







文章目录
1.建立测试库并切换到测试库
[root@master ~]# $HIVE_HOME/bin/hive
Logging initialized using configuration in jar:file:/usr/local/src/apache-hive-1.2.2-bin/lib/hive-common-1.2.2.jar!/hive-log4j.properties
hive> create database dzw;
OK
Time taken: 1.6 seconds
hive> use dzw;
OK
Time taken: 0.052 seconds
2.建立orders和trains表
2.1表字段分析
查看表内容
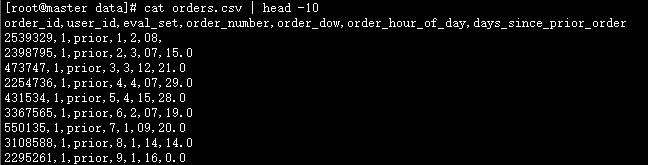
hive> create table orders(
> order_id string,
> user_id string,
> eval_set string,
> order_number string,
> order_dow string,
> order_hour_of_day string,
> days_since_prior_order string
> )
> row format delimited fields terminated by ','
> lines terminated by '\n'
--跳过文件行第1行
> tblproperties("skip.header.line.count"="1");
OK
Time taken: 0.112 seconds
插入数据
hive> load data local inpath '/usr/local/src/apache-hive-1.2.2-bin/data/orders.csv'
> into table orders;
Loading data to table dzw.orders
Table dzw.orders stats: [numFiles=1, totalSize=108968645]
OK
Time taken: 3.548 seconds
查询数据
hive> select * from orders limit 10;
OK
2539329 1 prior 1 2 08
2398795 1 prior 2 3 07 15.0
473747 1 prior 3 3 12 21.0
2254736 1 prior 4 4 07 29.0
431534 1 prior 5 4 15 28.0
3367565 1 prior 6 2 07 19.0
550135 1 prior 7 1 09 20.0
3108588 1 prior 8 1 14 14.0
2295261 1 prior 9 1 16 0.0
2550362 1 prior 10 4 08 30.0
Time taken: 0.121 seconds, Fetched: 10 row(s)
字段说明
order_id:订单号
user_id:用户id
eval_set:订单的行为(历史产生的或者训练所需要的)
order_number:用户购买订单的先后顺序
order_dow:order day of week ,订单在星期几进行购买的(0-6)
order_hour_of_day:订单在哪个小时段产生的(0-23)
days_since_prior_order:表示后一个订单距离前一个订单的相隔天数
2.2 建立trains表
说明:
order_id:订单号
product_id:商品ID
add_to_cart_order:加入购物车的位置
reordered:这个订单是否重复购买(1 表示是 0 表示否)
建表
hive> create table trains(
> order_id string,
> product_id string,
> add_to_cart_order string,
> reordered string
> )
> row format delimited fields terminated by ','
> lines terminated by '\n';
OK
Time taken: 0.878 seconds
插入数据并查询前10行
hive> load data local inpath '/usr/local/src/apache-hive-1.2.2-bin/data/order_products__train.csv'
> into table trains;
Loading data to table dzw.trains
Table dzw.trains stats: [numFiles=1, totalSize=24680147]
OK
Time taken: 1.633 seconds
hive> select * from trains limit 10;
OK
order_id product_id add_to_cart_order reordered
1 49302 1 1
1 11109 2 1
1 10246 3 0
1 49683 4 0
1 43633 5 1
1 13176 6 0
1 47209 7 0
1 22035 8 1
36 39612 1 0
Time taken: 0.552 seconds, Fetched: 10 row(s)
清理第一行脏数据并查看效果
hive> insert overwrite table trains
> select * from trains where order_id !='order_id';
Query ID = root_20201225175017_e0e740eb-b3cb-4e02-8eeb-3043eb75b946
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1608254818743_0028, Tracking URL = http://master:8088/proxy/application_1608254818743_0028/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0028
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2020-12-25 17:50:28,317 Stage-1 map = 0%, reduce = 0%
2020-12-25 17:50:39,025 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.37 sec
MapReduce Total cumulative CPU time: 4 seconds 370 msec
Ended Job = job_1608254818743_0028
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://master:9000/data/hive/warehouse/dzw.db/trains/.hive-staging_hive_2020-12-25_17-50-17_429_2849462889173378151-1/-ext-10000
Loading data to table dzw.trains
Table dzw.trains stats: [numFiles=1, numRows=1384617, totalSize=24680099, rawDataSize=23295482]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 4.37 sec HDFS Read: 24684298 HDFS Write: 24680176 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 370 msec
OK
Time taken: 23.199 seconds
hive> select * from trains limit 10;
OK
1 49302 1 1
1 11109 2 1
1 10246 3 0
1 49683 4 0
1 43633 5 1
1 13176 6 0
1 47209 7 0
1 22035 8 1
36 39612 1 0
36 19660 2 1
Time taken: 0.122 seconds, Fetched: 10 row(s)
3.常见业务操作
3.1 每个用户有多少个订单
分析
