






1.背景
随着AI大模型的火爆,向量数据库也越来越受欢迎,不止Elasticsearch在向量搜索上快速迭代,Redis 最近也推出向量集合(Vector Set) 功能,这是一种专为向量相似性设计的数据类型,也是 Redis 针对人工智能应用的一个新的选项。这是 Redis 创始人 Salvatore Sanfilippo(“antirez”)自 重新加入 公司以来的第一个重大贡献。
向量集合 是一种类似于有序集合(Sorted Set)的数据类型,不一样的是它将字符串元素与向量(而不是分数)关联起来,可以添加项目并检索与指定向量最相似的子集。它还支持过滤搜索功能,允许同时进行向量相似性和标量过滤。Sanfilippo 在他的博客中解释道:
简单来说,这个新的数据结构的目标是创建一种类似于有序集合的“集合类”数据类型,但分数是一个向量而不是标量。你可以像使用普通 Redis 数据结构一样添加和删除元素,无需担心其他问题,只需关注 Redis 抽象数据结构本身的特性即可。你可以查询与给定向量(或集合中已有的某个元素的向量)相似的元素,等等。
2.向量搜索基础理论
向量搜索的理念是:“如果我们能够将数据库中的项目以及输入的查询词表示为向量,那么我们就可以找到最接近输入的向量。”
向量 Vectors
可以将向量理解为从空间中的一个点到另一个点的移动。例如,在下图中,我们可以看到一些二维空间中的向量:
a是一个从 (100, 50) 到 (-50, -50) 的向量,b 是一个从 (0, 0) 到 (100, -50) 的向量。
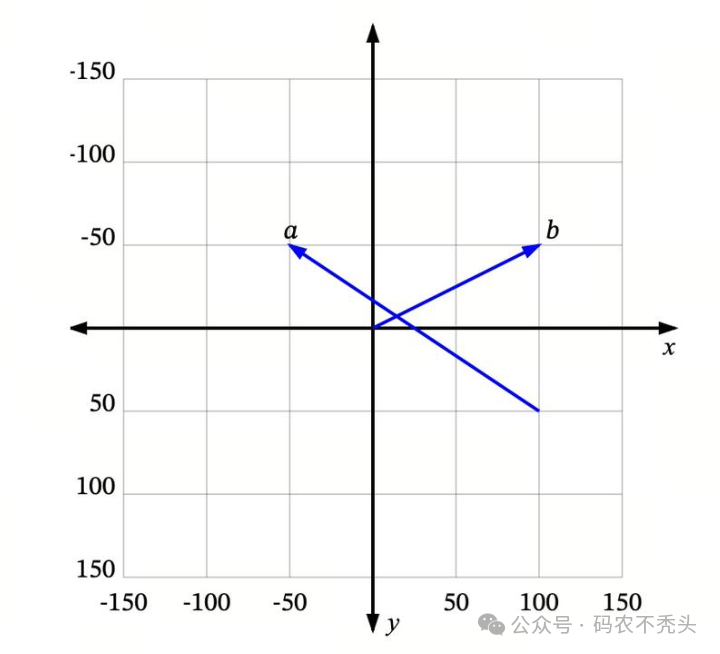
很多时候(在本文的其余部分也是如此),我们处理的向量是从原点 (0, 0) 开始的,比如b。这样我们可以省略“从哪里开始”的部分,直接说 b 是向量 (100, -50)。
如何将向量的概念扩展到非数值实体上呢?
