









目录
旧的索引迁移到新的索引(使用场景:数据迁移、索引优化、数据转换)
场景2:对象内嵌套了数组,数组内又嵌套了对象,如何添加?如何查询?
查询所有索引
GET _cat/indices查询索引的mapping信息
# 把index_name改为你要查看的索引名
GET /index_name/_mapping添加索引的同时添加mapping
# index_name为你要增加的索引名
# properties内的是你的字段 在这里创建了类型为integer的name字段
PUT /index_name
{
"mappings" : {
"properties" : {
"name" : {
"type" : "integer"
}
}
}
}在原有基础上新增字段
# 为index_name索引新增类型为text的title字段
# analyzer指定该字段的分词器,ik_max_word是IK分词器中细粒度分词的模式,与之相反的是ik_smart模式
# search_analyzer指定搜索时的分词器
PUT /index_name/_mapping
{
"properties" : {
"title" : {
"type" : "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
旧的索引迁移到新的索引(使用场景:数据迁移、索引优化、数据转换)
es没法在原有的结构上修改,比如你原来的结构使用的是ik分词器中的ik_smart模式,后面你发现ik_max_word模式才是你需要的效果,你想在原来的结构上把ik_smart修改为ik_max_word是不行的,只能是新创建一个索引,把字段的分词器改成ik_max_word,然后再进行数据迁移即可。
# old_index_name是旧的索引名,new_index_name是新的索引名
# 从old_index_name数据迁移到new_index_name
POST _reindex
{
"source":{
"index": "old_index_name"
},
"dest":{
"index": "new_index_name"
}
}数据迁移后旧索引下的数据还是存在的,不是说把所有数据迁移到新的索引后旧索引的数据就没了
查询索引下的文档总数
当我们进行数据迁移,想要查看是否迁移完成的话可以使用这个查询文档数量是否对应上即可
# 把index_name修改为你要查询的索引名
GET /_cat/count/index_name?v场景1:某一个字段的值是数组,如何存放?如何查询?
- 新建一个测试索引名,添加可以存放数组的字段
# 跟创建普通的字段差不多,唯独多了fields,fields内指定了一个类型为keyword的name字段
# fields下的name对应的就是数组当中的一个个值
PUT /test_index_name
{
