







终于从PN结开始聊到CPU了,在阅读本篇文章之前,建议先阅读往期半导体的基础文章:
中央处理器(CPU)作为计算机的大脑,是信息处理的核心。我们每天使用的电脑、手机、服务器,背后都依赖着这颗只有指甲盖大小的芯片完成亿万次计算。那么,这颗“小脑袋”是如何制造出来的?它的工作原理又是怎样的?本文将从制造工艺和工作机制两个方面带你深度了解CPU的世界。
一、CPU的制造技术:纳米级的精密工程
1.1 芯片制造工艺(制程工艺)
现代CPU的制造工艺常被称为“纳米制程”,例如5nm、3nm等,这里的“nm”(纳米)并非指晶体管的实际尺寸,而是表示工艺的综合能力,比如晶体管密度、功耗、开关速度等。

先解释一下常说的3纳米、5纳米、7纳米芯片到底是什么意思。早期制程节点(如90nm以上时代),直接对应PN结晶体管栅极物理长度,如上图所示,但随技术发展,节点命名逐渐转为等效工艺密度描述,不单是一个栅极物理指标了,而是一种营销术语,是因为所有工艺的改进,栅极漏极源极这些整体尺寸的变小,在同样大小的芯片上可以塞下更多的晶体管,在数量上相当于栅极变成之前尺寸的3纳米了,实际上,现在3纳米芯片的芯片,栅极的长度在12-14nm之间,5纳米芯片的栅极长度在21-24nm之间。
如果对PN结晶体管不了解的朋友,建议先看这两篇文章:
▍制程演进简史:
| 年代 | 工艺节点 | 特点 |
|---|---|---|
| 1990s | 250nm/180nm | 晶体管开始进入微米以下 |
| 2000s | 90nm/65nm | 铜互连替代铝互连 |
| 2010s | 32nm/22nm | 引入FinFET(鳍式场效应管)结构 |
| 2020s | 7nm/5nm/3nm | EUV(极紫外光刻)开始使用,晶体管密度大幅上升 |
1.2 制造流程简述
CPU的制造过程可长达3个月,涉及超过1000道工序,主要包括以下步骤:
Step 1:硅晶圆准备
使用高纯度的单晶硅制造晶圆(Wafer),直径多为300mm。
Step 2:光刻(Photolithography)
通过掩模(mask)和光源将图案投射到晶圆上,形成电路图形。传统使用193nm光源,3nm工艺使用EUV光刻(极紫外,13.5nm),目前只有荷兰的ASML公司可以生产。
Step 3:刻蚀(Etching)
利用化学或等离子体刻蚀工艺,去除多余材料,留下电路图案。
Step 4:离子注入(Doping)
向硅中注入特定杂质(如磷、硼)以控制晶体管导电性。
Step 5:金属互连(Metallization)
在不同晶体管之间形成电路连接,一般采用铜互连,3nm后期可能使用钴、钌等材料。
Step 6:封装(Packaging)
将切割下来的芯片封装到载板上,并引出针脚或焊球供主板使用。