需求: user_id order_id => user_id order_cnt
思路:这个涉及到分组的问题,依照用户id进行分组,然后统计每组的个数
由于数据量比较大,我们就提出十条数据进行查看,否则跑的非常慢
其实,在实际工作中,我们也应该首次小批量验证代码的正确性,而不是刚开始就全量跑,否则超浪费时间。
hive> select user_id,count(order_id)
> from orders
> group by user_id
> limit 10;
Query ID = root_20201225180531_9bfc67bd-df69-425a-847d-8b753c8ef72e
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1608254818743_0029, Tracking URL = http://master:8088/proxy/application_1608254818743_0029/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0029
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2020-12-25 18:05:41,044 Stage-1 map = 0%, reduce = 0%
2020-12-25 18:05:51,752 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.89 sec
2020-12-25 18:05:59,383 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.03 sec
MapReduce Total cumulative CPU time: 7 seconds 30 msec
Ended Job = job_1608254818743_0029
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 7.03 sec HDFS Read: 108976722 HDFS Write: 80 SUCCESS
Total MapReduce CPU Time Spent: 7 seconds 30 msec
OK
1 11
10 6
100 6
1000 8
10000 73
100000 10
100001 67
100002 13
100003 4
100004 9
Time taken: 29.954 seconds, Fetched: 10 row(s)
3.2 每个用户一个订单平均有多少商品
(1)一个订单有多少商品
hive> select order_id,count(product_id) pro_cnt
> from trains
> group by order_id
> limit 10;
Query ID = root_20201225201808_59c0d4b7-4aab-4715-bf12-747a502a4bdc
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1608254818743_0037, Tracking URL = http://master:8088/proxy/application_1608254818743_0037/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0037
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2020-12-25 20:18:19,039 Stage-1 map = 0%, reduce = 0%
2020-12-25 20:18:26,685 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.35 sec
2020-12-25 20:18:34,173 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.16 sec
MapReduce Total cumulative CPU time: 5 seconds 160 msec
Ended Job = job_1608254818743_0037
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.16 sec HDFS Read: 24687727 HDFS Write: 95 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 160 msec
OK
1 8
100000 15
1000008 7
1000029 8
100003 2
1000046 32
1000080 7
1000162 22
1000197 2
1000209 4
Time taken: 26.807 seconds, Fetched: 10 row(s)
(2)每个用户对应的商品量
hive> select od.user_id,t.pro_cnt
> from orders od
> inner join (select order_id,count(product_id) pro_cnt
> from trains
> group by order_id
> limit 100
> ) t
> on od.order_id=t.order_id
> limit 10;
Query ID = root_20201225194141_0f7f1456-3b80-424b-8f39-19763b884c1b
Total jobs = 5
Launching Job 1 out of 5
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1608254818743_0030, Tracking URL = http://master:8088/proxy/application_1608254818743_0030/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0030
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2020-12-25 19:41:49,190 Stage-1 map = 0%, reduce = 0%
2020-12-25 19:41:57,591 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.54 sec
2020-12-25 19:42:06,041 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.38 sec
MapReduce Total cumulative CPU time: 5 seconds 380 msec
Ended Job = job_1608254818743_0030
Launching Job 2 out of 5
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1608254818743_0031, Tracking URL = http://master:8088/proxy/application_1608254818743_0031/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0031
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 1
2020-12-25 19:42:19,516 Stage-2 map = 0%, reduce = 0%
2020-12-25 19:42:24,912 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 0.89 sec
2020-12-25 19:42:32,300 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 2.5 sec
MapReduce Total cumulative CPU time: 2 seconds 500 msec
Ended Job = job_1608254818743_0031
Stage-8 is selected by condition resolver.
