










准备
- 虚拟机准备三台centos7的服务器。保证三台服务器之间网络互通。
- jdk1.8 安装完成,并在三台centos7的服务器配置好环境变量。
- hadoop-3.4.0安装包
集群搭建步骤
1. 环境准备
三台服务器IP
三台服务器IP如下
| IP地址 |
|---|
| 192.168.83.144 |
| 192.168.83.145 |
| 192.168.83.146 |
关闭三台服务器的防火墙
使用一下命令关闭三台服务器的防火墙。
# 关闭防火墙。暂时关闭。重启服务器后系统自动开启防火墙
systemctl stop firewalld
# 禁用防火墙,服务器重启后防火墙是关闭状态
systemctl disable firewalld
修改三台服务器的hostname文件
使用以下命令编辑hostName文件
vi /etc/hostname
三台服务器修改的名称如下表
| 服务器 | 修改后的hostname |
|---|---|
| 192.168.83.144 | hadoop1 |
| 192.168.83.145 | hadoop2 |
| 192.168.83.146 | hadoop3 |
修改三台服务器的hosts映射
使用以下命令编辑hosts文件
vi /etc/hosts
在三台服务器的hosts文件新增以下配置:
192.168.83.144 hadoop1
192.168.83.145 hadoop2
192.168.83.146 hadoop3
配置三台服务器之间的免密登录
在每个服务器中使用以下命令生成RSA公钥和私钥
ssh-keygen
回车三次之后得到密钥。密钥存放地址在:/root/.ssh 下
使用以下命令将密钥分发给其他服务器达到免密登录的效果.
注意,第一次分发密钥需要输入密码
# 将密钥分给hadoop1
ssh-copy-id hadoop1
# 将密钥分给hadoop2
ssh-copy-id hadoop2
# 将密钥分给hadoop3
ssh-copy-id hadoop3
当三台服务器都分发完密钥之后,服务器之间即可进行免密登录
三台时间同步设置
为了保证三台服务器的时间一致,三台服务器需要同步网络时间。使用以下命令同步时间
ntpdate pool.ntp.org
也可以使用同步时间脚本。详情参考:centerOs7安装相关的应用脚本
2. hadoop安装资源划分
hadoop集群中主要有NameNode、DataNode、SecondaryNode 进程。
NameNode和SecondaryNode不要放在同一个服务器上。
DataNode在每个服务器上
具体如下表:
| 服务器 | 安装资源 |
|---|---|
| 192.168.83.144 | NameNode、DataNode |
| 192.168.83.145 | SecondaryNode 、DataNode |
| 192.168.83.146 | DataNode |
3. 开始搭建hadoop集群
192.168.83.144 即 hadoop1上的修改
解压安装包
将hadoop-3.4.0安装压缩包上传到服务器的 /usr/local/ 下
使用以下命令解压hadoop-3.4.0安装压缩包
# 格式:tar -zxvf 压缩包路径 -C 解压到的目标路径
tar -zxvf /usr/local/hadoop-3.4.0.tar.gz -C /usr/local/
解压完成后在 /usr/local/ 下会有一个名为 hadoop-3.4.0 的文件夹,此文件夹为hadoop的安装路径。
hadoop-3.4.0 文件夹目录结构说明如下:
bin: 存放命令执行文件
etc:存放配置文件
include:存放工具脚本
lib:存放资源库
sbin:存放管理集群的命令
share:存放共享资源、开发工具、官方案例
...
添加环境变量
使用以下命令打开编辑环境变量文件
vim /etc/profile
在文件中加入以下内容:
export HADOOP_HOME=/usr/local/hadoop-3.4.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
注意:如果PATH的值中以 冒号: 分隔每个配置。hadoop的配置需要添加 bin 和 sbin 路径
修改完成后使用以下命令重新加载环境变量
source /etc/profile
验证hadoop环境配置
使用以下命令验证hadoop的环境配置是否可用
hadoop version
如果打印出hadoop的版本号,则说明配置环境成功。
修改hadoop配置
进入 /usr/local/hadoop-3.4.0/etc/ 下。对以下文件进行修改
core-site.xml
将原来core-site.xml中的configuration标签替换为以下内容
<configuration>
<!--
设置NameNode节点 ,此处按照《hadoop安装资源划分》部分配置设置hadoop1为NameNode节点
注意:
hadoop1.x时代默认端口9000
hadoop2.x时代默认端口8020
hadoop3.x时代默认端口 9820。此处的版本为3.4.0所以使用的是9820的默认端口
-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:9820</value>
</property>
<!--
hdfs的基础路径,此路径的tmp 文件夹不需要手动创建,Hadoop
会自动创建tmp文件夹
-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.3.1/tmp</value>
</property>
</configuration>
hdfs-site.xml
将原来hdfs-site.xml中的configuration标签替换为以下内容
<configuration>
<!-- hadoop块的副本数量,一般情况下建议等于集群机器节点数量。 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--
设置SecondaryNameNode 节点 .
