







一.复杂应用的缓存执行计划
val inputRDD = sc.parallelize(Array[(Int,String)](
(1,"a"),(2,"b"),(3,"c"),(4,"d"),(5,"e"),(3,"f"),(2,"g"),(1,"h"),(2,"i")
),3)
val mappedRDD = inputRDD.map(r => (r._1 + 1, r._2))
val reducedByKeyRDD = mappedRDD.reduceByKey((x, y) => x + "_" + y,2)
val groupedByKeyRDD = mappedRDD.groupByKey().mapValues(v => v.toList)
reducedByKeyRDD.foreach(println)
groupedByKeyRDD.foreach(println)
val joinedRDD = reducedByKeyRDD.join(groupedByKeyRDD)
joinedRDD.foreach(println)

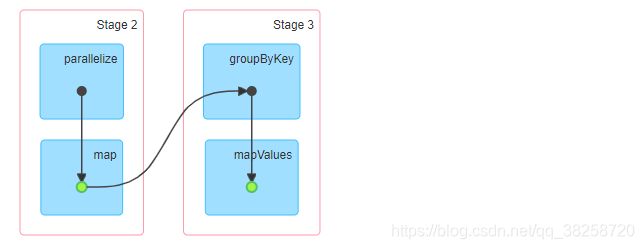
job0:
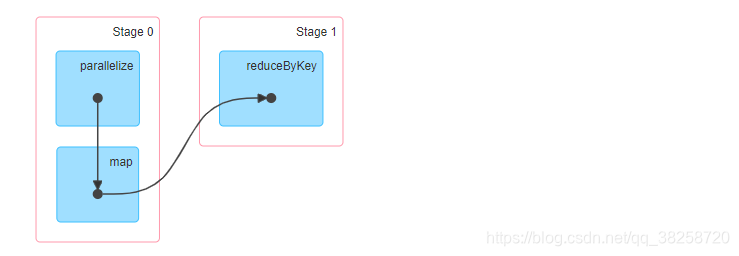
job1:
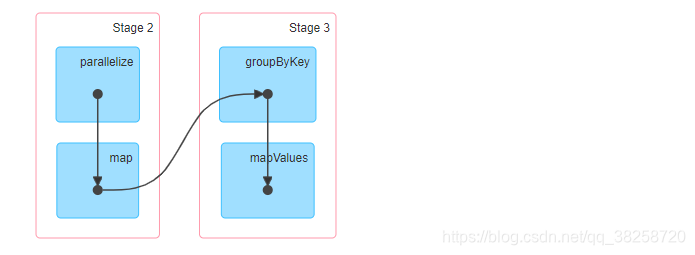
job2:
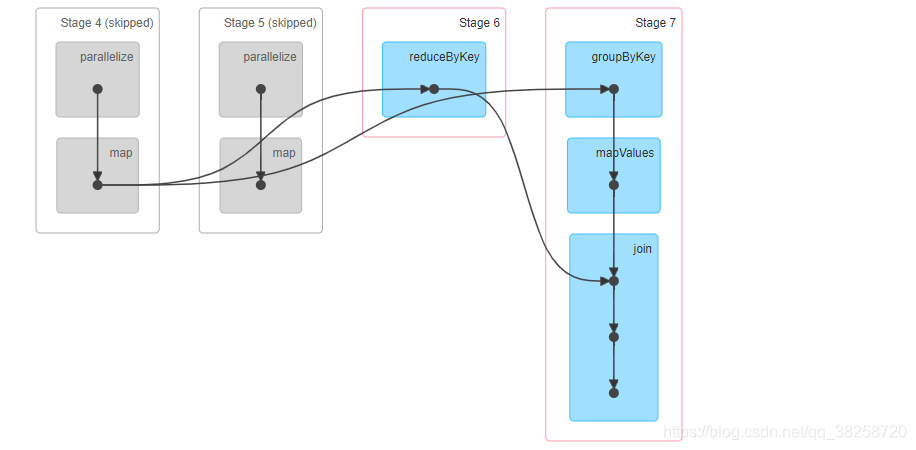
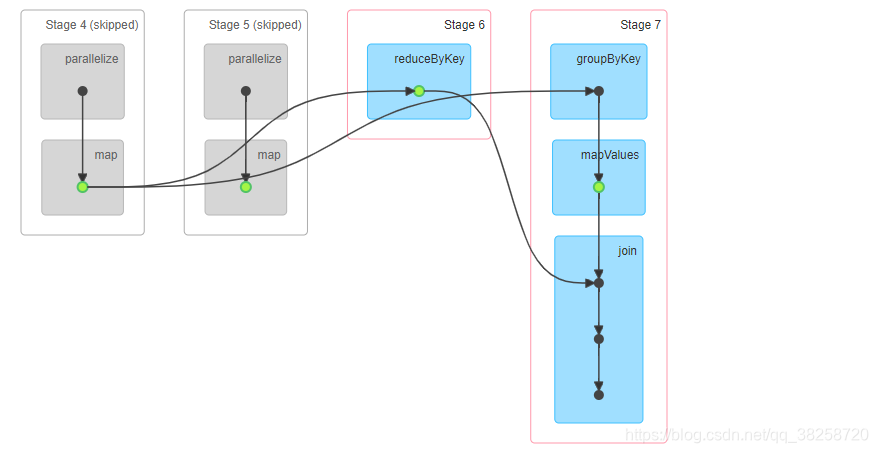
没使用缓存也会有skipped的原因:Spark task和Stage的跳过执行
使用缓存
val mappedRDD = inputRDD.map(r => (r._1 + 1, r._2))
mappedRDD.cache()
val reducedByKeyRDD = mappedRDD.reduceByKey((x, y) => x + "_" + y,2)
val groupedByKeyRDD = mappedRDD.groupByKey().mapValues(v => v.toList)
reducedByKeyRDD.cache()
groupedByKeyRDD.cache()
reducedByKeyRDD.foreach(println)
groupedByKeyRDD.foreach(println)
val joinedRDD = reducedByKeyRDD.join(groupedByKeyRDD)
joinedRDD.foreach(println)