Stage-9 is filtered out by condition resolver.
Stage-3 is filtered out by condition resolver.
Execution log at: /tmp/root/root_20201225194141_0f7f1456-3b80-424b-8f39-19763b884c1b.log
2020-12-25 19:42:46 Starting to launch local task to process map join; maximum memory = 518979584
2020-12-25 19:42:48 Dump the side-table for tag: 1 with group count: 100 into file: file:/tmp/root/91d22153-3518-4d43-b107-ce821689c861/hive_2020-12-25_19-41-41_039_8931438817336216656-1/-local-10005/HashTable-Stage-5/MapJoin-mapfile01--.hashtable
2020-12-25 19:42:48 Uploaded 1 File to: file:/tmp/root/91d22153-3518-4d43-b107-ce821689c861/hive_2020-12-25_19-41-41_039_8931438817336216656-1/-local-10005/HashTable-Stage-5/MapJoin-mapfile01--.hashtable (2953 bytes)
2020-12-25 19:42:48 End of local task; Time Taken: 1.936 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 4 out of 5
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1608254818743_0032, Tracking URL = http://master:8088/proxy/application_1608254818743_0032/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0032
Hadoop job information for Stage-5: number of mappers: 1; number of reducers: 0
2020-12-25 19:42:56,816 Stage-5 map = 0%, reduce = 0%
2020-12-25 19:43:05,282 Stage-5 map = 100%, reduce = 0%, Cumulative CPU 2.85 sec
MapReduce Total cumulative CPU time: 2 seconds 850 msec
Ended Job = job_1608254818743_0032
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.38 sec HDFS Read: 24687287 HDFS Write: 2696 SUCCESS
Stage-Stage-2: Map: 1 Reduce: 1 Cumulative CPU: 2.5 sec HDFS Read: 6902 HDFS Write: 2696 SUCCESS
Stage-Stage-5: Map: 1 Cumulative CPU: 2.85 sec HDFS Read: 19802604 HDFS Write: 80 SUCCESS
Total MapReduce CPU Time Spent: 10 seconds 730 msec
OK
6681 6
8137 6
9099 2
10892 5
11849 5
12918 1
20729 6
23867 20
24627 10
29165 15
Time taken: 85.301 seconds, Fetched: 10 row(s)
(3)计算每个用户对应的平均商品量
hive> select od.user_id,sum(t.pro_cnt)/count(*),avg(t.pro_cnt)
> from orders od
> inner join (select order_id,count(product_id) pro_cnt
> from trains
> group by order_id
> limit 100
> ) t
> on od.order_id=t.order_id
> group by od.user_id
> limit 10;
Query ID = root_20201225200037_7d1b3577-822a-4983-9d0a-cc33eca009e1
Total jobs = 6
Launching Job 1 out of 6
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1608254818743_0033, Tracking URL = http://master:8088/proxy/application_1608254818743_0033/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0033
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2020-12-25 20:00:44,401 Stage-1 map = 0%, reduce = 0%
2020-12-25 20:00:52,652 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.11 sec
2020-12-25 20:01:00,065 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.77 sec
MapReduce Total cumulative CPU time: 4 seconds 770 msec
Ended Job = job_1608254818743_0033
Launching Job 2 out of 6
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1608254818743_0034, Tracking URL = http://master:8088/proxy/application_1608254818743_0034/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0034
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 1
2020-12-25 20:01:12,082 Stage-2 map = 0%, reduce = 0%
2020-12-25 20:01:17,429 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 0.86 sec
2020-12-25 20:01:25,707 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 2.42 sec
MapReduce Total cumulative CPU time: 2 seconds 420 msec
Ended Job = job_1608254818743_0034
Stage-9 is selected by condition resolver.
Stage-10 is filtered out by condition resolver.
Stage-3 is filtered out by condition resolver.
