







一、递归神经网络
1、什么是递归神经网络
递归神经网络是两类人工神经网络的总称,分为是时间递归神经网络(Recurrent Neural Network)和结构递归神经网络(Recursive Neural Network)。前者也可叫循环神经网络。RNN网络在传统神经网络的基础上加入了“记忆”成分。
之前的一些神经网络模型中,假设训练数据之间是相互独立的,但是许多实际应用中,数据之间是相互依赖的,比如在时间序列相关的输入场景下,信息之间的传递更多的是一种相互传承的关系。再比如在空间结构场景中,数据之间存在空间的组合关系,可以将整体数据划分为局部的小结构,由局部的小结构推导出整体的性质。
2、RNN
下面使用RNN的时候,一般指代的是时间递归神经网络(Recurrent Neural Network)。其处理的对象是一种时间序列数据,它将数据信息流以一种循环的方式进行传递处理。
序列是什么:序列(x1,x2,…,xm)被看做一系列随着时间步长(time step)递进的事件序列。这里的时间步长并不是真实世界中所指的时间,而是指序列中的位置。
RNN的特点:
术语:当前时间步t的输入为xt,它的前缀序列输入数据为(x1,x2,…,xt-1)。
持续性:由于时间序列信息,前后数据不是相互独立,当前阶段的输出不仅和当前的输入有关,还会受到过去的决策影响,所以这是一种持续性,也是单词recurrent的意思。
记忆性:RNN可以保留序列的记忆信息。对于当前时刻t,上一个时刻的状态表示为ht-1,可以说st-1编码记录了xt的前缀序列数据的信息,这就时所谓的记忆性。当对t时刻的输入xt进行计算时,利用持续性,综合当前输入xt和前一时刻的记忆st-1,一起得到t时刻的状态st。比如为了给当前用户推送合适的数据,需要保留用户过去的操作点击行为。这些用户行为记录就是“记忆”。
3 Elman递归神经网络
递归神经网络在网络中出现环形结构,可让一些神经元的输出反馈回来作为输入信号。使得网络在t时刻的输出状态不仅与t时刻的输入有关,还与t-1时刻的网络状态有关,从而能处理与时间有关的动态变化。
Elman网络和前馈网络类似,但隐层神经元的输出被反馈回来,与下一时刻输入层的神经元提供的信号一起作为隐层神经元在下一时刻的输入。