此处按照《hadoop安装资源划分》部分配置设置hadoop2为SecondaryNameNode 节点
SecondaryNameNode http访问主机名和端口号。
-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop2:9868</value>
</property>
<!-- NameNode守护进程的http地址:主机名和端口号。-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop1:9870</value>
</property>
</configuration>
hadoop-env.sh
在 hadoop-env.sh 中加入以下配置
# 此处根据自己的jdk安装路径填写
export JAVA_HOME=/usr/local/jdk8
# Hadoop3中,需要添加如下配置,设置启动集群角色的用户
# NameNode 的启动用户
export HDFS_NAMENODE_USER=root
# DataNode 的启动用户
export HDFS_DATANODE_USER=root
# SecondaryNameNode 的启动用户
export HDFS_SECONDARYNAMENODE_USER=root
works
配置服务器节点.在works下加入以下配置。
hadoop1
hadoop2
hadoop3
到此hadoop1 的配置完成
192.168.83.145 和192.168.83.146 即hadoop2和hadoop3的配置
拷贝安装
由于hadoop2和hadoop3的配置也需要和hadoop1的配置一致,所以只需要将hadoop1中的/usr/local/hadoop3.4.0文件夹拷贝一份到hadoop2和hadoop3机器中即可。
在hadoop1服务器中使用以下命令将hadoop1中已经配置好的hadoop发送到hadoop2和hadoop3.
# 拷贝到hadoop2服务器的/usr/local/下
scp -r /usr/local/hadoop3.4.0 hadoop2:/usr/local/
# 拷贝到hadoop3服务器的/usr/local/下
scp -r /usr/local/hadoop3.4.0 hadoop3:/usr/local/
环境变量配置
hadoop2和hadoop3两台服务器的环境变量配置也要和hadoop1中的配置一致。参考上面的《 添加环境变量》步骤。
当然也可以使用拷贝的方式将hadoop1中已经配置好的环境变量文件拷贝到hadoop2和hadoop3。
最后都需要使用命令source /etc/profile重新加载环境变量配置
格式化集群
使用以下命令格式化集群。初始化一个新的hadoop集群环境
在hadoop1中使用以下命令格式化一个新的hadoop集群环境
hdfs namenode -format
执行成功之后,在hadoop1的安装路径 /usr/local/hadoop3.4.0/ 下会出现 tmp 文件夹,说明格式化成功。
注意,此时hadoop2和hadoop3还未生成tmp ,hadoop2和hadoop3需要集群启动之后才会自动生成此文件夹。
启动集群
在hadoop1中使用以下命令启动hadoop集群.