维度 Dimensions
如我们所见,每个数值向量都有 x 和 y 坐标(或者在三维系统中是 x、y、z,等等)。x、y、z... 是这个向量空间的轴,或称为维度。对于我们想要表示为向量的一些非数值实体,我们首先需要决定这些维度,并为每个实体在每个维度上分配一个值。
例如,在一个车辆数据集中,我们可以定义四个维度:“轮子数量”、“是否可以在地上开动”、“是否有发动机”和“最大乘员数”。然后我们可以将一些车辆表示为:
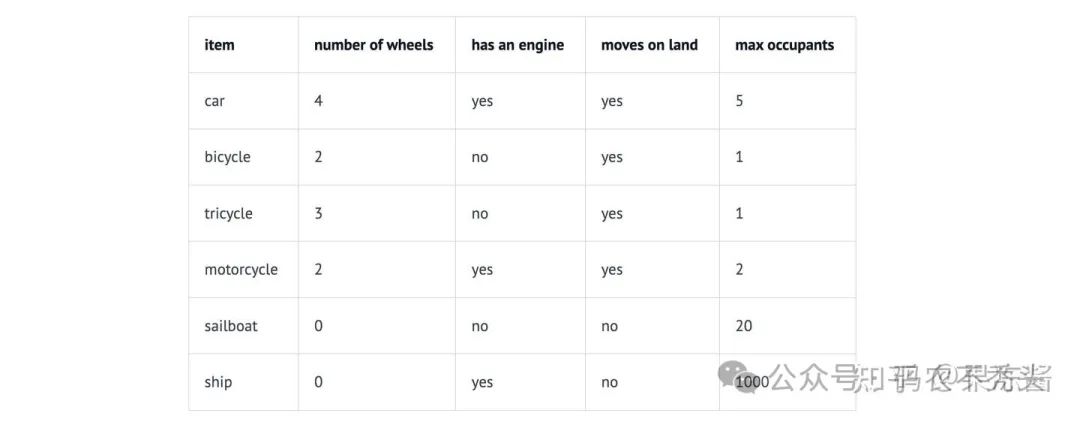
因此,我们的汽车Car向量将是 (4, yes, yes, 5),或者用数值表示为 (4, 1, 1, 5)(将 yes 设为 1,no 设为 0)。
维度是我们用来(试图)捕捉实体语义意义并用数字表示的一种方式。它们是主观的。没有规定必须选择这些特定的维度。我们可以使用“是否有翅膀”、“是否使用柴油”、“最高速度”、“平均重量”、“价格”等等。
维度也称为特征或方面。它们是向量搜索(以及数据科学/机器学习)中极其重要的一部分。我们很快会看到维度的数量和选择如何影响搜索。
相似度 Similarity
在向量搜索中,我们希望根据与搜索词的相似度返回结果。例如,如果用户搜索“汽车Car”,你希望能够返回提到“汽车automobile”与“车辆vehicle”的结果。向量搜索是一种实现这一目标的方法。
向量搜索还被用于推荐系统。例如,根据用户已经喜欢的内容推荐类似的产品、文章、节目或歌曲。在这种情况下,输入已经是数据集的一部分。
那么,如何确定哪些是最相似的?
必须首先定义“相似”是什么意思。每个向量都有一个大小(也称为长度或大小)和方向。例如,在这个图中,p 和
a 指向相同的方向,但长度不同。p 和 b 正好指向相反的方向,但有相同的大小。然后还有c,长度比p短一点,方向不完全相同,但很接近。
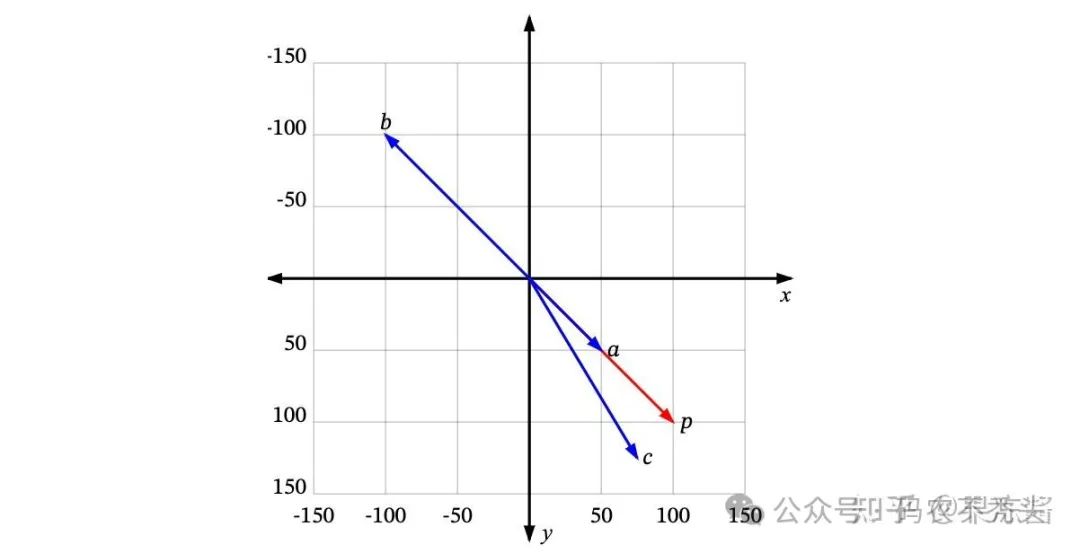
那么,哪一个最接近 p 呢?