"mappings" : {
"properties" : {
"my_array" : {
"type" : "text",
"analyzer" : "ik_max_word",
"search_analyzer": "ik_max_word",
"fields" : {
"name" : {
"type" : "keyword"
}
}
}
}
}
}响应:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test_index_name"
}
- 添加测试数据
假如我们有三个数组,分别是:
["张三", "李四"]
["橙留香", "菠萝吹雪", "陆小果"]
["疯清扬", "天山果姥", "无极"]
单个添加:
# 为test_index_name添加一条id为1的数据
PUT /test_index_name/_doc/1
{
"my_array": ["张三", "李四"]
}
批量添加:
POST /test_index_name/_bulk
{"create":{"_id":"2"}}
{"my_array":["橙留香", "菠萝吹雪", "陆小果"]}
{"create":{"_id":"3"}}
{"my_array":["疯清扬", "天山果姥", "无极"]}通过以上步骤已经添加了三条数据,接下来让我们查询看下效果
- 查询方式1
# 查询数组内name有张三的数据
GET /test_index_name/_search
{
"query": {
"bool": {
"must": [
{
"term": {"my_array.name": "张三"}
}
]
}
}
}结果:
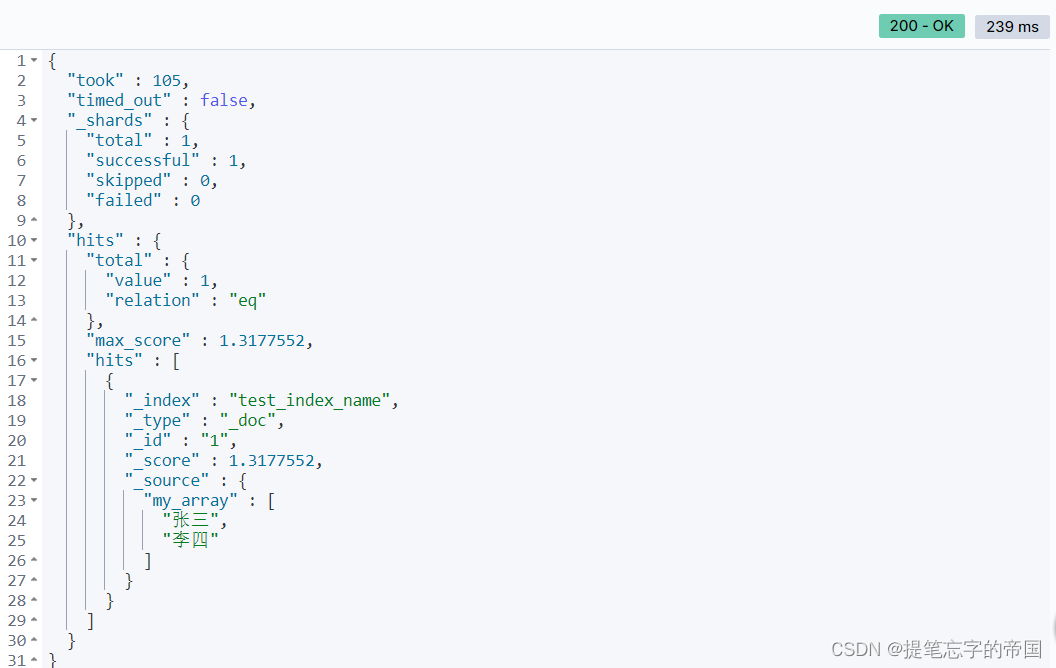
可以看到查询出了包含张三的数据了
- 查询方式2
GET /test_index_name/_search
{
"query": {
"bool": {
"must": [
{
"match": {"my_array": "疯清扬"}
}
]
}
}
}结果:
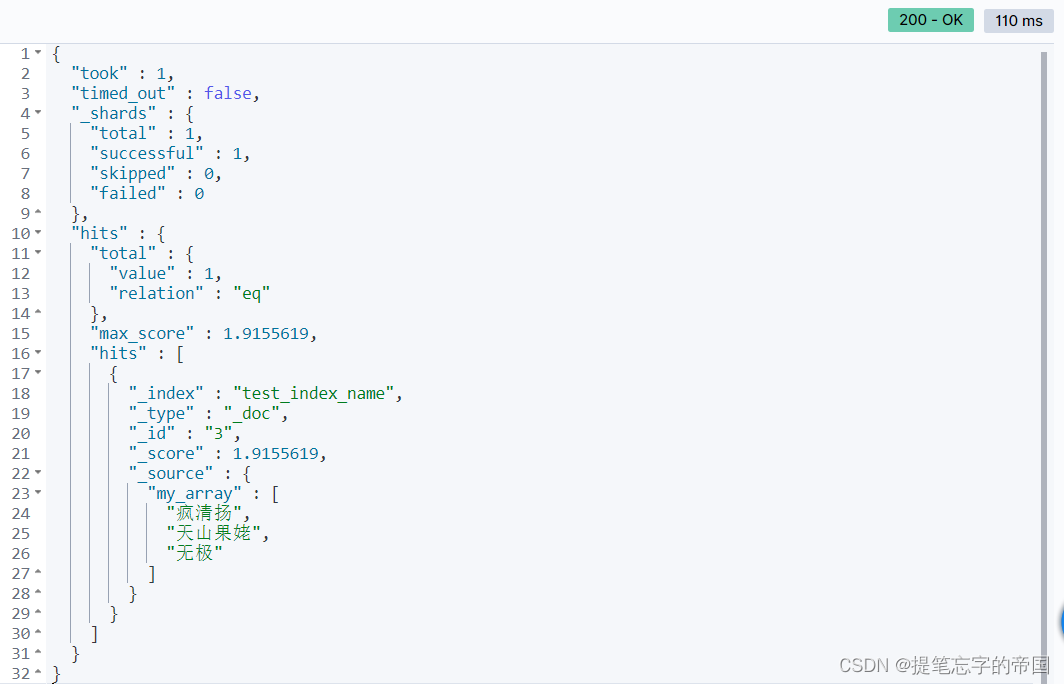
方式1是根据数组内的name值精确匹配。方式2是my_array字段的模糊匹配,因为我们一开始创建的my_array是text类型的,text类型会进行分词,因此可以用match进行模糊匹配,而my_array内的name是keyword类型的,keyword类型不会进行分词,它是一个整体,那么就可以用term进行精确匹配了,当然你也可以把keyword类型改成text类型,这样也可以进行模糊匹配了,可以自行探索下。使用term精确匹配text类型的字段时,可能查询没有结果,原因是因为text的所有分词中可能没有对应上的内容。
场景2:对象内嵌套了数组,数组内又嵌套了对象,如何添加?如何查询?