提示:以上制造工艺原理细节感兴趣的朋友,请看往期文章:芯片的制造过程;有更详细的讲解。
1.3 晶体管密度与摩尔定律
摩尔定律由英特尔联合创始人 戈登·摩尔(Gordon Moore) 于 1965 年提出,其核心观点是:“每隔约 18~24 个月,集成电路上的晶体管数量将增加一倍,性能也将随之提升,而单位成本下降。”
换句话说:计算能力每两年翻一番。它最初是对芯片行业技术进步速度的观察预测,但几十年来,摩尔定律几乎成了半导体产业发展的“金科玉律”。
晶体管是CPU/GPU最基本的构成单元。以苹果M1为例,其使用5nm工艺,拥有160亿个晶体管。而英特尔14代酷睿(Meteor Lake)则采用Intel 4工艺,晶体管密度突破1亿颗/mm²。现在最新的iPhone 16 Pro搭载的A18 Pro芯片采用台积电3nm工艺,晶体管数量为220亿个晶体管。
摩尔定律在显卡中的体现:
| 年份 | 代表显卡 | 工艺制程 | 晶体管数量 | 特点 |
|---|---|---|---|---|
| 2006 | NVIDIA G80(8800GTX) | 90nm | 6.8 亿 | 第一个支持 CUDA 的 GPU |
| 2012 | GTX 680(Kepler) | 28nm | 35 亿 | 功耗控制好,游戏主力 |
| 2020 | RTX 3080(Ampere) | 8nm | 280 亿 | 实时光追,AI加速 |
| 2022 | RTX 4090(Ada Lovelace) | 4nm | 763 亿+ | 超强 AI、超高功耗 |
从几亿到几百亿晶体管,GPU 的“密度进化”正是摩尔定律的真实体现。
近年来,人们常说摩尔定律“失效”了,原因包括:
-
物理极限逼近:晶体管尺寸接近原子级,继续缩小越来越难。
-
成本急剧上升:先进制程如 3nm 的制造成本是天价。
-
散热与功耗问题严重:晶体管太密,功耗暴涨,难以控制温度。
所以今天的摩尔定律,不再是“1.5年翻一番”,而可能是 3~4 年才有较大的提升。
二、CPU的工作原理:一个小指令的大旅程
CPU的本质就是一个超高速执行指令的机器。无论你在打游戏还是刷网页,背后都有CPU在执行一条条指令。从你点击鼠标的一瞬间开始,到屏幕出现反应,中间可能执行了数十亿条底层指令。
2.1 基本组成
CPU通常由以下核心模块组成:
- 算术逻辑单元(Arithmetic Logic Unit, ALU)
- 控制单元(Control Unit, CU)
- 寄存器(Registers)
- 高速缓存(Cache)
- 总线接口(Bus Interface)
- 时钟(Clock)
- 7. 内存映射单元(Memory Management Unit,MMU)
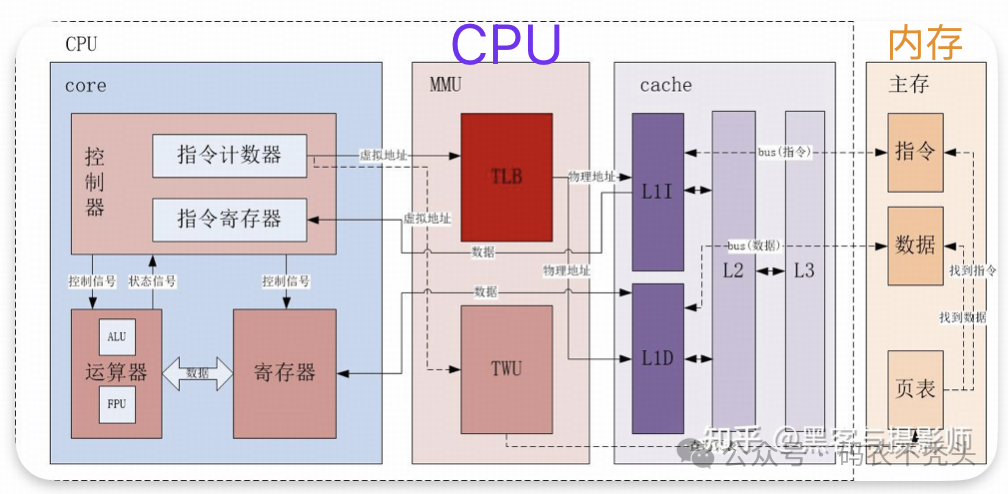
2.1.1. 算术逻辑单元(ALU)