start-dfs.sh
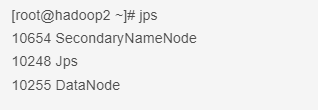
启动完成之后hadoop1、hadoop2、hadoop3 中都会生成对应的tmp文件夹 。且分别在hadoop1、hadoop2、hadoop3 中使用 jps 命令都能查询到hadoop的进程信息。
如下三个图:


其他启动停止的操作命令
# 启动HDFS所有进程(NameNode、SecondaryNameNode、DataNode)
start-dfs.sh
# 停止HDFS所有进程(NameNode、SecondaryNameNode、DataNode)
stop-dfs.sh
# hdfs --daemon start 单独启动一个进程
# 只开启NameNode
hdfs --daemon start NameNode
# 只开启SecondaryNameNode
hdfs --daemon start SecondaryNameNode
# 只开启DataNode
hdfs --daemon start DataNode
# hdfs --daemon stop 单独停止一个进程
# 只停止NameNode
hdfs --daemon stop NameNode
# 只停止SecondaryNameNode
hdfs --daemon stop SecondaryNameNode
# 只停止DataNode
hdfs --daemon stop DataNode
# hdfs --workers --daemon start 启动所有的指定进程
# 开启所有节点上的DataNode
hdfs --workers --daemon start DataNode
# hdfs --workers --daemon stop 启动所有的指定进程
# 停止所有节点上的DataNode
hdfs --workers --daemon stop DataNode
4. 物理机浏览器访问hadoop系统界面
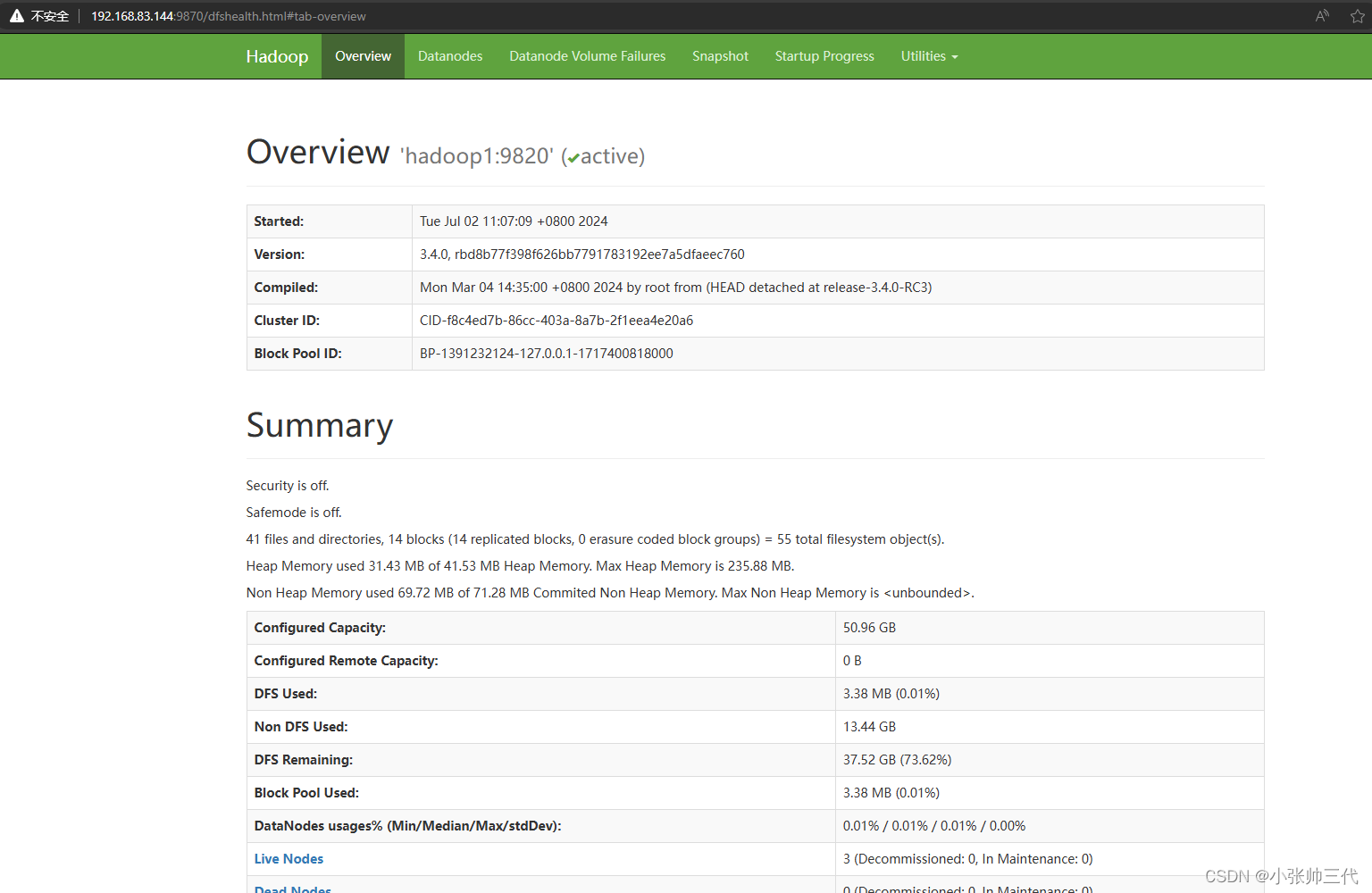
集群启动完成之后,在物理机的浏览器上访问以下地址:
http://192.168.83.144:9870
即可看到下图界面。
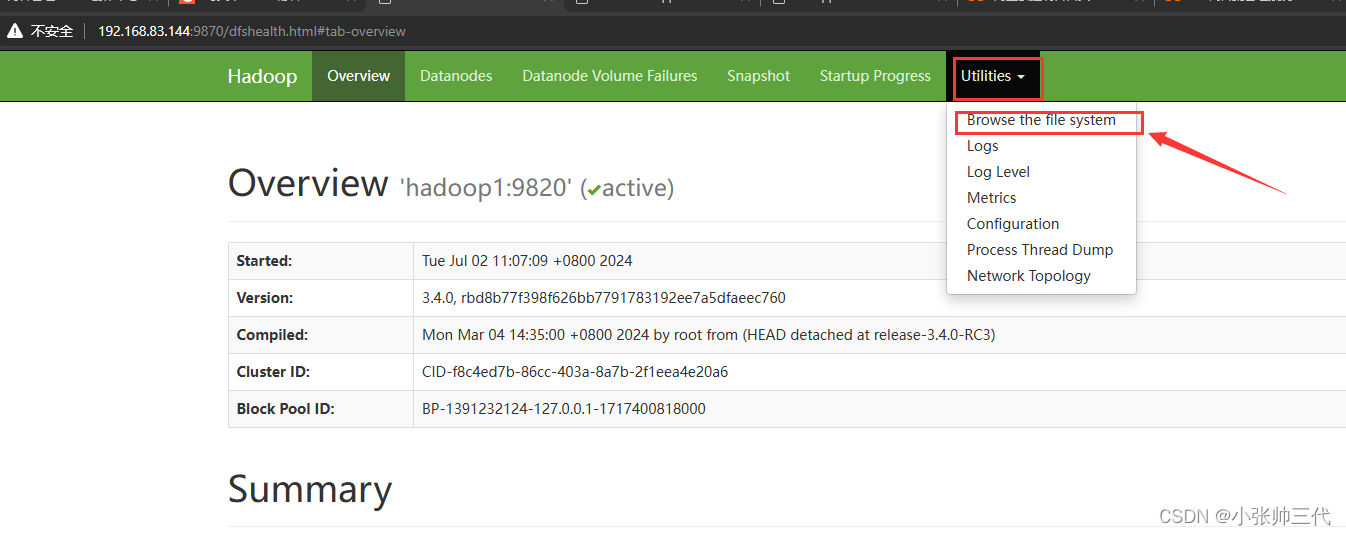
访问分布式文件系统
在界面导航栏中点击 Utilities –Browse the file system
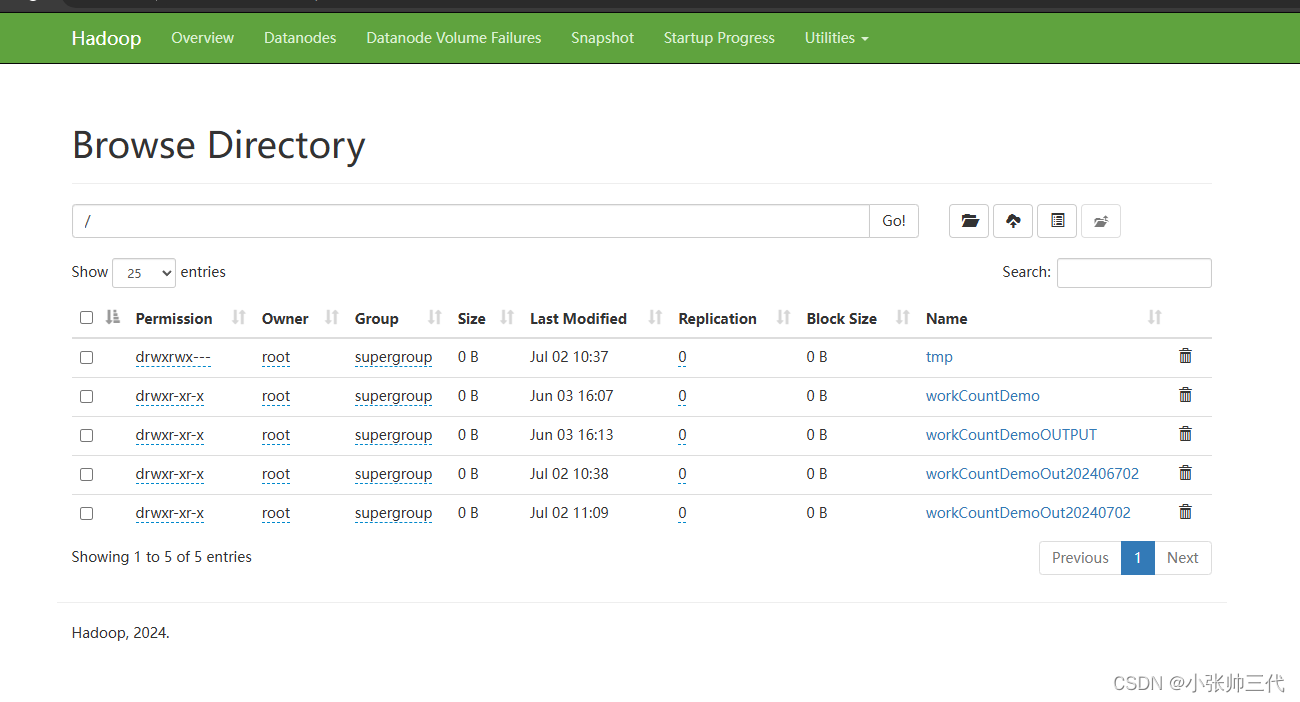