比如我们有两条数据是这样的:
第一条:
{
"title": "果宝特攻",
"data": {
"role": "主角",
"names": [
{
"name": "疯清扬"
},
{
"name": "天山果姥"
}
]
}
}
第二条:
{
"title": "倚天屠龙记",
"data": {
"role": "主角",
"names": [
{
"name": "张无忌"
},
{
"name": "张三丰"
}
]
}
}
看起来有点复杂哈,待会有你头大的,哈哈哈哈~
- 建索引添加字段
PUT /test_index_name_1
{
"mappings" : {
"properties" : {
"title" : {
"type" : "keyword"
},
"data" : {
"type" : "nested",
"properties" : {
"role" : {
"type" : "keyword"
},
"names" : {
"type" : "nested",
"properties" : {
"name" : {
"type" : "keyword"
}
}
}
}
}
}
}
}让我们把索引结构抽出来和数据结构对比看下:
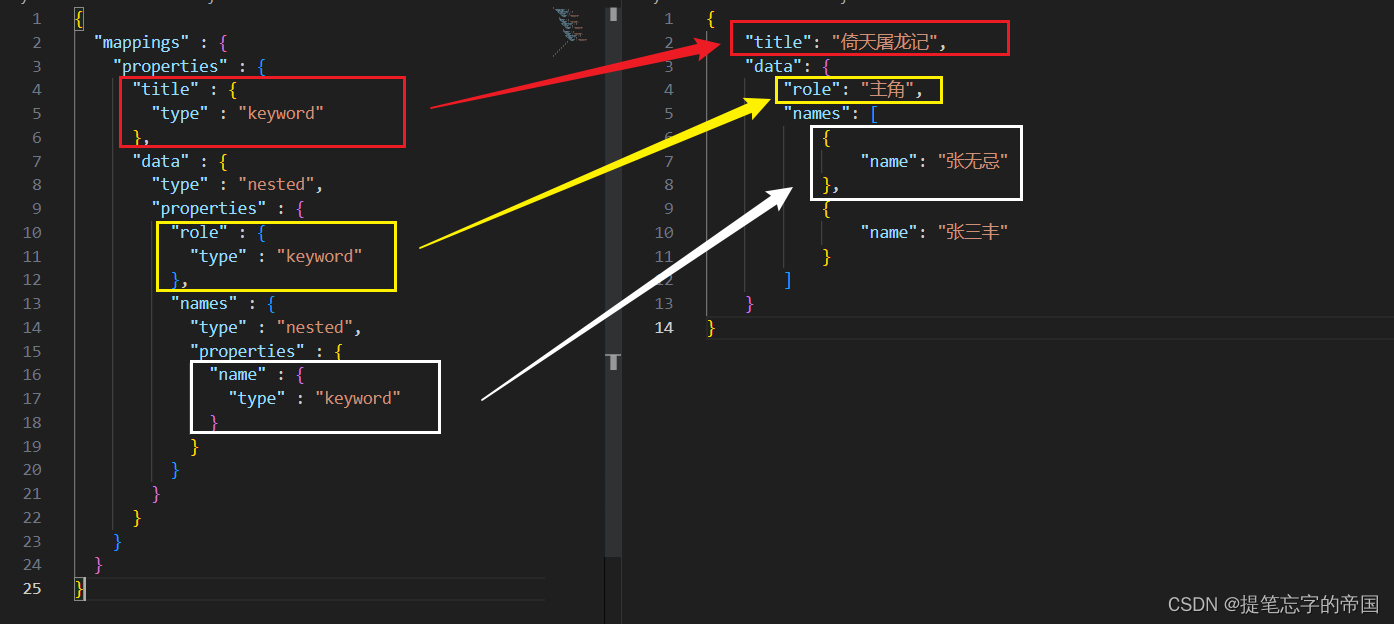
