







发表会议:ICLR 2024
论文标题:Mol-Instructions: A Large-Scale Biomolecular Instruction Dataset for Large Language Models
论文链接:https://arxiv.org/pdf/2306.08018.pdf
代码链接:https://github.com/zjunlp/Mol-Instructions
引言
在自然语言处理(NLP)的众多应用场景中,大型语言模型(Large Language Model, LLM)展现了其卓越的文本理解与生成能力,不仅在传统的文本任务上成绩斐然,更在生物学、计算化学、药物研发等跨学科领域证明了其广泛的应用潜力。尽管如此,生物分子研究领域的特殊性—比如专用数据集的缺乏、数据标注的高复杂度、知识的多元化以及表示方式的不统一—仍旧是当前面临的关键挑战。针对这些问题,本文提出Mol-Instructions,这是一个针对生物分子领域各项研究任务定制的指令数据集。
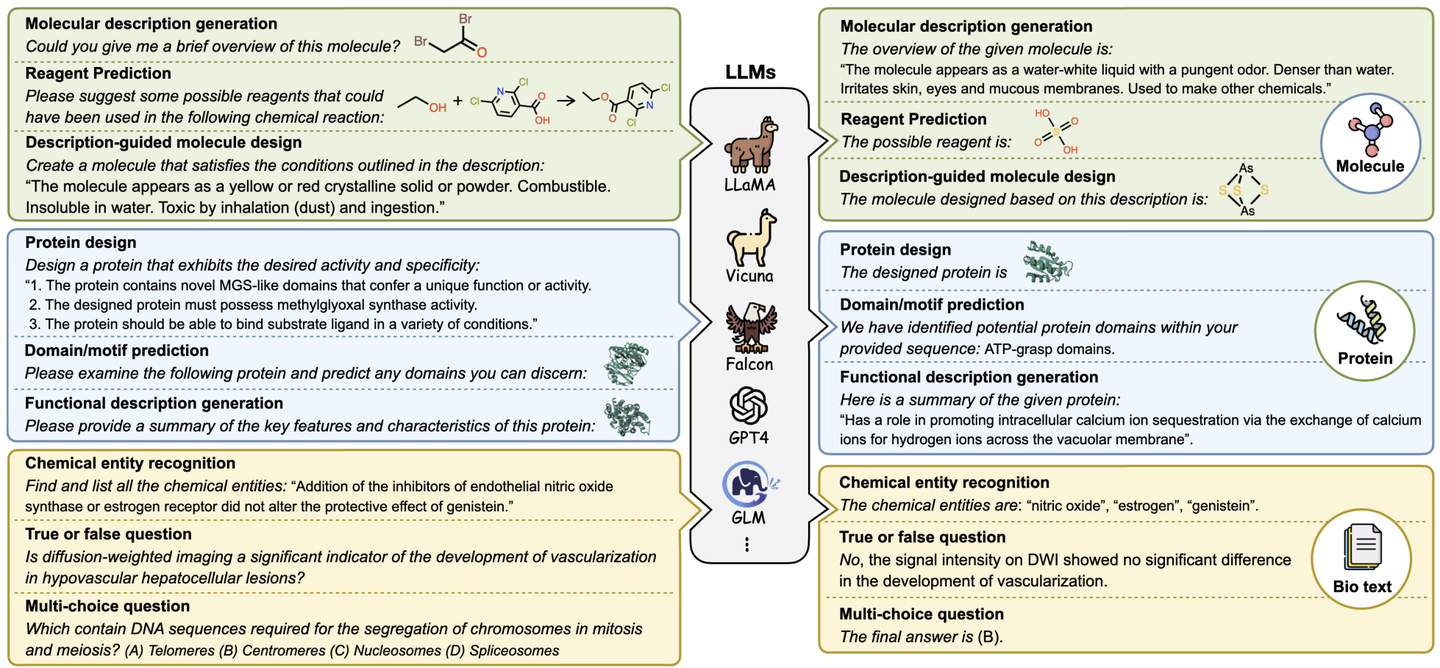
构建 Mol-Instructions
Mol-Instructions的构建流程如下:
-
借助LLM的能力,生成多样化的任务描述,模拟人类需求和表达的多样性。
-
采用多种预处理策略,将现有数据库中的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









