









一,单因子与对比分析可视化
数据
import pandas as pd
df = pd.read_csv('./HR.csv')
#查看前十条数据
df.head(10) 以下为显示的结果
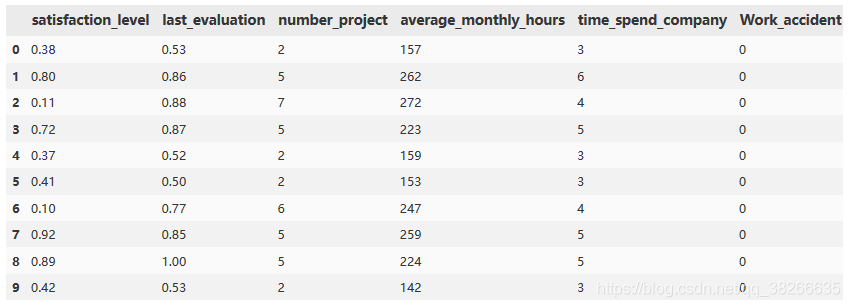
我们可以看出:
第一个属性satisfaction_level(满意度)的取值应该是在0-1之间;
last_evaluation(最近一次的评价)也是在0-1之间;
number_project(每个员工做的项目数);
average_monthly_hours(平均每个月的工作时长),这里取整了;
time_spend_company(在公司呆了多长时间),单位是年;
Work_accident(是否有工作事故),0表示没有,1表示有;
左(最近是否离职),1表示离职,0表示没有离职;
promotion_last_5years(最近五年是否晋升),1表示晋升,0表示没有晋升;
部门(每个员工所在的部门);
工资(工资),分三等级:低,中,高。
2.理论铺垫
(1)集中趋势:数据聚拢程度的一种衡量,表示数据聚拢在哪个位置。
++ 均值:经常用来衡量一些分布比较规律的连续值的集中趋势。
#DataFrame和Series这两种数据结构的操作共用,形式相同
df.mean()
#返回的类型是Series
type(df.mean())
#用Series直接求均值,得到一个值
df["satisfaction_level"].mean()++ 中位数:衡量一些异常值的集中趋势,如特大,特小的值。
#求中位数
df["satisfaction_level"].median()++ 众数:用在离散值的集中趋势衡量。
#众数
df.mode()
df["satisfaction_level"].mode()
df["department"].mode()
type(df["department"].mode())++ 分位数:跟其他几个值共同作用,产生不错的效果常用的是四分位数。
#求四分位数
df.quantile(q=0.25)
#Series求分位数
df["satisfaction_level"].quantile(q=0.25)(补)四分位数计算:

(2)离中趋势:数据离散程度的衡量
++ 标准差(如下),方差(标准差的平方):越大表示数据越离散,越小表示数据越聚。
#标准差
df.std()
df["satisfaction_level"].std()
#方差
df.var()
df["satisfaction_level"].var(0)注:关于正态分布的离中趋势的一个重要概念 - 对于正态分布的数据来说,数据落在-1倍标准差和+1倍标准差内的概率为69%,落在-1.96倍标准差和1.96倍标准差内的概率为95%,落在-2.58倍标准差和2.58倍标准差内的概率为99%,也就是这部分面积可以达到99%。
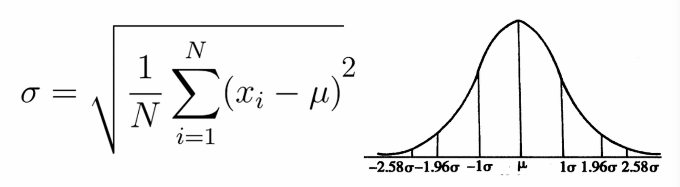
(3)数据分布:偏态与峰度
++偏态系数S: 。数据平均值偏离状态的一种衡量中位数与均值相差得多,就说这是有偏态的,分布值为正,正偏,它的均值比较大;负值,负偏,它的均值较小。
#偏态系数
df.skew()
#偏态值是负的,说明平均值偏小,大部分值大于平均值
#说明大多数人处于比较满意的状态
df["satisfaction_level"].skew()++峰态系数K: 数据分布集中强度的衡量值越大,顶越尖;值越小,分布越平缓正态分布的峰态系数一般是3,经常有算法将这个值直接减3再把正态分布的峰值系数定为0也是可以的。如果有个分布峰态系数<3或> 5,则此分布不是正态分布。
#峰度系数
df.kurt()
df["satisfaction_level"].kurt()
#-0.67比正态分布稍微平缓一些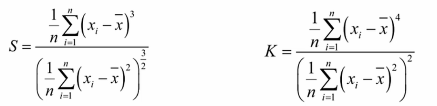
