









1.前言
再上一章主要介绍了音频文件的相关操作,在录音的过程当中,由于android机型不同的型号,即使采样率设置成44100k,有一定的外接音或者一些噪音等印象,配音出来的结果并不是很好,肯能存在’滋滋声’或者一些声音失真。所以这一章我们将深入操作下音频的原始数据(即PCM文件),需要做一些音频降噪增益的处理,使用户的配音体验能做的更好。这篇文章主要先大致介绍下webrtc。在第三章会讲下如何在Android里具体去使用降噪和增益模块,剩余的篇章会介绍下实现的原理,有兴趣的小伙伴们可以慢慢读下去。
有想直接看代码的朋友可以直接走下面这个链接
webrtc实现代码直通车
在此,列举对于音频的降噪处理相对成熟的三方库
-
Speex 是一套主要针对语音的开源免费,无专利保护的应用集合,Speex项目旨在通过免费提供昂贵专有语音编解码器的替代方案来降低语音应用程序的进入壁垒。它的主要功能有同一位流中的窄带(8 kHz),宽带(16 kHz)和超宽带(32 kHz)压缩 ,强度立体声编码,丢包隐藏,可变比特率操作(VBR),语音活动检测(VAD),不连续传输(DTX),定点端口,回声消除器,噪声抑制。开发Speex的Xiph.org基金会已经宣布废弃Speex,建议改用Opus取代。
-
它支持视频,语音,和同龄人之间发送通用数据,允许开发者建立强大的语音和视频通信解决方案。该技术适用于所有现代浏览器,以及对所有主要平台的本地客户。背后的WebRTC的技术实现为一个开放的网络标准,可作为所有主流浏览器常规的JavaScript API。对于本地客户端,如Android和iOS应用中,库可提供相同的功能。webRtc库里有一个音频降噪的模块,即
audio_process,所处位置在/webrtc/modules/audio_processing -
根据噪声的不同大部分处理是针对平稳噪声以及瞬时噪声来做。RNNoise 降噪算法则是根据纯语音以及噪声通过 GRU 训练来做。包含特征点提取、预料等核心部分。
传统降噪算法大部分是估计噪声 + 维纳滤波,噪声估计的准确性是整个算法效果的核心。
RNNoise 的优点主要是一个算法通过训练可以解决所有噪声场景以及可以优化传统噪声估计的时延和收敛问题。
RNNoise 的缺点是深度学习算法落地问题。因为相对大部分传统算法,RNNoise 训练要得到一个很好的效果,由于特征点个数、隐藏单元的个数以及神经网络层数的增加,导致模型增大,运行效率。