Execution log at: /tmp/root/root_20201225200037_7d1b3577-822a-4983-9d0a-cc33eca009e1.log
2020-12-25 20:01:41 Starting to launch local task to process map join; maximum memory = 518979584
2020-12-25 20:01:44 Dump the side-table for tag: 1 with group count: 100 into file: file:/tmp/root/91d22153-3518-4d43-b107-ce821689c861/hive_2020-12-25_20-00-37_002_3179557432139060992-1/-local-10006/HashTable-Stage-6/MapJoin-mapfile21--.hashtable
2020-12-25 20:01:44 Uploaded 1 File to: file:/tmp/root/91d22153-3518-4d43-b107-ce821689c861/hive_2020-12-25_20-00-37_002_3179557432139060992-1/-local-10006/HashTable-Stage-6/MapJoin-mapfile21--.hashtable (2953 bytes)
2020-12-25 20:01:44 End of local task; Time Taken: 3.012 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 4 out of 6
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1608254818743_0035, Tracking URL = http://master:8088/proxy/application_1608254818743_0035/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0035
Hadoop job information for Stage-6: number of mappers: 1; number of reducers: 0
2020-12-25 20:01:53,119 Stage-6 map = 0%, reduce = 0%
2020-12-25 20:02:01,607 Stage-6 map = 100%, reduce = 0%, Cumulative CPU 3.8 sec
MapReduce Total cumulative CPU time: 3 seconds 800 msec
Ended Job = job_1608254818743_0035
Launching Job 5 out of 6
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1608254818743_0036, Tracking URL = http://master:8088/proxy/application_1608254818743_0036/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0036
Hadoop job information for Stage-4: number of mappers: 1; number of reducers: 1
2020-12-25 20:02:13,693 Stage-4 map = 0%, reduce = 0%
2020-12-25 20:02:19,861 Stage-4 map = 100%, reduce = 0%, Cumulative CPU 0.78 sec
2020-12-25 20:02:27,212 Stage-4 map = 100%, reduce = 100%, Cumulative CPU 2.53 sec
MapReduce Total cumulative CPU time: 2 seconds 530 msec
Ended Job = job_1608254818743_0036
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.77 sec HDFS Read: 24687372 HDFS Write: 2696 SUCCESS
Stage-Stage-2: Map: 1 Reduce: 1 Cumulative CPU: 2.42 sec HDFS Read: 6902 HDFS Write: 2696 SUCCESS
Stage-Stage-6: Map: 1 Cumulative CPU: 3.8 sec HDFS Read: 108975489 HDFS Write: 4063 SUCCESS
Stage-Stage-4: Map: 1 Reduce: 1 Cumulative CPU: 2.53 sec HDFS Read: 11337 HDFS Write: 148 SUCCESS
Total MapReduce CPU Time Spent: 13 seconds 520 msec
OK
102695 1.0 1.0
106588 5.0 5.0
10892 5.0 5.0
112108 8.0 8.0
113656 2.0 2.0
115438 8.0 8.0
115520 1.0 1.0
116188 7.0 7.0
117294 3.0 3.0
11849 5.0 5.0
Time taken: 111.316 seconds, Fetched: 10 row(s)
4.每个用户在一周中的购买订单的分布
思路:列转行
hive> select
> 'user_id'
> , sum(case when order_dow='0' then 1 else 0 end) dow0
> , sum(case when order_dow='1' then 1 else 0 end) dow1
> , sum(case when order_dow='2' then 1 else 0 end) dow2
> , sum(case when order_dow='3' then 1 else 0 end) dow3
> , sum(case when order_dow='4' then 1 else 0 end) dow4
> , sum(case when order_dow='5' then 1 else 0 end) dow5
> , sum(case when order_dow='6' then 1 else 0 end) dow6
> from orders
> where user_id in ('1','2','3')
> group by user_id;
Query ID = root_20201225222212_b6fe7699-1cff-4bd7-879f-1ca76a628b39
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1608254818743_0045, Tracking URL = http://master:8088/proxy/application_1608254818743_0045/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0045
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2020-12-25 22:22:22,282 Stage-1 map = 0%, reduce = 0%
2020-12-25 22:22:30,755 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.5 sec
2020-12-25 22:22:37,263 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.77 sec
MapReduce Total cumulative CPU time: 4 seconds 770 msec
Ended Job = job_1608254818743_0045
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.77 sec HDFS Read: 108982479 HDFS Write: 66 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 770 msec
OK
user_id 0 3 2 2 4 0 0
user_id 0 6 5 2 1 1 0
user_id 6 2 1 3 0 1 0
Time taken: 25.924 seconds, Fetched: 3 row(s)
5.某个时间段查看每个用户购买了哪些商品
将用户信息表和产品信息表关联
hive> select od.user_id,tr.product_id
> from orders od
> inner join trains tr
> on od.order_id=tr.order_id
> where od.order_hour_of_day='16'
> limit 30;
Query ID = root_20201225211222_d681738f-a98f-4646-a9a1-b87cdeae46ca
Total jobs = 2
Stage-6 is selected by condition resolver.
