







目录
前言
本文主要是本人的学习心得,包括以下两个方面:
一、对论文《无监督的深度嵌入式聚类》(DEC)相关知识的学习;
二、对DEC代码的学习。
一、对论文《无监督的深度嵌入式聚类》(DEC)相关知识的学习
(一)论文简介:
聚类对于许多数据驱动的应用至关重要,并且已在距离函数和分组算法方面进行了广泛的研究。在聚类表示学习方面相对的研究较少。在本论文中,我们提出了深度嵌入式聚类(DEC),一种使用深度神经网络同时学习特征表示和聚类分配的方法。DEC学习了从数据空间到低维特征空间的映射,迭代地优化了聚类目标。我们对图像和文本语料库的实验评估表明,与现有技术相比,该方法有显着改进。
(二)相关知识点:
1. KL散度
KL(Kullback-Leibler)散度,也称为相对熵,是度量两个概率分布之间差异的一种指标。在信息理论中,KL散度用来衡量两个概率分布之间的信息损失,或者说是两个概率分布之间的距离。
假设有两个概率分布P和Q,KL散度定义为: P是真实概率分布,Q是推测的概率分布。
其中,P(i)和Q(i)分别表示P和Q在第i个事件上的概率。KL散度的值越大,表示两个概率分布之间的差异越大;值为0表示两个概率分布完全相同。
KL散度常用于概率模型之间的比较和评估,例如在机器学习中用于衡量两个概率分布的相似性,或者用于评估生成模型的效果等。
2.软分配
软分配(soft assignment)是一种数据聚类算法中常用的方法,它与硬分配(hard assignment)不同,可以将一个数据点分配到多个簇中,而不是只分配到一个簇中。
在软分配算法中,数据点与簇之间的关系不是二元的,而是通过一组权重来表示的。具体来说,对于一个数据点和多个簇,软分配算法会计算每个簇与该数据点的相似度,并将相似度转化为权重,表示该数据点被分配到该簇的概率。因此,一个数据点可能被分配到多个簇,其分配权重之和为1。
例如:

3.K-means算法
K-Means算法的目标是最小化数据点与其所属簇的聚类中心点之间的距离之和(通常使用欧氏距离)。这个目标函数被称为簇内平方和(SSE,Sum of Squared Errors)。K-Means算法通过迭代更新聚类中心点和重新分配数据点来逐步优化SSE,以达到更好的聚类效果。
需要注意的是,K-Means算法对初始聚类中心点的选择敏感,因此不同的初始点可能会得到不同的聚类结果。为了克服这个问题,通常会进行多次运行,并选择具有最小SSE的结果作为最终聚类结果。
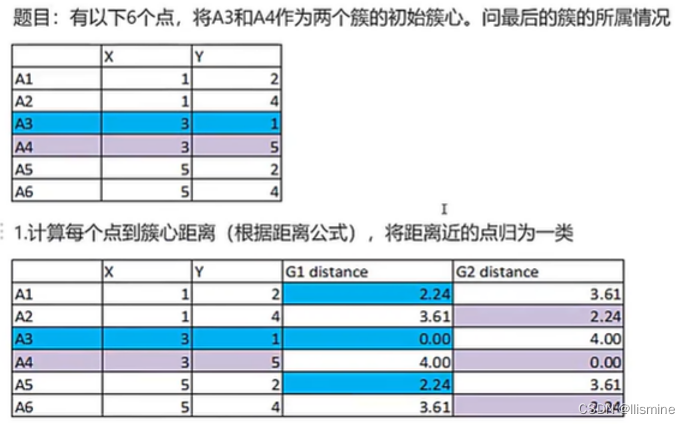
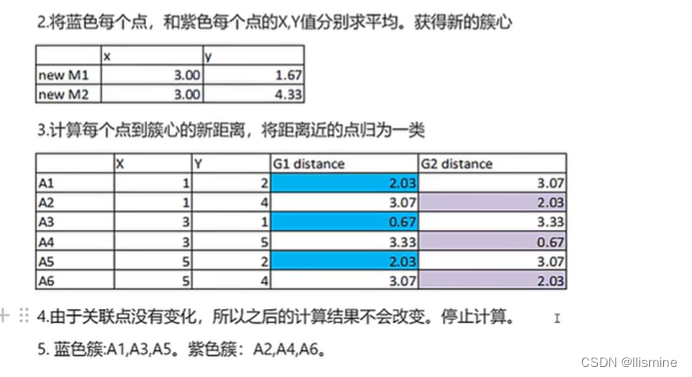
步骤+例子:
1、首先定义有多少个类/簇
2、将每个簇的簇心随机选在一个点(x,y)上
3、将每个数据点(均有(x,y))关联到距离最近的簇心上,即计算每个数据点到各个簇心的距离,到哪个簇心距离小,则属于哪个簇。计算每个簇有多少个数据点。