如果“相似”仅仅意味着指向相似的方向,那么a 是最接近 p 的。接下来是 c。b 是最不相似的,因为它正好指向与p 相反的方向。如果“相似”仅仅意味着相似的大小,那么 b 是最接近 p 的(因为它有相同的长度),接下来是 c,然后是 a。
在向量搜索中,我们很少只看大小。这是因为你可以轻易地得到一个在每个维度上值完全不同但整体长度相同的向量(例如,b 和 p 的长度相同,但方向正好相反)。由于向量通常用于描述语义意义,仅仅看长度通常无法满足需求。大多数相似度测量要么仅依赖于方向,要么同时考虑方向和大小。
相似度测量 Measures of similarity
四种常见的向量相似度计算方法:
- 欧几里得距离 Euclidean distance
:两个向量“尖端”之间的直接距离。当两个向量相同时,欧几里得距离为 0,当任一向量的角度(方向)或大小(长度)增加时,距离增加。因此,对于一个向量 p,我们可以计算到所有其他向量的距离,并选择距离最小的那个。
- 曼哈顿距离 Manhattan distance
:这也是“尖端”之间的距离,但假设你只能沿着坐标轴平行移动(左、右、上、下)。
- 点积 Dot product
:通过将向量的相应维度相乘并求和来得到。 这是一个有用的公式,因为它利用了两个向量的维度,意味着它同时考虑了方向和大小。例如:
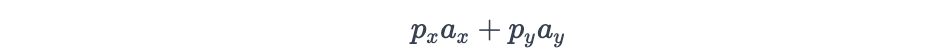
4. 余弦相似度Cosine similarity:通过计算两个向量之间的角度的余弦值来工作(这意味着余弦相似度只考虑方向,不考虑大小)。我们通过将点积除以两个长度的乘积来得到,即:
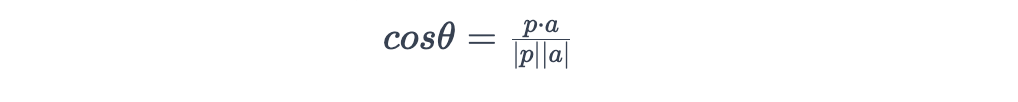
这个图展示了向量 ppp 和另一个向量 aaa 之间的四种相似度测量。如果拖动向量的尖端来重新定位它们,可以观察到数值的变化。(可以尝试的操作包括:将向量放置在彼此垂直的位置,将它们直接放置在彼此对立的位置,或者使它们具有相同的大小)。(拖动操作可以在原文[1]中尝试)
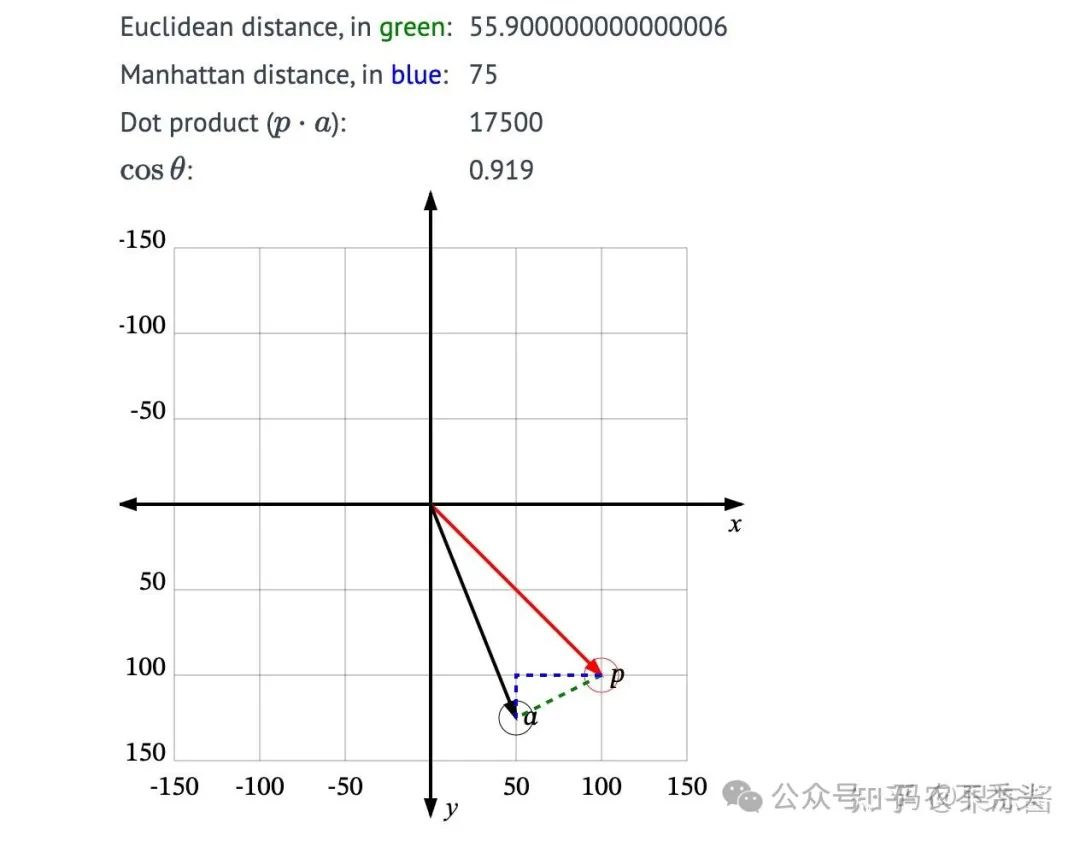
从中我们可以看到这些度量的一些有用的事实以及如何选择:
欧几里得距离:如果向量完全相同,欧几里得距离为 0。当其中一个向量的大小或它们之间的角度发生变化时,距离会无限增加。这可能是最直接的度量(数值较小 = 更相似),并且使用非常普遍。曼哈顿距离的行为类似(相等时为 0,然后增加)。
点积:当两个向量相等时,点积从某个数值(非 0)开始。如果保持两个向量的大小相等,并增加角度,点积会减少,当两个向量呈直角时,点积为 0。继续增加角度,点积会减少直到两个向量完全相反,然后再次增加,直到回到开始的位置。另一方面,如果在保持角度不变的情况下增加 aaa 的大小,点积会不断增加。
这种不均匀的分布使得点积使用起来更复杂(没有最大值;较小的点积可能意味着更不相似或更相似)。它也不是唯一的;有多个不同的位置可以使得 aaa 的点积与 a=p 时相同。点积通常只有在我们能够将所有向量归一化为相同长度时才有意义(此时,它等于余弦相似度)。
余弦相似度:仅仅考虑两个向量之间的角度(更准确地说,是角度的余弦值)。这意味着结果始终在 1 和 -1 之间,而点积可以是任意数值。余弦值为 1 当向量完全相同时;当向量呈直角时余弦值降至 0;当它们完全相反时为 -1。这个特性很整洁。它的缺点是它不考虑向量的大小——对于指向某个方向的所有向量,余弦值是相同的,不论它们的长度。因此,余弦相似度通常只在数据集中所有向量长度相同时使用,或者我们不关心它们的长度。
余弦相似度的第二个缺点是计算开销更大。要计算点积,你需要将每个向量的维度相乘并求和。要计算余弦相似度,你还需将点积除以两个向量长度的乘积。这看起来不是什么大问题,但在大型数据库中,成千上万的向量,每个向量有数百或数千个维度,这会占用大量 CPU 时间。这就是为什么 Elasticsearch 推荐使用点积,并将所有向量归一化为相同长度。
那么你如何选择使用哪种度量呢?实际上,这取决于了解你的数据,并进行实验以查看哪种方法能给你带来最佳结果。从互联网上了解到的判断依据:
- 欧几里得距离
是一个“安全”的默认选择,当你对数据了解不多时可以使用。
-
如果所有向量具有相同的长度(或可以归一化为相同长度),那么余弦相似度/点积可能是一个不错的选择。
-
如果向量的维度非常高,曼哈顿距离 可能是更好的度量方法。
3.redis向量检索(Vector Search)的核心原理
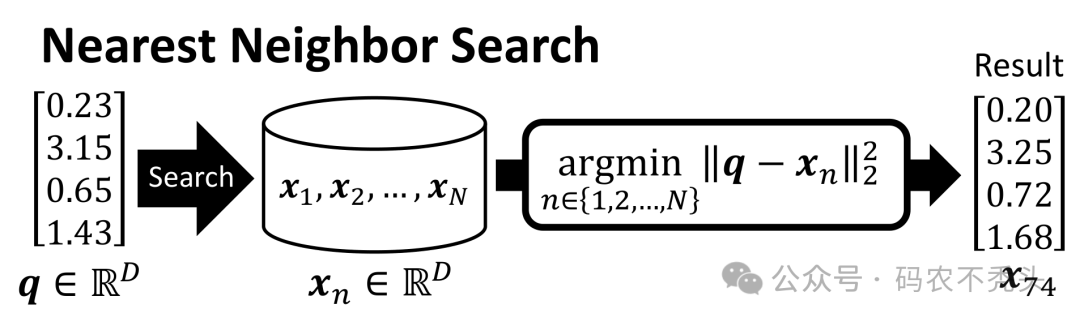
3.1. 向量化数据:
当你将 JSON 中的字段存入 Redis 时,向量化工具(例如 vectorStore)会将指定的字段转换为高维向量。每个字段的内容会通过某种嵌入模型(如 Word2Vec、BERT、OpenAI Embeddings 等)转换成向量表示。每个向量表示的是该字段内容的语义特征。
3.2. 搜索时的向量生成:
当执行 SearchRequest.query(message) 时,系统会将输入的 message 转换为一个查询向量。这一步是通过同样的嵌入模型,将查询文本转换为与存储在 Redis 中相同维度的向量。
3.3. 相似度匹配:
vectorStore.similaritySearch(request) 函数使用了一个向量相似度计算方法来查找最相似的向量。这通常是通过 余弦相似度 或 欧几里得距离 来度量查询向量和存储向量之间的距离。然后返回与查询最相似的前 K 个文档,即 withTopK(topK) 所指定的 K 个最相关的结果。
3.4. 返回匹配的文档:
匹配的结果是根据相似度得分排序的 List<Document>。这些文档是你最初存储在 Redis 中的记录,包含了 JSON 中指定的字段。
3.使用Spring Boot集成Redis向量数据库实现相似性搜索
实验目标
实现文件数据向量化到redis,并进行相似性搜索
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<projectxmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.1</version>
<relativePath /><!-- lookup parent from repository -->
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>RedisVectorStore</artifactId>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<spring-ai.version>0.8.1</spring-ai.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-transformers-spring-boot-starter</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-redis-spring-boot-starter</artifactId>
<version>${spring-ai.version}</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.1.0</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</pluginRepository>
</pluginRepositories>
</project>
controller
package com.et.controller;
import com.et.service.SearchService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.et.service.SearchService;
import java.util.HashMap;
import java.util.Map;
@RestController
publicclassHelloWorldController{
@Autowired
SearchService searchService;
@RequestMapping("/hello")
public Map<String, Object> showHelloWorld(){
Map<String, Object> map = new HashMap<>();
map.put("msg", searchService.retrieve("beer"));
return map;
}
}
configuration
初始化redis向量数据
JsonReader loader = new JsonReader(file, KEYS);
JsonReader 和 VectorStore 实现是将 KEYS 中指定的多个字段拼接在一起,生成一个统一的文本表示,然后通过嵌入模型将这些字段的组合文本转换为一个单一的向量,那么这里就是将多个字段组合成一个综合向量,并将其处理后存入 Redis。
package com.et.config;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.autoconfigure.vectorstore.redis.RedisVectorStoreProperties;
import org.springframework.ai.reader.JsonReader;
import org.springframework.ai.vectorstore.RedisVectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.core.io.InputStreamResource;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Component;
