






常用软件
VirtualBox
-
类似VMWare的虚拟机
Vagrant
-
VirtualBox的Linux系统各发行版镜像仓库,使用vagrant连接VirtualBox能快速拉取centos镜像通过一行命令快速创建centos虚拟机
-
详细使用见Linux指南
Kibana
- Kibana的Dev Tools可用于使用Elasticsearch的WEB API,管理和操作ES中的数据
- Dev Tools界面使用快捷键Ctrl+Home或者Ctrl+End可以快速跳转至控制台的首行或者最后一行
- Dev Tools界面的格式化快捷键为Ctrl+I
JMeter
- Jmeter中选择Options–Choose Language中可以选择简体中文
-
JMeter设置
【线程组设置】
-
Thread Group表示发送请求的最小单位是以线程作为单位的
-
Name是线程组的名称,Comments是该线程组的摘要说明,这两个都可以不填
-
Number of Threads是并发请求的用户数,意思是给并发请求启动多少个线程来模拟用户数量
-
Ramp-up period指的是这些线程在多长时间内将这些线程启动起来,可以看做多长时间内把所有请求发送出去,注意这里只是发送请求的时间,总的时间包含等待响应的时间,不同的服务器性能和响应内容可能导致总时间远远超出发送请求的时间
- ❓:注意不是单个循环发送的时间,因为设置50个循环请求少的时候也是瞬间发完,这里具体的意思还需要明确,倾向于多长时间将这些线程启动起来,因为请求少,每个线程50次请求可以瞬间发完
-
Loop Count该线程组发送请求循环的次数【每个线程发送多少个请求】,infinite表示无限次发送请求
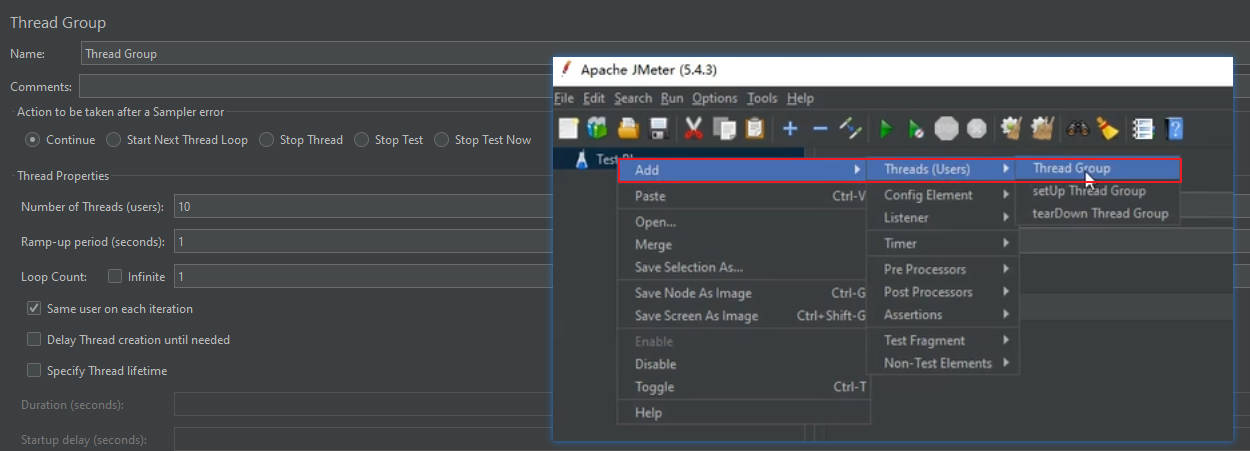
【请求设置】
- 点击绿色按钮是启动该线程组,弹框是提示是否保存当前设置的请求计划,点击保存会将请求设置保存在本地的jmeter的bin目录下的Summary Report.jmx文件中【就是持久化操作】,齿轮加两个扫把图标是清空全部统计数据【不清空每次测试数据会累计】
- 取样器是选择要发送请求的样式
- 需要在Web Server菜单指定请求的协议,目标服务器的IP地址或者被DNS解析的域名,目标服务器端口号
- 在Http Request中指定请求的方式和请求路径
-
-
使用jmeter分析测试结果
【jmeter的查看测试结果集菜单】
-
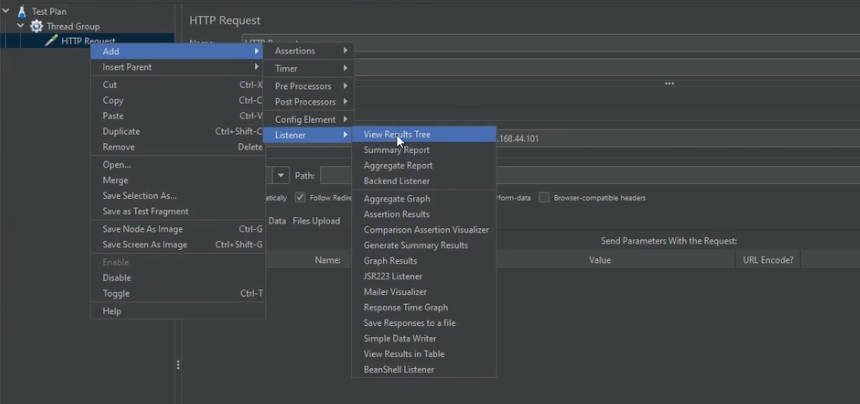
listener【监听器】下有很多展示测试数据的测试结果集选项,比较常用的有以下三种,要像图中这样选中对应的选项卡,在选项卡菜单中运行线程组
-
View Result Tree:查看结果树,能够看到每次请求的响应状态和对应的响应结果
-
Summary Report:汇总报告,显示请求总数,平均、最小、最大响应时间,响应时间的方差和标准差【反应每个样本响应时间和平均值的偏差程度】,异常比例,吞吐量【该指标非常重要,通过该指标来衡量接口每秒的并发能力】,每秒接收和发送的网络数据【网络数据太慢会影响对服务器性能的判断,因为发送请求太慢】
-
View Result in Table:
-
Aggregate Report:聚合报告,显示样本总量、平均响应时间、响应时间中位数、90%、95%、99%请求完成的时间【单位是毫秒】,请求最小最大响应时间、异常比例、吞吐量、接收和发送网络数据的速率
-
Aggregation Graph:能够将统计数据以图表的形式进行展示,在列设置中设置柱状图展示的数据类型、
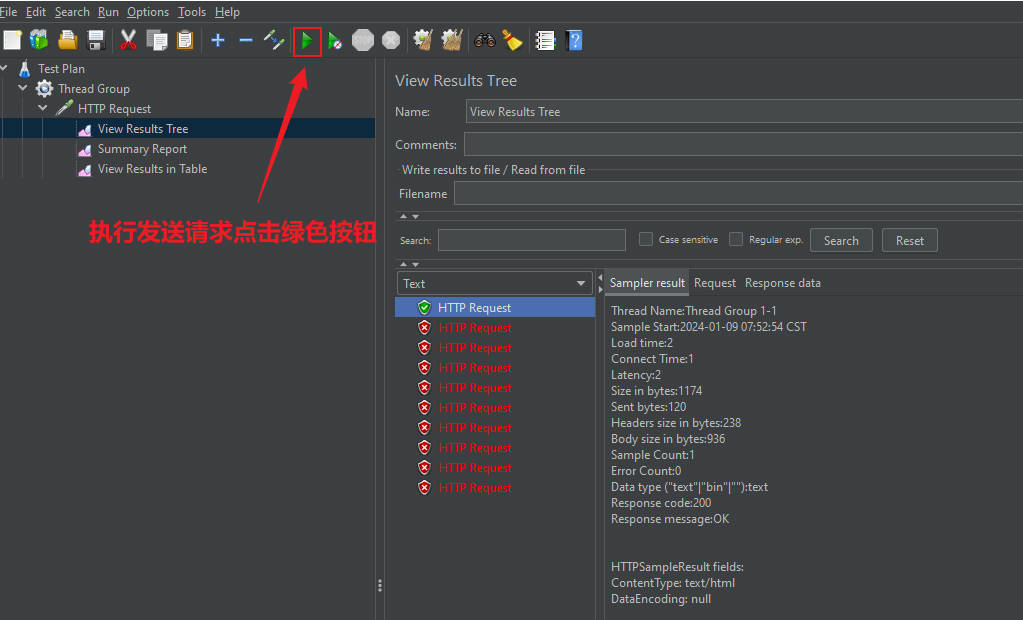
【View Result Tree测试效果】
-
直接选中对应的结果集选项,并按此前操作点击绿色按钮
-
在此前的限流设置下,一秒内的十次并发请求,只有第一个成功了
-
该结果集选项卡下能看到每个请求的请求协议信息、请求的URL和响应数据