可以看到除了使用到nested类型外,其他结构和普通的结构没什么区别,nested类型可以使用在对象或数组上,具体的介绍如下:
Nested数据类型的作用
-
独立查询:Nested数据类型是object数据类型的特殊版本,允许对象数组被索引,这样它们可以独立地被查询。
-
内部结构:在内部,nested对象将数组中的每个对象作为一个单独的隐藏文档来索引,这意味着可以使用nested查询独立查询每个nested对象。
-
Lucene文档:每个nested对象都被索引为一个独立的Lucene文档。例如,如果我们索引了一个包含100个user对象的单一文档,那么会创建101个Lucene文档。比如我们有以下数据:
{
"title": "Example Document",
"users": [
{ "name": "Alice", "age": 30 },
{ "name": "Bob", "age": 25 }
]
}这个示例的有两个user对象,对应两个 Lucene文档,而包含title字段和users字段是这两个 Lucene文档的父文档,因此这个示例会创建三个 Lucene文档(一个父文档、两个user对象)
-
使用场景:只有在需要独立查询对象数组的特殊情况下,才应该使用nested类型。对于大量、随机的键值对,可以考虑使用flattened数据类型来代替,因为它能将整个对象映射为一个字段,并允许对其内容进行简单搜索。这是因为nested文档和查询通常都比较昂贵。