即可进入文件系统
5. yarn 配置
yarn是hadoop的组件,不需要单独安装。修改配置即可使用
修改mapred-site.xml
编辑mapred-site.xml 在configuration 标签中添加以下配置
<!-- 指定MapReduce作业执行时,使用YARN进行资源调度 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- /usr/local/hadoop-3.4.0 为hadoop的安装路径 -->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.4.0</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.4.0</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop-3.4.0</value>
</property>
修改yarn-site.xml
编辑yarn-site.xml 在configuration 标签中添加以下配置
<!-- 设置ResourceManager
hadoop1 为ResourceManager所在的机器
-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
<!--配置yarn的shuffle服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
修改hadoop-env.sh
编辑hadoop-env.sh 在末尾添加以下配置
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
分发配置
将本机器的配置发送给其他节点的机器。使用scp命令分发整个配置文件夹即可。例如
将本机器的 /usr/local/hadoop-3.4.0/etc/ 下的 hadoop 文件夹分发给hadoop2 机器的 /usr/local/hadoop-3.4.0/etc 目录下。
scp -r /usr/local/hadoop-3.4.0/etc/hadoop root@hadoop2:/usr/local/hadoop-3.4.0/etc
同理,从hadoop1分发给hadoop3
scp -r /usr/local/hadoop-3.4.0/etc/hadoop root@hadoop3:/usr/local/hadoop-3.4.0/etc