【Summary Report测试效果】
Label字段指是发送的是哪一类请求,Http Request表示发送的是http请求,Total表示所有请求的统计信息
Sample表示发送请求的样本个数,我发了3次十个请求,这里就显示的30个
Average、Min、Max、Std.DEV都是响应时间,意思是响应时间的平均值,最小值、最大值和中位值
Error是请求发送发生错误的请求比例有多少
Throughput是指吞吐量,就是指QPS,卧槽我这里怎么是9.6个每分钟,老师的演示是11个每秒,说样本太少,展示数据的结果不准确
Received KB/sec是指每秒接收数据的吞吐量,即网络消耗的吞吐
Send KB/sec是指每秒发送数据的吞吐量
Avg.Bytes是平均每秒数据吞吐量的大小
需要关注的主要就是QPS和发送接收数据的吞吐量,如果QPS怎么也上不去,就像下图演示的情况,此时一定要关注传输数据的吞吐量,因为数据传输的速率是由网卡决定的,比如百兆网卡下载速度应该是100除以8,即12M左右,到达数据传输上限或者延迟很高QPS也是上不去的,不知道是不是我这里的网络太差的原因,但是我这儿用的是同一台主机,难道也是用网卡进行通信的吗
注意上面的工具栏两个小扫把【悬停显示clear】可以清除页面的数据【一个是清除当前,一个是清除所有】,每次发送请求都最好点一下清除数据,方便统计
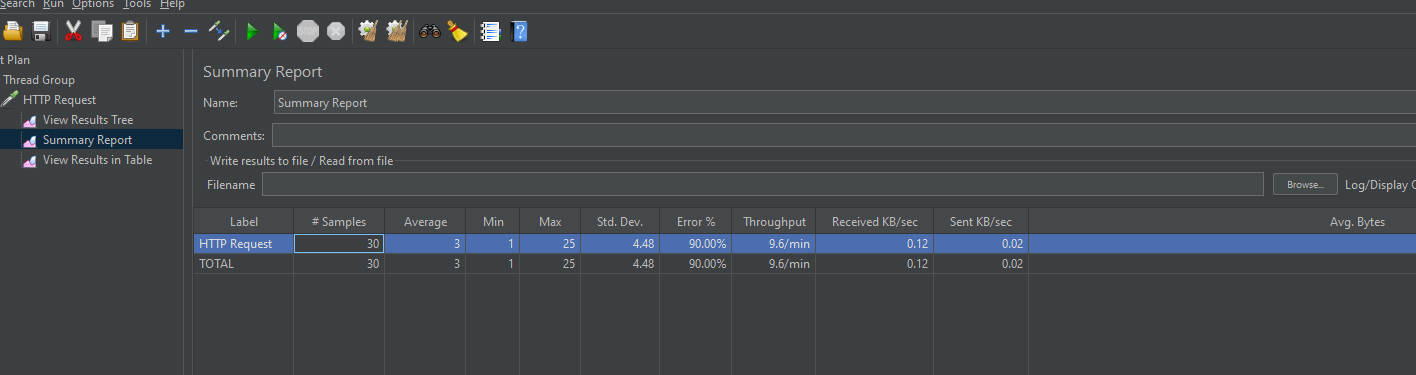
【View Result in Table测试效果】
能够看到每个请求的开始时间【毫秒级别】,请求线程、响应时间、响应状态、请求和响应数据量
-
-
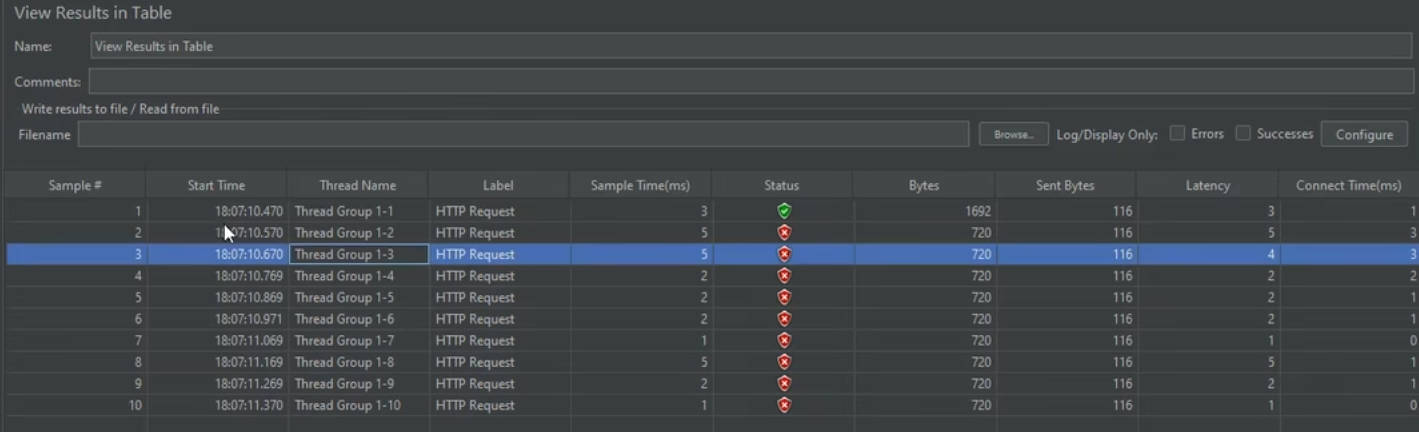
对Nginx服务器无限次请求,观察jmeter统计效果
我这里发了十二万个请求,在nginx服务器的设定限流规则下,只有几个成功了【因为试验了几秒钟】,此时我的QPS上来了,能达到42.4每秒,卧槽老师的都快10000每秒了
连续发起请求,整个过程40多万个请求,可以动态的显示QPS效果。我这里QPS稳定达到了14000左右每秒【最高一万七,一万七不是真实数据,我第二次请求一直单增,但是最终还是稳定1万四】,老师的还是10000左右
虚拟机的配置相比于实际生产机极低,也能到一万多的QPS,QPS高的原因是nginx性能高此外还有请求几乎都报错,即有很多无效的QPS
顶上error和success分别勾选能单独统计成功请求和失败请求的QPS,在ngixn设置的限流策略下随时间推移勾选成功会将QPS稳定在设置值1r/s
而且在View Result in Table中能看到成功请求的时间间隔严格的遵循1s,完全精确到jmeter的时间刻度1ms
JMeter常见问题
- JMeter报错Address Already in use
- 问题描述:Jmeter访问测试本机127.0.0.1的端口服务,在无限请求的情况下请求产生大量异常,异常率迅速飙升超过50%,响应体报错,提示信息
Address already in use - 原因分析:该问题实际是windows的问题,windows本身提供给TCP/IP的端口是1024-5000,且需要四分钟才会循环回收这些端口,短时间内跑大量的请求会将端口占满
- 解决方法一:修改windows的注册文件,windows官方文档中指出当尝试大于5000的TCP端口连接时会收到大量错误,可以通过以下方案来解决
- 1️⃣:在win+r打开窗口中使用命令
regedit打开注册表 - 2️⃣:选择
计算机\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters, - 3️⃣:右击
parameters,新建–DWORD32位,修改对应名字为MaxUserPort,点击该MaxUserPort,在弹出窗口将数值改为65534,基数为十进制【这是设置最大可用端口数量】 - 4️⃣:右击