-
性能警告:由于与nested映射相关的开销,Elasticsearch设置了一些设置来防止性能问题:
- index.mapping.nested_fields.limit:一个索引中可以有的不同nested映射的最大数量。默认值为50。
- index.mapping.nested_objects.limit:一个文档在所有nested类型中可以包含的嵌套JSON对象的最大数量。这个限制有助于防止文档包含太多的nested对象时出现内存溢出错误。默认值是10000。
官方文档介绍:Nested field type | Elasticsearch Guide [7.17] | Elastic
通过上面的介绍你应该理解咱们创建的索引结构了,那么接下来让我们添加数据查询试试。
- 添加数据
PUT /test_index_name_1/_doc/1
{
"title": "果宝特攻",
"data": {
"role": "主角",
"names": [
{
"name": "疯清扬"
},
{
"name": "天山果姥"
}
]
}
}
PUT /test_index_name_1/_doc/2
{
"title": "倚天屠龙记",
"data": {
"role": "主角",
"names": [
{
"name": "张无忌"
},
{
"name": "张三丰"
}
]
}
}
- 查询
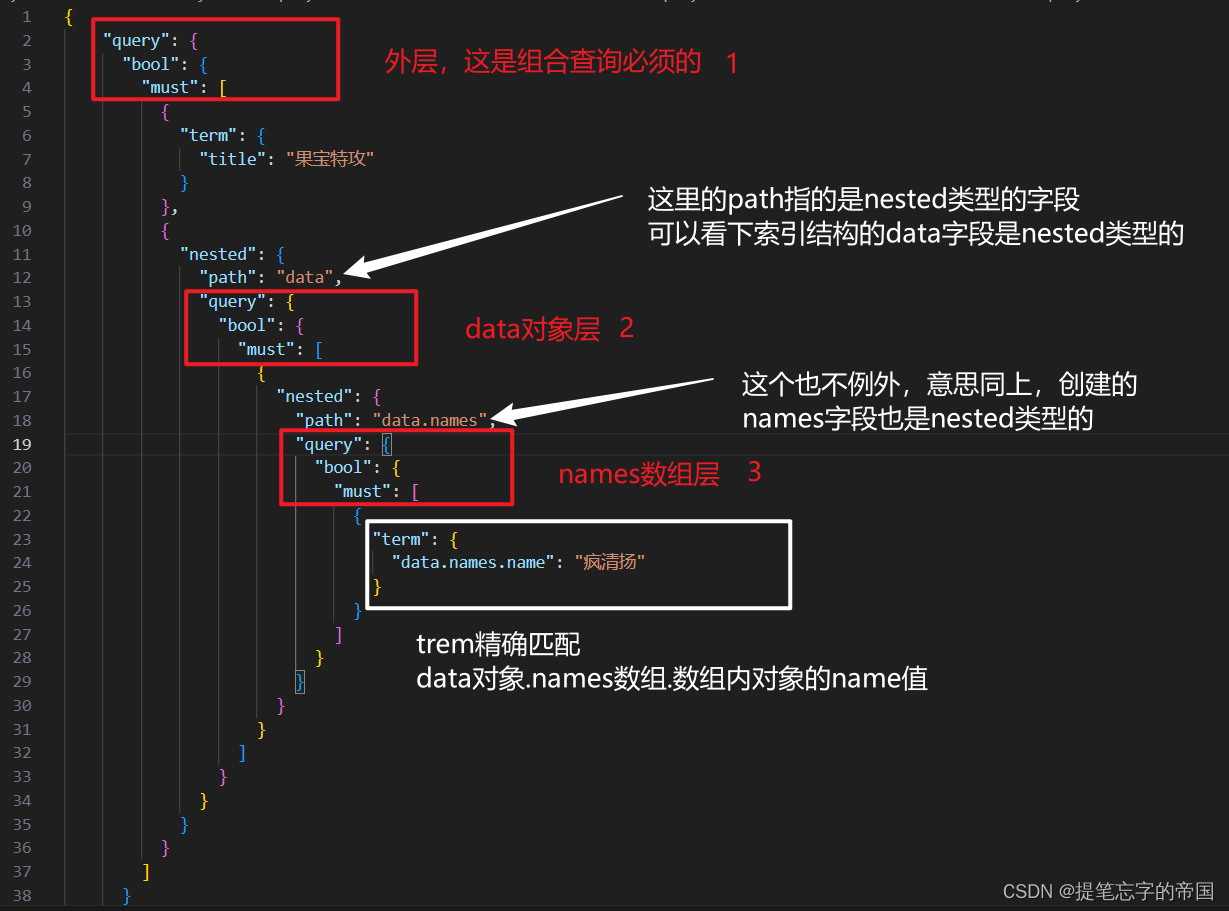
GET /test_index_name_1/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"title": "果宝特攻"
}
},
{
"nested": {
"path": "data",
"query": {
"bool": {
"must": [
{
"nested": {
"path": "data.names",
"query": {
"bool": {
"must": [
{
"term": {
"data.names.name": "疯清扬"
}
}
]
}
}
}
}
]
}
}
}
}
]
}
}
}结果:
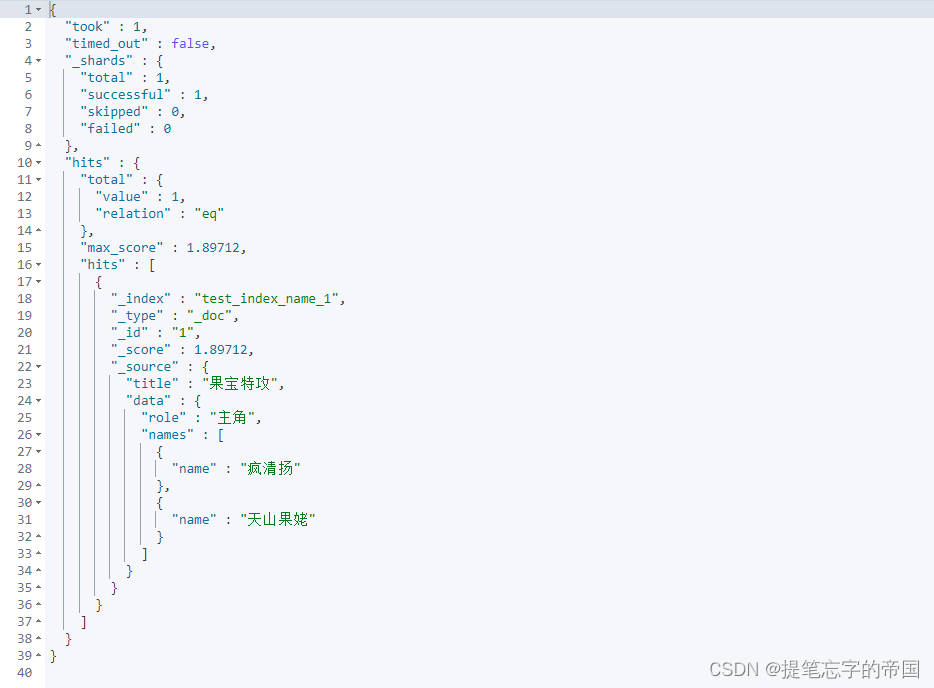
解释查询语句:
基本上就是一层嵌套一层的去查询,看下图的解释应该就明白了:
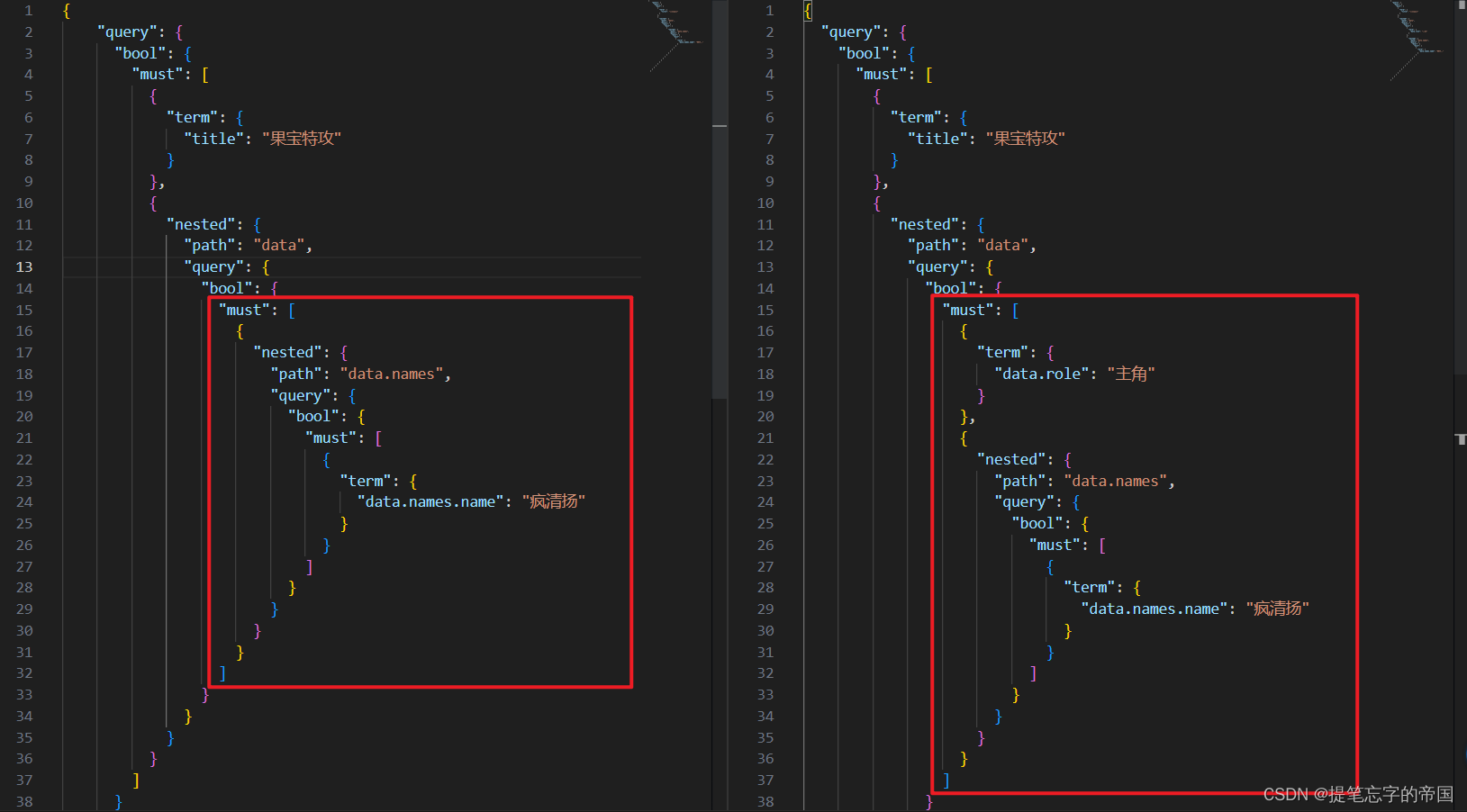
如果我想添加role字段的查询条件呢?其实就是在data对象层添加一个条件即可,对比:
场景3:向量的使用?