4、将各个簇中的数据点 坐标取平均值,选为新的簇心
5、再次计算每个数据点到新簇心的距离,根据距离小为依据,重新判断每个数据点所属簇,再次统计簇中的个数,直到每个簇拥有的点的个数不变。
4.AE(自编码器)
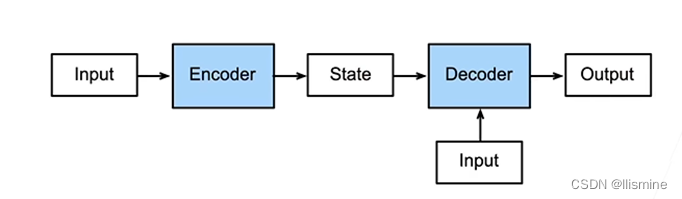
编码器-解码器(encoder-decoder)结构通常被用来实现自编码器(Autoencoder),也就是常说的 AE。其中,编码器将输入数据映射到低维空间中的编码表示,而解码器通过从编码中重构后的原始数据来产生输出。这个过程可以通过训练自编码器来学习数据的压缩表示和重建能力,从而实现特征提取、数据降维、数据去噪等任务。
整个过程如图所示:
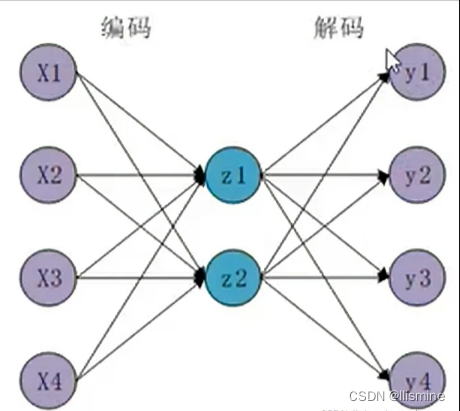
最简单的自动编码器如图所示:
5.反向传播算法
AE(Autoencoder)自编码器和反向传播算法的关系:
Autoencoder是一种无监督学习算法,用于学习输入数据的低维表示。它由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器将输入数据映射到低维的编码表示,而解码器则将编码表示映射回原始输入空间,以重构输入数据。
在训练过程中,Autoencoder的目标是最小化重构误差,即使解码器能够尽可能地还原输入数据。为了实现这一目标,反向传播算法被广泛应用于Autoencoder的训练中。
反向传播算法是一种基于梯度的优化算法,用于调整神经网络中的权重和偏置,使其能够最小化损失函数。在Autoencoder的训练过程中,反向传播算法通过计算重构误差的梯度来更新编码器和解码器的参数。具体地,首先计算重构误差(通常使用均方误差)和编码器输出之间的差异,然后使用反向传播算法计算梯度并将其传播回网络,从而更新网络的权重和偏置,以最小化重构误差。
通过反向传播算法的迭代优化,Autoencoder能够学习到一组有效的编码表示,这些表示能够保留输入数据的关键特征并减少冗余信息。这种学习过程是通过最小化重构误差来实现的,而反向传播算法是计算并应用梯度的关键步骤,使得网络能够逐步调整参数以提高重构的准确性。因此,反向传播算法在训练Autoencoder中起着重要的作用。
具体详细讲解可点此处:反向传播算法过程
二、对DEC代码的学习
首先先了解DNN和AE的区别:
DNN 和 AE 算法是相关但不完全相同的概念。
AE(Autoencoder)是一种无监督学习算法,它由编码器和解码器两部分组成,可以将高维输入数据压缩为低维编码表示,然后再通过解码器重构出与原始输入相似的输出结果。AE 可以用于特征提取、数据压缩、去噪等任务,在某些情况下也可作为生成模型使用。
DNN(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