启动和停止yarm
使用以下命令启动和停止yarn
启动
start-yarn.sh
停止
stop-yarn.sh
hadoop 操作脚本
创建hadoopUtil.sh 方便操作hadoop
#!/bin/bash
echo "hadoop的操作脚本"
echo "1. 启动所有进程(NameNode、SecondaryNameNode、DataNode、Yarn、mr-historyserver、timelineserver)"
echo "2. 停止所有进程(NameNode、SecondaryNameNode、DataNode、Yarn、mr-historyserver、timelineserver)"
echo "3. 查看集群所有节点的进程"
read -ep "请选择操作:" idx
if [ -z ${idx} ];then
echo "未选择。退出"
exit 1001
fi
if [ "1" == ${idx} ];then
echo "启动HDFS所有进程(NameNode、SecondaryNameNode、DataNode、Yarn、mr-historyserver、timelineserver)"
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver
yarn --daemon start timelineserver
elif [ "2" == ${idx} ];then
echo "停止HDFS所有进程(NameNode、SecondaryNameNode、DataNode、Yarn、mr-historyserver、timelineserver)"
stop-dfs.sh
stop-yarn.sh
mapred --daemon start historyserver
yarn --daemon stop timelineserver
elif [ "3" == ${idx} ];then
HOSTS=( hadoop1 hadoop2 hadoop3 )
for HOST in ${HOSTS[@]}
do
ssh -T $HOST << TERMINATER
echo "---------- $HOST ----------"
jps | grep -iv jps
exit
TERMINATER
done
fi



















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