运算器是一个负责算术运算和逻辑运算的模块,主要包含算术逻辑单元(Arithmetic Logic Unit,简称ALU)和浮点运算单元(Floating Point Unit,简称FPU)。ALU的主要功能:在控制信号的作用下,完成加、减、乘、除等算术运算,以及与、或、非、异或等逻辑运算以及移位、补位等运算。通常ALU由两个输入端和一个输出端(两个值输入,一个结果输出)。FPU主要负责浮点运算和高精度整数运算。有些FPU还具有向量运算的功能,另外一些则有专门的向量处理单元。
2.1.2. 控制单元(CU)
控制器又称为控制单元(Control Unit,简称CU),是计算机的指挥中心,只有在它的控制下,整个CPU才能够有条不紊地工作、自动执行程序。CU包括指令寄存器、指令计数器,其中指令寄存器存放当前正在执行的指令,指令计数器总是指向下一条要执行指令的地址。CU的工作流程为:从内存中取指令、翻译指令、分析指令。然后根据指令的含义,向有关部件发送控制命令,控制相关部件,执行指令所包含的操作。具体的指令执行过程如下:CU通过指令计数器,获取下一条将要执行指令的地址,通过该地址获取具体的指令,存放在指令寄存器,然后对该指令解码,如果是一个add(加法指令),会通过将寄存器中的值加载到运算器,其中寄存器中的值是从cache或者主存中获取的,经过运算器的运算产生进位、溢出等信号反馈给控制器,产生的结果也存放在寄存器中。
2.1.3. 寄存器(Registers)
寄存器的主要功能是存储数据、地址及指令,并且能够高速、自动地完成数据的存储。寄存器是有记忆功能的器件,而且采用两种稳定状态0或1来记录数据信息,所以CPU中的程序和数据,都要转换为二进制才可以存储和操作。寄存器也是由与、或、非逻辑门电路组成的。相比内存,寄存器的访问速度更快,提升 CPU 的整体性能。
主要类型:
通用寄存器(General-Purpose Registers): 用于存储临时数据和运算结果
特殊寄存器(Special-Purpose Registers):
程序计数器(Program Counter, PC):存储下一条指令的地址。
指令寄存器(Instruction Register, IR):存储当前正在执行的指令。
状态寄存器(Status Register):存储运算结果的状态标志,如零标志、进位标志、溢出标志等。
关于寄存器更详细的原理,请看寄存器的组成原理
2.1.4. 高速缓存(Cache)
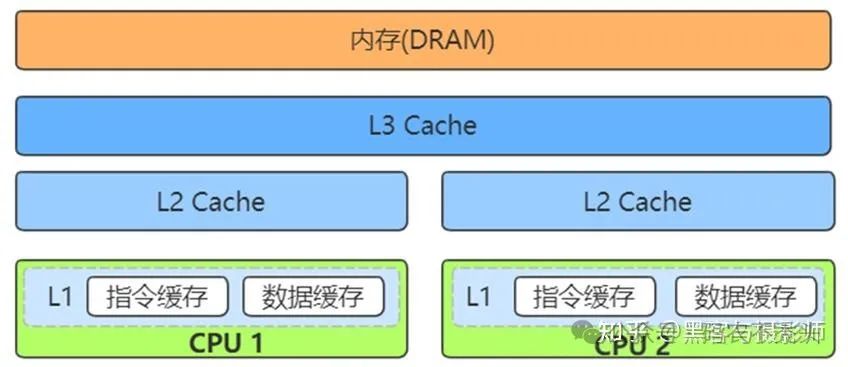
缓存是位于 CPU 和主存之间的高速存储,用于存储频繁访问的数据和指令。
通过缓存机制,减少 CPU 等待数据从主存加载的时间,极大提升数据访问速度。
一级缓存(L1 Cache):速度最快,容量最小,通常集成在 CPU 核心内部。
