







Android多线程、线程池原理与AsyncTask
CPU、进程、线程
1.CPU核心数和线程数的关系
购买笔记本电脑,经常会听到四核八核的概念,就是指CPU核心数,一般来说CPU核心数和进程是1:1的关系,但是Intel 引入了超线程技术,实现了1:2的关系,4核8进程等等。
2.CPU时间片轮转机制
时间片轮转调度是一种最古老、最简单、最公平且使用最广的算法,又称RR调度。每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间。
举个例子来说,现在同时有100个线程需要运行,每个线程需要5ms(也就是一个时间片),那么需要的最多时间也就是500ms,在我们肉眼根本看出来卡顿,CPU运行时有时候突然会飙到90%,可能就是在运行一个消耗资源比较多的线程,从一个线程切换到另一个线程,也需要消耗很多资源,需要保存停止线程的信息,启动线程如果运行过也需要去读取它对应的信息。时间片轮转机制大约有20%的浪费在了管理开销上。
3.进程和线程
进程:程序运行资源分配最小单位。比如:打开一个word文档,就是一个进程,操作系统要为它分配资源。
线程:线程是CPU调度的最小单位,必须依赖于进程存在。举个例子,每当我们启动一个app就会有UI线程,work线程,UI线程渲染界面,work线程就去处理一些事件等。
并行和并发
举个例子来说,一条高速公路,有四个车道,车辆并排行驶最多就能是四辆,那么最大并行就是四辆车;CPU就相当于是这条高速公路,而核心数就相当于车道;当谈论并发,肯定是有时间单位的,也就是说单位时间内并发量是多少多少。这条公路一小时通过的车辆是1000辆,那么并发量就是 1000辆/小时。
Android 启动线程
1.Thread
Thread是我们经常使用的一种开启线程的方式,定义一个类继承自Thread,重写run方法,在run方法里处理你的事件
class MyThread extends Thread{
@Override
public void run() {
super.run();
Log.e("I am Thread","——————————");
}
}
MyThread myThread = new MyThread();
myThread.start();
2.Runnable
Runnable和Thread同样也是我们经常使用的方式,但是它相对于Thread来说,Runnable抽象的是任务,而Thread抽象的是线程。
我们看Thread类的源码会发现它的构造方法中有对于的Runnable参数

使用Runable时,直接在Thread构造方法中传入即可
new Thread(new Runnable() {
@Override
public void run() {
Log.e("I am Runnable","——————————");
}
}).start();
3.Callable
Runnable和Thread 都是实现了run方法,仔细观察会发现run方法都是void无返回值类型,这样一来就无法获取线程的回调。Callable就是解决这个问题的,它和Runnable一样都是抽象任务的。
观察Callable的源码发现它是一个泛型类,唯一的接口方法call返回的就是我们传入的泛型

但是,Thread类的构造方法中并没有Callable对应的构造器。此时,我们就需要用到FutureTask,观察FutureTask的源码,它实现了RunnableFuture

我们点进去RunnableFuture,会发现它继承与Runnable

由此我们得知,Callable不能直接传入Thread,需要复制给FutureTask,把FutureTask传入Thread即可
FutureTask<String> futureTask = new FutureTask<>(new Callable<String>() {
@Override
public String call() throws Exception {
Log.e("I am Callable","——————————");
return "Callable onSuccess";
}
});
new Thread(futureTask).start();
//FutureTask提供了get()方法获取回调
Log.e("Callable回调",futureTask.get());
run() 和 start()的区别
如果调用线程的run()方法,那和调用一个普通类的普通方法是没有任何区别的;调用start()方法,才是真正启动了一个线程去执行run()方法里的代码,而且start方法一个线程只能调用一次,多次调用会报异常。
Android 关闭线程
关闭线程的方法
有始有终,既然可以启动线程,那么肯定会有关闭线程的方法,我们点进Thread的源码看它的方法可以看到和start相对的方法stop