++正态分布(公式如下)与三大分布(卡方分布,T分布和F分布):其应用详见下节。
import scipy.stats as ss
ss.norm
# 我们看下norm的性质
# m:均值 v:方差 s:偏态系数 k:峰态系数
# 所以结果返回四个值
ss.norm.stats(moments="mvsk")
# 指定分布的横坐标,返回纵坐标的值
ss.norm.pdf(0.0)
#输入的值必须是0-1之间的,返回的是累积值
#返回的是从负无穷到1.28155156累计值是0.9,我们知道从负无穷到正无穷的积分是1
ss.norm.ppf(0.9)
#返回的是从负无穷一直累积到2的概率
ss.norm.cdf(2)
#正两倍的标准差减去负两倍的标准差的累积概率
ss.norm.cdf(2)-ss.norm.cdf(-2)
#产生正态分布的数量,指定size,就得到多少个符合正态分布的数
ss.norm.rvs(size=10)卡方分布(χ2分布):几个标准正态分布(均值为0,方差为1)的平方和满足于分布,这个分布就是卡方分布。
# 卡方分布
ss.chi2T分布:正态分布的一个随机变量除以一个服从卡方分布的变量,就是吨分布经常用来根据小样本来估计呈正态分布且方差未知的总体的均值。
# t分布
ss.tF分布:是由构成两个服从卡方分布的随机变量的比构成的。
# f分布
ss.f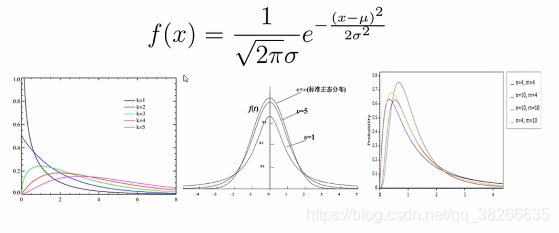
注:各种分布的操作同正态分布
(4)抽样理论
抽样分类:重复抽样与非重复抽样
抽样方式:完全随机抽样,等差距抽样,分类和分层抽样
# 抽10个样本
df.sample(n=10)
# 抽取指定百分比的样本
df.sample(frac=0.001)
# Series也可以抽样
df["satisfaction_level"].sample(n=10)++抽样误差(公式如下):

N——表示抽样的数量,N——总体的数量
当N = 1时,重复抽样与不重复抽样公式一样
当N = n时,没有误差,抽样可代表整体。
某些情况下,我们需要根据控制在误差水平之内确定抽样的数量,使用以下公式:

3. 数据分类
定类(类别):根据事务离散,无差别属性进行的分类例如:性别,民族
定序(顺序):可以界定数据的大小,但不能测定差值例:收入的低中高
定距(间隔):可以界定数据大小的同时,可测定差值,但无绝对零点(乘法,除法无意义)例如:摄氏度
定比(比率):可以界定数据大小,可测定差值,有绝对零点例如:身高,体重,长度,体积
4. 单属性分析
异常值分析:离散异常值,连续异常值,常识异常值。
#(sl是satisfaction_level的简称,后面的s代表它是个Series)
sl_s = df["satisfaction_level"]
#isnull()有True,说明有异常值
sl_s.isnull()
#查看异常值有几条
sl_s[sl_s.isnull()]
#查看这两条数据的完整情况
df[df["satisfaction_level"].isnull()]
#丢弃异常值(丢弃这两条数据)
sl_s = sl_s.dropna()
#填充异常值
#sl_s = sl_s.fillna()
#看有无其他异常值
#均值看起来没什么问题
sl_s.mean()
#标准差也没什么问题
sl_s.std()
#最大值
sl_s.max()
#最小值
#我们可以看到它就是个0-1的分布
sl_s.min()
#中位数
sl_s.median()
#下四分位数
sl_s.quantile(q=0.25)
#上四分位数
#0.82-0.44=0.38 向上向下都可以覆盖到它的最大值和最小值
sl_s.quantile(q=0.75)
#基本上可以断定无其他异常值
#偏度:负偏,均值偏小,大部分数比均值大
sl_s.skew()
