







一.神经网络的概述:
神经网络(Neural Network)是一种计算模型,它受到人脑神经元的结构和功能的启发而设计出来的。它可以用于解决各种复杂的问题,例如图像识别、自然语言处理、声音识别等。在神经网络中,大量的人工神经元通过加权连接构成了一个复杂的网络,该网络可以通过大量的训练数据来学习和适应各种复杂的输入输出关系,从而实现人工智能的目标。由于神经网络的强大表征能力和适应性,它被广泛应用于各种领域,包括计算机视觉、自然语言处理、机器人学、控制等。
二.BP神经网络的概述:
BP(Back Propagation)网络是一种按误差逆传播算法训练的多层前馈网络,是应用最广泛的神经网络模型之一。它的基本思想是输入层接收输入特征向量,通过激活函数将其转换为权重向量,输入到隐藏层进行处理,然后通过激活函数将处理后的权重向量传递到输出层,最终输出预测结果。BP神经网络的训练过程包括数据预处理、网络结构设计、模型训练、模型评估和模型优化等步骤。在训练过程中,通常使用梯度下降等优化算法来更新模型参数。BP神经网络具有良好的泛化能力和鲁棒性,已经被广泛应用于各种领域,例如自然语言处理、机器学习、图像处理等。三.BP神经网络的应用:
1)函数逼近:用输入向量和相应的输出向量训练一个网络逼近一个函数。
2)模式识别:用一个待定的输出向量将它与输入向量联系起来。
3)分类:把输入向量所定义的合适方式进行分类。
四.BP神经网络的原理:
要想明白BP的原理要先了解正向传播的原理和几个名词。
(一)基本名词:
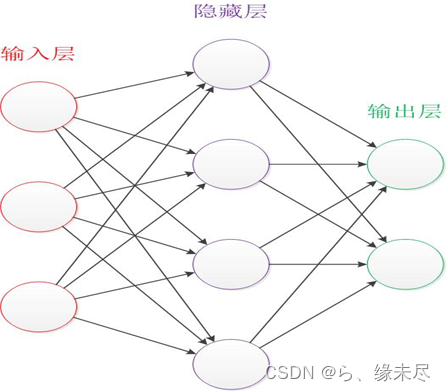
输入层(input layer):常是指非线性可分的特征图的最前面的一层,它接收大量的非线性输入信号,并将它们转换为线性形式,以便于后续的处理。输入层的神经元数量通常很多,因为它需要接收尽可能多的输入信号,以便于后续的处理和分析。输入层的输入向量通常是大量的非线性特征值,它们需要经过一系列的处理,例如非线性变换、平移、缩放等,才能转换为线性形式。
隐藏层(hidden layer):隐藏层不直接接受外界的信号,也不直接向外界发送信号。隐藏层在神经网络中的作用是将输入数据的特征,抽象到另一个维度空间,来展现其更抽象化的特征,这些特征能更好的进行线性划分。输出层将隐藏层激活转换为您希望输出所在的任何比例。
输出层(output layer):神经网络的输出层是指最后一层,它将隐藏层的激活值作为输出信号,输出到外部世界。输出层的神经元数量和激活函数的数量可以根据具体问题和任务而定,通常情况下,输出层的神经元数量要少于隐藏层的神经元数量,而激活函数的数量要多于隐藏层的激活函数数量。
激活函数(active function):激活函数是一类非线性函数,它将非线性特性引入到人工神经网络中,其主要作用是使用非线性的方法将神经网络模型中一个节点的输入信号转换成一个非线性输出信号,从而增强神经网络对非线性函数的拟合能力。常见的激活函数有sigmoid、tanh、relu、prelu、softmax。
其中介绍几个常用的激活函数
SIGMOID:
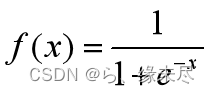
其图像为
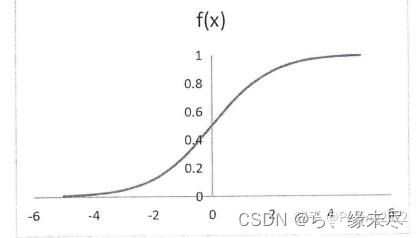
取值范围在0到1之间
TANH:
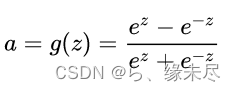
其图像为
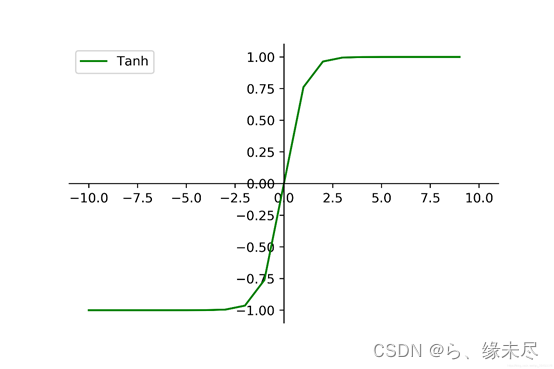
取值范围为-1到1之间相比较于sigmoid范围更大,适配更强
RELU