不过它的方法上面已经标记了废弃的注解
这是因为,stop方法是抢占式的,如果一个线程正在写入一个10kb的文件,我在中途调用了stop方法,那很有可能写到5kb直接停止了,很有可能就损坏文件了。
JDK给我们提供了新的并且相对安全的方法来结束线程

interrupt() 用来停止线程,和stop不同的是它并不是抢占式的,而是协作式的,就好比其他线程告诉正在执行的线程,你需要中断了,而正在执行的线程完全可以不理会这一消息,这就会出现一种情况,我调用了interrupt() 但是线程仍然在继续执行。
isInterrupted() 用来判断线程是否被中断,会返回中断标识位的布尔值
interrupted() 同样是用来判断线程是否被中断,但是会将中断标识位改为false
Runnable关闭线程
用Thread启动的线程,可以直接调用interrupt()方法去关闭线程,那么Runnable呢?它实现的接口里只有一个run()方法,该怎么停止线程呢?
Thread.currentThread().interrupt();
join() 和 yield()
这里扩展一下Thread的join() 和 yield()方法
join() join的意思就是加入,我们可以理解这个方法就是插队的意思,比如:A线程正在执行,需要10ms执行完毕,当他执行到8ms的时候,B线程调用了join(),那么A线程就会暂停来运行B线程,当B线程结束运行之后,A线程把剩下的2ms任务完成。更多的join()方法是用在合并线程让线程顺序执行,在B线程中调用了A的join()方法,则会按顺序先执行A后执行B。
yield() 使当前线程让出CPU占有权,但让出的时间不可设定,也不会释放锁资源,所有执行yield的线程也可能在进入可执行状态后马上又被执行。
线程间的共享和协作
synchronized内置锁
当多个线程同时对一个同一个变量进行修改,比如 i = 0,多个线程对他进行 +1 的操作就很有可能出现问题,结果具有不确定性,针对这个问题,JDK提供了synchronized关键字来解决这个问题。
下面有一个Counter 类,里面有一个为0的变量count ,还有一个add()的方法,调用时会对count 加 1 ;
public class Counter {
int count = 0;
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public void add(){
count ++ ;
}
}
我在主线程中启动两个线程,分别执行add() 10000次,理想的结果肯定是20000。但是实际运行每次结果却都不同,偶尔才会得出20000的结果
class MyThread extends Thread{
Counter counter;
public MyThread(Counter counter){
super();
this.counter = counter;
}
@Override
public void run() {
super.run();
for (int i=0; i< 10000; i++){
counter.add();
}
}
}
Counter counter = new Counter();
MyThread myThread1 = new MyThread(counter);
MyThread myThread2 = new MyThread(counter);
myThread1.start();
myThread2.start();
Thread.sleep(500);
Log.e("计算之后的结果:", ""+ counter.getCount());
输出结果:

如果不加锁的情况下,运行多次,就会出现结果随机的情况;
现在,我们给add()方法加上synchronized锁,一次只能一个线程去调用这个方法
修改add方法为
public synchronized void add(){
count ++ ;
}
再次执行代码后,结果正确了:

synchronized 关键字,本质上锁的都是对象,它的使用方法有以下几种:
1.锁当前类的方法,把方法当成一个对象去锁 三种写法都相同
public synchronized void add(){
count ++ ;
}
public void add(){
synchronized (this){
count ++ ;
}
}
public void add(){
synchronized (object){
count ++ ;
}
}
2.静态对象、静态方法锁
如果在静态对象,静态方法中加synchronized 关键字,因为static 修饰的方法、类在虚拟机中只存在一个,所以本质上锁的是static 类对应的class对象
public static synchronized void setCount(int count) {
//do somethings
}
进程间的协作 wait() notify/notifyAll()
进程之间相互协作经常会遇到,当某个线程需要具备某个条件才能继续运行时,就可以调用wait()等待,当符合条件时,可以调用notify/notifyAll()去通知唤醒线程。notify只能通知一个线程,notifyAll可以通知所有的线程。
wait和notify/notifyAll 标准范式:
wait:
1)获取对象的锁。
2)如果条件不满足,那么调用对象的wait()方法,被通知后仍要检查条件。
3)条件满足则执行对应的逻辑。
notify/notifyAll:
1)获得对象的锁。
2)改变条件。
3)通知所有等待在对象上的线程。
想象以下场景,有一个快递Package,当他发出100公里以上时我们就视为快递达,或者当它到达地为北京时,视为送达
Package类
public class Package {
public String city = "";
public int km = 0;
public synchronized void changeKm(){
this.km = 101;
notifyAll();
}
public synchronized void changeCity(){
this.city = "北京";
notifyAll();
}
public synchronized void waitKm(){
while (this.km < 100){
try {
Log.e("km < 100","线程"+Thread.currentThread().getName()+"等待,快递运送中");
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
Log.e("km > 100","线程"+Thread.currentThread().getName()+"结束,快递送达");
}
public synchronized void waitCity(){
while (!this.city.equals("北京")){
try {
Log.e("city is not beijing","线程"+Thread.currentThread().getName()+"等待,快递运送中");
wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
Log.e("city is == beijing","线程"+Thread.currentThread().getName()+"结束,快递送达");
}
}
现在我们分别定义两个线程,一个监听公里数,一个监听目的地
final Package p = new Package();
class MyThread1 extends Thread{
public MyThread1(String name){
super(name);
}
@Override
public void run() {
super.run();
p.waitKm();
}
}
class MyThread2 extends Thread{
public MyThread2(String name){
super(name);
}
@Override
public void run() {
super.run();
p.waitCity();
}
}
MyThread1 myThread1 = new MyThread1("1");
myThread1.start();
MyThread2 myThread2 = new MyThread2("2");
myThread2.start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//模拟快递已经送达
p.changeKm();
p.changeCity();
输出结果:

仔细观察代码会发现一个问题,两个线程run()中调用的方法都是已经上锁synchronized的方法,那么notify/notifyAll 为什么还可以调用?这是因为wait()中具有释放锁的逻辑,调用wait()后就会释放锁;notify/notifyAll 并没有释放锁的逻辑,而是在执行完所有通知的逻辑之后才会释放锁。
ThreadLocal 线程变量
ThreadLocal,即线程变量,是一个以ThreadLocal对象为键、任意对象为值的存储结构。这个结构被附带在线程上,也就是线程之间是隔离的独立的。
使用方法:
final ThreadLocal<Integer> threadLocal = new ThreadLocal<Integer>(){
@Nullable
@Override
protected Integer initialValue() {
return 1;
}
};
class MyThread extends Thread{
@Override
public void run() {
super.run();
for (int i=0; i< 10000; i++){
threadLocal.set(threadLocal.get()+1);
}
Log.e("线程"+Thread.currentThread().getName()+"结果:", ""+ threadLocal.get());
}
}
MyThread thread1 = new MyThread();
MyThread thread2 = new MyThread();
thread1.start();
thread2.start();
输出结果:

可以看出两个线程里的结果互相不影响
Lock接口
synchronized锁虽然可以解决多线程访问变量的问题,但是如果一个递归方法加上了synchronized锁,就会出现死锁的情况,第一次调用时,获取锁,正常运行没有问题,当递归调用第二次时,这个方法的锁已经被当前线程拿到了,无法再次获取,就出现死锁的情况。
为了解决这一问题,Lock接口就出现了。Lock可以让我们自己实现上锁和释放的操作,但是也要考虑死锁的问题,如果加锁之后的代码出现了异常,抛出异常后就不执行后面的解锁释放代码,所以,释放锁的代码一定要卸载finally中,确保会执行,使用方法如下:
public class Counter {
int count = 0;
Lock lock = new ReentrantLock();
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public void add(){
lock.lock();
try {
count ++ ;
}finally { // 释放锁一定要在finally中 确保百分百会执行
lock.unlock();
}
}
}
Lock锁还提供了一些更加便利的方法,synchronized获取不到锁是没办法再次去尝试获取锁的,而Lock给我们提供了以下方法:
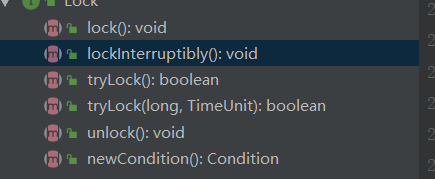
lockInterruptibly() 中断获取锁的操作
tryLock() 尝试获取锁
可重入锁ReentrantLock
可重入锁ReentrantLock,顾名思义,可以多次获取锁,synchronized关键字隐式的支持重入,ReentrantLock在多次调用lock方法时不会被阻塞。
所谓锁的公平和非公平
公平锁、非公平锁
公平锁:当多个线程要访问同一个锁时,按顺序一个个的获取释放锁
非公平锁:后来的线程可能优先获得锁
非公平锁比公平锁效率高一些,省去了一些CPU时间片轮转的上下文切换时间,ReentrantLock默认缺省也是非公平锁,如果要使用公平锁,在构造器中传入true即可,源码也是非常简单,就不多说了