parameters,新建–DWORD32位,修改对应名字为TCPTimedWaitDelay,点击该TCPTimedWaitDelay,在弹出窗口将数值改为30,基数为十进制【这是】设置windows回收关闭端口的等待时间为30s - 5️⃣:退出注册表编辑器,重启计算机配置才能生效
- 1️⃣:在win+r打开窗口中使用命令
- 问题描述:Jmeter访问测试本机127.0.0.1的端口服务,在无限请求的情况下请求产生大量异常,异常率迅速飙升超过50%,响应体报错,提示信息
Jconsole
- 该工具用于远程或者本地监控Java进程的线程数目、线程运行状态、内存占用等信息
- Jconsole远程连接Java进程需要被连接Java进程在虚拟机做一些额外配置才能允许远程连接,一般项目上线测试使用Jvisualvm也需要这些配置,弹幕说叫jmx配置
-
jconsole远程连接Java进程配置
-
被远程连接Java程序使用以下命令启动
- ip地址:这个是当前虚拟机的IP地址,不是jconsole所在主机的IP地址
- 连接端口:是Jconsole与远程主机的通讯端口,可以随意指定
- 是否需要安全连接:一般自己用也不需要安全连接选择false,如果需要选择true
- 是否需要认证:一般自己使用不需要安全认证可以选择false,如果需要选择true
java -Djava.rmi.server.hostname=`ip地址` -Dcom.sun.management.jmxremote - Dcom.sun.management.jmxremote.port=`连接端口` -Dcom.sun.management.jmxremote.ssl=是否安全连接 - Dcom.sun.management.jmxremote.authenticate=是否认证 java类名 -
通过该启动参数启动的Java进程并提供了远程监控服务,jconsole可以通过该ip和指定的监听端口连接到远程的Java进程上来进行调试,没有设置认证jconsole直接通过ip地址和端口直连就行,不需要输入用户名和口令;需要服务器开放对应端口通讯
-
-
监控堆内存变化、CPU、线程指标的jconsole和jvisualvm工具
-
这两个工具都是Java提供的,jvisualvm是jdk6以后提供的工具,是jconsole的升级版工具,一般推荐使用jvisualvm,相比于jconsole功能更强大,还可以将运行期间出现的问题以快照的形式下载下来慢慢分析来优化应用
-
jconsole的使用
-
安装了java环境直接在CMD窗口敲命令
jconsole启动jconsole控制台 -
上来就提示需要新建连接,指要连接的具体应用,可以连接本地的,也可以连接远程的,本地进程会列举所有运行java程序的进程名称和对应的进程号,选择对应的应用进行监控
-
监控面板
-
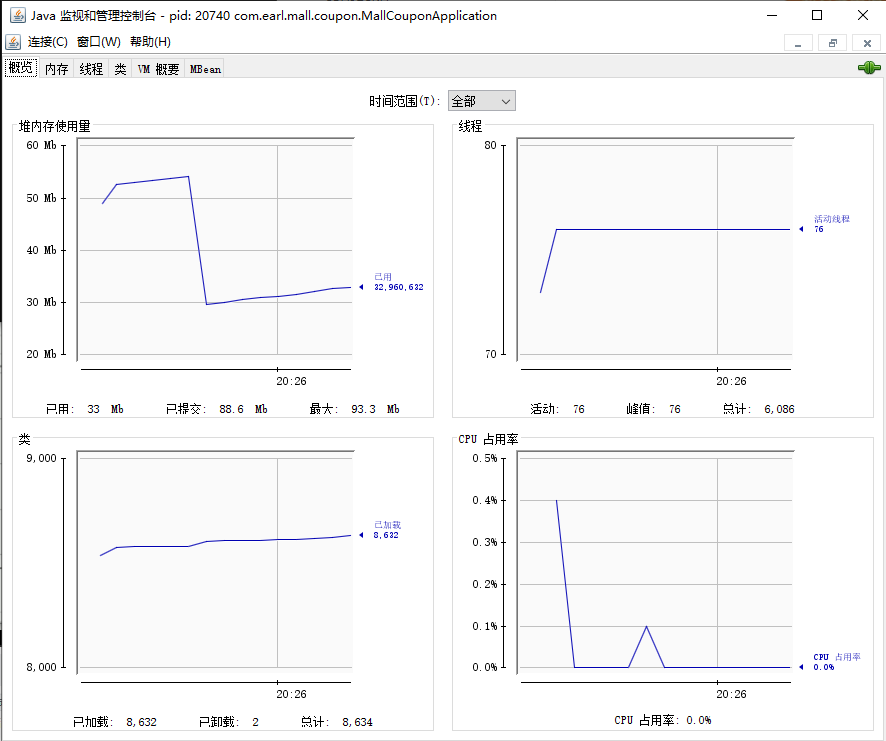
概览面板
- 监控的数据包括堆内存使用量,线程数【压力测试线程数会一直向上涨】,已加载的类数量,CPU占用率
-
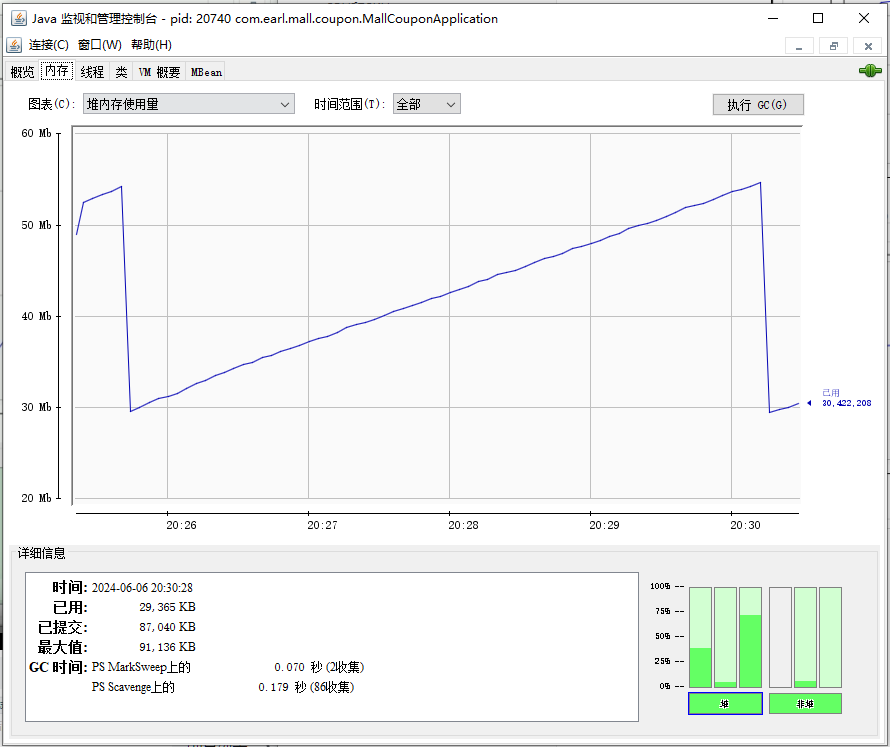
内存面板
- 绿条第一个是老年代内存,第二个是伊甸园区内存,第三个是幸存者区内存,
-
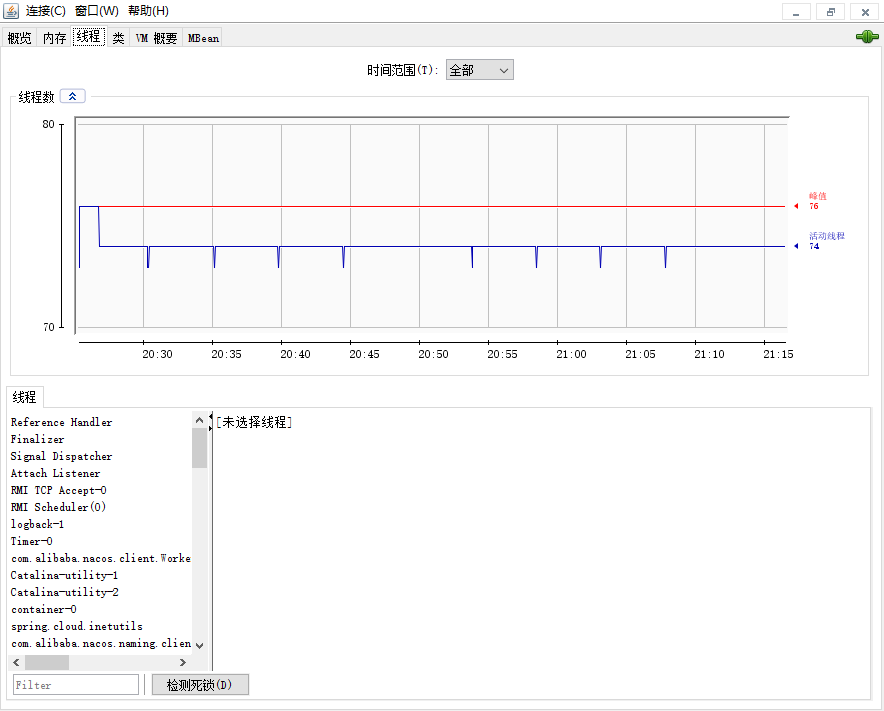
线程面板
- 显示当前的每个线程和对应的堆栈跟踪信息
-
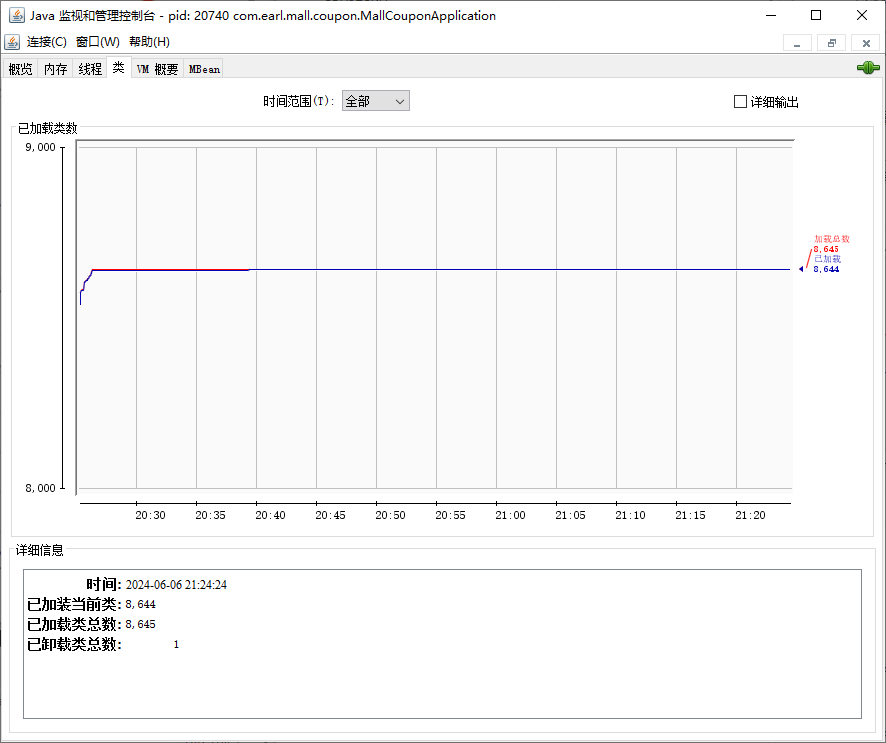
类面板
- 显示当前加载的类信息
-
-
-
Jvisualvm
-
jvisualvm的使用
-
安装了java环境直接在CMD窗口使用命令
jvisualvm启动,弹幕说IDEA可以安装VisualVM Launcher插件,启动后选择连接目标进程,注意Java8以后不再自带jvisualvm -
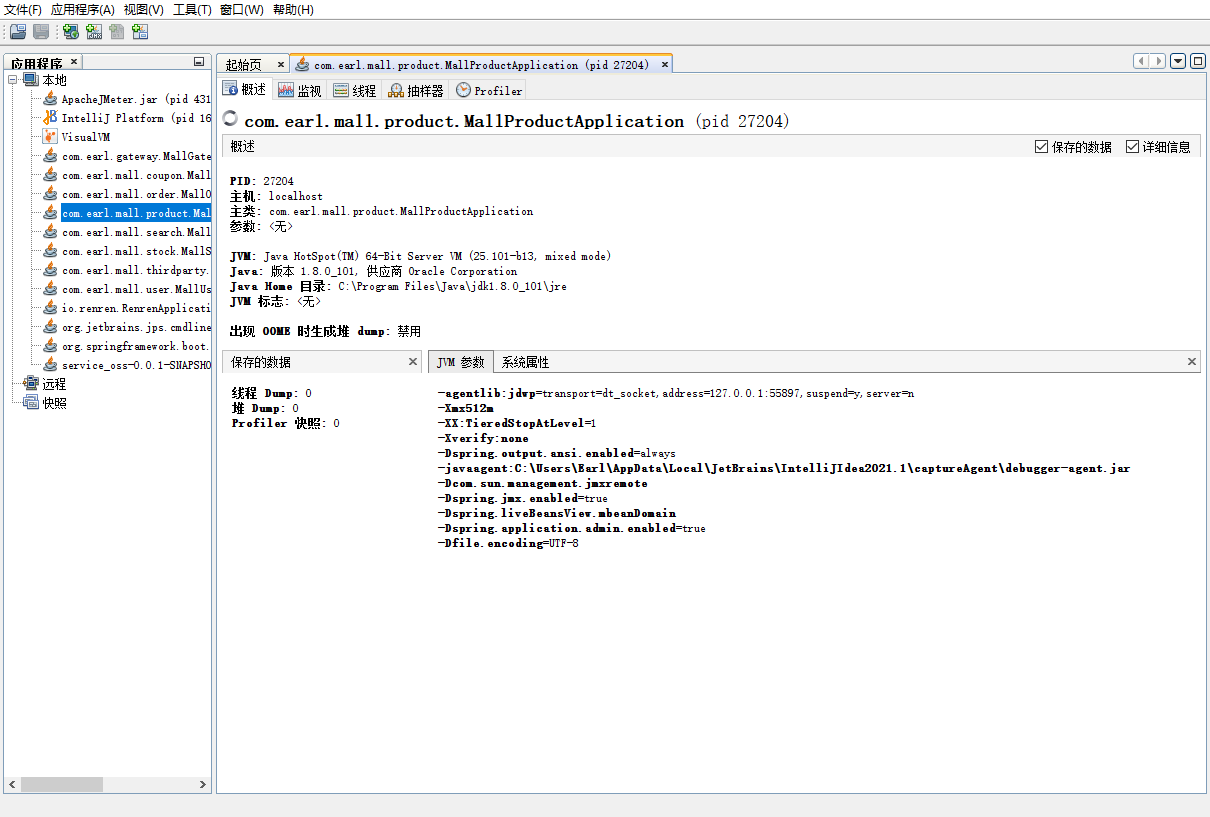
概述面板显示了JVM参数和系统变量属性
-