Stage-1 is filtered out by condition resolver.
Execution log at: /tmp/root/root_20201225211222_d681738f-a98f-4646-a9a1-b87cdeae46ca.log
2020-12-25 21:12:36 Starting to launch local task to process map join; maximum memory = 518979584
2020-12-25 21:12:42 Dump the side-table for tag: 1 with group count: 131209 into file: file:/tmp/root/07adb778-9b83-4c21-8ca0-a04988cf34fd/hive_2020-12-25_21-12-22_556_466250092893260946-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile21--.hashtable
2020-12-25 21:12:43 Uploaded 1 File to: file:/tmp/root/07adb778-9b83-4c21-8ca0-a04988cf34fd/hive_2020-12-25_21-12-22_556_466250092893260946-1/-local-10003/HashTable-Stage-3/MapJoin-mapfile21--.hashtable (17754343 bytes)
2020-12-25 21:12:43 End of local task; Time Taken: 7.667 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 2 out of 2
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1608254818743_0041, Tracking URL = http://master:8088/proxy/application_1608254818743_0041/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0041
Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 0
2020-12-25 21:12:53,310 Stage-3 map = 0%, reduce = 0%
2020-12-25 21:13:01,842 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 3.53 sec
MapReduce Total cumulative CPU time: 3 seconds 530 msec
Ended Job = job_1608254818743_0041
MapReduce Jobs Launched:
Stage-Stage-3: Map: 1 Cumulative CPU: 3.53 sec HDFS Read: 97802 HDFS Write: 282 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 530 msec
OK
24 31222
52 46149
52 3798
52 24135
52 16797
52 43352
52 14032
52 39275
52 8048
52 30450
52 27839
52 30720
83 2186
83 16254
83 26856
128 25005
128 11512
128 40198
128 30949
128 43643
128 43713
128 18152
128 43798
128 48220
128 15984
176 24852
176 31958
176 20995
176 44632
176 13639
Time taken: 41.451 seconds, Fetched: 30 row(s)
6.想知道距离现在最近 或者最远的时间
思路:先建表导入数据
在应用聚合函数min(),max()进行筛选
hive> create table `udata`(
> `user_id` string,
> `item_id` string,
> `rating` string,
> `timestamp` string
> )
> row format delimited fields terminated by '\t'
> lines terminated by '\n';
OK
Time taken: 0.06 seconds
hive> load data local inpath '/usr/local/src/apache-hive-1.2.2-bin/data/ml-100k/u.data'
> into table udata;
Loading data to table dzw.udata
Table dzw.udata stats: [numFiles=1, totalSize=1979173]
OK
Time taken: 0.317 seconds
hive> select * from udata limit 10;
OK
196 242 3 881250949
186 302 3 891717742
22 377 1 878887116
244 51 2 880606923
166 346 1 886397596
298 474 4 884182806
115 265 2 881171488
253 465 5 891628467
305 451 3 886324817
6 86 3 883603013
Time taken: 0.092 seconds, Fetched: 10 row(s)
hive> select min(`timestamp`) min_tim, max(`timestamp`) max_min
> from udata;
Query ID = root_20201225214757_845d7cc9-80fd-41c3-b554-2c9eda0332ee
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1608254818743_0043, Tracking URL = http://master:8088/proxy/application_1608254818743_0043/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0043
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2020-12-25 21:48:03,904 Stage-1 map = 0%, reduce = 0%
2020-12-25 21:48:10,313 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.64 sec
2020-12-25 21:48:17,542 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.09 sec
MapReduce Total cumulative CPU time: 3 seconds 90 msec