#峰度:相对于正态分布较平缓
sl_s.kurt()++连续异常值(可以直接舍弃或取边界值代替异常值):
# last_evaluation差不多也在0-1之间
le_s = df["last_evaluation"]
q_low=le_s.quantile(q=0.25)
q_high=le_s.quantile(q=0.75)
q_interval=q_high-q_low
k=1.5
#用上下界进行筛选,可以同时筛选(去掉异常值的另一种方法)
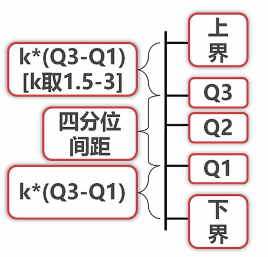
le_s=le_s[le_s<q_high+k*q_interval][le_s>q_low-k*q_interval]上下界之间的为正常值,其余为异常值。K = 1.5时,邻近边界算是中等异常; K = 3时,是非常异常。异常值的出现很有可能让大部分代表数据属性的值失去意义(如,人均收入又被超高收入平均了,这个时候均值不如中位数更有说服力)。
Q1——下四分位数;
Q2——中位数;
Q3——上四分位数;
四分位间距——Q1与Q3之间的间距;
上四分位数向上取ķ倍,K一般取1.5〜3,可以确定个上界;同理,得下界。
++离散异常值(直接舍弃,也可把所有异常值当成一个单独的值来处理(用个特殊标记标记,以区分其与正常值)):
离散属性定义范围外的所有值均为异常值(如:空值;收入离散化有中高低三类,其他值就为异常值)。
s_s=df["salary"]
#发现有异常值
s_s.value_counts()
# 去异常值:把异常值填成空,再dropna()
#高收入人群是少数,低收入人群是多数
s_s.where(s_s!='nme').dropna().value_counts()++知(常)识异常值:在限定知识与常识范围外的所有值均为异常值。(如:身高超过10米,就不符合常理)。
对比分析:绝对数与相对数,(怎么比)时间,空间,理论维度比较
# 1. 去掉异常值
#axis=0以行为单位删除,how="all"表示只有这一行全是空值才把它去掉,any是只有一个就删
df = df.dropna(axis=0,how="any")
df =df[df["last_evaluation"]<=1][df["salary"]!="nme"][df["department"]!="sale"]
# 2. 对比分析(以部门为单位进行)
# 1)直接进行对比分析
#同样部门的数据聚到一起,怎么处理呢?取均值,有些离散的非数字属性就直接去掉了
#我们可以看到HR的满意度是比较低的;
#上一次评价是旗鼓相当的,而management的上一次评价是比较高的;
#项目数量,HR最低,可能跟它的工作性质也有关系
#每月工作的平均时长(在公司的时间),management比较长,可能它的待遇也比较高
#事故,最大值是RandD,最小值是hr
#离职率,最大值是hr,最小值是managment
#最近五年是否被提升,最大值managment,最小值是product_mng=0
df.groupby("department").mean()
# 2)拉出几列进行分析
#切片:index全取,属性列取"last_evaluation","department"
#把这两列数据进行groupby
df.loc[:,["last_evaluation","department"]].groupby("department")
df.loc[:,["last_evaluation","department"]].groupby("department").mean()
# 3) 自定义函数进行对比
#看下"average_monthly_hours"的极差(最大值-最小值),我们用apply定义个匿名函数
#极差是比较平均的