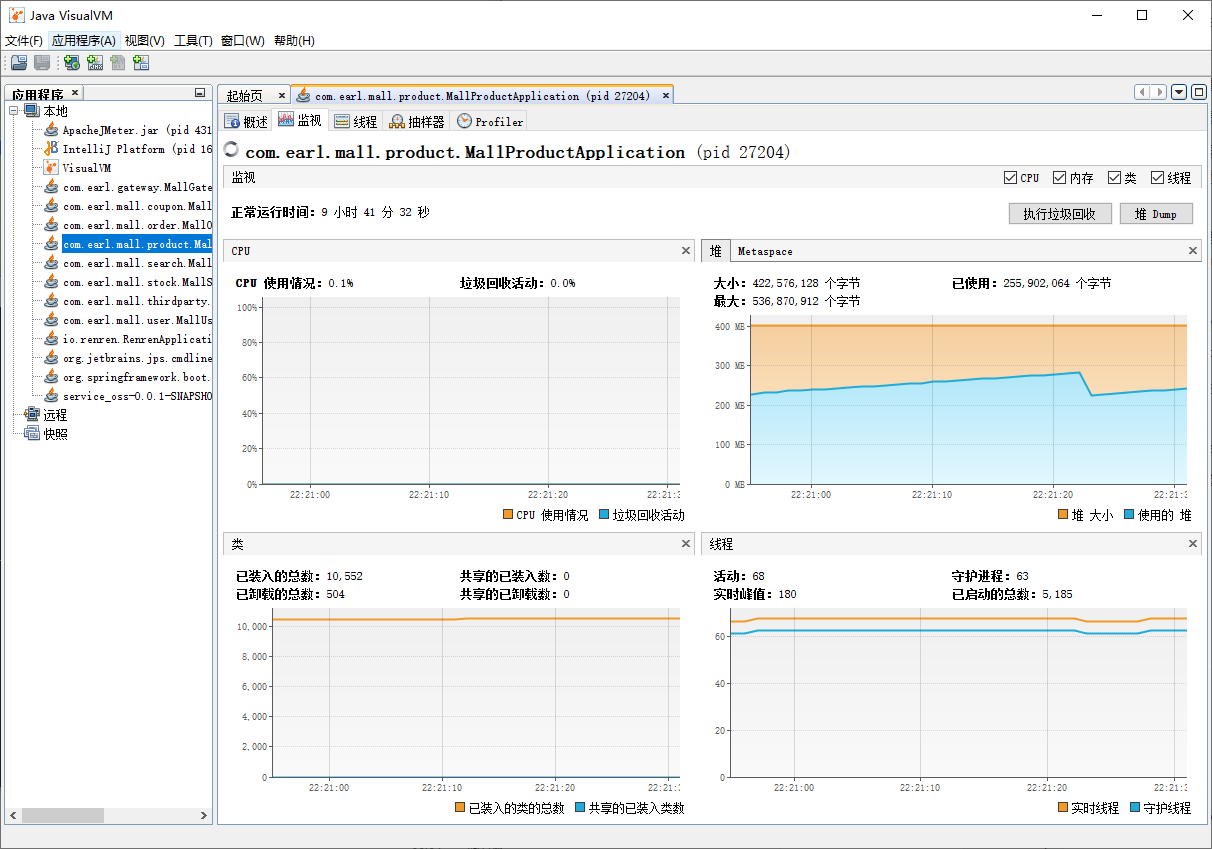
监视面板显示CPU信息、堆内存信息、线程数,已装载类
- 压测期间需要观察已经使用的堆空间和已经使用的堆空间大小,线程情况和CPU情况,来观察当前应用到底是局限在CPU的计算上,还是内存经常容易满,还是线程数不够导致运行太慢等等,像下图CPU的使用了一直维持个位数的使用率,说明CPU太闲了
-
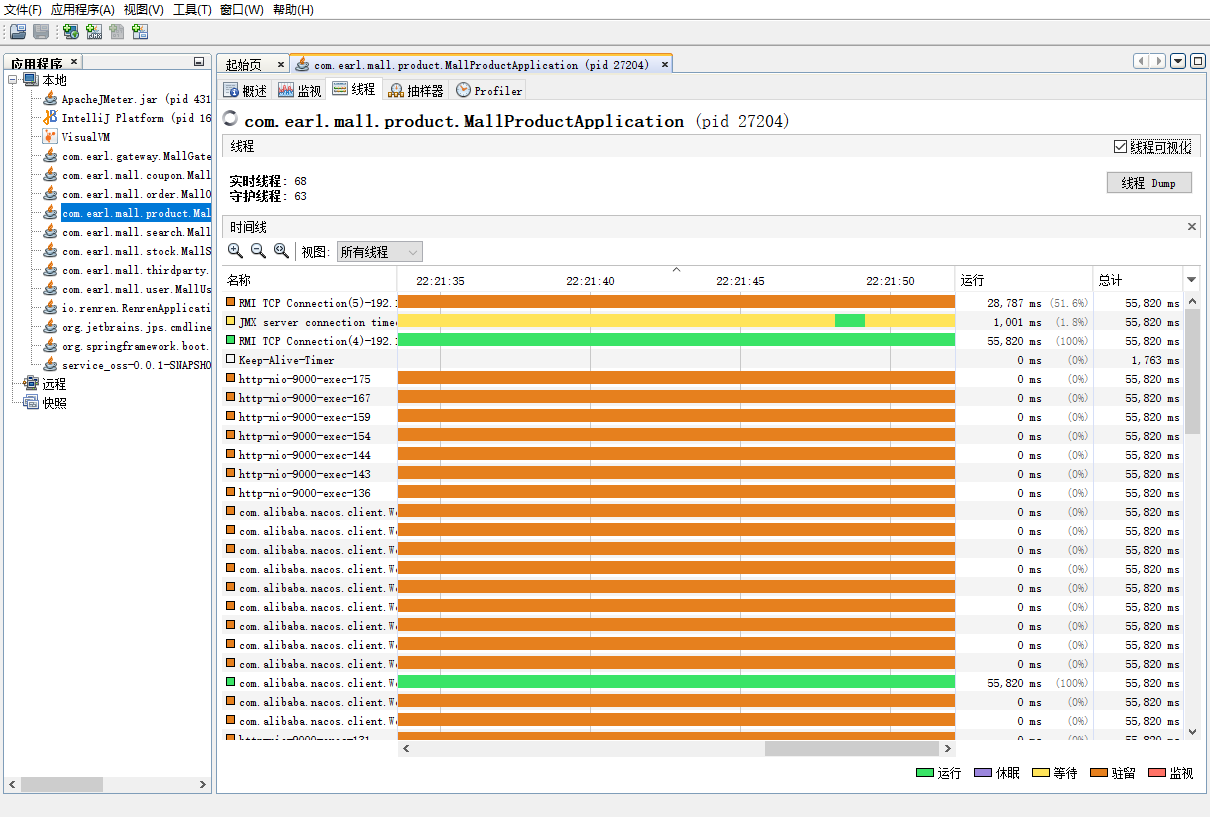
线程面板显示线程的具体信息,还展示当前线程是在运行、休眠【休眠状态是调用了sleep方法的线程】、等待【等待是调用了wait方法的线程】、驻留【线程池中等待接收新任务的空闲线程】以及监视【监视的意思是两个线程发生了锁的竞争,当前线程正在进行等待锁】
-
项目中还需要监控内存的垃圾回收等信息,jvisualvm默认是不带该功能的,需要安装插件,点击工具–插件,点击可用插件–检查最新版本来测试是否报错无法连接到VisualVM插件中心,如果报错,原因是需要指定插件中心的版本【修改插件中心的地址】,按照以下方式解决
-
打开插件中心的网址
https://visualvm.github.io/pluginscenters.html -
使用命令
java -version查看本机的jdk版本java version "1.8.0_101",重点关注小版本号101 -
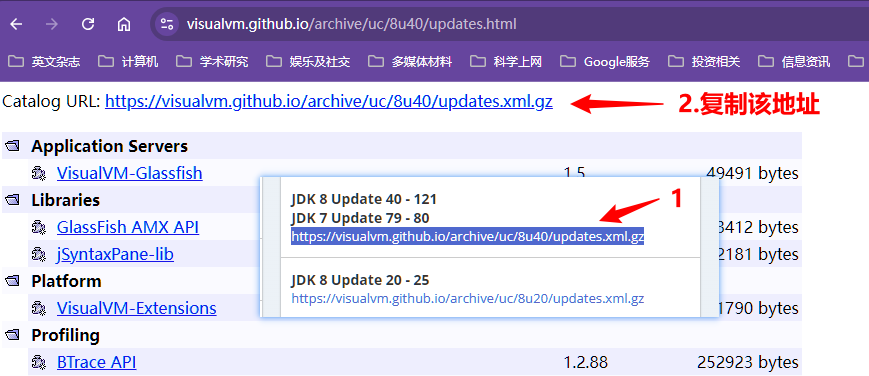
在插件中心的网址中找到小版本所在对应的版本号区间,拷贝对应版本区间的插件更新地址【点进该地址,复制页面最顶上的地址】
-
在jvisualvm中点击设置–编辑Java VisualVM插件中心,将地址粘贴到弹出框的URL栏中,点击确定后会自动进行更新
-
此时就可以直接使用可用插件菜单的插件了,安装不来用个梯子,因为github有可能连不上
-
-
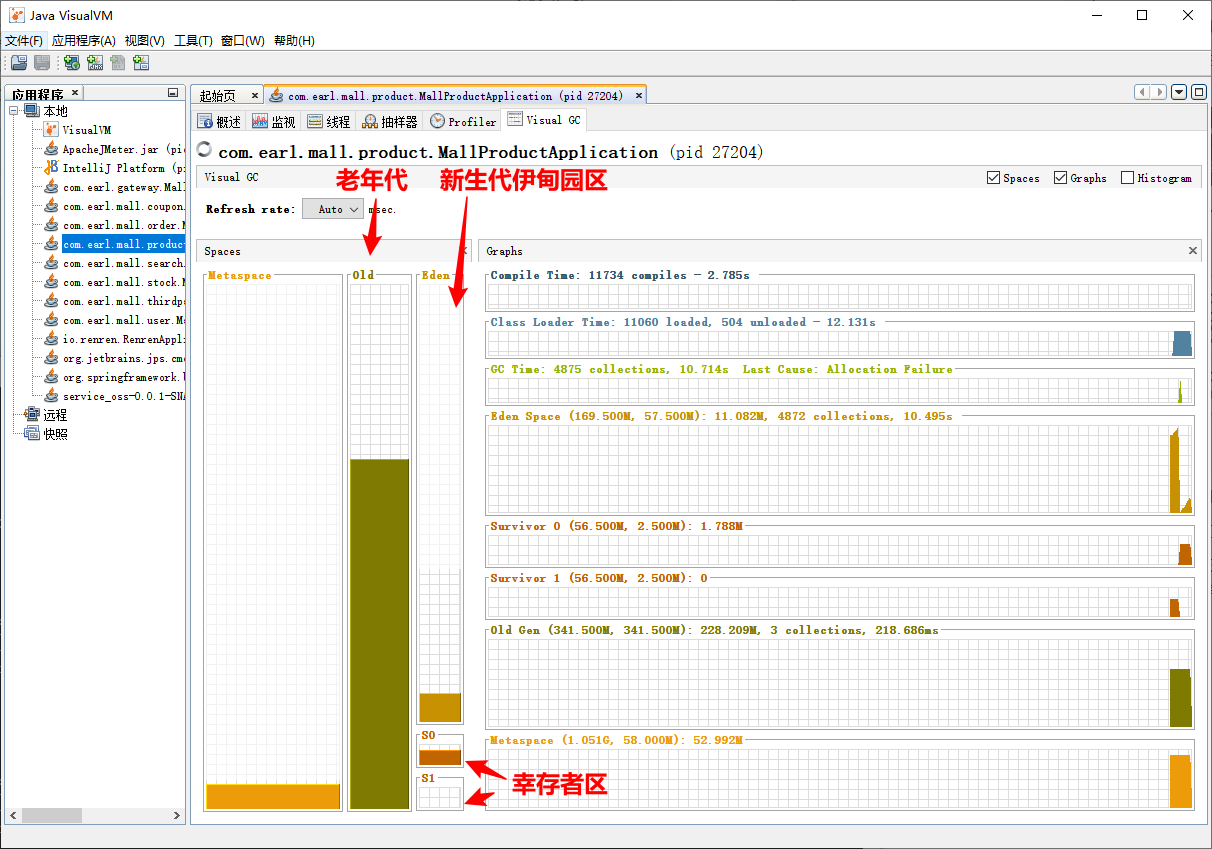
在可用插件中选择插件VisualVM GC,通过该插件可以观察到垃圾回收的过程,点击安装,安装完点击文件–退出,重启jvisualvm,面板会多出一个Visual GC面板,其中Old表示老年代,右边的表示新生代【最上面是伊甸园区、下面是两个幸存者区】
-
GC Time 4875 collections表示总共GC的次数为4875次,后面跟的是GC花费的总时间10.714s
-
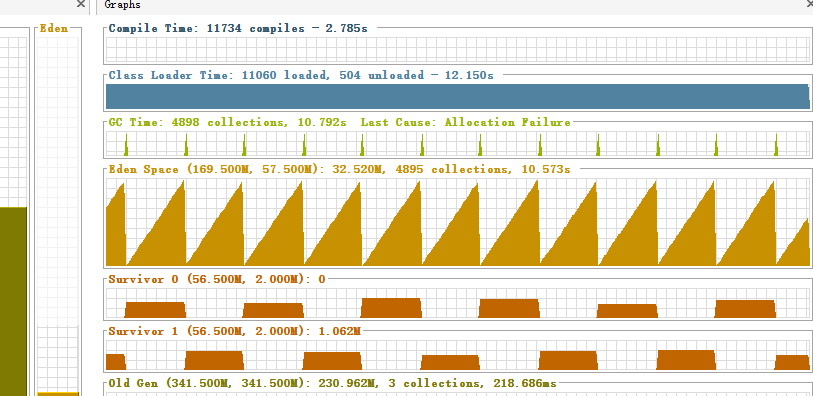
Eden Space中是4872次GC,耗时10.495s,单次约2.15毫秒,下面的图标显示的是内存用量的实时曲线,正常健康的曲线是如下图所示的类直角三角形曲线,意味着伊甸园区的内存满了以后触发一次GC然后内存用量清零
-
Old Gen是老年代,是3次GC,耗时218.686毫秒,单次约72.9毫秒,性能远远低于YGC,因此线上一定要避免频繁地进行FGC,老年代内存缓慢增长,老年代满了以后执行一次FGC
-
Metaspace是元空间,是直接操作物理空间的,前面的数字是最大空间,后面的数字是当前用量,元空间的内存用量不需要关心
-
-
PostMan
-
请求路径带参数
Java生态
SpringBoot生态
MyBatisPlus
整合MyBatisPlus
-
引入依赖
<!--mybatisPlus--> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.2.0</version> </dependency> -
引入mysql数据库驱动依赖
最好是对应mysql版本的mysql驱动,但是从中央仓库发现没有对应5.7.27的mysql驱动,官网给出的解释是mysql驱动5.1和8.0版本可以适配mysql5.6、5.7和8.0的所有版本,5.1兼容jre1.5、1.6、1.7、1.8,8.0只兼容jre1.8;官方推荐使用8.0版本的mysql驱动