二级缓存(L2 Cache):速度较快,容量适中,可以集成在 CPU 核心内部或外部。
三级缓存(L3 Cache):容量较大,速度较慢,通常共享于多个核心。
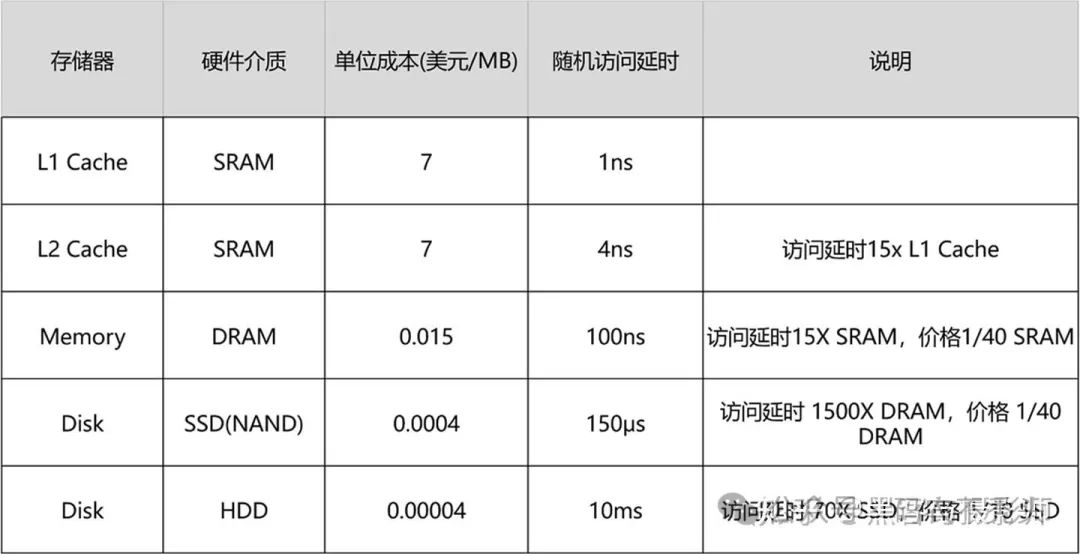
现代计算机或嵌入式系统的存储设备,一般有 Cache、内存、SSD、HDD硬盘。这些存储设备越靠近 CPU 速度越快,容量越小,价格越贵。
寄存器(Register):寄存器与其说是存储器,其实更像是 CPU 本身的一部分,只能存放极其有限的信息,但是速度非常快,和CPU同步。
高速缓存(CPU Cache):使用静态随机存取存储器(Static Random-Access Memory,简称SRAM)的芯片。
内存(DRAM):使用动态随机存取存储器(Dynamic Random Access Memory,简称DRAM)的芯片,比起 SRAM 来说,它的密度更高,有更大的容量,而且它也比 SRAM 芯片便宜不少。
硬盘:如固态硬盘(Solid-state drive 或 Solid-state disk,简称SSD)、硬盘(Hard Disk Drive,简称HDD)。
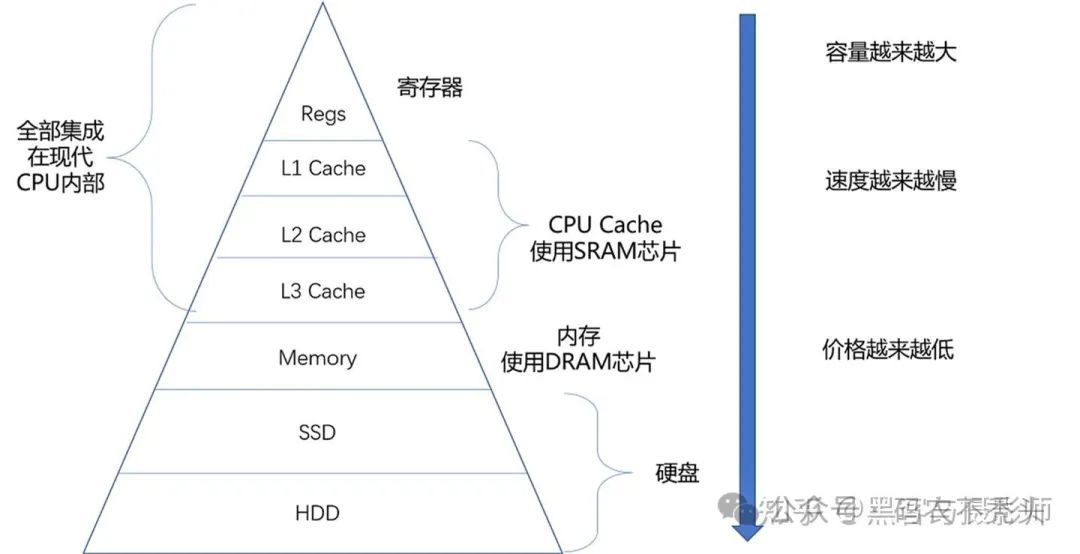
每一种存储器设备,只和它相邻的存储设备打交道。比如,CPU Cache是从内存里加载而来的,或者需要写回内存,并不会直接写回数据到硬盘,也不会直接从硬盘加载数据到CPU Cache中,而是先加载到内存,再从内存加载到Cache中。
可以看出,越是速度快的设备,容量就越小。这里一共 10M 的 Cache,成本只是几十美元。而 8GB 的内存、128G 的 SSD 以及 1T 的 HDD,大概零售价格加在一起,也就和我们的高速缓存的价格差不多。
2.1.5. 总线接口(Bus Interface)
虽然从上面的框图上,不能直观地看到BUS总线的存在,但是地址、数据的传输都是依赖总线完成的。它就像一条高速公路,快速完成各个单元间的数据交换,也是数据从内存流进和流出CPU的地方。CPU总线(前端总线)传输速率,决定着CPU与内存之间传输数据的速度快慢。CPU总线速率越高,CPU从内存取指令和数据的等待时间越少,运行程序速度越快。总线又细分成数据总线、地址总线和控制总线。总线的工作原理也很复杂繁琐,感兴趣的评论区留言,可以考虑出一篇博客来讲总线的工作原理
2.1.6. 时钟(Clock)
功能:
同步操作:提供统一的时钟信号,确保 CPU 各部分按固定频率工作。
时序管理:控制指令执行的各个阶段(取指、译码、执行、访存、写回)的时序。
特点:
时钟频率:以赫兹为单位,决定了 CPU 每秒可以执行的时钟周期数。
相位:时钟信号的上升沿和下降沿用于触发不同的操作。
2.1.7 MMU
