







上一篇博客以爬取《你好,李焕英》豆瓣热门短评来作为爬虫入门小案例,这一篇博客主要以石家庄市为例,爬取58同城在售楼盘房源信息,主要包括以下字段:小区名称,所在区,地址以及均价等,总体来说,难度系数不大,算是入门级第二个小案例,废话不多说,让我们一起去看看把;
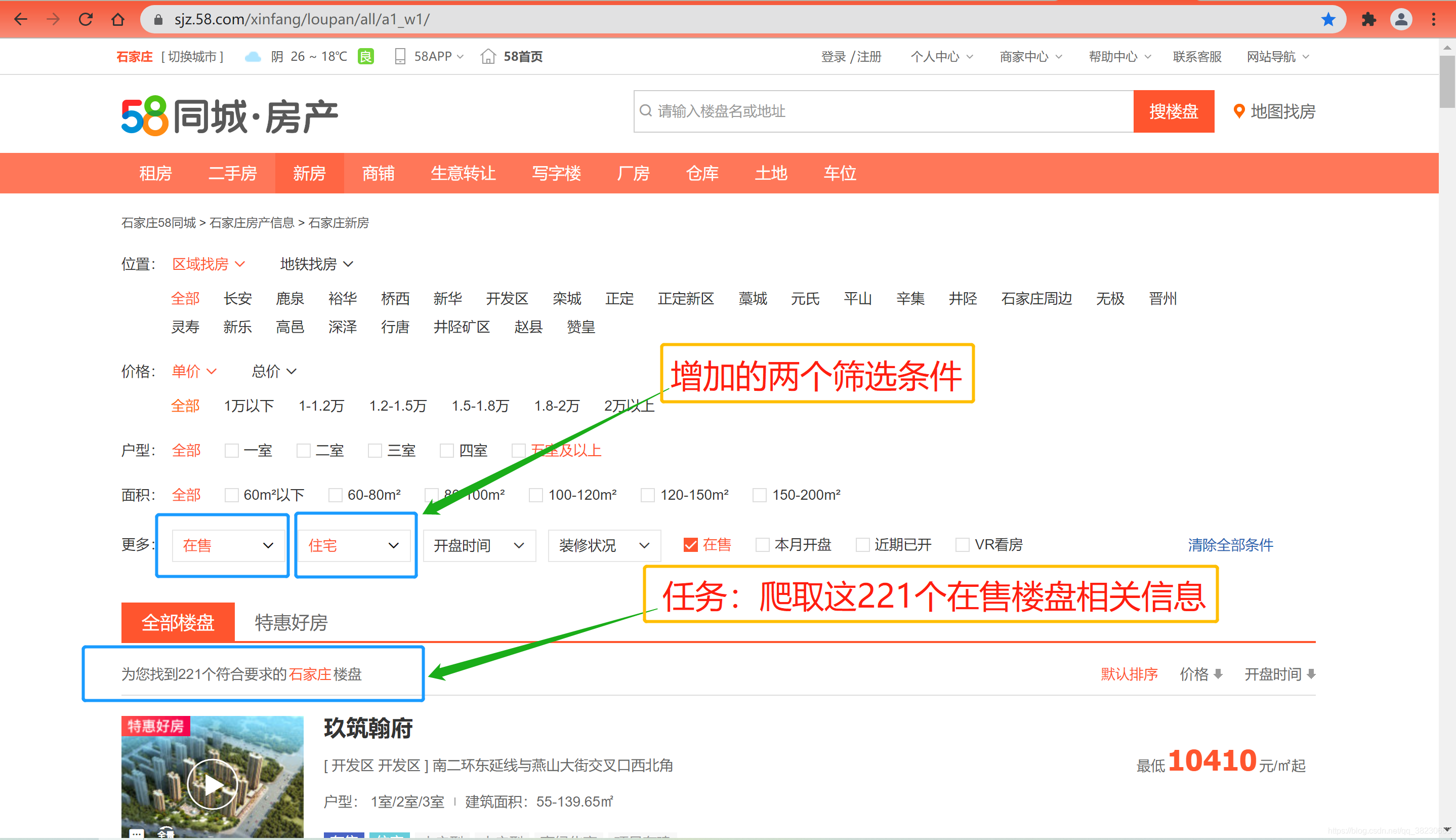
从58同城石家庄市新房首页可以看出,总共显示696个楼盘,但是有些楼盘并不是在售状态,售价还没公布,所以为了数据爬取完整,增加两个筛选条件(在售,住宅),如下图所示。从图中可以看到,筛选后满足条件的楼盘共有221个,每页有60个楼盘,一共需要爬取4页,我们的任务就是:爬取到这221个在售楼盘的相关字段信息;
1. 获取58同城石家庄市在售楼盘URL
为了方便查看起见,这次将前4页URL放在一起进行比较;
url1 = 'https://sjz.58.com/xinfang/loupan/all/a1_w1/' # 第一页