<!--mysql驱动--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.17</version> </dependency> -
在
application.yml配置数据源信息Spring: datasource: username: root password: Haworthia0715 url: jdbc:mysql://192.168.56.10:3306?mall_pms driver-class-name: com.mysql.jdbc.Driver -
使用MyBatisPlus需要以下配置
-
启动类上添加注解
@MapperScan("com/earl/mall/product/dao")来告诉MybatisPlus该应用的相关Mapper接口位置实际该注解写在配置类上即可,接口写成Dao或者Mapper无所谓
@MapperScan("com/earl/mall/product/dao") @SpringBootApplication public class MallProductApplication { public static void main(String[] args) { SpringApplication.run(MallProductApplication.class, args); } } -
在配置文件
application.yml配置mybatis-plus.mapper-locations属性来告诉MybatisPlus该应用的相关SQL映射文件的位置默认配置就是
classpath*:/mapper/**/*.xml,classpath*的意思是不仅扫描当前类路径,连引入依赖的类路径下也一起扫描;如果只是classpath表示只扫描当前类路径下,不扫描引入依赖的类路径mybatis-plus: mapper-locations: classpath*:/mapper/**/*.xml
-
配置主键自增
在实体类的主键上有注解
@TableId,如下源码所示,该注解的自增属性默认是没有开启的,属性值为none如果只是在实体类的主键上设置主键类型只会对当前实体类对应的数据库表生效,如果不想每个表都设置一次,可以在配置文件通过属性值
mybatis-plus.global-config.db-config.id-type=auto来进行设置
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD})
public @interface TableId {
String value() default "";
//默认没有开启主键自增功能
IdType type() default IdType.NONE;
}
-
实体类的
@TableId注解@Data @TableName("pms_attr_attrgroup_relation") public class AttrAttrgroupRelationEntity implements Serializable { private static final long serialVersionUID = 1L; /** * id */ @TableId private Long id; /** * 属性id */ private Long attrId; /** * 属性分组id */ private Long attrGroupId; /** * 属性组内排序 */ private Integer attrSort; } -
相关的IdType属性值
0或者AUTO是自增主键