内存映射单元(Memory Management Unit,简称MMU),指的是将虚拟地址转化成物理地址的模块。MMU包含了两个模块:页表查找表(Table Lookup Buffer,简称TLB)和页表遍历单元(Table Walk Unit,简称TWU)。TLB是一个高速缓存,用于缓存页表转换的结果,从而减少页表查询的时间。一个完整的页表翻译和查找的过程叫做页表查询,页表查询是通过硬件模块TWU自动完成的,但是页表的维护需要软件来完成,且存放在主存中,因此页表查询是一个耗时的过程。当TLB未命中时,MMU才会通过TWU查询页表,从而得到翻译后的物理地址,这个虚拟地址及物理地址的映射,也会存储在TLB中。
2.2 CPU 的工作流程(取指-译码-执行)
CPU 的工作流程通常分为以下几个阶段:
取指(Fetch)
译码(Decode)
执行(Execute)
访存(Memory Access)
写回(Write Back)
取指 (Fetch) → 解码 (Decode) → 执行 (Execute) → 访存 (Memory Access)→ 写回 (Write Back)
1)取指
取指令(Instruction Fetch,简称IF)阶段是将一条指令从cache或主存中,获取指令到指令寄存器的过程。CPU中有一个程序计数器(Program Counter,简称PC)寄存器,其中保存着将要执行指令的地址。指令读取是通过将PC寄存器的值,输出给cache或者内存,然后由cache或内存返回该值对应地址中的指令。当一条指令被取出后,PC中的数值将根据指令字长度自动递增。
2) 译码
取出指令后,CPU会立即进入指令译码(Instruction Decode,简称ID)阶段。在指令译码阶段,指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别,以及各种获取操作数的方法。指令有很多种,有进行各种运算的指令、控制下一条命令的指令、对内存进行读写的命令,还有对CPU进行控制的指令。
3) 执行
在取指令和指令译码阶段之后,接着进入执行指令(Execute,简称EX)阶段。此阶段的任务是完成指令所规定的各种操作,实现具体指令的功能。为此,CPU的不同部分的组件被连接起来,以执行所需的操作。例如,执行一个加法运算,ALU将会连接到一组输入和一组输出。输入提供了要进行相加运算的数值,而输出求和后的结果。如果加法运算产生一个,对该CPU处理而言过大的结果,在标志暂存器里,运算溢出(Arithmetic Overflow,简称AO)标志可能会被设置。
4) 访存
根据指令需要,有可能要访问主存,读取操作数,这样就进入了访存取数的阶段。此阶段的任务是:根据指令中的地址码,经过MMU将虚拟地址转化成物理地址,根据物理地址得到操作数,在cache或主存中的地址,并从cache或主存中读取该操作数用于运算。