import java.util.Map;
import java.util.zip.GZIPInputStream;
@Component
publicclassDataLoaderimplementsApplicationRunner{
privatestaticfinal Logger logger = LoggerFactory.getLogger(DataLoader.class);
privatestaticfinal String[] KEYS = { "name", "abv", "ibu", "description" };
@Value("classpath:/data/beers.json.gz")
private Resource data;
privatefinal RedisVectorStore vectorStore;
privatefinal RedisVectorStoreProperties properties;
publicDataLoader(RedisVectorStore vectorStore, RedisVectorStoreProperties properties){
this.vectorStore = vectorStore;
this.properties = properties;
}
@Override
publicvoidrun(ApplicationArguments args)throws Exception {
Map<String, Object> indexInfo = vectorStore.getJedis().ftInfo(properties.getIndex());
Long sss= (Long) indexInfo.getOrDefault("num_docs", "0");
int numDocs=sss.intValue();
if (numDocs > 20000) {
logger.info("Embeddings already loaded. Skipping");
return;
}
Resource file = data;
if (data.getFilename().endsWith(".gz")) {
GZIPInputStream inputStream = new GZIPInputStream(data.getInputStream());
file = new InputStreamResource(inputStream, "beers.json.gz");
}
logger.info("Creating Embeddings...");
// tag::loader[]
// Create a JSON reader with fields relevant to our use case
JsonReader loader = new JsonReader(file, KEYS);
// Use the autowired VectorStore to insert the documents into Redis
vectorStore.add(loader.get());
// end::loader[]
logger.info("Embeddings created.");
}
}
配置redis vectorStore
package com.et.config;
import org.springframework.ai.autoconfigure.vectorstore.redis.RedisVectorStoreProperties;
import org.springframework.ai.chat.ChatClient;
import org.springframework.ai.document.MetadataMode;
import org.springframework.ai.transformers.TransformersEmbeddingClient;
import org.springframework.ai.vectorstore.RedisVectorStore;
import org.springframework.ai.vectorstore.RedisVectorStore.RedisVectorStoreConfig;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
publicclassRedisConfiguration{
@Bean
TransformersEmbeddingClient transformersEmbeddingClient(){
returnnew TransformersEmbeddingClient(MetadataMode.EMBED);
}
@Bean