job0:
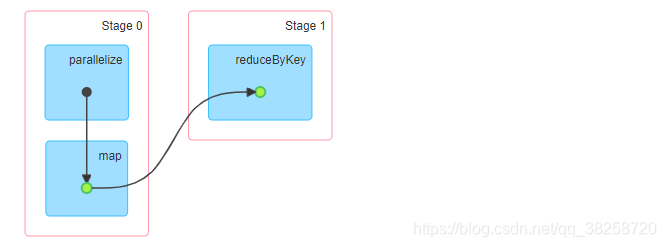
job1:
job2:
二.缓存数据的写入和读取方法
写入方法
上方例子中第一个缓存:

val mappedRDD = inputRDD.map(r => (r._1 + 1, r._2))
mappedRDD.cache()
val reducedByKeyRDD = mappedRDD.reduceByKey((x, y) => x + "_" + y,2)
map(),cache(),shuffle前的combine()的执行顺序是怎么样的呢?
如果map()操作后,先combine()的话,则mappedRDD的数据会丢失,不会缓存。所以是先缓存,再combine()。
所以原数据有9条记录,而shuffle write有8条记录,是因为先缓存了,再combine(),combine()后少了一条记录。所以缓存的数据大小可能比shuffle write的大小大。(并且shuffle会进行序列化,也会减少大小)
缓存的数据872B, shuffle write的数据301B:

写入的细节:
每个Executor都有个区域进行缓存,由blockManager管理。
将分区数据写入到memoryStore中,memoryStore包含LinkedHashMap,由双向链表实现。
key为blockId(rddId+partitionId),value为分区数据。
上方例子中第二个缓存:

读取方法
首先会寻找本地的blockManager去寻找缓存数据,如果在另一个结点,需通过远程访问。
三.缓存数据的替换和回收
自动缓存替换
spark采用了LRU算法(替换当前最久未被使用的RDD)
用LinkedHashMap来实现LRU,由双向链表实现。
最近插入或者读取的分区数据放在表头,尾部的数据就是当前最久未被使用的,替换时直接删掉尾部就行。
用户主动回收
使用 unpersist(),这个操作是立即执行的。 放在job执行之后。
四.spark缓存与mapreduce缓存对比
mapreduce的DistributedCache用于缓存job运行所需要的文件,不是用来存储中间结果的。
而且DistributedCache是将缓存文件存在本地磁盘上,不是内存中。
spark缓存的缺点:
1.缓存的RDD不能修改。
2.spark难以获取缓存rdd的生命周期,难以精确的缓存替换
3.application之间不能共享缓存,可以用Alluxio来解决。














 8192
8192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









