







mysql分享
1:创建表
create table a{
id int not null autoincrement,
name varchar(30) not null,
gmtcreate datetime not null
}engine=innodb charset=utf8 autocrement=999;
创建表的时候,一般要指明使用的引擎以及字符串的格式,另外,对于自增的字段,如果要指定自增开始的数字,可以用如上的写法,否则,从1开始自增。
或者是在表创建完成之后,加上一句来指定自增字段的开始值。
alter table a id auto_increment=999;
2:插入数据
insert into a(name,gmtcreate) values(“lily”,“2021-06-17”),(‘mike’,‘2021-06-20’);
如上,支持逗号分开,批量插入数据,且插入的时候,有自增的字段可以不用填,但是一开始指定列名的时候不要指向插入的字段。
3:删除数据表
drop table a; //删除数据表a,并不保留数据库结构
drop datebase test; //删除test数据库,并都不保留数据库结构
delete from a where name=‘lily’ //删除表a中name=Lily的数据
4:查找数据
1:单表查询
select * from a where name =‘lily’
2:多表联表查询
左联接,右联接,内联接
select * from a left join b on a.id=b.sid;
select * from a right join b on a.id=b.sid;
select * from a inner join b on a.id=b.sid
左联接就是左表的数据+右表对应的字段,如果某条数据,左表有,但是右表没有符合条件的数据,则对应的字段为null补上。
右联接同理,是右表的数据+左表对应的字段,左表有的字段但是右表没有时,则此字段被丢弃。左表没有的字段但是右表有时,则左表对应的列的值为null。
内联接为取得左右表的交集。
3:简单的内联方式
我们知道,用inner join,可以表示内联,但是其实如果不用关键字,用多个逗号隔开,其实这也是内联。
5:union联接结果集
union,可以用于2个及以上select 结果组,将多个结果集集合到一个结果集合中,多个select语句会删除其中重复的语句。
union all:组合结果集,但是不会删除重复的。
可以结合union和concat,进行参数的传参,完成sql语句的拼接之后,提交审批工单。
用union联接sql语句,然后其中一个子句用concat来格式化结果传参
比如:有如下两张表。


查出score为100的学生ID与名字,然后插入到uniqueindex表,这个sql工单语句可以用如下sql执行获取。
select "insert into uniqueindex(`id`,`name`) values" union select concat("(",id,",",student,"),") from score where score=100;
这里解释下上面的sql语句,union前面是取了select后面“”内的sql子句。
union后面“select concat("(",id,",",student,"),") from score where score=100"的执行顺序:先执行select * from score where score=100;在将得到的结果取出id,student字段,并且加上了"(", “,” "),"的字符拼接,得到最后的格式化之后的结果子串。
最后用union将2个子串结合起来,得到最后的结果。
这样得到结果如下。

获取得到的sql结果,将这个sql最后的","去掉,语句末尾加上“;”,即得到对应的sql语句,可以直接进行工单提交。
最终提交的工单sql
insert into uniqueindex(`id`,`name`) values (4,张三),(7,王五);
6:索引
主键索引:一般来说,mysql里面每个主键都会有对应的主键索引。
混合(联合)索引:将多个字段值放在一起,组装成一个索引。
6.1:创建表的时候就创建了索引
create table indextest(
id int not null,
name varchar(32) not null,
gmtcreate datetime not null,
key id_name(id,name) using btree comment’混合索引’
)engine=innodb charset=utf8;
如上,在创建表的时候,就创建了名字是id_name的混合索引,索引的字段是id和name,并且,混合索引以前面的字段是否匹配上为主来判断是否用此索引。
6.2 建完表之后,单独创建索引
1://对表indextest的name字段,建立一个唯一索引。
create index inname on indextest(name);
2:修改表结构(增加一个索引)
alter table inname add index inname(name);
3:删除索引
drop index inname on indextest;
6.3 唯一索引
前面的都是普通索引,普通索引是可以有重复的,
而唯一索引与之的区别就是,索引列的值必须唯一,且可以为空(多个null值不属于重复的)
但是如果是混合唯一索引,name就是组合的列值是唯一的。
6.3.1 添加唯一索引的几种方式
1:在创建表的时候,同步添加唯一索引
create table indextest(
id int not null,
name varchar(32) not null,
gmtcreate datetime not null,
unique key id_name(id,name) using btree comment’混合索引’
)engine=innodb charset=utf8;
2:创建完表之后,单独添加唯一索引
create unique index inname on indextest(name);
3:修改表结构,添加索引
alter table indextest add unique inname(name);
4:用alter来添加索引
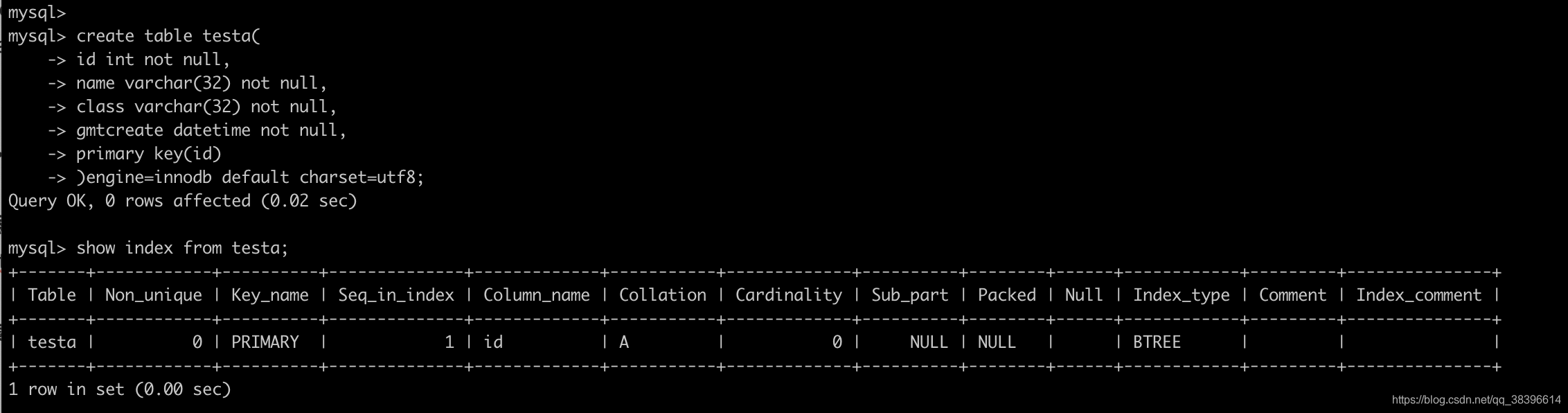
假设有个初始表
create table testa(
id int not null,
name varchar(32) not null,
class varchar(32) not null,
gmtcreate datetime not null,
)engine=innodb default charset=utf8;
- 将主键添加为索引
alter table testa add primary key(id);
这就是给表testa添加了一个主键id,然后由于它是主键,它就不能为空,且值必须是唯一的。而mysql里面,对主键都设立了主键的唯一索引。
- 手动添加别的列为唯一索引
alter table testa add unique index indexclass(class);

