







 本文记录了一次在Hive中尝试插入数据时遇到的错误,错误表现为MapReduce任务无法正常启动。问题根源在于NameNode内存不足和YARN配置问题。解决方案包括检查并调整Hadoop的ClassPath,更新`yarn-site.xml`配置,优化`hadoop-env.sh`,重启Hadoop服务,以及设置Hive本地模式。通过这些步骤,最终成功插入数据,并在ResourceManager Web UI中验证了任务完成。
本文记录了一次在Hive中尝试插入数据时遇到的错误,错误表现为MapReduce任务无法正常启动。问题根源在于NameNode内存不足和YARN配置问题。解决方案包括检查并调整Hadoop的ClassPath,更新`yarn-site.xml`配置,优化`hadoop-env.sh`,重启Hadoop服务,以及设置Hive本地模式。通过这些步骤,最终成功插入数据,并在ResourceManager Web UI中验证了任务完成。
记录一次hive 错误
描述错误:
进入hive客户端插入数据报错
# 报错:
hive (default)> insert into javaAndBigdata.student(id,name) values (3,"java页大数据");
Query ID = root_20220323224810_5192a9f4-95ae-4166-b21e-c8e5f1493c32
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
2022-03-23 22:48:15,074 INFO [d31f649c-88de-4e0c-9dbb-f724e403a684 main] client.AHSProxy: Connecting to Application History server at slave2/192.168.52.11:10200
2022-03-23 22:48:15,183 INFO [d31f649c-88de-4e0c-9dbb-f724e403a684 main] client.AHSProxy: Connecting to Application History server at slave2/192.168.52.11:10200
2022-03-23 22:48:15,252 INFO [d31f649c-88de-4e0c-9dbb-f724e403a684 main] client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
Starting Job = job_1648046463761_0002, Tracking URL = http://slave1:8088/proxy/application_1648046463761_0002/
Kill Command = /opt/hadoop-3.2.2/bin/mapred job -kill job_1648046463761_0002
Hadoop job information for Stage-1: number of mappers: 0; number of reducers: 0
2022-03-23 22:48:36,569 Stage-1 map = 0%, reduce = 0%
Ended Job = job_1648046463761_0002 with errors
Error during job, obtaining debugging information...
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec
# 解决:
1. 获取Hadoop classpath
[root@leader root]# hadoop classpath
/opt/hadoop-3.2.2/etc/hadoop:/opt/hadoop-3.2.2/share/hadoop/common/lib/*:/opt/hadoop-3.2.2/share/hadoop/common/*:/opt/hadoop-3.2.2/share/hadoop/hdfs:/opt/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/opt/hadoop-3.2.2/share/hadoop/hdfs/*:/opt/hadoop-3.2.2/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.2.2/share/hadoop/mapreduce/*:/opt/hadoop-3.2.2/share/hadoop/yarn:/opt/hadoop-3.2.2/share/hadoop/yarn/lib/*:/opt/hadoop-3.2.2/share/hadoop/yarn/*:/opt/hadoop-3.2.2/bin/hadoop
2. 往yarn-site.xml文件中添加以下内容 #value为hadoop classpath值
<property>
<name>yarn.application.classpath</name>
<value>/opt/hadoop-3.2.2/etc/hadoop:/opt/hadoop-3.2.2/share/hadoop/common/lib/*:/opt/hadoop-3.2.2/share/hadoop/common/*:/opt/hadoop-3.2.2/share/hadoop/hdfs:/opt/hadoop-3.2.2/share/hadoop/hdfs/lib/*:/opt/hadoop-3.2.2/share/hadoop/hdfs/*:/opt/hadoop-3.2.2/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.2.2/share/hadoop/mapreduce/*:/opt/hadoop-3.2.2/share/hadoop/yarn:/opt/hadoop-3.2.2/share/hadoop/yarn/lib/*:/opt/hadoop-3.2.2/share/hadoop/yarn/*:/opt/hadoop-3.2.2/bin/hadoop</value>
</property>
3. 往hadoop-env.sh文件中添加以下内容 # 根据自身情况!!