Ended Job = job_1608254818743_0043
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.09 sec HDFS Read: 1986910 HDFS Write: 20 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 90 msec
OK
874724710 893286638
Time taken: 21.516 seconds, Fetched: 1 row(s)
7.判断用户在那一天比较活跃
hive> select
> user_id, collect_list(cast(days as int)) as day_list
> from
> (select
> user_id
> , (cast(893286638 as bigint) - cast(`timestamp` as bigint)) / (24*60*60) * rating as days
> from udata
> ) t
> group by user_id
> limit 10;
Query ID = root_20201225215327_0f6867b5-be7b-4e08-870c-fdee5a8f41c0
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1608254818743_0044, Tracking URL = http://master:8088/proxy/application_1608254818743_0044/
Kill Command = /usr/local/src/hadoop-2.6.5/bin/hadoop job -kill job_1608254818743_0044
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2020-12-25 21:53:33,180 Stage-1 map = 0%, reduce = 0%
2020-12-25 21:53:41,420 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.68 sec
2020-12-25 21:53:47,711 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.24 sec
MapReduce Total cumulative CPU time: 4 seconds 240 msec
Ended Job = job_1608254818743_0044
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.24 sec HDFS Read: 1989361 HDFS Write: 4098 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 240 msec
OK
1 [682,158,682,843,271,1054,204,682,341,636,843,667,1060,853,758,632,682,1054,569,853,91,843,1054,682,40,843,843,843,338,843,632,632,1054,948,379,210,421,1054,632,853,843,203,758,682,170,341,1054,208,511,569,338,208,511,758,682,682,843,1054,379,341,834,1054,170,843,210,843,682,1054,835,569,210,203,1044,632,853,1060,632,853,569,843,682,843,758,511,948,1054,848,853,843,204,417,170,758,421,170,511,843,417,569,632,848,632,948,610,170,338,682,632,183,170,632,511,814,632,853,1060,843,569,682,421,843,1054,569,569,843,1054,853,511,208,853,843,843,511,632,81,632,948,511,853,1060,843,170,632,848,843,843,843,948,1060,170,208,1054,569,511,341,848,914,263,511,511,569,263,758,682,758,163,626,1054,210,511,758,417,626,632,1060,1054,853,682,1018,341,843,135,948,632,511,341,1060,569,848,421,170,1060,843,569,948,758,853,379,682,170,682,758,843,853,1060,843,853,122,853,843,848,835,341,853,421,421,170,1054,1060,853,843,203,1044,1054,843,843,948,569,341,1060,843,1054,569,203,682,1054,948,511,632,843,341,682,1060,511,853,1054,843,569,682,341,948,421,632,189,1054,682,1054,135,1054,170,271,948,1054,204,843,682,1054,843,1060,626,853,421]
10 [712,712,534,891,712,890,534,891,891,890,712,597,712,712,712,712,890,653,712,712,712,891,712,712,534,891,712,490,891,712,534,712,891,891,712,712,712,712,712,712,891,891,712,891,891,712,890,712,890,891,712,712,534,712,712,712,712,891,712,712,712,712,712,712,712,712,712,712,712,712,534,890,890,712,712,712,712,712,712,891,891,891,891,890,712,712,534,712,712,712,712,890,712,891,891,891,712,712,534,891,891,712,890,891,712,712,712,712,712,891,712,712,712,712,712,712,712,712,891,712,891,891,712,534,891,534,712,712,712,712,534,712,712,534,712,712,891,712,534,712,712,891,712,712,891,712,712,712,891,712,712,891,712,712,712,712,890,712,712,712,890,712,712,534,891,712,891,712,890,712,712,712,891,712,891,890,712,891,890,712,712,712,712,534]