阅读了网上一些资料,对比过来,webrtc的降噪模块比较适合我这边的业务使用,所以这篇文章主要讲webrtc关键函数,需要调用webrct降噪模块的调用和降噪过后的音频数据对比。之后补上webrtc增益模块(主要函数是 analog_agc.c)。下面的代码里已经集成了相应的降噪模块
2. webrtc介绍
声音处理针对音频数据进行处理,包括回声消除(AEC)、AECM(AEC Mobile)、自动增益(AGC)、降噪(NS)、静音检测(VAD)处理等功能,用来提升声音质量。
webrtc相关代码我这边使用的声网提供的镜像代理,跟着文档走一遍就行了
声网提供的webrtc源码下载和编译
学而思提供的webrtc源码下载和编译
google webrtc source
整个过程是比较久的, 我这边下载了一个多小时

2.1 webrtc 简介
借助WebRTC,您可以在基于开放标准的应用程序中添加实时通信功能。它支持在同级之间发送视频,语音和通用数据,从而使开发人员能够构建功能强大的语音和视频通信解决方案。该技术可在所有现代浏览器以及所有主要平台的本机客户端上使用。说白了,就是具备极强的音视频功能。
2.2 webrtc 框架
这是webrtc的整体代码目录

整个webrtc代码非常大,因为它也涵盖了一些成熟的第三方库,使他的功能更加完善。包括ffmpeg、sqlite等。
接下来看一下官方给出的框架图
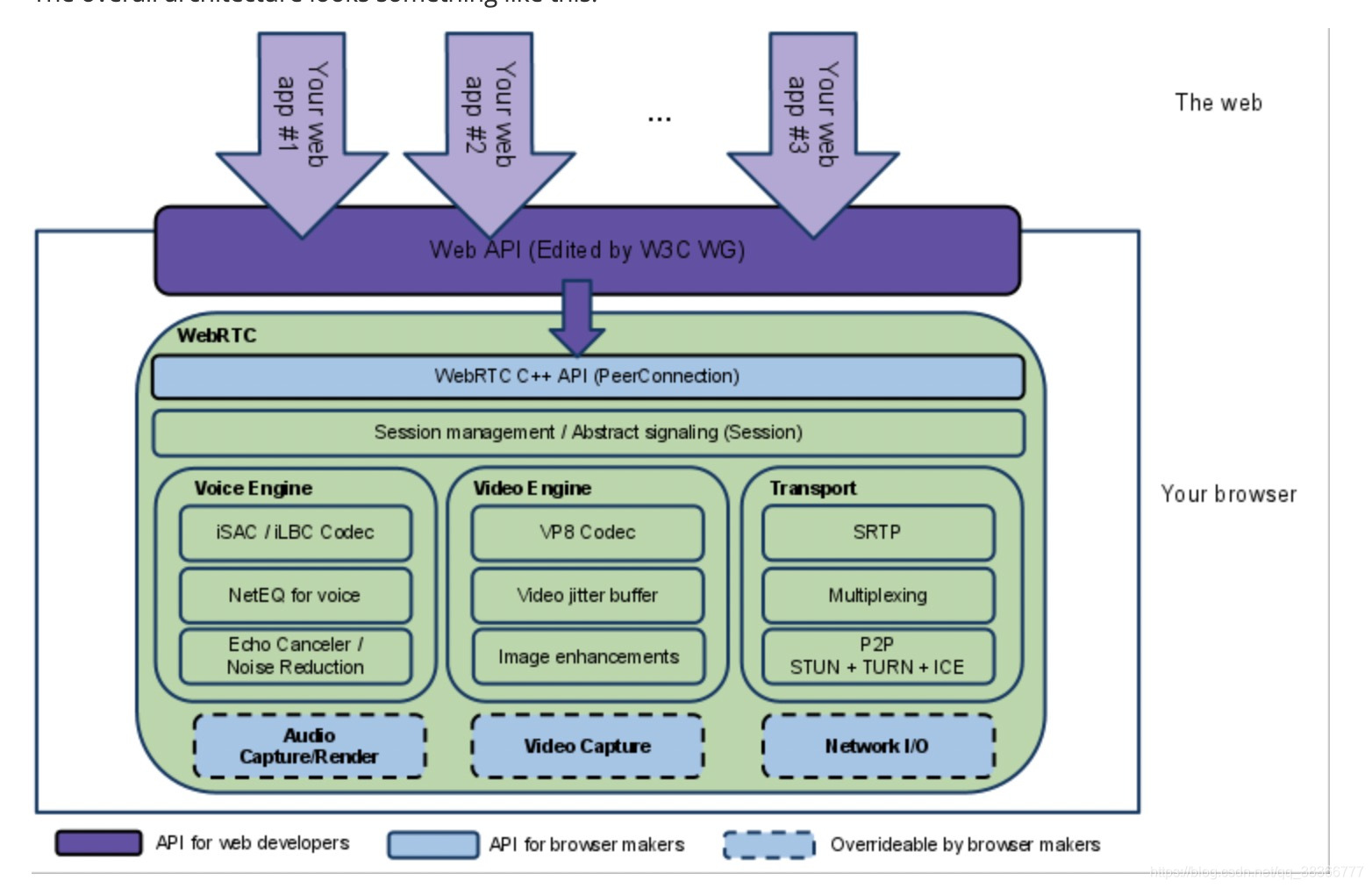
如果我们的项目暂时不做p2p连接等功能,可以先重点看下 VoiceEngine 和 VideoEngine
VoiceEngine
- iSAC / iLBC / Opus
iSAC:用于VoIP和流音频的宽带和超宽带音频编解码器。iSAC使用16 kHz或32 kHz采样频率,具有12到52 kbps的自适应可变比特率。
iLBC:用于VoIP和流音频的窄带语音编解码器。使用8 kHz采样频率,其20ms帧的比特率为15.2 kbps,30ms帧的比特率为13.33 kbps。由IETF RFC 3951和3952定义。
Opus:支持从6 kbit / s到510 kbit / s的恒定和可变比特率编码,从2.5 ms到60 ms的帧大小以及从8 kHz(带4 kHz带宽)到48 kHz(带20 kHz带宽)的各种采样率,可以复制人类听觉系统的整个听力范围)。由IETF RFC 6176定义。NetEQ for Voice
一种动态抖动缓冲区和错误隐藏算法,用于隐藏网络抖动和数据包丢失的负面影响。在保持最高语音质量的同时,尽可能降低延迟。