url2 = 'https://sjz.58.com/xinfang/loupan/all/a1_p2_w1/?PGTID=0d0091a8-000f-1266-1fca-62399388c79c&ClickID=1' # 第二页
url3 = 'https://sjz.58.com/xinfang/loupan/all/a1_p3_w1/?PGTID=0d0091a8-000f-1c31-0cc2-4fa1844adb62&ClickID=1' # 第三页
url4 = 'https://sjz.58.com/xinfang/loupan/all/a1_p4_w1/?PGTID=0d0091a8-000f-1aa1-0444-a8d210a73004&ClickID=1' # 第四页从4页的URL中,我们可以看到每个URL后都携带了两个参数:PGTID和ClickID,由于我没有专门学过网页开发,所以关于第一次参数PGTID也不是很清楚,第二次参数ClickID似乎与点击次数有关,当然这两个参数具体含义不知道也没关系,可以试试把他们删掉,然后却发现带不带后面两个参数并不影响最终的网页页面。其实,好多网站URL后面携带的参数,对于普通用户没有必要全都知道,我们只需要知道一些常用参数即可。
在删除后面PGTID和ClickID参数后,我们可以看到后3页唯一不同的就是p2,p3,p4,这肯定就代表着页数;所以我们得出第一页肯定就是p1,只不过系统自动隐藏了。故本案例的URL即:
# 首页
url = 'https://sjz.58.com/xinfang/loupan/all/a1_p1_w1/'
# 爬取石家庄市所有在售楼盘221个
for i in range(4):
url = 'https://sjz.58.com/xinfang/loupan/all/a1_p{}_w1/'.format(i)
2. 分析网页html代码,查看各字段信息所在的网页位置
在网页空白处右键,选择【检查】,即可查看网页详细的源代码;
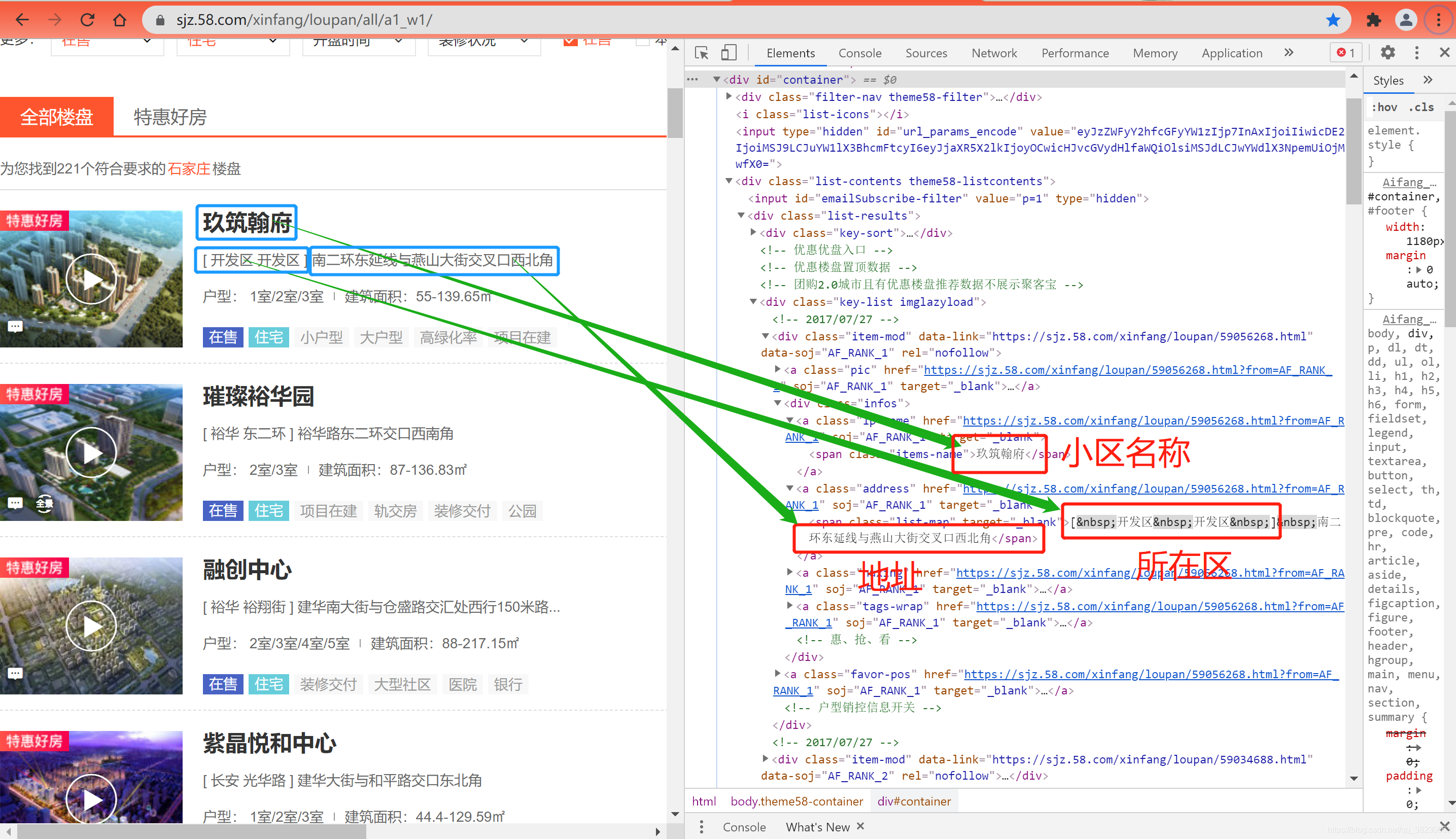
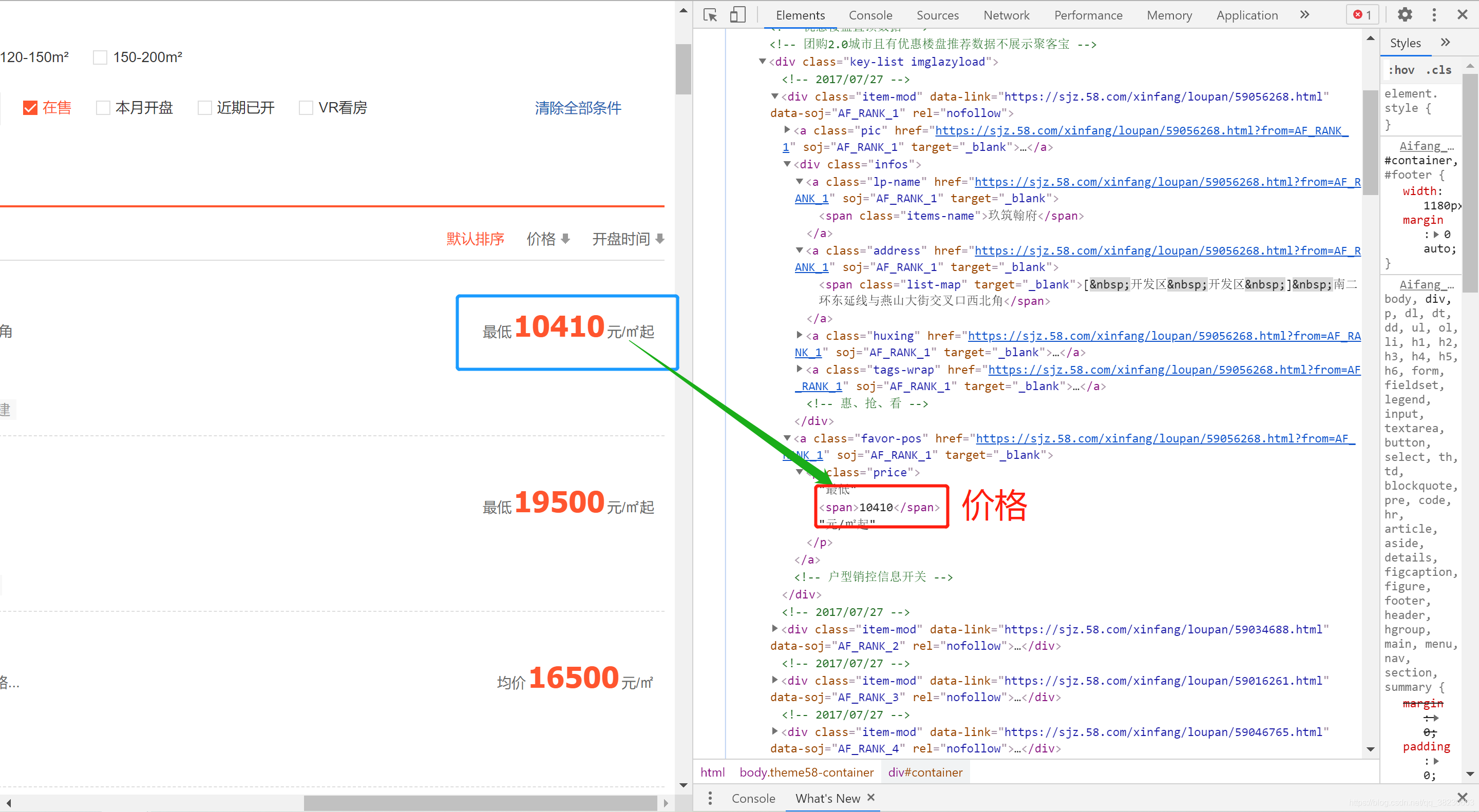
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