在es没有添加向量的搜索方式前,搜索靠的是关键字,但是关键字的搜索结果在有些时候不是那么尽人意,因此有了向量的方式后在一定程度上可以做到语义上的搜索,不过我们需要使用Embedding将文本转为向量,效果好不好就看你的Embedding模型好不好了。
流程:
我们需要借助Embedding模型将文本转为向量,然后入库。在查询的时候将查询的问题借助Embedding转为向量,然后拿着向量去库里查。流程大概是这么个流程。
- 建索引添加字段
PUT /test_index_name_2
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"my_v": {
"type": "dense_vector",
"dims": 1024
}
}
}
}
新建了两个字段,一个是content字段,指定了ik分词器。一个是my_v字段,类型是dense_vector,也就是向量类型,dims指的是向量的维度,因为接下来用的Embedding模型维度是1024的,因此这里的dims填1024即可,如果你用其他的Embedding模型,那么就需要看你的Embedding模型维度是多少了。一般Embedding模型的文档会说明维度是多少的。
- 下载模型
这一步因为用到了Embedding模型,因此我们需要在代码中添加,这里就用python演示了,接下来的演示我将使用这个Embedding模型:
git lfs install
git clone https://huggingface.co/BAAI/bge-large-zh- 部署模型
安装依赖
pip install -U FlagEmbedding示例代码:
# -*- coding: utf-8 -*-
from FlagEmbedding import FlagModel
# 模型路径
MODEL_PATH = 'D:/python_project/pythonProject/bge-large-zh'
if __name__ == '__main__':
model = FlagModel(MODEL_PATH)
my_v = model.encode("这是一个测试转向量的文本")
print(my_v)
print(f'向量维度:{len(my_v)}')
输出结果:

- es入库
我的elasticsearch数据库是7.12.1的
安装elasticsearch依赖:
pip install elasticsearch==7.17.0示例代码:
# -*- coding: utf-8 -*-
from FlagEmbedding import FlagModel
from elasticsearch import Elasticsearch
# 模型路径
MODEL_PATH = 'D:/python_project/pythonProject/bge-large-zh'
if __name__ == '__main__':
content = '橙留香来自一位三流剑客之家,与果冻武术学院里的菠萝吹雪、陆小果组成“果冻三剑客”,最后三人终于打败四大恶贼,成为民族大英雄。'
# 加载模型
model = FlagModel(MODEL_PATH)
# 初始化es连接 如果没有账户密码不填即可
es = Elasticsearch([{'host': '127.0.0.1', 'port': 9200}], http_auth=('elastic', '123456789'))
# 文本转向量
my_v = model.encode(content)
print(my_v)
print(f'向量维度:{len(my_v)}')
# 入库
data = {
"my_v": my_v,
"content": content
}
response = es.index(index="test_index_name_2", document=data)
print(response)
- 查询
示例代码:
# -*- coding: utf-8 -*-
import json
from FlagEmbedding import FlagModel
from elasticsearch import Elasticsearch
# 模型路径
MODEL_PATH = 'D:/python_project/pythonProject/bge-large-zh'
if __name__ == '__main__':
question = '果冻三剑客是谁?'
