,不会增加对象的引用计数,和 shared_ptr 之间可以相互转化,shared_ptr 可以直接赋值给它,它可以通过调用 lock 函数来获得 shared_ptr
class A
{
public:
shared_ptr<B> pb_;
~A(){cout<<"A delete\n";}
};
class B
{
public:
shared_ptr<A> pa_;
~B(){cout<<"B delete\n";}
};
void fun()
{
shared_ptr<B> pb(new B());
shared_ptr<A> pa(new A());
pb->pa_ = pa;
pa->pb_ = pb;
cout<<pb.use_count()<<endl;
cout<<pa.use_count()<<endl;
}
int main()
{
fun();
return 0;
}
可以看到fun函数中pa ,pb之间互相引用,两个资源的引用计数为2,当要跳出函数时,智能指针pa,pb析构时两个资源引用计数会减一,但是两者引用计数还是为1,导致跳出函数时资源没有被释放(A、B的析构函数没有被调用),如果把其中一个改为 weak_ptr 就可以了,我们把类A里面的 shared_ptr pb_ 改为 weak_ptr pb_ ,这样的话,资源 B 的引用开始就只有1,当 pb 析构时,B 的计数变为 0,B 得到释放,B 释放的同时也会使 A 的计数减一,同时 pa 析构时使 A 的计数减一,那么 A 的计数为 0,A 得到释放
注意的是我们不能通过weak_ptr直接访问对象的方法,比如 B 对象中有一个方法 B_print(),我们不能这样访问,pa->pb_->B_print(),因为pb_是一个 weak_ptr,应该先把它转化为 shared_ptr,如:shared_ptr p = pa->pb_.lock(); p->B_print();















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









