







前言
原文链接:Joint Unsupervised Learning of Deep Representations and Image Clusters
正如文章题目所说,这篇文章提出了一个联合深度表征和图像聚类的无监督学习方法:将聚类算法应用于CNN的深层表示。算法的思想是通过CNN得出的图像良好表征会改善聚类的结果,而聚类结果又为CNN的特征表示提供了监督信号,通过交替优化卷积和聚类过程,使得CNN学习到图像的高级特征的同时聚类效果也达到最好,以此得出的CNN的深层特征来应用于其他任务上也会得到良好的效果。具体而言,作者在文章中采用的聚类方法是层次聚类(agglomerative clustering)的合并算法。
层次聚类(Agglomerative clustering)
层次聚类的合并过程是在聚类的初始过程将每一个数据点都看成是一个类,通过距离度量函数计算两个类别的相似性,然后将最为相似的两类数据点合成为一个类,反复迭代上述过程。

为什么要采用层次聚类呢?1)CNN的初始权重是随机初始化的因此得到的representation是不可靠的,数据点间的相似性不可靠。层次聚类在初始时将每一个数据点都看成是一个类,初始状态时,每一个 data,unreliable representation,cluster 一 一对应,分类结果正确,因此在reprenetation不可靠的情况下也是正确的(过拟合状态)。2)随着训练的进行,representation变得更加优秀,相似性得以更好的度量 ,类与类之间得以合并。3)层次聚类是一个迭代的过程和CNN的迭代过程相呼应 。
传统的层次聚类基于欧氏距离来进行相似性度量,论文中样本的相似性度量是基于如下方法:
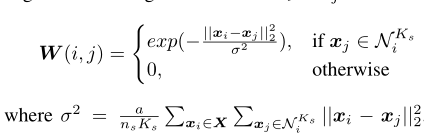
文中定义是存储CNN输出特征
和
之间相似度的相似度矩阵,从公式可以看出,特征
和
的差别越大,相似性越小。分母
是分子求和的形式,相当于进行了归一化。
是样本个数,a和
是预先定义的超参数。
是样本点
最为相似的
个样本点。
文章创新点
上述提到了在representation空间中点与点之间的相似性描述方法,随着迭代过程的进行,簇与簇之间的相似性理应也有一个好的描述。关于簇与簇之间的相似性,作者借鉴了这篇文章中的方法,总的来说就是用一个来表示簇与簇之间的相似性,
越相似,值越大。传统 的层次聚类算法只是单纯的用点(簇)与点(簇)之间的相似性来进行簇的合并,作者认为如果要将两个簇进行合并,要考虑当前簇的局部结构。即要合并的两个簇之间不仅要有较高的相似性,而且还要保证和其他簇之间有着较大的差异性。在这里,我们用
代表
的
个最邻近簇构成的集合,并且按照相似性由大到小进行降序排列。较高的相似性表示我们希望
越大越好,较大的差异性表示我们希望
越小越好。因此作者构造了如下的损失函数:

公式中的第一项表示和他最近邻的簇的相似度,与传统的层次聚类算法一致,自然是希望越大越好,也就是说这两个簇需要尽可能地近才能够合并。第二项表示
和他最邻近簇的相似度 和
和其他邻近簇的相似度 之间的差异的均值,这个差异自然是越大越好,也就是说最邻近簇尽量地靠近当前
,其他簇尽量地远离当前
。因为是损失函数嘛,添加负号表示整个式子越小越好。

左图表示传统的层次聚类选择最为相似的两个点的聚类结果为b和它的最邻近点进行合并。右图表示用作者提出的方案,找到最为相似的两个点的同时也要保证其他点尽量远离最为相似的这两点,最终聚类结果是选择e和它的最邻近点进行合并。
优化方案
模型的目标是要找到最好的CNN的参数以及图像标签序列Y,作者采用交替优化的方式:1)先固定CNN的模型参数
,将上一轮迭代得到的标签序列
通过合并簇的方式来更新
得到
。2)利用聚类得到的类别标签序列Y作为监督信号来实现CNN参数
的更新。
第一步没什么可说的,利用层次聚类的合并思想,找到符合条件(考虑相似度和差异性)的两个簇进行合并。主要说说聚类得到的结果是如何作为监督信号的?
容易想到的方法是利用序列Y作为标签利用传统的交叉熵误差来进行分类更新。这里作者利用簇间的相似性和差异性来设计损失函数:
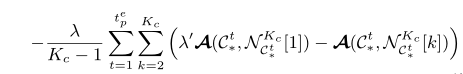
其中。括号内的含义和之前损失函数里的第二项相似,描述的是当前点与最邻近点的相似度 和 当前点和邻域内其他点的相似度之间的差异,这个值自然是越大越好。因为每进行一步CNN的参数更新执行了多步的合并,因此第一个求和符号表示累积了这个多步合并里面的所有损失。由于该损失是基于簇定义的,因此需要整个数据集传入CNN参与优化,难以应用传统的批量传入的方法。直觉上,不同簇之间的相似性能够通过数据点之间的相似性来表达。因此作者设计了一个基于单个样本的损失函数来近似基于簇的损失函数。
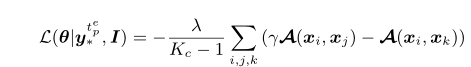
和
是同一个簇的数据点,
是不同簇的数据点,这里的簇是通过类别标签序列Y得到的。为了进一步简化,可以将
定义在当前簇的前
个最邻近簇中,这样就可以通过SGD的优化方式求出CNN的参数
。
迭代过程

这是我对这篇文章的理解与笔记,如果有理解错误的地方,欢迎指正!!















 1141
1141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