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -Xmx2048m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx4096m"
4. 重启hadoop
5. 启动hive 和hiveserver2
6. 再次插入数据
hive (default)> insert into javaAndBigdata.student(id,name) values (4,"let it go");
Query ID = root_20220323232131_0246d4d1-6982-44c3-9b81-b8d5b177585b
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
2022-03-23 23:21:32,341 INFO [21d358d7-5351-4236-a51b-72e1fff3f8e2 main] client.AHSProxy: Connecting to Application History server at slave2/192.168.52.11:10200
2022-03-23 23:21:32,372 INFO [21d358d7-5351-4236-a51b-72e1fff3f8e2 main] client.AHSProxy: Connecting to Application History server at slave2/192.168.52.11:10200
2022-03-23 23:21:32,377 INFO [21d358d7-5351-4236-a51b-72e1fff3f8e2 main] client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
Starting Job = job_1648048675105_0002, Tracking URL = http://slave1:8088/proxy/application_1648048675105_0002/
Kill Command = /opt/hadoop-3.2.2/bin/mapred job -kill job_1648048675105_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2022-03-23 23:21:54,900 Stage-1 map = 0%, reduce = 0%
2022-03-23 23:22:05,376 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.45 sec
2022-03-23 23:22:11,604 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.4 sec
MapReduce Total cumulative CPU time: 4 seconds 400 msec
Ended Job = job_1648048675105_0002
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://mycluster/user/hive/warehouse/javaandbigdata.db/student/.hive-staging_hive_2022-03-23_23-21-31_828_2244712009779940990-1/-ext-10000
Loading data to table javaandbigdata.student
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.4 sec HDFS Read: 15467 HDFS Write: 253 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 400 msec
OK
_col0 _col1
Time taken: 42.228 seconds
---
# 查看效果!
hive (default)>
> select * from javaAndBigdata.student;
OK
student.id student.name
1 java
2 bigdata
3 java页大数据
4 let it go
Time taken: 0.146 seconds, Fetched: 4 row(s)
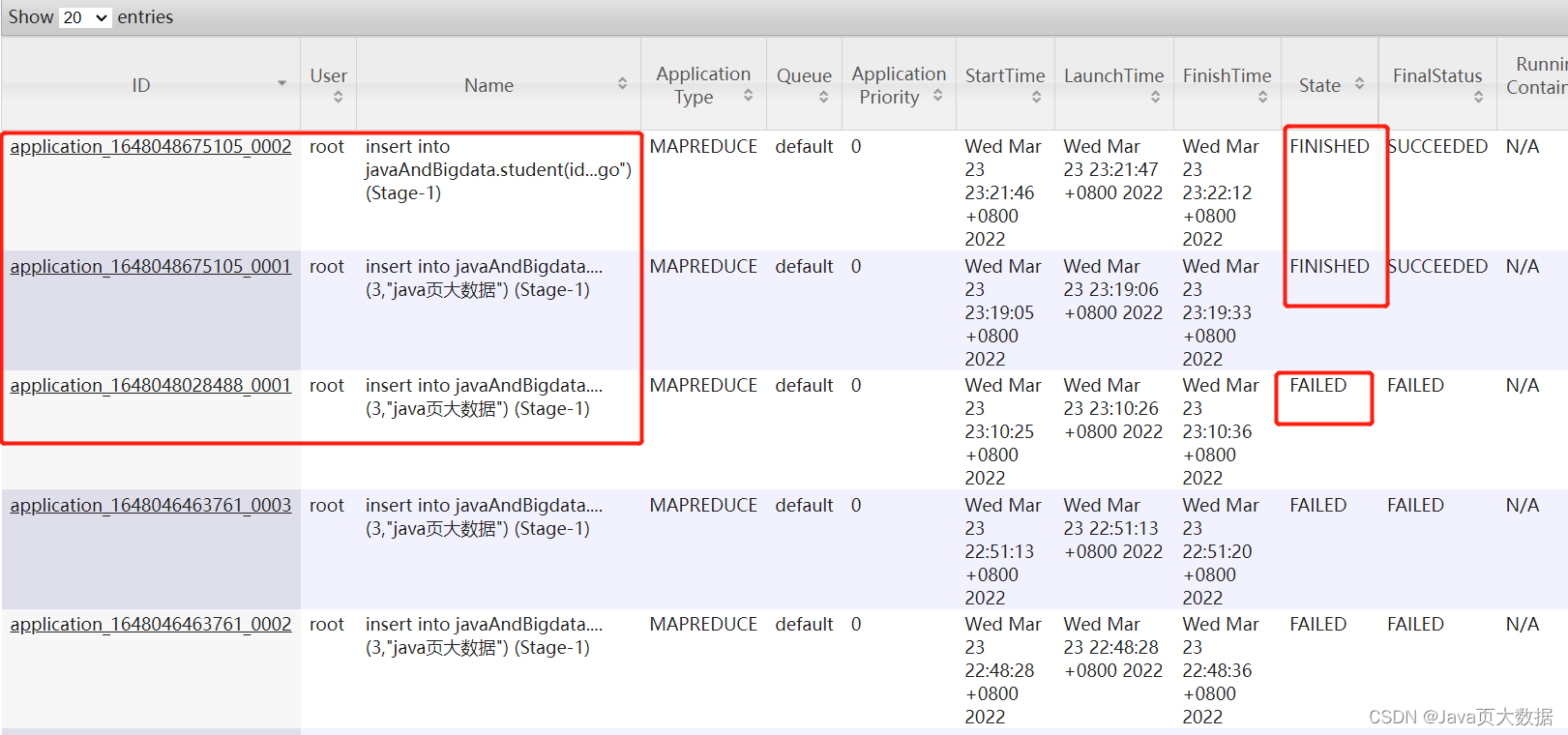
7. 到resourcemanager webui查看;会看到对应的task是成功的,还有其他之前失败的task
# 原因:
- namenode内存空间不够,JVM剩余内存空间不够新job运行所致
- yarn与hadoop之间的访问出现问题,需要手动配置(maybe)
- resourcemanager webui结果展示
规避方法
使用本地而不是用yarn跑mr
set hive.exec.mode.local.auto=true;
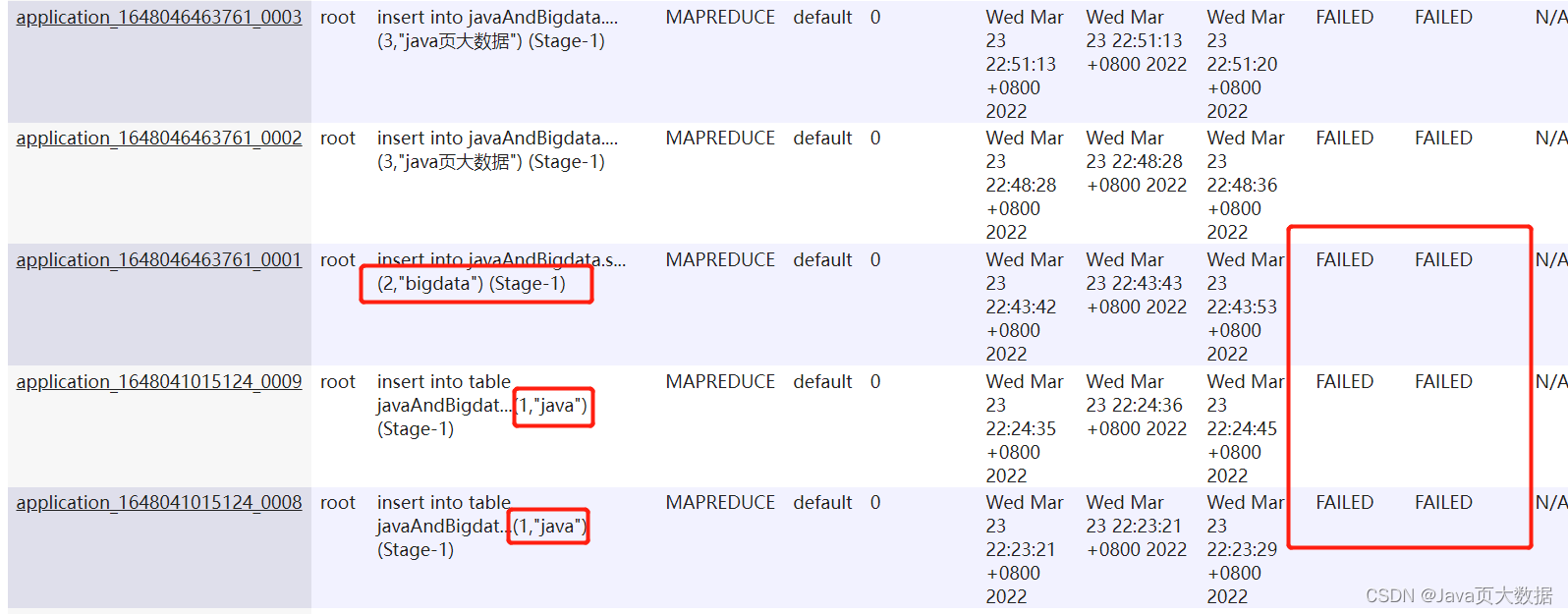
- 这可以插入数据,但是实质上你跑mapreduce的时候还是会碰到问题!!!
- 在resourcemanager webui也是可以看到,task压根就没有成功,但是本地却成功了!!截图如下:

















 1600
1600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