-
回声消除器(AEC)
声学回声消除器是基于软件的信号处理组件,可实时消除因播放的声音进入有源麦克风而产生的声学回声。 -
降噪(NR)
降噪组件是一个基于软件的信号处理组件,可消除通常与VoIP相关的某些类型的背景噪声。(嘶嘶声,风扇噪音等)
VideoEngine
VideoEngine是一个框架视频媒体链,用于从摄像机到网络以及从网络到屏幕的视频。
-
VP8
WebM项目的视频编解码器。它设计用于低延迟,因此非常适合RTC。 -
视频抖动缓冲器
视频动态抖动缓冲器。帮助掩盖抖动和丢包对整体视频质量的影响。 -
图像增强
例如,从网络摄像头捕获的图像中消除视频噪声。
从整体的框架来看,webrtc代码容量有非常大,但是各个引擎之间是相互独立的。所以我们可以单独把音频模块相应的功能抽取出来,在本文中抽出了ns(降噪)和 agc (增益)
3 webrtc 降噪模块和音频增益模块使用
3.1 降噪模块使用流程
看下下面的时序图
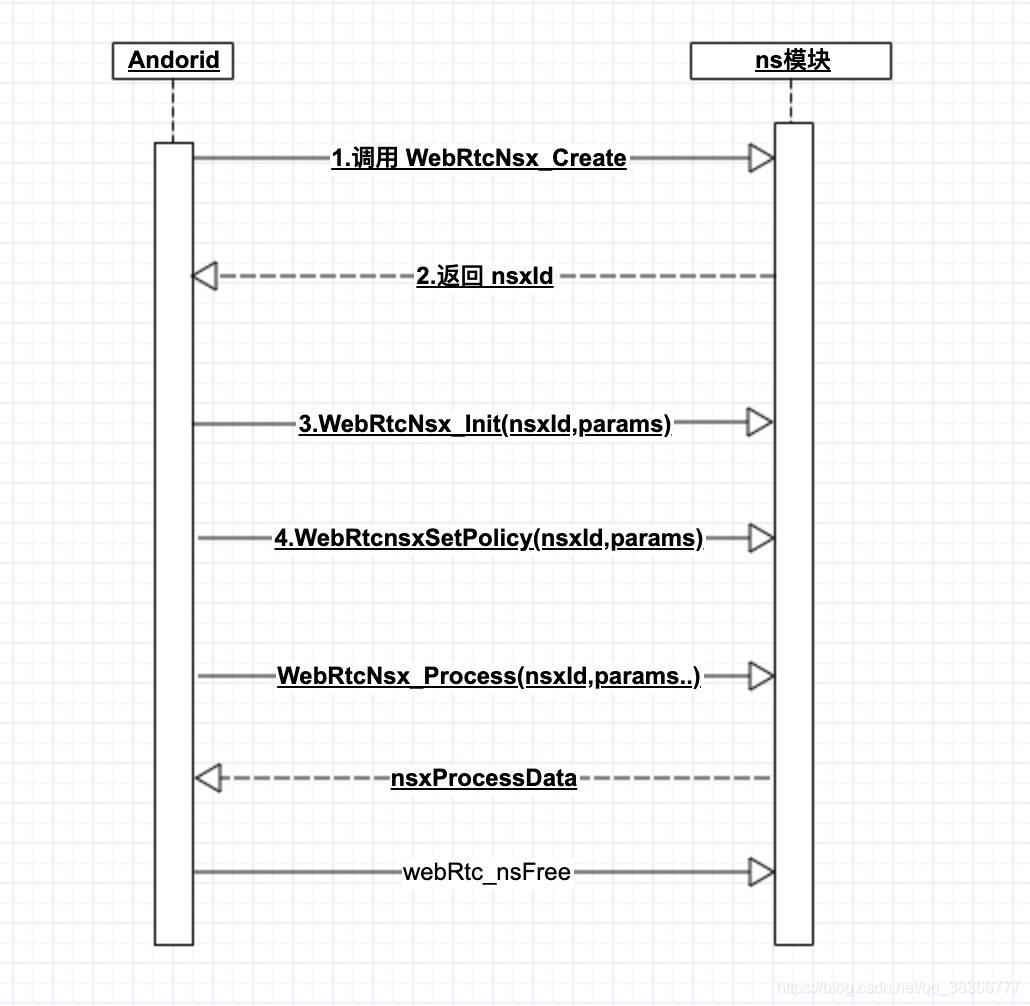
//ns初始化
//fs == 8000 || fs == 16000 || fs == 32000 || fs == 48000
nsxId = WebRtcNsUtils.WebRtcNsx_Create();
int nsxInit = WebRtcNsUtils.WebRtcNsx_Init(nsxId, 8000); //0代表成功
int nexSetPolicy = WebRtcNsUtils.nsxSetPolicy(nsxId, 2);
WebRtcNsUtils.WebRtcNsx_Process(nsxId, inputData, num_bands, nsProcessData);
调用的流程不难,没有特别复杂的操作。先create,init,(setConfig可要可不要),再process,最后一个free释放资源
- 这边要注意一点 不同版本的webrtc支持的采样率是不同的,以及自身音频文件是否符合降噪的采样率,否则容易出错,这边大家可以看返回的ret的参数是多少,如果process返回0为正常。
int WebRtcNs_InitCore(NoiseSuppressionC *self, uint32_t fs) {
int i;
// Check for valid pointer.
if (self == NULL) {
return -1;
}
// Initialization of struct.
