







目录
一.重新计算机制(lineage)
1.重新计算的前提
计算的过程中,需要保证幂等性。就是无论执行多少遍,得到的结果都要一样,重新计算才有意义。
- 计算逻辑需要确定,含有随机函数,得到的结果就不一样。
- 计算逻辑需要幂等,shuffle操作不能保证到下游的数据顺序到达,reduceByKey需要保证交换律和结合律。比如说求和就可以,字符串拼接则计算会不一致。
2.从哪开始重新计算
Spark采用了lineage的数据溯源方法。
核心思想:每个RDD的上游数据是什么,以及RDD是如何通过parent RDD计算得到的。(即记录了 数据+计算)
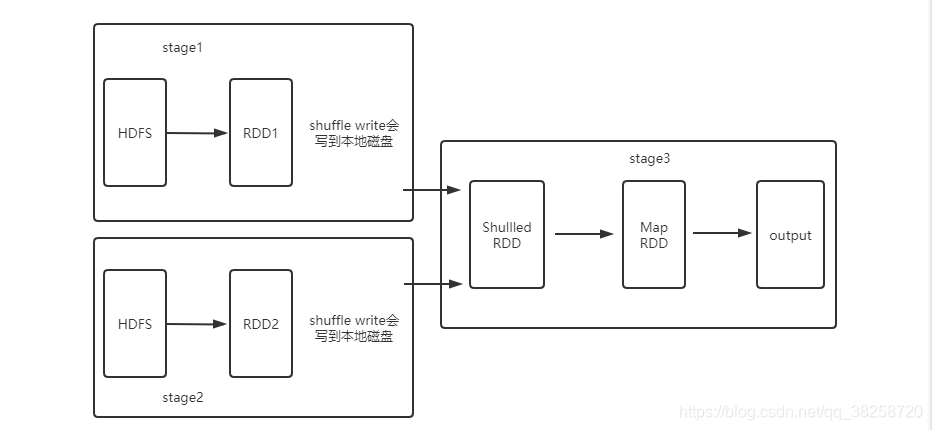
stage3的MapRDD的一个分区丢失,通过lineage向前查找:
- 如果向前查找的RDD缓存过,则直接从缓存的数据开始计算。
- 没有缓存继续向前,遇到shuffle操作,stage1和stage2的shuffle write数据采用了“延迟操作”,会写入本地磁盘,job完成后才会删除。
二.checkpoint机制
计算链过长,重新计算的代价很高,则需要checkpoint机制,将计算中间结果持久化,checkpoint是保存在hdfs或者Alluxio中。
补充一点:上方stage1的shuffle write会写入本地磁盘,但是并不可靠,宕机后就没了,如果计算链过长,可以用checkpoint持久化。
对于迭代型作业,虽然说可以用缓存,但是可能以前的缓存都被替换掉,然后最新的缓存的结点宕机,重新算开销很大,需要用checkpoint持久化。
1.一个action,一个checkpoint
sc.setCheckpointDir("checkpoint")
val data = Array[(Int, Char)]((1, 'a'), (2, 'b'),
(3, 'c'), (4, 'd'),
(5, 'e'), (3, 'f'),
(2, 'g'), (1, 'h')
)
val pairs = sc.parallelize(data, 3).map(r => (r._1 + 10, r._2))
pairs.checkpoint()
val result = pairs.groupByKey(2)
result.foreach(println)

一个action,会产生两个job,第二个job才执行checkpoint,执行checkpoint就停掉,不执行后面的代码。
2.checkpoint放action后有个系统bug
val pairs = sc.parallelize(data, 3).map(r => (r._1 + 10, r._2))
pairs.count()
pairs.checkpoint()
val result = pairs.groupByKey(2)
result.foreach(println)

这里有个系统bug
程序只有两个job,没有产生checkpoint,虽然 pairs.checkpoint() 位于 pairs.count() 后不对这个job生效,但是后面还有个 foreach,checkpoint也没有生效。
3.一个RDD进行多次checkpoint(系统需要改进)
val pairs = sc.parallelize(data, 3).map(r => (r._1 + 10, r._2))
pairs.checkpoint()
val result = pairs.groupByKey(2)
result.checkpoint()
result.foreach(println)

只对result进行了checkpoint,因为采用的是从后往前扫描,到resultRDD后就将lineage切断。源码还没有修改,修改的话改为从前往后扫描。
4.先cache再checkpoint
先cache,能使checkpoint产生的job不用从头计算。
checkpoint能够切断lineage,就不需要保存完整的依赖图。














 1213
1213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