# 加载模型
model = FlagModel(MODEL_PATH)
# 初始化es连接 如果没有账户密码不填即可
es = Elasticsearch([{'host': '127.0.0.1', 'port': 9200}], http_auth=('elastic', '123456789'))
# 文本转向量
my_v = model.encode(question)
# 查询条件
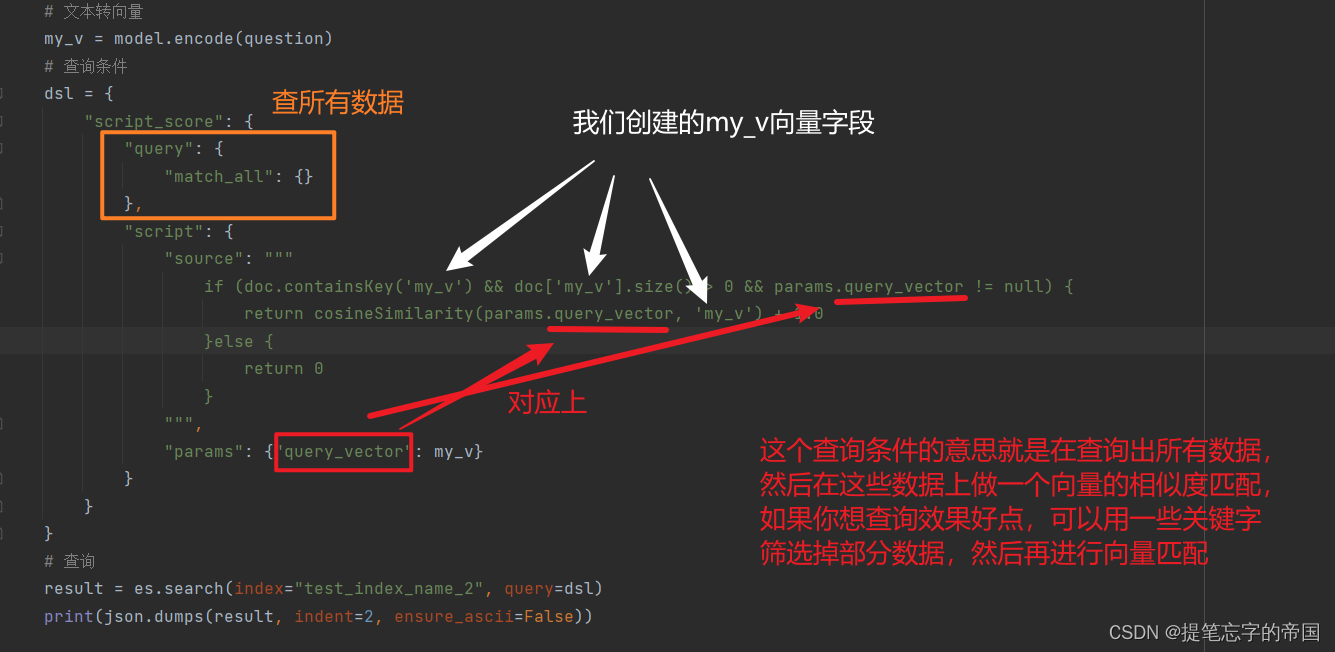
dsl = {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": """
if (doc.containsKey('my_v') && doc['my_v'].size() > 0 && params.query_vector != null) {
return cosineSimilarity(params.query_vector, 'my_v') + 1.0
}else {
return 0
}
""",
"params": {"query_vector": my_v}
}
}
}
# 查询
result = es.search(index="test_index_name_2", query=dsl)
print(json.dumps(result, indent=2, ensure_ascii=False))结果:
你可能会看到很多-0.007382424082607031这种数据,这个就是文本的向量
代码解释:
👍点赞,你的认可是我创作的动力 !
🌟收藏,你的青睐是我努力的方向!
✏️评论,你的意见是我进步的财富!
















 370
370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