df.loc[:,["average_monthly_hours","department"]].groupby("department")["average_monthly_hours"].apply(lambda x:x.max()-x.min())++绝对数比较:比较收入,身高,评分之类的
++相对数比较:
1)结构相对数:像用产品合格率来评价产品质量;或用考试通过率来评价学生的整体水平或考题难度之类的;
2)比例相对数:总体内用不同部分的数值进行比较比如说,传统意义上的,三大产业,农业,重工业和服务业的比例来相互比较,如哪个产业相对于哪个产业的比例发生什么样的变化。
3)比较相对数:同一时空下的,相似或同质的指标进行对比。如不同时期下的同一样商品的价格;不同互联网公司的待遇水平。
4)动态相对数:有时间的概念在里面。如:物理上的速度,用户数量的增速。
5)强度相对数:性质不同但又相互联系的属性进行联合如:人均(GDP),粮食亩产,密度。
++时间:现在跟过去比,过去跟未来比,由此未来推断走势。我们常会听到两个词——同比(和去年同期进行比较),环比(比上个月)。
++空间:可以指现实方位上的空间,如不同城市,国家,地区等;也可以指逻辑上的空间,如一家公司的不同部门或者不同公司间进行比较。
++经验与计划:经验的比较,如历史上失业率达到百分之几就很可能发生暴乱,各国之间失业率进行比较;计划的比较,我们做工作需要排期,一个实施进度需要和计划的排期进行比较。
结构分析(可看作对比分析中比例相对数的比较):各组成部分的分布与规律
++静态结构分析:直接分析系统的组成,如十一五期间三大产业的组成,第一产业13%,第二产业46%,第三产业41%,由此可确定我国的产业结构;同时,我们还可以把它跟美国,印度等国家进行比较,来衡量产业结构是否均衡,下一步该怎么决策等等。
++动态结构分析:以时间为轴,分析结构变化的趋势。我们知道十一五期间三大产业的占比,那么此期间三大产业是如何变化的,就能反应我们国家性质上的变化方向(第一产业大幅降低,第二产业小幅升高,而第三产业大幅升高,这就说明我们国家产业在转型)。
分布分析:数据分布频率的显式分析
++直接获得概率分布:得到的数进行排列或将各个离散值的数量数出来进行排列就可得到它的分布。(可能没什么意义,此时或进行比较或进行复合分析,得到的分布才会有意义。)
++判断一个分布是不是正态分布:
意义:如果一个分布为正态分布,那我们可轻易地用已有的性质 - 均值,方差等来快速定位某具体值相对于整体的位置如:如果得到一组数是正态分布的结论,我们分析其中一个具体的数比较接近均值减去一倍标准差的位置,那么我们基本就可以推断大概有84.5%的样本要比这个值大。那么,84.5%是怎么来到呢?像我们讲过,正态分布正负一倍标准差的值占全部值的69%,那么两个边缘以外的地方就各占到了15.5%,所以比这个值大的样本就占到了84.5%。
快速判断一个分布不是正态分布的方法:
1)如果一个分布偏态绝对值比较大,那就不是正态分布。这个值一般取到零点几,具体的值要依据数据质量和业务场景而定。
2)如果正态分布的峰态系数定为3,那么<1和> 5的肯定不是正态分布。同样,若正态分布峰值定为0,那么<-2和> 2的不是正态分布。
++极大似然(相似程度的衡量):可以表示一连串的数和分布到底有多像。给出一串数字,我们知道它是属于正态分布的,就一定可以确定一个均值,一个方差,使该均值和方差确定的正态分布下。这串数字的这几个点在这个确定的分布的取值就是他们的概率。这几个值的和或积,在刚刚确定的均值和方差下是最大的。那么对这几个和或积取对数,就叫极大似然。还是那串数,怎么判断它更接近正态分布,而不接近牛逼分布呢?可以对比它在不同分布下的极大似然。哪个极大似然越大,它就更接近哪个分布。当然最大的极大似然是我们直接获得的分布,但这个分布可能没有意义,和已有的分布建立联系,可能它的作用会更大。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