VectorStore vectorStore(TransformersEmbeddingClient embeddingClient, RedisVectorStoreProperties properties){
var config = RedisVectorStoreConfig.builder().withURI(properties.getUri()).withIndexName(properties.getIndex())
.withPrefix(properties.getPrefix()).build();
RedisVectorStore vectorStore = new RedisVectorStore(config, embeddingClient);
vectorStore.afterPropertiesSet();
return vectorStore;
}
}
查询service
查询时,查询文本也会生成一个整体向量,与存储的综合向量进行匹配。
package com.et.service;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class SearchService{
@Value("${topk:10}")
privateint topK;
@Autowired
private VectorStore vectorStore;
public List<Document> retrieve(String message){
SearchRequest request = SearchRequest.query(message).withTopK(topK);
// Query Redis for the top K documents most relevant to the input message
List<Document> docs = vectorStore.similaritySearch(request);
return docs;
}
}
5.测试
启动Spring Boot应用程序,查看日志
___ ____ /\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \ ( ( )\___ | '_| '_|| '_ \/ _` | \ \ \ \ \\/ ___)| |_)| || || || (_|| ) ) ) ) ' |____| .__|_| |_|_||_\__, | / / / / =========|_|==============|___/=/_/_/_/ :: Spring Boot :: (v3.2.1) 2024-09-24T14:03:48.217+08:00 INFO 23996 --- [ main] com.et.DemoApplication : Starting DemoApplication using Java 17.0.9 with PID 23996 (D:\IdeaProjects\ETFramework\RedisVectorStore\target\classes started by Dell in D:\IdeaProjects\ETFramework) 2024-09-24T14:03:48.221+08:00 INFO 23996 --- [ main] com.et.DemoApplication : No active profile set, falling back to 1 default profile: "default" 2024-09-24T14:03:49.186+08:00 INFO 23996 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port 8088 (http) 2024-09-24T14:03:49.199+08:00 INFO 23996 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat] 2024-09-24T14:03:49.199+08:00 INFO 23996 --- [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.17] 2024-09-24T14:03:49.289+08:00 INFO 23996 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext 2024-09-24T14:03:49.290+08:00 INFO 23996 --- [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 1033 ms 2024-09-24T14:03:49.406+08:00 WARN 23996 --- [ main] ai.djl.util.cuda.CudaUtils : Failed to detect GPU count: CUDA driver version is insufficient