







 本文通过实例展示了如何使用Python和Xpath技术从豆瓣电影《你好,李焕英》的短评页面抓取评论者、评分、日期、点赞和内容,适合初学者入门。受限于豆瓣反爬策略,仅抓取了前500条热门评论。
本文通过实例展示了如何使用Python和Xpath技术从豆瓣电影《你好,李焕英》的短评页面抓取评论者、评分、日期、点赞和内容,适合初学者入门。受限于豆瓣反爬策略,仅抓取了前500条热门评论。
2021年春节档热播电影《你好,李焕英》,拿下累计票房54.12亿,一路杀进中国票房榜前五,堪称票房黑马。今天就以《你好,李焕英》这部电影为例,利用Python中的Xpath爬取其豆瓣短评,爬取的字段主要有:评论者、评分、评论日期、点赞数以及评论内容。该案例难度系数不大,刚好作为入门案例,废话不多说,让我们一起去看看吧!

注:虽然在《你好,李焕英》豆瓣短评首页中显示共有41万多条短评,但是当浏览时,却发现只能查看前25页的短评,也就是说用户只能看到500条短评评论。发现这个问题后,查阅了一些相关资料,原来是豆瓣电影早在2017年起就不再展示全部短评。官方给出的调整原因是:“为了在不影响用户体验的前提下反爬虫、反水军”(无奈.ipg)。鉴于此,本案例只爬取前500条热门短评。
1. 获取《你好,李焕英》豆瓣短评URL
不论爬取什么网站,第一步都是先获取我们所要爬取的网站地址,也就是url,获取的途径就是打开浏览器,找到《你好,李焕英》短评所在网页界面,然后地址栏中即为我们所需要的url。(注:一般情况下,网站第一页的url不会显示页码,所以这里就需要查看第二页的url)
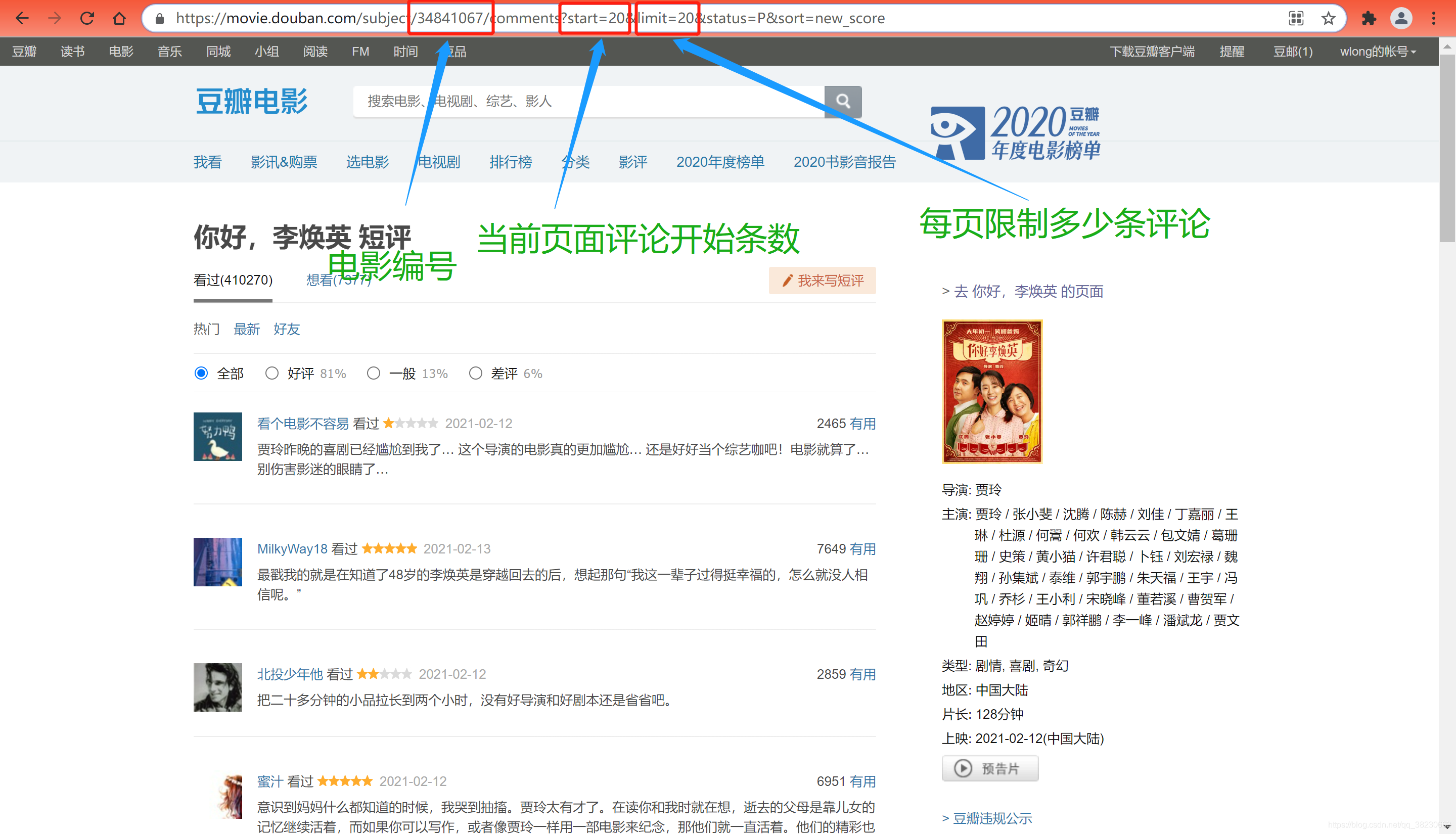
所以,该URL即为:
# 第一页的url
url = "https://movie.douban.com/subject/34841067/comments?start=0&limit=20&status=P&sort=new_score"
# 多页时,只需加入循环
for i in range(25): #豆瓣限制最多爬取25页,400条短评
url = "https://movie.douban.com/subject/34841067/comments?start={}&limit=20&status=P&sort=new_score".format(i*20) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3316
3316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