100 [88,44,66,22,88,88,44,44,88,66,66,66,66,88,110,66,66,66,66,88,66,66,110,44,44,88,88,88,88,66,66,66,22,88,22,22,66,66,88,22,66,66,66,88,88,88,66,88,88,22,44,44,44,44,66,88,66,88,110]
101 [560,560,560,560,560,747,373,560,560,373,373,373,560,560,373,560,373,747,373,747,560,747,373,747,186,934,373,186,373,373,747,560,560,747,560,747,747,747,373,560,747,560,747,560,560,373,747,747,373,373,560,373,373,560,373,560,560,560,186,560,747,747,560,560,560,560,373]
102 [220,155,155,51,155,347,331,103,155,103,604,155,331,155,231,231,216,103,103,155,155,207,3,6,441,10,3,155,437,207,103,155,51,13,207,155,155,103,331,155,155,155,155,493,207,104,533,155,155,103,347,155,6,150,155,103,10,103,103,103,207,604,207,207,155,6,207,103,155,103,441,155,441,103,103,220,6,103,6,10,155,6,155,103,103,103,103,155,347,155,155,155,155,155,155,103,103,51,103,103,103,331,10,10,155,194,103,10,103,144,220,155,155,155,136,155,51,13,805,51,155,6,6,331,155,188,103,103,331,220,103,347,103,103,51,155,10,207,10,51,103,220,155,103,103,231,231,207,103,103,155,155,6,51,657,220,231,155,155,103,6,441,10,155,103,43,805,155,155,10,103,103,10,6,155,144,6,115,10,6,155,155,103,284,231,155,6,155,155,6,207,155,155,103,207,6,155,51,103,6,155,155,480,10,103,207,263,331,103,220,136,179,207,155,103,155]
103 [595,595,446,595,595,744,446,446,744,744,595,595,446,446,297,148,446,446,595,595,744,446,446,595,595,446,595,744,446]
104 [56,111,112,223,111,168,111,168,55,55,167,167,55,112,167,280,56,167,223,55,223,168,167,55,55,112,223,167,167,167,111,55,167,224,55,111,112,111,167,279,168,167,112,168,56,168,167,168,223,223,223,111,167,55,223,168,280,224,224,223,112,111,224,278,112,223,167,55,168,167,167,167,223,55,167,111,167,55,56,224,112,280,223,224,111,279,56,111,111,55,55,111,112,278,56,167,167,224,112,56,168,167,168,167,112,112,111,168,111,167,111]
105 [188,235,188,94,188,141,141,188,188,235,94,141,94,94,235,141,188,235,188,94,94,141,141]
106 [547,547,547,435,410,547,547,217,410,547,547,548,410,410,684,547,684,326,548,547,547,547,548,547,410,435,548,410,435,212,410,684,684,547,547,410,326,547,326,547,547,684,217,544,547,410,410,435,547,410,548,435,547,410,684,547,684,411,435,410,410,410,685,547]
107 [70,46,93,46,93,23,117,117,93,93,46,23,46,117,70,46,70,93,70,23,70,70]
Time taken: 21.771 seconds, Fetched: 10 row(s)
8.用户购买的数量大于100的商品
hive> select
> user_id, count(distinct product_id) pro_cnt
> from
> (
> -- 订单训练数据 场景 整合两个新老系统数据
> select
> a.user_id,b.product_id
> from orders as a
> left join trains b
> on a.order_id=b.order_id
> union all
> -- 订单历史数据
> select
> a.user_id,b.product_id
> from orders as a
> left join prior b
> on a.order_id=b.order_id
> ) t
> group by user_id
> having pro_cnt >= 100
> limit 10;
或者
with user_pro_cnt_tmp as (
select * from
(-- 订单训练数据
select
a.user_id,b.product_id
from orders as a
left join trains b
on a.order_id=b.order_id
union all
-- 订单历史数据
select
a.user_id,b.product_id
from orders as a
left join prior b
on a.order_id=b.order_id
) t
)
select
user_id
, count(distinct product_id) pro_cnt
from user_pro_cnt_tmp
group by user_id
having pro_cnt >= 100
limit 10;
结果
100001 211
100010 119
100038 177
10009 125
100092 152
100114 115
100123 170
100146 154
100173 106
100187 154















 568
568











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