乐观锁、悲观锁
悲观锁:对所有方法变量都必须获取锁,我们上面的synchronized关键字,Lock接口,都属于悲观锁
乐观锁:和悲观锁相反,可以不先获取锁,先读取变量,当要写入变量时,会执行CAS(Compare and Swap)操作,先去把old变量和内存中的变量去比较,如果还是原来的old值就写入,否则一直重复执行,直到符合条件才写入
ReadWriteLock接口和读写锁ReentrantReadWriteLock
之前提到的锁都属于排他锁,都只允许一个线程获取锁,而其他的线程均被阻塞。读写锁顾名思义,通常我们的应用中,读的操作大于写的操作,所以ReentrantReadWriteLock设定为,对于同一对象,读是可以并行的同时去读,读的时候不能进行写入的操作;而写入时只能进行有一个线程去写,并且不能进行读的操作。一般情况下,读写锁的性能都会比排它锁好,因为大多数场景读是多于写的。在读多于写的情况下,读写锁能够提供比排它锁更好的并发性和吞吐量。
Lock和Condition 实现等待和通知
上面的wait()和notifyAll()我们实现了线程等待和通知,那时候用的是synchronized锁,那么我们用Lock锁如何实现等待和通知呢?
我们继续引用上面 快递包裹 的例子,我们修改Package类,修改为用Lock锁,并且实现等待和通知
修改Package类
public class Package {
public String city = "";
public int km = 0;
//锁
Lock lock = new ReentrantLock();
//Condition 意味条件,去实现等待和通知
//kmCond 针对公里数 cityCond 针对到达地
Condition kmCond = lock.newCondition();
Condition cityCond = lock.newCondition();
public void changeKm(){
lock.lock();
this.km = 101;
try {
kmCond.signalAll();
}finally { //释放锁 一定要写在finally中 确保执行
lock.unlock();
}
}
public void changeCity(){
lock.lock();
this.city = "北京";
try {
cityCond.signalAll();
}finally { //释放锁 一定要写在finally中 确保执行
lock.unlock();
}
}
public void waitKm(){
lock.lock();
try {
while (this.km < 100){
Log.e("km < 100","线程"+Thread.currentThread().getName()+"等待,快递运送中");
kmCond.await();
}
Log.e("km > 100","线程"+Thread.currentThread().getName()+"结束,快递送达");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
lock.unlock();
}
}
public void waitCity(){
lock.lock();
try {
while (!this.city.equals("北京")){
Log.e("city is not beijing","线程"+Thread.currentThread().getName()+"等待,快递运送中");
cityCond.await();
}
Log.e("city is == beijing","线程"+Thread.currentThread().getName()+"结束,快递送达");
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
lock.unlock();
}
}
}
定义两个线程分别监听公里数和到达地:
class MyThread1 extends Thread{
Package p;
public MyThread1(Package p){
super();
this.p = p;
}
@Override
public void run() {
super.run();
p.waitKm();
}
}
class MyThread2 extends Thread{
Package p;
public MyThread2(Package p){
super();
this.p = p;
}
@Override
public void run() {
super.run();
p.waitCity();
}
}
Package p = new Package();
//监听公里数线程
new MyThread1(p).start();
//监听到达地线程
new MyThread2(p).start();
//模拟送达
Thread.sleep(500);
p.changeKm();
p.changeCity();
输出结果:

和synchronized锁用wait()notifyAll()实现的效果一模一样
线程池ThreadPool
基本概念
我们平时用的new Thread().start(),相对来说消耗资源比较多,首先new对象需要消耗,创建线程需要消耗,销毁线程同样消耗。那么线程池,顾名思义,将线程池化,并且可以复用,节省资源,最大的好处是将线程可管理化。
JDK给我们提供了一个线程池ThreadPoolExecutor,我们来看一下它给我们提供的构造器:

参数非常多,一个个来学习;
int corePoolSize
corePoolSize 是设定线程池的核心数,也就是有几个线程
int maximumPoolSize
当核心线程都在执行任务时,消息阻塞队列中的任务也已经填满了,还有新的任务时可以让线程池新增线程,maximumPoolSize 用来设定corePoolSize + 新增线程的最大值
long keepAliveTime
设定新增线程执行完任务后的存活时间
TimeUnit unit
keepAliveTime的时间单位
BlockingQueue<Runnable> workQueue
workQueue 当线程池中的线程都在执行任务,那么新增的任务就会放到workQueue中(是一个消息阻塞队列,下面会单独说明)
ThreadFactory threadFactory
线程工厂,并不是创建线程的工厂,主要是用来命名线程池,一般缺省
RejectedExecutionHandler handler
RejectedExecutionHandler 是当消息阻塞队列填满时,对队列中无法添加的新任务的处理,RejectedExecutionHandler给我们提供了四种处理方式:
1.DiscardOldestPolicy 丢弃阻塞队列中最前面的任务
2.AbortPolicy 超过线程池容量 直接抛出异常(线程池缺省默认策略)
3.CallerRunsPolicy 哪个线程提交过来的任务就由哪个线程执行
4.DiscardPolicy 直接丢弃任务
我们也可以实现RejectedExecutionHandler接口自定义策略。
线程池的使用
接下来看一下代码中如何使用线程池
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(4, 8, 1L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(10),
new ThreadPoolExecutor.AbortPolicy());
threadPool.execute(new Runnable() {
@Override
public void run() {
int i = 0;
while (i<10){
Log.e("线程1循环", i +"");
i++;
}
}
});
threadPool.execute(new Runnable() {
@Override
public void run() {
int i = 0;
while (i<10){
Log.e("线程2循环", i +"");
i++;
}
}
});
输出结果:

线程池的工作流程
代码实现非常的简单就不多说了,具体来看一下线程池的工作流程:

当线程池创建完成后,接受到新的任务,便直接开始由空闲的线程开始执行,那么最初线程池里是有corePoolSize个线程;当所有的线程都在运行时,依然有新的任务,则会放进BlockingQueue阻塞队列中;当线程都在运行,阻塞队列也满了的情况下,会增加新的线程,可增加线程数就是maximumPoolSize - corePoolSize;新增加的线程也都处于运行状态时,再接收到新的任务,则会根据我们设置的RejectedExecutionHandler 策略来对任务进行处理,默认则是直接抛出异常。新增加的线程把任务执行结束后,他会保留keepAliveTime时长后直接销毁。
BlockingQueue
BlockingQueue 是消息阻塞队列,看一下它里面的方法

提供的方法中 插入数据和取除数据的方法都是成对的
add() remove() 当插入/取出数据时不满足条件(队列已满或者队列为空)则直接抛出异常
offer() poll() 当插入/取出数据时不满足条件(队列已满或者队列为空)则返回特殊值
put() take() 当插入/取出数据时不满足条件(队列已满或者队列为空)则会一直阻塞线程,当能够插入/取出时,线程完成操作
如何合理的配置线程池
我们可以讲线程池接受的任务分为三大类,根据任务的类型合理分配:
- CPU密集型,也就是需要大量的计算的任务,消耗CPU比较多的,针对这种任务,一般线程池的线程数设为和设备CPU核心数相等的数量。
//获取设备CPU核心数
int CpuCount = Runtime.getRuntime().availableProcessors();
- IO密集型,大量读写操作的我们称之为IO密集型。针对这种类型,一般线程池的线程数设为CPU核心书的两倍
- 混合型,当上述两种任务都存在时,如果耗时相对比较接近,则最好创建两个线程池对任务分开处理(反之,则直接统一处理)。
AsyncTask使用和原理
AsyncTask基本使用
AsyncTask是一个抽象类,我们一般新建一个类去继承AsyncTask,重写它的方法即可。
public class MyAsyncTask extends AsyncTask<Integer, Integer, String> {
//后台任务执行之前调用
@Override
protected void onPreExecute() {
super.onPreExecute();
Log.e("任务执行前调用","onPreExecute");
}
//子线程中的操作
@Override
protected String doInBackground(Integer... integers) {
for(int i=0; i<integers[0];i++){
Log.e("子线程执行任务","doInBackground " + i);
//触发回调
publishProgress(i);
}
return integers[0].toString();
}
//doInBackground中的回调
@Override
protected void onProgressUpdate(Integer... values) {
Log.e("子线程执行任务回调","onProgressUpdate" + values[0]);
}
//后台任务完成后的回调
@Override
protected void onPostExecute(String s) {
super.onPostExecute(s);
Log.e("任务执行完成调用","onPostExecute");
}
}
//调用执行
MyAsyncTask myAsyncTask = new MyAsyncTask();
myAsyncTask.execute(5);
输出结果:

AsyncTask的使用比较简单,在android中如果要设置对应控件可以在MyAnsycTask类中增加构造方法, 将控件传入进来即可。
AsyncTask实现原理及源码分析
AsyncTask本质上就是封装了 Thread + Handler。下面贴一下AsyncTask源码中比较重要的几部分
首先我们要搞清楚AsyncTask它的构造做了什么事情
AsyncTask构造器方法比较长,一图截不下,我就直接复制过来了
public AsyncTask(@Nullable Looper callbackLooper) {
mHandler = callbackLooper == null || callbackLooper == Looper.getMainLooper()
? getMainHandler()
: new Handler(callbackLooper);
mWorker = new WorkerRunnable<Params, Result>() {
public Result call() throws Exception {
mTaskInvoked.set(true);
Result result = null;
try {
Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND);
//noinspection unchecked
result = doInBackground(mParams);
Binder.flushPendingCommands();
} catch (Throwable tr) {
mCancelled.set(true);
throw tr;
} finally {
postResult(result);
}
return result;
}
};
mFuture = new FutureTask<Result>(mWorker) {
@Override
protected void done() {
try {
postResultIfNotInvoked(get());
} catch (InterruptedException e) {
android.util.Log.w(LOG_TAG, e);
} catch (ExecutionException e) {
throw new RuntimeException("An error occurred while executing doInBackground()",
e.getCause());
} catch (CancellationException e) {
postResultIfNotInvoked(null);
}
}
};
}
由以上源码我们可以看出,它的构造方法中实际上就实例化了Handler,WorkerRunnable、FutureTask。Handler肯定是用来通知的,源码中,WorkerRunnable中的run方法,调用了我们复写的doInBackground方法。剩下的FutureTask,我们上面说了,它接受的就是一个Callable对象,我们继续跟踪它的源码看一下它干了一件什么事:



显而易见,FutureTask里实例化了一个Message对象。
我们接着来分析AsyncTask源码,从任务执行前调用的onPreExecute方法开始,我们点进去看一下它的源码:
发现它什么事情都没做,肯定是给其他方法调用的

我们在executeOnExecutor中方法中调用了它,我们看看executeOnExecutor方法又是在何时调用的

看到这里,已经很明显,我们在调用AsyncTask 的 execute方法时,就先执行了onPreExecute方法。所以onPreExecute方法是在主线程中运行的!!
通过executeOnExecutor方法中的代码,也就是下面这部分:

我们还可以得出,同一个AsyncTask 是不能多次调用execute,因为executeOnExecutor 开头就判断了状态,如果正在运行状态,再次调用会直接抛出异常!
那么executeOnExecutor中的参数又是哪里来的呢?

我们继续跟踪下代码

发现它是一个SerialExecutor 实例,SerialExecutor是什么呢?

原来,它内部是由一个双端队列ArrayDeque<Runnable>,它主要是用来把AsyncTask中的任务实现串行的,就是无论你提交多少个任务,这里都是一个个执行,那么他又是如何执行的呢?注意下面这里的代码
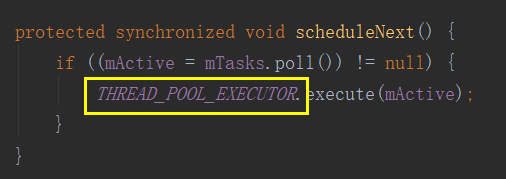

这个THREAD_POOL_EXECUTOR,就是我们上面说到的线程池,这也就证明了AsyncTask就是由线程池+Handler实现的。















 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









