







起因
三点原因吧:
- 平时打开手机最常做的就是看新闻!!(第二微信)
- 而且大部分的媒体都在“今日头条化”(本人拙见),各类戏子新闻满天飞,实在是污染眼球
- 既然是计算机专业的学生那就自己动手搞一个吧!
项目的总体思路
首先你需要有这些新闻数据,而且每天都会更新。所以需要一个可维护的可扩展的获取数据的程序
我选择了Python作为开发语言,scrapy作为数据源,web框架待定。Django就算了(Django就有点杀鸡用牛刀了,而且我不喜欢Django,封装的太过分了),flask或者web.py任选之一。
通过Scrapy抓取数据,清洗之后存放到MySQL数据库,在网站端展示出来,并且给每条新闻一个评分功能,让用户为他看到的新闻打分,通过交替最小二乘法对用户进行推荐,这里我还要使用spark进行计算,大致思路就是这样的。
今天记录的第一部分就是关于搭建Scrapy
Scrapy是Python里很流行的一个爬虫框架,不再说废话了,开始做了!
- 先安装scrapy(没装Python和pip的就别往下看了),cmd输入 pip install scrapy
- 选择你的项目目录,进去:shift+鼠标右键---->在此处打开命令窗口 输入:scrapy startproject Hunter
- 准备工作都OK了,在你的IDE里导入项目开始编程吧,我用的Pycharm,你可以随便选一个你喜欢的
- 项目目录的截图是这样的(这里面我做了改动了,初始的目录你可以在你的本地看到)
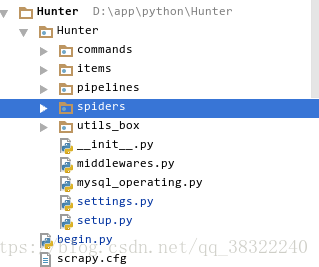
items文件夹里是item文件,它定义了你需要抓取得字段,每个item是一个字典类型,后续我会写到
pipelines里的文件对你获取的item数据进行操作,你可以清洗、筛选、过滤、存储它们
spiders里的文件是你的页面解析文件
settings文件显然是一个配置文件
utils_box文件夹,这里我存放一些工具,后面会涉及(你也可以不写)
begin.py文件是一个项目开始的执行文件
主要的我都介绍了,其余的涉及会谈到,scrapy的大致简化流程就是:1、在item里定义你要获取的信息 2、在spider里去解 析网页获得item里的对应信息,传递给item对象并且yield抛出 3、pipeline会接到你抛出的item对象,对它进行处理
- 看一下item(只截图了,代码会放在GitHub上)

先写一个简化版的,暂时只需要这些字段信息
- 我们的spider(这里抓取日本共同社新闻网为例,https://china.kyodonews.net/ 这家媒体的报道具有一定的参考性,而且网站页面结构很稳定,很少改动,get请求就可以获取HTML)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2060
2060











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









