






这里我们主要分析一下 在Spark中创建RDD时候数据是如何分区的。
以一个集合数据为例:val listRdd = sc.makeRDD(List(1,2,3,4))点进makeRDD方法
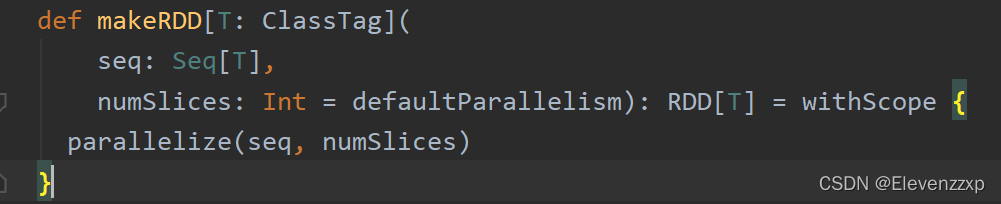
makeRDD方法有两个参数:
Seq:传入的序列
numSlices:切片数,没有制定的会有默认的defaultParallelism,默认的切片数与本机的内核数有关
点进parallelize方法,在点 getPartitions方法里的slice方法
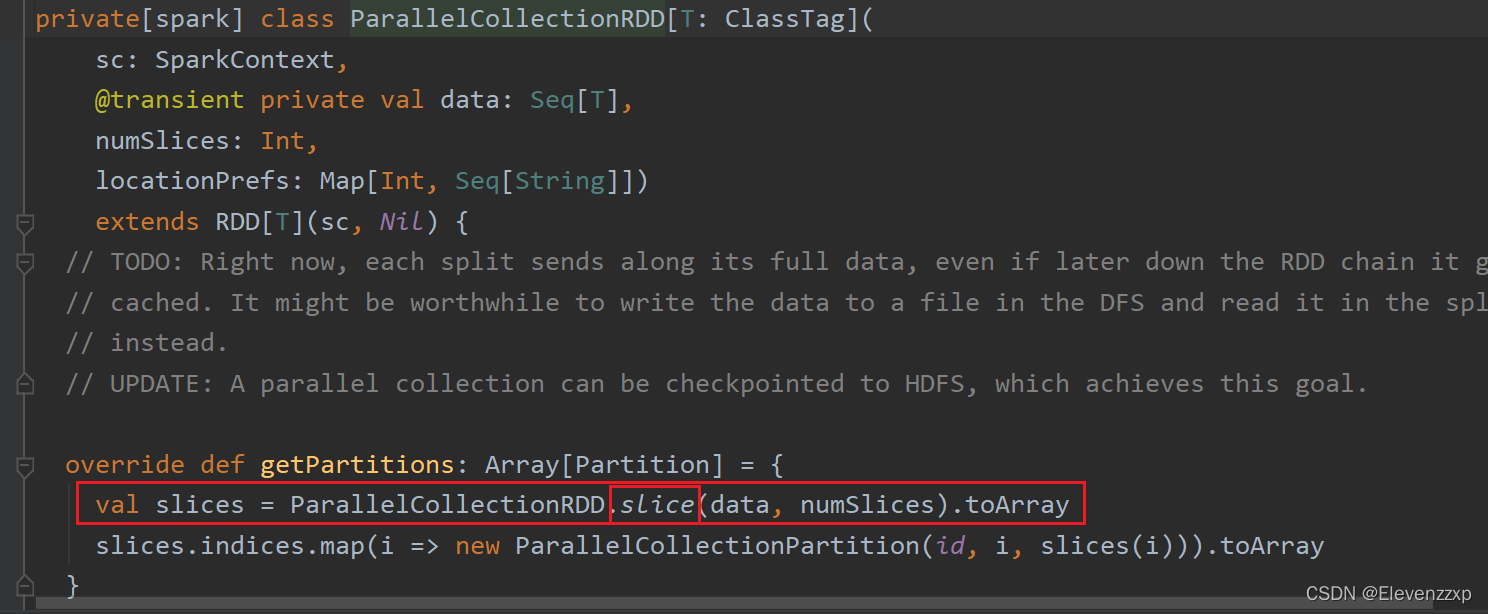

这里我们主要分析一下 在Spark中创建RDD时候数据是如何分区的。
以一个集合数据为例:val listRdd = sc.makeRDD(List(1,2,3,4))点进makeRDD方法
makeRDD方法有两个参数:
Seq:传入的序列
numSlices:切片数,没有制定的会有默认的defaultParallelism,默认的切片数与本机的内核数有关
点进parallelize方法,在点 getPartitions方法里的slice方法
 357
5298
357
5298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