5) 写回
结果写回(Write Back,简称WB)阶段,一般把执行指令阶段的运行结果数据,写回到内部寄存器中,以便被后续的指令快速地存取。在有些情况下,结果数据也可被写入相对较慢,但较廉价且容量较大的主存。许多指令还会改变程序状态寄存器中标志位的状态,这些标志位标识着不同的操作结果,可被用来影响程序的动作。在指令执行完毕、结果数据写回之后,若无意外事件(如结果溢出等)发生,CPU就接着从程序计数器PC中取得下一条指令地址,开始新一轮的循环,下一个指令周期将顺序取出下一条指令。
2.3 CPU中断流程
之前我们的计算机都是单核的,那么我们同时运行多个APP,也就是多个进程,计算机好像也是在并行运行,实际上不是,计算机同时只能运行一个进程,这就是所谓的CPU中断,CPU根据时钟周期来切换执行,因为时钟周期非常短,通常只有几微秒(现代计算机的时钟周期已经在纳秒级了),根本感知不到,因此就感觉你在聊微信的同时还在写刷剧,是并行的,但实际不一定是并行的,现在基本上都是多核,但即使是多核,最多一核同时处理一个进程。
CPU中断切换的过程如下:
-
保存PC:保存当前的 PC 的值到内存的某个位置
-
修改PC:修改 PC 的值,让执行其他执行流
-
还原PC:其他执行流执行结束之后,通过将刚才保存的 PC 值恢复到 PC 寄存器
-
继续原执行流:继续中断前的执行流
3.现代 CPU 的高级特性
超标量架构:允许在一个时钟周期内执行多条指令,通过多个执行单元并行处理。
乱序执行:指令可以不按照程序顺序执行,以优化资源利用和提升性能。
分支预测:预测程序中的分支走向,减少流水线停顿和指令重排。
超线程技术:允许每个物理核心同时处理多个线程,提高多任务处理能力。
向量处理单元:专门用于处理向量指令,提高科学计算和图形处理性能。
节能技术:动态调整功耗和性能,如动态电压频率调整(DVFS)、休眠模式等。
4.总结
CPU 作为计算机系统的核心,承担着指令执行和数据处理的关键任务。其基本结构包括算术逻辑单元(ALU)、控制单元(CU)、寄存器、高速缓存(Cache)、总线接口和时钟等组成部分。通过这些部件的协同工作,CPU 能够高效地执行各种计算任务。
现代 CPU 的设计不断融合新技术和优化方法,如超标量架构、乱序执行、多核设计、异构计算等,以应对日益增长的计算需求和性能挑战。同时,功耗管理、制造工艺和指令集架构的选择也在影响着 CPU 的发展方向。
理解 CPU 的基本结构和工作原理,对于深入学习计算机体系结构、优化软件性能以及设计高效的硬件系统具有重要意义。随着技术的不断进步,CPU 的设计和功能将持续演化,以满足未来计算需求的多样化和复杂化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