if (fs == 8000 || fs == 16000 || fs == 32000 || fs == 48000) {
self->fs = fs;
} else {
return -1;
}
…………
}
这里看一下Process代码,最终调用的是ns_core.c 的WebRtcNs_ProcessCore,在下一章我们会介绍ns_core.c文件主要逻辑
void WebRtcNs_Process(NsHandle *NS_inst,
const float *const *spframe,
size_t num_bands,
float *const *outframe) {
WebRtcNs_ProcessCore((NoiseSuppressionC *) NS_inst, spframe, num_bands,
outframe);
}
3.1 webrtc 测试结果
测试结果用Audacity来分析音频数据, 8000采样率的 pcm文件

16000采样率

32000采样率
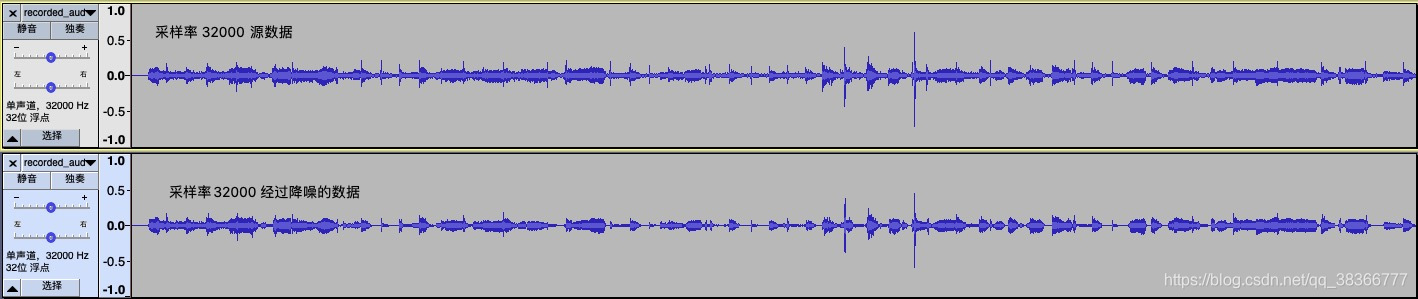
通过图可以看到,部分特别尖端的数据会被优化掉
通过降噪后,原本的音频一些小杂音会被抹去。
4 webrtc 音频降噪函数解析
webrtc 降噪的关键函数在 ns_core.c,噪声频谱可以使用如语音/噪声似然函数进行估计。将接收到的每帧信号和频率分量分类为噪声或语音。这边会先从原理和代码角度来解析。
4.1 算法相关原理
y(t) = x(t)+n(t) --(1)
上式中x和n分别表示语音和噪声,而y表示麦克风采集到的信号。 从上图可以看出语音和噪声是加性且不相关的关系,所以这里的中心思想就变成了从Y中估计噪声D,然后抑制n(t)以得到语音。所以对噪声的估计准确性是至关重要的,我们知道声音是正态分布的图,有如下算法可以参考,
- 基于VAD检测的噪声估计,VAD对Y进行检测,如果检测没有语音,则认为噪声,这是对噪声的一种估计方法。
2.基于全局幅度谱最小原理,该估计认为幅度谱最小的情况必然对应没有语音的时候。
3.还有基于矩阵奇异值分解原理估计噪声的
webRTC没有采用上述的方法,而是对似然比(VAD检测时就用了该方法)函数进行改进,将多个语音/噪声分类特征合并到一个模型中形成一个多特征综合概率密度函数,对输入的每帧频谱进行分析。其可以有效抑制风扇/办公设备等噪声。
其抑制过程如下:
对接收到的每一帧带噪语音信号,以对该帧的初始噪声估计为前提,定义语音概率函数,测量每一帧带噪信号的分类特征,使用测量出来的分类特征,计算每一帧基于多特征的语音概率,在对计算出的语音概率进行动态因子(信号分类特征和阈值参数)加权,根据计算出的每帧基于特征的语音概率,修改多帧中每一帧的语音概率函数,以及使用修改后每帧语音概率函数,更新每帧中的初始噪声(连续多帧中每一帧的分位数噪声)估计。
4.2 set_feature_extraction_parameters
设置了特征提取使用到的参数,当前WebRTC噪声抑制算法使用了LRT特征/频谱平坦度和频谱差异度三个指标,没有使用频谱熵和频谱方差这两个特征。
这里简单介绍下概念
- LRT特征
似然比检验是基于 最大似然估计(ML),进一步引入某个假设,来证明新引入假设是否成立的方法。首先,假设原来的条件已经令似然函数取得最大值,新引入的假设不会超过这个最大似然函数值,但如果约束条件有效,有约束的最大值应当接近无约束的最大值,两者的比值接近于1。否则远远小于1。
极大似然估计的原理,用一张图片来说明
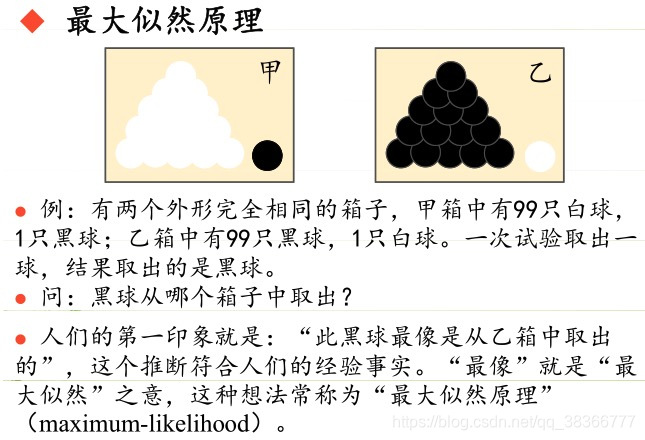
总结起来,最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
原理:极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
似然比检验是利用似然函数来检测某个假设(或限制)是否有效的一种检验。一般情况下,要检测某个附加的参数限制是否是正确的,可以将加入附加限制条件的较复杂模型的似然函数最大值与之前的较简单模型的似然函数最大值进行比较。如果参数限制是正确的,那么加入这样一个参数应当不会造成似然函数最大值的大幅变动。一般使用两者的比例来进行比较,这个比值是卡方分配。
尼曼-皮尔森引理说明,似然比检验是所有具有同等显著性差异的检验中最有统计效力的检验。
- 频谱平坦度 频谱平坦度介绍
频谱平坦度也叫做维纳熵,即各个频率分量的几何平均数与算术平均数的比值, 网上有定义,下面直接出公式了。
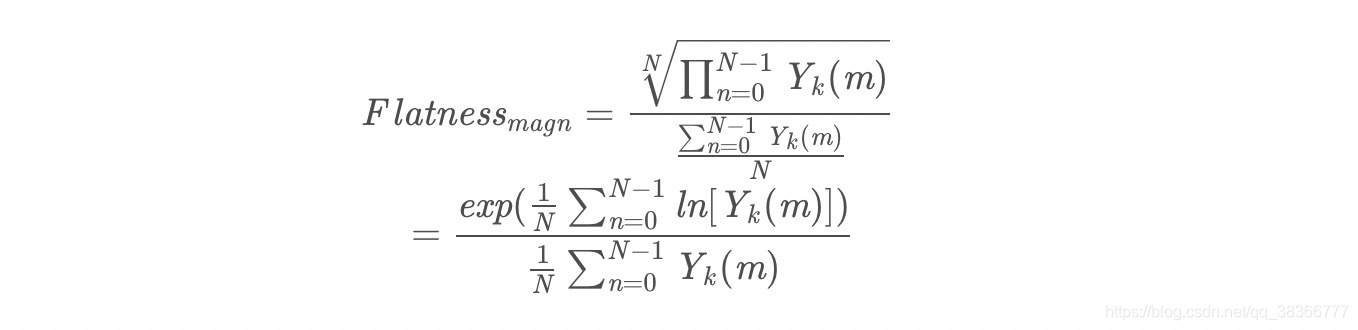
直观的说如果每个分量都相等,比值为1;分量值相当,比值接近于1,这时认为是白噪声;分量差异大的话,比值接近0,一般认为有语音产生。
在下文会更详细的说明
- 频谱偏差