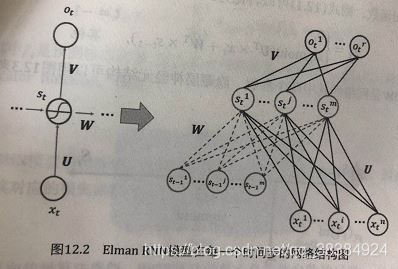
上图为Elman递归神经网络的展开图,通过展开操作,从理论上可以把网络模型拓展为无限维,也就是无限的时间序列。而且可见RNN在每一时间步t都有相同的网络结构。
该网络结构:输入层的神经元个数为n,隐层的神经元数量为m,输出层神经元个数为r。
图中,x是某时间步输入向量(n维),s代表网络隐层的某时间步状态(m维),o代表某时间步的输出向量(r维),输入层与隐层之间由权重矩阵U连接,大小为(nxm)维;W是连接上一时间步的隐层单元与当前时间步的隐层单元的权重矩阵,大小为(mxm)维;V是连接隐藏层与输出层单元的权重矩阵,大小为(mxr)维。
公式形式:RNN的前向传播可以表示为:某一时间步t的情况
个时间步的记忆结果st-1和当前的输入xt共同决定,这些信息保存在隐层中,不断向后传递,跨越多个时间步,影响每一个新输入数据的处理。
下图为一个时间步,时间步t的网络结构图:
最下方是RNN的输入层,用X表示,X = (x0,x1,…,xT),是T+1个时间步的输入向量组成序列,其中xt表示第t时间步的输入数据,xt通常是一个如图的n元向量。
中间部分是网络的隐层,用S(H)表示,S = (s0,s1,…,sT),是T+1个时间步的隐层状态向量组成序列,st也是一个向量,为第t时间步的隐层向量。它是如图所示的m元向量。它是处理记忆信息的地方。
##总结##划重点##:典型的时间递归神经网络Elman,每个时间步都是一个神经网络结构,但是因为加入了时间序列,也就是有了持续性和记忆性。随着时间步的推移,对于某个时间步的网络结构:都有一个输入xt,它是一个n维向量,它就是输入层。都有一个前缀隐层记忆信息st-1,它是个m维向量,它是所谓的记忆信息层。都有隐层st,,st,它一个m为向量,它表示当前隐层的状态。都有一个输出ot,它是个r维向量,它就是输出层。输入层和隐层之间的权重矩阵U,记忆信息层和隐层之间的权重矩阵W,隐层和输出层之间的权重矩阵V。记忆信息层和输入层共同决定当前隐层的状态。随着时间序列的前进,每个时间步都会产生自己的结果。当隐层不止一个的时候,隐层与隐层之间的连接为权重矩阵Y1,Y2。
前向传播过程:对于每个时间步来说,都有当前时刻的输入和传递过来的记忆信息,他们共同作为当前隐层的输入信号,然后当前隐层产生当前的输出和记忆信息。所以可知随着时间序列的前进,每个时间步都会产生自己的输出结果,记忆信息和当前输入共同决定隐层的状态。记忆信息的传递是通过不同时间步隐层之间的连接权重记录的,不断向后传递,跨越多个时间步,影响每一个新输入数据的处理。
(2)时间反向传播BBTT
当使用传统的神经网络进行监督学习的时候,模型训练的本质是最小化损失函数来确定参数的取值。一般采用反向传播BP算法进行参数更新。但是在循环神经网络中,由于循环的存在,参数W,U,V矩阵在计算中共享,这时普通的BP算法无法应用到RNN的训练中。
BPTT算法是BP算法在RNN结构上的一种变体形式,采取在RNN模型的展开式上进行梯度计算。从计算过程看,BPTT与标准反向传播算法基本相同,最主要的差异是由于在RNN网络中,每一时刻计算都共享参数变量W,所以计算梯度的时候,每个时刻的层得到的W的梯度都需要累加在一起,以保证每一层计算所得的误差都得到一定程度的校正,而在传统的神经网络中,每个网络的参数计算都是相互独立的,所以梯度学习也是相互独立的.
缺点:梯度消失,无法保存较远的记忆。
灵活的RNN结构
因为在隐层序列向量定长的时候,输入输出可变长,这种灵活结构的前提是,RNN固有的记忆和持续性。
4 长短时记忆网络LSTM
前提背景:
普通RNN结构只能对距离比较近的时刻的记忆更加强烈,而距离较远则并不清楚。如传统的Elman模型,由于存在梯度消失等缺点,不能有效地保留长时间的记忆信息。数学
解释如下:
RNN结构本质是很多层相同非线性函数的嵌套形式,如果忽略掉激活函数和输入向量,RNN节点的状态ht可以表示为:

若特征值取小于1则会快速降为0,若特征值大于1,快速趋向于无穷。由于权重矩阵W随着时间序列前进被共享,由上图可见,在状态传递过程中相当于W被乘了很多次,到第t个时间步Wt可能只能趋向于0或无穷大了,就是消失或爆炸。导致对于一个时间序列,任何前面发生的时间的记忆都会以指数级的速度被遗忘。
【A】:LTSM基本原理:
长短时记忆网络LSTM是时间递归神经网络的一种变体。整体结构和传统的RNN基本一致,与传统的Elman模型激活层的结构不同,隐藏层的设计更复杂,并有效克服了梯度消失问题。LSTM隐藏层的核心设计是一种叫记忆体(cell state)的信息流,它负责把记忆信息从序列的初始位置传递到序列的末端。通过4个相互交互的“门”单元,控制着在每一时间步t对记忆信息值的修改。
术语介绍:x号是点积操作,因为sigmoid函数取值范围为[0,1],门控制器描述信息能够通过的比例LSTM在某时间步短期记忆单元st的基础上增加了一个长期记忆单元Ct来保持长期记忆。
1、忘记门:忘记门选择保留上一时间步t-1的长期记忆Ct-1的哪些信息进入下一时间步的长期记忆Ct。得到信息保留比例 ft,忘记门通过一个激活函数实现:
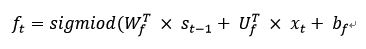
利用激活函数将函数值压缩得到一个大小在(0,1)之间的阈值,当函数值接近1的时候,表示记忆体保留的信息越多,当函数值接近0的时候,表示记忆体丢弃的信息越多。
2、输入门:它决定了当前时间步的输入信息(候选门的信息总量)形成的新记忆C’t中有多少信息将被添加到下一时间步长期记忆Ct中,与忘记门计算公式几乎一致:
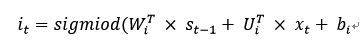
3、候选门:用来计算当前时间步输入xt与上一时间步短期记忆st-1所具有的信息总量,计算如下:
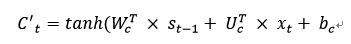
4、输出门:也就是由Ct求解st的过程,控制着当前时间步短期记忆st如何受长期记忆Ct的影响,计算公式:
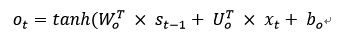
ot是一个大小在(0,1)之间的权重值,这样传递给下一阶段的记忆信息为:
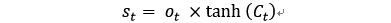
时间序列状态st的更新是靠记忆信息Ct和输出比例ot来决定的,记忆信息流Ct一直处于更新中。
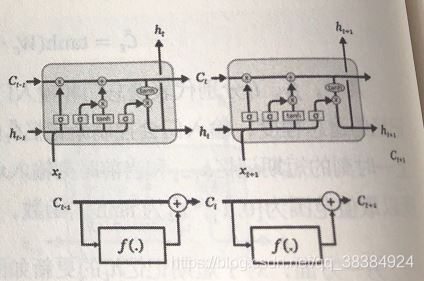
LSTM隐藏层的逻辑设计图:
根据理解,手绘了逻辑图

忘记门将上一时间步的输出信息st-1与当前输入xt进行线性组合后,得到过去记忆Ct-1的信息保留比例 ft,由候选门得到当前输入与过去记忆的信息总量C’t;由输入门得到候选门中的信息总量添加到记忆信息流中的比例it ,;输出门得到更新后得到的记忆Ct用于下一阶段得到st的信息比例。
记忆的更新:由两部分组成,第一部分通过忘记门过滤过去的部分记忆,大小为
ft x Ct-1;第二部分是添加当前的新增数据信息,添加比例由输入门控制,大小为
it x C’t 。 这联股份组合得到更新后的记忆信息Ct:
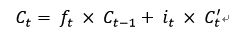
LSTM改进主要体现在通过门控制器增加了对不同时刻记忆的权重控制,加入跨层连接削减梯度消失的影响,在原有结构增加了线性连接,使得长期信息更好传递。
下图为节点级联和其抽象表示:
5 GRU门控制递归单元网络
我们要注意的是下面所说的隐藏层并不是隐层,是将网络结构展开后随着时间序列而得到的一系列隐层组成的,所以也叫隐藏层。
LSTM网络的设计方式多种多样,在实际应用中,隐藏层的“门”的单元设计可能会由于要解决的实际问题不同,在设计上会有细微的差别。
GRU基本原理:在LSTM基础上进行了简化,主要包括下面两个方面的改造:(1)将输入门和忘记门组合成一个新的门单元,成为更新门;(2)将记忆单元Ct与隐藏层单元st结合为一个统一的单元,如图所示:
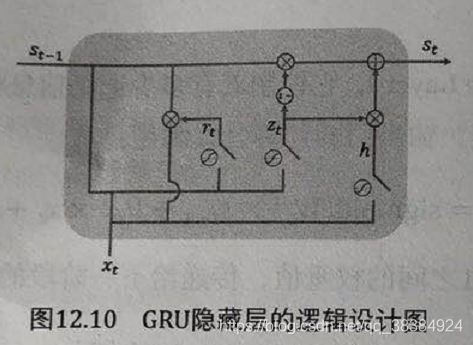
如图:rt是重置门,它的值决定了过去记忆和当前输入的组合方式;zt表示更新门,它控制过去记忆能保存多少;h就是候选门;
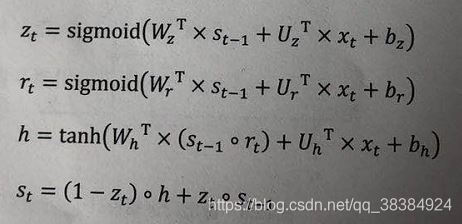















 4542
4542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