图像为
取值范围为0到1但其相对于sigmoid函数来说,它取负值时输出0,正值时输出为1,用于梯度下降时更快
权重:在神经网络中,输入信号通常是非线性的,因此需要使用权重来将其转换为线性形式,以便于后续的处理。假设输入为a,且与其相关联的权重为W,那么在通过结点之后,输入变为a*W。
偏置:偏置则控制激活函数的输出范围,从而控制神经元的输出。在神经网络中,偏置的应用非常广泛,它可以用于控制权重的大小,从而控制神经网络的输出;也可以用于控制神经元的激活概率,从而控制神经网络的权重更新速率。与权重共同形成了wx+b这样的线性形式
(二)正向传播
正向传播从前到后的原则,如下图:
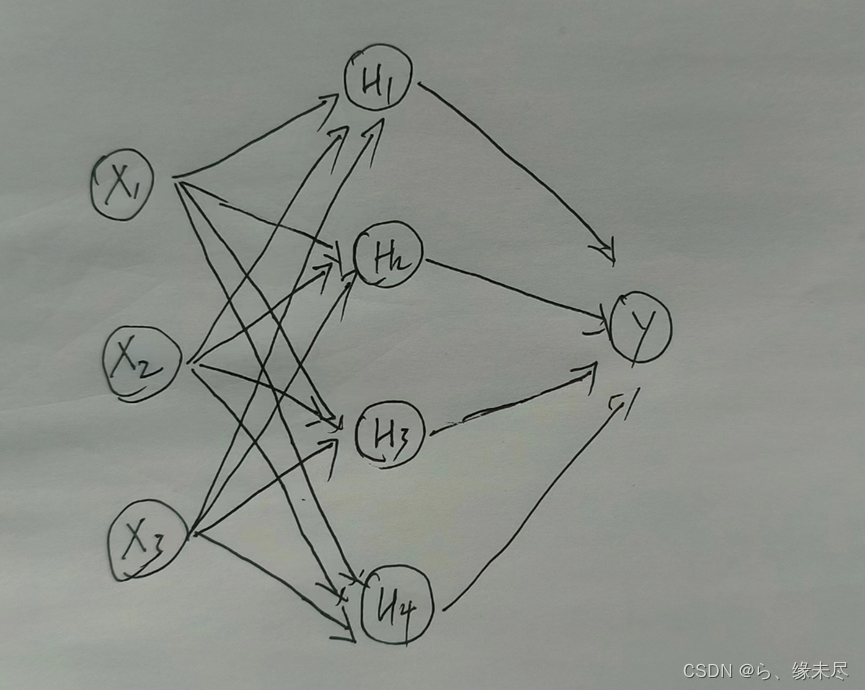
本图中展示的就是一个很基本的神经网络结构,从前到后正向传播就是依次经过每一层的计算最终从输出层输出
正向传播的步骤:
1.将上一层的输出乘以权重矩阵,并加上该层的偏置向量。
2.将得到的结果作为该层的输入,使用激活函数对其进行非线性转换,得到该层的输出。
3.将该层的输出作为下一层的输入,重复1和2步骤。
就其中一个实例拉出来就是如下
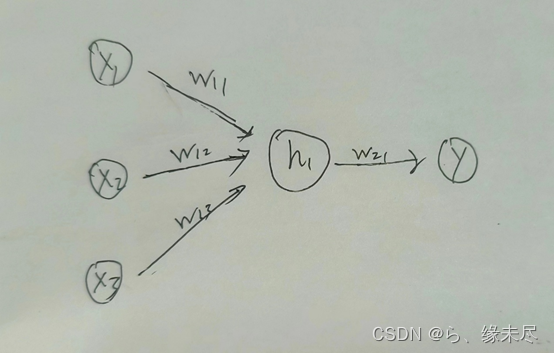
权重代表的就是连接每层节点的线
先不考虑矩阵就单个数据,如图x1,x2,x3通过连线上的权重后变成了h1的输入方程
Z1=x1*w11+x2*w12+x3*w13+b1
通过h1里的激活函数转化变成了
A=sigmoid(z)
再通过连线上的权重到输出层时变成了
Z2=A*w21*+b2
最后的输出就结果就是
Y_hat=sigmoid(z2)
因此以上四步就是正向传播的过程
Z1=x1*w11+x2*w12+x3*w13+b1
A=sigmoid(z)
Z2=A*w21*+b2
Y_hat=sigmoid(z2)
但以为数据都是很多的很次单独计算的时间复杂度和空间复杂度会很高,因此引入了向量化,和矩阵,利用矩阵运算会大幅度提高运算效率
(3)反向传播
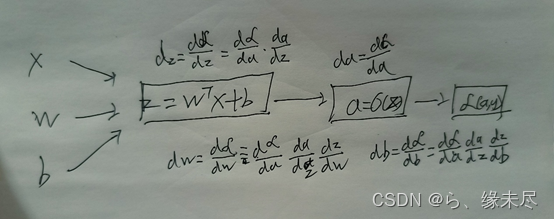 理解完了正向传播那么反向传播就可以理解为反过计算
理解完了正向传播那么反向传播就可以理解为反过计算
如图,x,w.b表示矩阵参数,由输入层到隐藏层形成了z=wtx+b的形式,其中的wt表示的转置,然后得到输出层的a
这时就可以说明反向传播的作用,因为神经网络不可能一开始就能得到你想要的结果,因此就需要训练它,而训练它的方式就是改变权重和偏置,首先就是要知道预测值和真实值相差的程度,这时就可以用损失函数来表示,根据损失函数反向求导偏函数,然后计算梯度通过梯度下降算法来实现对权重和偏置的更新。
所以首要就是先求出各个参数的导数,利用求导的链式法则即可

通过以上步骤即可得到da,dz,dw,db再通过梯度下降算法即可更新参数实现反向传播和训练
w2 =w2- learning_rate * dw2
w1 =w1- learning_rate * dw1
b2 =b2- learning_rate * db2
b1 =b1- learning_rate * db1
实战python的代码实现:
import numpy as np
# 定义sigmoid激活函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))#np.exp()函数是求e^{x}的值
# 定义反向传播算法
def backpropagation(X, y, w1, w2, b1, b2, learning_rate):