这个是将输入的频谱和估算的频谱模板进行对比来评价语音和噪声概率的方法。是一种谱估计方法
4.3 WebRtcNs_InitCore
self:应该初始化的实例
fs:采样频率 这边注意下(不同版本对采样频率支持不一样,越新的支持的采样频率越多)
// Initialize state.
int WebRtcNs_InitCore(NoiseSuppressionC* self, uint32_t fs) {
int i;
// Check for valid pointer.
if (self == NULL) {
return -1;
}
// Initialization of struct.
if (fs == 8000 || fs == 16000 || fs == 32000 || fs == 48000) {
self->fs = fs;
} else {
return -1;
}
self->windShift = 0;
// We only support 10ms frames.
if (fs == 8000) {
//语音数据的长度,8k/10ms的数据量是80
self->blockLen = 80;
//分析长度,由于是在频域分析,将长度像上取2的幂次,最小的值是128,实际上是fft的长度
self->anaLen = 128;
//窗函数,采用混合汉宁平顶窗函数
self->window = kBlocks80w128;
} else {
self->blockLen = 160;
self->anaLen = 256;
self->window = kBlocks160w256;
}
self->magnLen = self->anaLen / 2 + 1; // Number of frequency bins.
// Initialize FFT work arrays.
self->ip[0] = 0; // Setting this triggers initialization.
memset(self->dataBuf, 0, sizeof(float) * ANAL_BLOCKL_MAX);
WebRtc_rdft(self->anaLen, 1, self->dataBuf, self->ip, self->wfft);
//是滑动分析窗,针对80点128的fft而言,每一次会保留前一帧的128-80=48个点的数据,而不是对80点简单填充0变成128点做fft。
//但这会带来合成上的问题,通常采用加窗以防止重叠带来的突变。可以使用做fft变换一样的窗函数。但这要求窗函数保幂映射,即重叠
//区部分窗口的平方和必须为1.
memset(self->analyzeBuf, 0, sizeof(float) * ANAL_BLOCKL_MAX);
//dataBuf存储的是原始时域信号
memset(self->dataBuf, 0, sizeof(float) * ANAL_BLOCKL_MAX);
//syntBuf是谱减法,减去噪声后变换到时域的信号
memset(self->syntBuf, 0, sizeof(float) * ANAL_BLOCKL_MAX);
// For HB processing.这是高频部分,最多有两个band
memset(self->dataBufHB,
0,
sizeof(float) * NUM_HIGH_BANDS_MAX * ANAL_BLOCKL_MAX);
// For quantile noise estimation.
memset(self->quantile, 0, sizeof(float) * HALF_ANAL_BLOCKL);
//3帧同步估计,lquantile是对数分位数。density是概率密度,计算分位数用到概率密度的。
for (i = 0; i < SIMULT * HALF_ANAL_BLOCKL; i++) {
self->lquantile[i] = 8.f;
self->density[i] = 0.3f;
}
for (i = 0; i < SIMULT; i++) {
// counter是一个权值,代表的每一帧对分位数估计而言其所占的比重。
self->counter[i] =
(int)floor((float)(END_STARTUP_LONG * (i + 1)) / (float)SIMULT);
}
self->updates = 0;
// 维纳滤波器初始化
for (i = 0; i < HALF_ANAL_BLOCKL; i++) {
self->smooth[i] = 1.f;
}
// 设置抑制噪声的激进度
self->aggrMode = 0;
// Initialize variables for new method.
self->priorSpeechProb = 0.5f; // Prior prob for speech/noise.