@Getter public enum IdType { /** * 数据库ID自增 */ AUTO(0), /** * 该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) */ NONE(1), /** * 用户输入ID * <p>该类型可以通过自己注册自动填充插件进行填充</p> */ INPUT(2), /* 以下3种类型、只有当插入对象ID 为空,才自动填充。 */ /** * 分配ID (主键类型为number或string), * 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(雪花算法) * * @since 3.3.0 */ ASSIGN_ID(3), /** * 分配UUID (主键类型为 string) * 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(UUID.replace("-","")) */ ASSIGN_UUID(4), /** * @deprecated 3.3.0 please use {@link #ASSIGN_ID} */ @Deprecated ID_WORKER(3), /** * @deprecated 3.3.0 please use {@link #ASSIGN_ID} */ @Deprecated ID_WORKER_STR(3), /** * @deprecated 3.3.0 please use {@link #ASSIGN_UUID} */ @Deprecated UUID(4); private final int key; IdType(int key) { this.key = key; } } -
配置该应用中所有的实体类主键自增
mybatis-plus: global-config: db-config: id-type: auto
排除数据源自动配置
如果基础环境引入了数据库配置需要在微服务中配置数据源,但是有些微服务如网关不需要配置数据库,此时方法一是在子pom文件中排除引入的数据库依赖,方法二是在启动类上的
@SpringBootApplication注解的exclude属性配置排除DatasourceAutoConfiguration.class
-
方法1实现
在子pom文件中排除引入的数据库依赖
<dependency> <groupId>com.earl.mall</groupId> <artifactId>mall-common</artifactId> <version>0.0.1-SNAPSHOT</version> <exclusions> <exclusion> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> </exclusion> </exclusions> </dependency> -
方法2实现
在启动类上的
@SpringBootApplication注解的exclude属性配置排除DatasourceAutoConfiguration.class@EnableDiscoveryClient @SpringBootApplication(exclude = {DataSourceAutoConfiguration.class}) public class MallGatewayApplication { public static void main(String[] args) { SpringApplication.run(MallGatewayApplication.class, args); } }
配置逻辑删除
mybatisplus的逻辑删除是更新操作,根据id和对应的逻辑删除字段将逻辑存在的指定id的记录的逻辑删除字段改成逻辑删除
配置了逻辑删除查询操作也会自动变成查询满足条件且逻辑删除字段为逻辑未删除的记录
-
在对应模块的application.yml文件中配置逻辑删除字段值
和默认配置相同可省略
#mybatisplus逻辑删除配置,这是统一的全局配置,该配置就默认配置,如果配置和默认配置相同可以不写 #从mybatisPlus3.3.0以后要配置logic-delete-field属性了,这里是3.2.0不需要配置 #logic-delete-field: flag # 全局逻辑删除的实体字段名(since 3.3.0,配置后可以忽略不配置步骤2) logic-delete-value: 1 # 逻辑已删除值(默认为 1) logic-not-delete-value: 0 # 逻辑未删除值(默认为 0) -