# 先正向传播计算输出值
z1 = np.dot(X, w1) + b1
a1 = sigmoid(z1)
z2 = np.dot(a1, w2) + b2
y_hat = sigmoid(z2)
# 计算误差和误差梯度
error = y_hat - y
dz2 = y_hat - y
dw2 = 1 / len(y) * np.dot(a1.T, dz2)
db2 = 1 / len(y) * np.sum(dz2, axis=0, keepdims=True)
dz1 = np.dot(dz2, w2.T) * sigmoid(z1) * (1 - sigmoid(z1))
dw1 = np.dot(X.T, dz1)
db1 = np.mean(dz1, axis=0)
# 更新权重和偏置
w2 -= learning_rate * dw2
w1 -= learning_rate * dw1
b2 -= learning_rate * db2
b1 -= learning_rate * db1
return w1, w2, b1, b2,error
# 定义训练函数
def train(X, y, hidden_units, epochs, learning_rate):
# 初始化权重和偏置
input_units = X.shape[1]#shape[0]读取矩阵第一维度的长度,即行数;使用shape[1]读取矩阵第二维度的长度,即列数
output_units = 1
w1 = np.random.randn(input_units, hidden_units)#生成3行4列的矩阵
w2 = np.random.randn(hidden_units, output_units)
b1 = np.zeros((1, hidden_units))#生成的结果全是零
b2 = np.zeros((1, output_units))
# 迭代训练
for i in range(epochs):
w1, w2, b1, b2, error = backpropagation(X, y, w1, w2, b1, b2, learning_rate)
if i % 1000 == 0:
print(f"Epoch {i}: error = {np.mean(np.abs(error)):.4f}")#mean()函数功能:求取均值 np.abs求绝对值
return w1, w2, b1, b2
# 测试
X = np.array([[0, 0, 1], [0, 1, 1], [1, 0, 1], [1, 1, 1]])
y = np.array([[0], [0.25], [0.75], [1]])
hidden_units = 4
epochs = 10000
learning_rate = 0.1
w1, w2, b1, b2 = train(X, y, hidden_units, epochs, learning_rate)
# 预测结果
z1 = np.dot(X, w1) + b1
a1 = sigmoid(z1)
z2 = np.dot(a1, w2) + b2
y_hat = sigmoid(z2)
print(y_hat)输出结果如下:
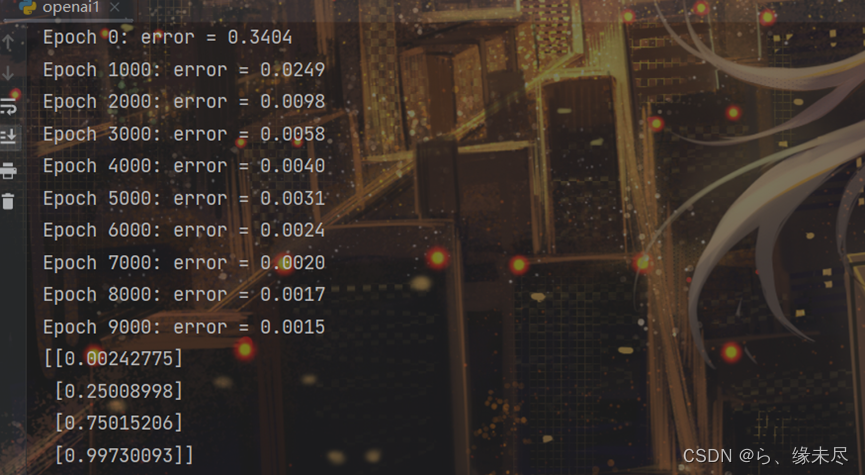
预测值与真实值[[0],[0.25],[0.75],[1]]基本拟合,训练成功!















 1930
1930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