// Previous analyze mag spectrum.
memset(self->magnPrevAnalyze, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// Previous process mag spectrum.
memset(self->magnPrevProcess, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// Current noise-spectrum.
memset(self->noise, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// Previous noise-spectrum.
memset(self->noisePrev, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// Conservative noise spectrum estimate.
memset(self->magnAvgPause, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// For estimation of HB in second pass.
memset(self->speechProb, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// Initial average magnitude spectrum.
memset(self->initMagnEst, 0, sizeof(float) * HALF_ANAL_BLOCKL);
for (i = 0; i < HALF_ANAL_BLOCKL; i++) {
// Smooth LR (same as threshold).
self->logLrtTimeAvg[i] = LRT_FEATURE_THR;
}
//特征量,计算噪声用到。光谱平整度 和功能量
// Feature quantities.
// Spectral flatness (start on threshold).
self->featureData[0] = SF_FEATURE_THR;
self->featureData[1] = 0.f; // Spectral entropy: not used in this version.
self->featureData[2] = 0.f; // Spectral variance: not used in this version.
// Average LRT factor (start on threshold).
self->featureData[3] = LRT_FEATURE_THR;
// Spectral template diff (start on threshold).
self->featureData[4] = SF_FEATURE_THR;
self->featureData[5] = 0.f; // Normalization for spectral difference.
// Window time-average of input magnitude spectrum.
self->featureData[6] = 0.f;
memset(self->parametricNoise, 0, sizeof(float) * HALF_ANAL_BLOCKL);
// Histogram quantities: used to estimate/update thresholds for features.
memset(self->histLrt, 0, sizeof(int) * HIST_PAR_EST);
memset(self->histSpecFlat, 0, sizeof(int) * HIST_PAR_EST);
memset(self->histSpecDiff, 0, sizeof(int) * HIST_PAR_EST);
self->blockInd = -1; // Frame counter.
// Default threshold for LRT feature.
self->priorModelPars[0] = LRT_FEATURE_THR;
// Threshold for spectral flatness: determined on-line.
self->priorModelPars[1] = 0.5f;
// sgn_map par for spectral measure: 1 for flatness measure.
self->priorModelPars[2] = 1.f;
// Threshold for template-difference feature: determined on-line.
self->priorModelPars[3] = 0.5f;
// Default weighting parameter for LRT feature.
self->priorModelPars[4] = 1.f;
// Default weighting parameter for spectral flatness feature.
self->priorModelPars[5] = 0.f;
// Default weighting parameter for spectral difference feature.
self->priorModelPars[6] = 0.f;
// Update flag for parameters:
// 0 no update, 1 = update once, 2 = update every window.
self->modelUpdatePars[0] = 2;
self->modelUpdatePars[1] = 500; // Window for update.
// Counter for update of conservative noise spectrum.
self->modelUpdatePars[2] = 0;
// Counter if the feature thresholds are updated during the sequence.
self->modelUpdatePars[3] = self->modelUpdatePars[1];
//白噪声和粉红噪声
self->signalEnergy = 0.0;
self->sumMagn = 0.0;
self->whiteNoiseLevel = 0.0;
self->pinkNoiseNumerator = 0.0;
self->pinkNoiseExp = 0.0;
set_feature_extraction_parameters(self);
// Default mode.
WebRtcNs_set_policy_core(self, 0);
self->initFlag = 1;
return 0;
}
4.4 ComputeSpectralFlatness
频谱度计算时N表示STFT后频率点数,B代表频率带的数量,K是频点指数,j是频带指数。每个频带包括大量的频率点。就128个频率点可分成4个频带(低带,中低频带,中高频带,高频),每个频带32个频点。对于噪声Flatness偏大且为常数,而对于语音,计算出的数量则偏下且为变量。这四个频段对于语音信号差异是比较大的,对于噪声是比较小的,根据上面的公式,如果接近于1,则是噪声,(噪声的幅度谱趋于平坦),二对于语音,上面的N次根是对乘积结果进行N次缩小,相比于分母部分,缩小的数量级是倍数的,所以语音的平坦度较小,是趋近于0的。
// Compute spectral flatness on input spectrum.
// |magnIn| is the magnitude spectrum.
// Spectral flatness is returned in self->featureData[0].
static void ComputeSpectralFlatness(NoiseSuppressionC* self,
const float* magnIn) {
size_t i;
size_t shiftLP = 1; // Option to remove first bin(s) from spectral measures.
float avgSpectralFlatnessNum, avgSpectralFlatnessDen, spectralTmp;
// Compute spectral measures.