- 手动添加别的列为全文索引
alter table testa add fulltext index indexname(name);

- 手动删除索引
alter delete table testa drop index indexclass;

7:使用小窍门
7.1 数据迁移,迁移老数据
如图,有旧表 atest。

新建一个空的数据表,结构如下
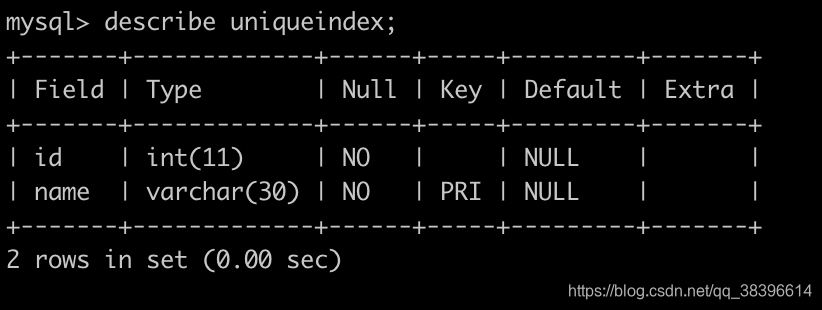
现在操作将旧表中tableid=1的数据迁移到新表,sql如下
insert into uniqueindex(id,name)
select id,name from atest where tableid=1;

操作之后的新表数据如下。

7.2 拼接参数
concat:拼接参数
select concat(id,name) complex from atest;

concat_ws:增加分隔符来拼接参数
select concat(id,"-",name) complex from atest; //这个如果是要拼接多个字段,就要写多个分隔符。
select concat_ws("-",id,name) complex from atest;//将统一的分隔符放在第一个入参的位置,之后跟上多个串联的参数。
原表数据

输入mysql按hour分组,并且将各列每组的值的集合用‘-’分隔开,并且其中ID集合要倒序排列。
select group_concat(id order by id desc separator '_'),group_concat(concat_ws('-',tableid)),hour,group_concat(concat_ws('-',name)) from atest group by hour;
在group_concat里面可以使用separator来明确指明分隔符,也可以内嵌一个concat_ws来格式化。并且可以在结果集里面设置排序,但是排序只会影响对应的列结果集,不会影响别的列结果集。

7.3 group 之后对应组函数处理
组函数处理:min(),max(),sum(),avg(),group_concat(),count()等。
比如:存在部分订单,一个订单编号(bizno)有多条记录的,找出这部分有重复订单编号的订单,并找出其中id比较小的部分。
select biz_no,min(id) from tablename group by biz_no having count(1)>1
7.4 慢查询
查询慢查询语句: show variables like "%slow%;
查询慢查询的时间阈值: show variables like “long_query_time”;
修改设置慢查询的时间阈值: set global long_query_time=100; //设置慢查询时间阈值为100秒。














 1403
1403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