配置逻辑删除组件ISqlInjector并注入IOC容器
从MybatisPlus3.1.1开始不再需要配置该ISqlInjector组件,即高版本可省略
@Configuration public class MyBatisPlusConfiguration{ @Bean public ISqlInjector sqlInjector(){ return new LogicSqlInjector(); } } -
在实体类的逻辑删除标识字段上添加
@Tablelogic注解@Tablelogic注解内部有两个属性value和delval,分别表示代表逻辑未删除的字面值和逻辑删除的字面值,该属性值的默认值都为空字符串,为空字符串会自动获取全局配置,全局配置没有使用默认配置,如果不为空字符串就会优先使用该注解的配置来确定哪些值表示逻辑删除和逻辑未删除【
@Tablelogic注解】@Documented @Retention(RetentionPolicy.RUNTIME) @Target(ElementType.FIELD) public @interface TableLogic { /** * 默认逻辑未删除值(该值可无、会自动获取全局配置) */ String value() default ""; /** * 默认逻辑删除值(该值可无、会自动获取全局配置) */ String delval() default ""; }【配置实例】
@TableLogic(value = "1",delval = "0") private Integer showStatus;【执行的SQL语句】
==> Preparing: UPDATE pms_category SET show_status=0 WHERE cat_id IN ( ? ) AND show_status=1 ==> Parameters: 1432(Long) <== Updates: 1
打印SQL语句
SpringBoot调整日志级别配置打印MyBatisPlus的SQL语句
-
在应用的application.yml中配置MyBatisPlus日志级别
这样就能打印dao包下的MyBatisPlus的SQL执行语句
#将SpringBoot应用的com.earl.mall包下所有类的日志级别调整成DEBUG级别 logging: level: com.earl.mall: debug
renren分页查询处理
-
配置mp的分页插件
@Configuration //@EnableTransactionManagement开启事务 @EnableTransactionManagement @MapperScan("com.earl.mall.product.dao")//指定Mapper接口的位置 public class MPPagePluginConfig { @Bean//引入分页插件 public PaginationInterceptor paginationInterceptor(){ PaginationInterceptor paginationInterceptor = new PaginationInterceptor(); //设置请求页码大于最后一页的操作,true表示调回到首页,false表示继续请求,默认为false paginationInterceptor.setOverflow(true); //设置最大单页限制数量,默认为500条,设置为-1表示不受限制 paginationInterceptor.setLimit(1000); return paginationInterceptor; } } -
分页相关工具类
-
分页参数处理