// For flatness.
avgSpectralFlatnessNum = 0.0;
avgSpectralFlatnessDen = self->sumMagn;
for (i = 0; i < shiftLP; i++) {
//跳过第一个频点,即直流频点Den是denominator(分母)的缩写,avgSpectralFlatnessDen是上述公式分母计算用到的
avgSpectralFlatnessDen -= magnIn[i];
}
// Compute log of ratio of the geometric to arithmetic mean: check for log(0) case.
// 计算分子部分,numerator(分子),对log(0)是无穷小的值,所以计算时对这一情况特殊处理。
for (i = shiftLP; i < self->magnLen; i++) {
if (magnIn[i] > 0.0) {
avgSpectralFlatnessNum += (float)log(magnIn[i]);
} else {
//TVAG是time-average的缩写,对于能量出现异常的处理。利用前一次平坦度直接取平均返回。这里平滑因子是0.3.
self->featureData[0] -= SPECT_FL_TAVG * self->featureData[0];
return;
}
}
// Normalize.
avgSpectralFlatnessDen = avgSpectralFlatnessDen / self->magnLen;
avgSpectralFlatnessNum = avgSpectralFlatnessNum / self->magnLen;
// Ratio and inverse log: check for case of log(0).
spectralTmp = (float)exp(avgSpectralFlatnessNum) / avgSpectralFlatnessDen;
// Time-avg update of spectral flatness feature.
self->featureData[0] += SPECT_FL_TAVG * (spectralTmp - self->featureData[0]);
// Done with flatness feature.
}
4.5 ComputeSpectralDifference
有关噪声频谱的另一个假设是,噪声频谱比语音频谱更稳定。因此,可假设噪声频谱的整体形状在任何给定阶段都倾向于保持相同。这第三个特征用于测量输入频谱与噪声频谱形状的偏差。
计算公式如下
// avgDiffNormMagn = var(magnIn) - cov(magnIn, magnAvgPause)^2 / var(magnAvgPause)
4.6 ComputeSnr
根据分位数噪声估计计算前后信噪比。
后验信噪比指观测到的能量与噪声功率相关的输入功率相比的瞬态SNR:
根据分位数噪声估计计算前后信噪比。
输入:|magn |是信号幅度谱的估计。
|noise| 噪声谱估计的幅度。
输出 得到前后信噪比
static void ComputeSnr(const NoiseSuppressionC* self,
const float* magn,
const float* noise,
float* snrLocPrior,
float* snrLocPost) {
size_t i;
for (i = 0; i < self->magnLen; i++) {
// Previous post SNR.
// Previous estimate: based on previous frame with gain filter.
float previousEstimateStsa = self->magnPrevAnalyze[i] /
(self->noisePrev[i] + 0.0001f) * self->smooth[i];
// Post SNR.
snrLocPost[i] = 0.f;
if (magn[i] > noise[i]) {
snrLocPost[i] = magn[i] / (noise[i] + 0.0001f) - 1.f;
}
// DD estimate is sum of two terms: current estimate and previous estimate.
// Directed decision update of snrPrior.
snrLocPrior[i] =
DD_PR_SNR * previousEstimateStsa + (1.f - DD_PR_SNR) * snrLocPost[i];
} // End of loop over frequencies.
}
4.7 SpeechNoiseProb
这个函数主要计算语音和噪声概率,并将这两者概率返回,这个函数主要是对计算公式进行推导,这里就不做细讲了
4.8 UpdateNoiseEstimate
更新噪音估算。
probSpeech = self->speechProb[i];
probNonSpeech = 1.f - probSpeech;
// Temporary noise update:
// 如果更新值小于之前的值,则将其用于语音帧。
noiseUpdateTmp = gammaNoiseTmp * self->noisePrev[i] +
(1.f - gammaNoiseTmp) * (probNonSpeech * magn[i] +
probSpeech * self->noisePrev[i]);
上述噪声估计模型会对噪声可能性较大(即语音可能性较小)的每个帧和频率槽的噪声进行更新。对于噪声可能性不大的帧和频率槽,则将对信号中上一个帧的估计作为噪声估计。完成噪声估计更新后,噪声估计和过滤流程采用维纳增益滤波器以减少或消除来自输入帧的估计噪声量。
4.9 WebRtcNs_ProcessCore
ProcessCore是降噪的核心函数,主要的降噪程序。这边就不贴住完整代码了,可以跟着流程去看代码
void WebRtcNs_ProcessCore(NoiseSuppressionC *self,
const float *const *speechFrame,
size_t num_bands,
float *const *outFrame)
1、检查启动是否完成和校验相关参数,更新L波段的分析缓冲区,更新分析缓冲区的H波段(数组类型)。
2、 计算输入带噪语音数据帧的能量值。(看代码定义的能量值)
在这种情况下, 希望避免更新统计信息:只有0时更新特性统计信息将导致阈值向零信号的情况移动。这反过来有这样的效果,一旦信号被“打开”(非零值),一切将被视为语音,没有噪声抑制效果。根据不活跃信号的持续时间,系统需要相当长的时间来了解什么是噪音,什么是语音。
Windowing(self->window, self->analyzeBuf, self->anaLen, winData);
energy = Energy(winData, self->anaLen);
static float Energy(const float *buffer, size_t length) {
size_t i;
float energy = 0.f;
for (i = 0; i < length; ++i) {
energy += buffer[i] * buffer[i];
}
return energy;
}
if (energy == 0.0) {
self->signalEnergy = 0;
return;
}
3、FFT傅里叶变换
4、计算维纳滤波增益,通过直接判决法计算先验信噪比。
// DD estimate is sum of two terms: current estimate and previous estimate.