for CUDA runtime version (35) 2024-09-24T14:03:49.407+08:00 WARN 23996 --- [ main] ai.djl.util.cuda.CudaUtils : Failed to detect GPU count: CUDA driver version is insufficient for CUDA runtime version (35) 2024-09-24T14:03:49.408+08:00 INFO 23996 --- [ main] ai.djl.util.Platform : Found matching platform from: jar:file:/D:/jar_repository/ai/djl/huggingface/tokenizers/0.26.0/tokenizers-0.26.0.jar!/native/lib/tokenizers.properties 2024-09-24T14:03:49.867+08:00 INFO 23996 --- [ main] o.s.a.t.TransformersEmbeddingClient : Model input names: input_ids, attention_mask, token_type_ids 2024-09-24T14:03:49.867+08:00 INFO 23996 --- [ main] o.s.a.t.TransformersEmbeddingClient : Model output names: last_hidden_state 2024-09-24T14:03:50.346+08:00 INFO 23996 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port 8088 (http) with context path '' 2024-09-24T14:03:50.354+08:00 INFO 23996 --- [ main] com.et.DemoApplication : Started DemoApplication in 2.522 seconds (process running for 2.933) 2024-09-24T14:03:50.364+08:00 INFO 23996 --- [ main] com.et.config.DataLoader : Creating Embeddings... 2024-09-24T14:03:51.493+08:00 WARN 23996 --- [ main] ai.djl.util.cuda.CudaUtils : Failed to detect GPU count: CUDA driver version is insufficient for CUDA runtime version (35) 2024-09-24T14:03:51.800+08:00 INFO 23996 --- [ main] ai.djl.pytorch.engine.PtEngine : PyTorch graph executor optimizer is enabled, this may impact your inference latency and throughput. See: https://docs.djl.ai/docs/development/inference_performance_optimization.html#graph-executor-optimization 2024-09-24T14:03:51.802+08:00 INFO 23996 --- [ main] ai.djl.pytorch.engine.PtEngine : Number of inter-op threads is 6 2024-09-24T14:03:51.802+08:00 INFO 23996 --- [ main] ai.djl.pytorch.engine.PtEngine : Number of intra-op threads is 6 2024-09-24T14:04:26.212+08:00 INFO 23996 --- [nio-8088-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet'
查看redis是否存在向量化的数据
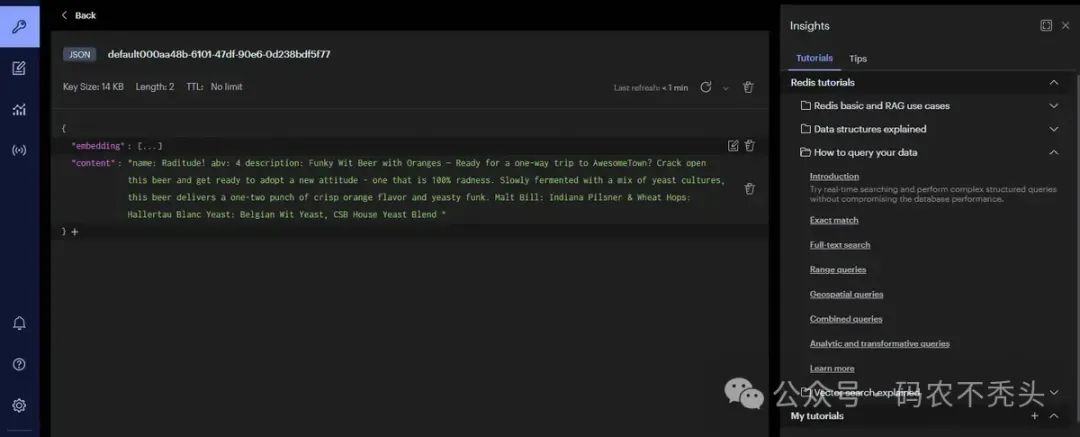
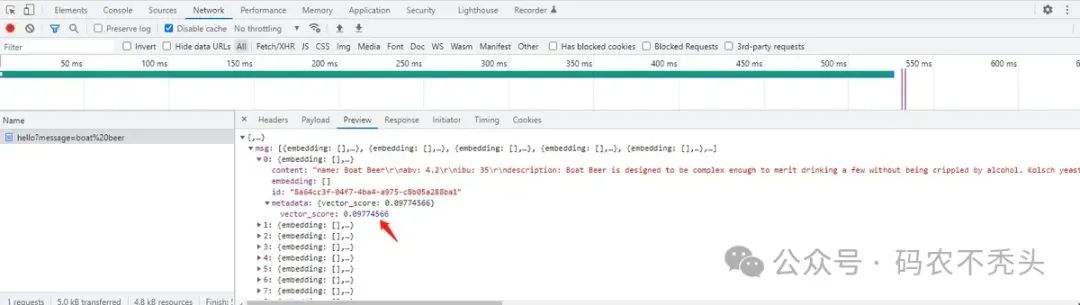
访问http://127.0.0.1:8088/hello 进行0 相似度搜索(top 10),返回得分前10的数据

















 911
911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