// Directed decision update of |snrPrior|.
snrPrior = DD_PR_SNR * previousEstimateStsa +
(1.f - DD_PR_SNR) * currentEstimateStsa;
// Gain filter.
theFilter[i] = snrPrior / (self->overdrive + snrPrior);
5、对维纳增益值根据用户设置的降噪等级,进行下溢与上溢处理。
6、进行维纳滤波,并将增益后的频域数据(频率降噪)通过IFFT转为时域数据。
7、对降噪等级进行判断,如果等级为0 ,则维纳滤波输出则为最后的降噪结果。否则,继续处理。
8、计算维纳滤波后的帧数据能量,并计算与步骤2中的能量比值, gain = (float)sqrt(energy2/ (energy1 + 1.f));
9、当gain值大于0.5,计算因子1,factor1= 1.f + 1.3f * (gain - B_LIM);并判断gain *factor1是否大于1。如果大于1,因子1则为 factor1 = 1.f / gain;
10、当gain值小于0.5,判断gain是否小于增益下限值(用户设定),如果小于,则 gain = self->denoiseBound;计算因子2,factor2= 1.f - 0.3f * (B_LIM - gain);
11、结合先验语音概率计算最终的增益因子。
factor = self->priorSpeechProb* factor1 + (1.f - self->priorSpeechProb) * factor2;
12、在时域,将维纳滤波处理后的数据与facror相乘,得到最后的降噪结果。
13、如果对信号进行了分子带处理,则接下来需要对高频部分的自带进行处理。
if (flagHB == 1) {
// Average speech prob from low band.
// 平均值(4->8kHz)的频率频谱
avgProbSpeechHB = 0.0;
for (i = self->magnLen - deltaBweHB - 1; i < self->magnLen - 1; i++) {
avgProbSpeechHB += self->speechProb[i];
}
//1.计算高频部分的先验语音概率,这是是用低频子带求平均得到
avgProbSpeechHB = avgProbSpeechHB / ((float) deltaBweHB);
// 如果语音被处理过,例如AEC,那么它不应该被认为是用于高频带抑制目的的语音。
sumMagnAnalyze = 0;
sumMagnProcess = 0;
for (i = 0; i < self->magnLen; ++i) {
sumMagnAnalyze += self->magnPrevAnalyze[i];
sumMagnProcess += self->magnPrevProcess[i];
}
RTC_DCHECK_GT(sumMagnAnalyze, 0);
// 2.将上一步计算的结果进行缩放,乘以上一帧处理后的输出信噪比
avgProbSpeechHB *= sumMagnProcess / sumMagnAnalyze;
// Average filter gain from low band. //3.计算得到的各频点的维纳滤波增益的平均值。 avgFilterGainHB
avgFilterGainHB = 0.0;
for (i = self->magnLen - deltaGainHB - 1; i < self->magnLen - 1; i++) {
avgFilterGainHB += self->smooth[i];
}
avgFilterGainHB = avgFilterGainHB / ((float) (deltaGainHB));
avgProbSpeechHBTmp = 2.f * avgProbSpeechHB - 1.f;
//4.对先验语音概率进行映射,得到初步的增益值。gainModHB
gainModHB = 0.5f * (1.f + (float) tanh(gainMapParHB * avgProbSpeechHBTmp));
// Combine gain with low band gain. //5.将上两步(gainModHB 、avgFilterGainHB)中得到的结果进行平滑,得到高频部分最终的增益因子。
gainTimeDomainHB = 0.5f * gainModHB + 0.5f * avgFilterGainHB;
if (avgProbSpeechHB >= 0.5f) {
gainTimeDomainHB = 0.25f * gainModHB + 0.75f * avgFilterGainHB;
}
gainTimeDomainHB = gainTimeDomainHB * decayBweHB;
// Make sure gain is within flooring range.
// Flooring bottom.
if (gainTimeDomainHB < self->denoiseBound) {
gainTimeDomainHB = self->denoiseBound;
}
// Flooring top.
if (gainTimeDomainHB > 1.f) {
gainTimeDomainHB = 1.f;
}
// Apply gain.
for (i = 0; i < num_high_bands; ++i) {
for (j = 0; j < self->blockLen; j++) {
//6.返回结果
outFrameHB[i][j] =
WEBRTC_SPL_SAT(WEBRTC_SPL_WORD16_MAX,
gainTimeDomainHB * self->dataBufHB[i][j],
WEBRTC_SPL_WORD16_MIN);
}
}
}
小结
webrtc的功能还是很强大的,使用起来很方便,但是整体实现还是比较复杂的,需要我们继续去挖掘理解。AGC的部分源码可以直接看代码里的,也可以去阅读网上相关的解析。
参考
《实时语音处理实践指南》

















 6951
6951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