/** * Copyright (c) 2016-2019 人人开源 All rights reserved. * * https://www.renren.io * * 版权所有,侵权必究! */ package com.earl.common.utils; import com.baomidou.mybatisplus.core.metadata.IPage; import com.baomidou.mybatisplus.core.metadata.OrderItem; import com.baomidou.mybatisplus.extension.plugins.pagination.Page; import com.earl.common.xss.SQLFilter; import org.apache.commons.lang.StringUtils; import java.util.Map; /** * 查询参数 * * @author Mark sunlightcs@gmail.com */ public class Query<T> { public IPage<T> getPage(Map<String, Object> params) { return this.getPage(params, null, false); } public IPage<T> getPage(Map<String, Object> params, String defaultOrderField, boolean isAsc) { //分页参数 long curPage = 1; long limit = 10; if(params.get(Constant.PAGE) != null){ curPage = Long.parseLong((String)params.get(Constant.PAGE)); } if(params.get(Constant.LIMIT) != null){ limit = Long.parseLong((String)params.get(Constant.LIMIT)); } //分页对象 Page<T> page = new Page<>(curPage, limit); //分页参数 params.put(Constant.PAGE, page); //排序字段 //防止SQL注入(因为sidx、order是通过拼接SQL实现排序的,会有SQL注入风险) String orderField = SQLFilter.sqlInject((String)params.get(Constant.ORDER_FIELD)); String order = (String)params.get(Constant.ORDER); //前端字段排序 if(StringUtils.isNotEmpty(orderField) && StringUtils.isNotEmpty(order)){ if(Constant.ASC.equalsIgnoreCase(order)) { return page.addOrder(OrderItem.asc(orderField)); }else { return page.addOrder(OrderItem.desc(orderField)); } } //没有排序字段,则不排序 if(StringUtils.isBlank(defaultOrderField)){ return page; } //默认排序 if(isAsc) { page.addOrder(OrderItem.asc(defaultOrderField)); }else { page.addOrder(OrderItem.desc(defaultOrderField)); } return page; } } -
Query中自定义工具类
SQLFilter/** * Copyright (c) 2016-2019 人人开源 All rights reserved. * * https://www.renren.io * * 版权所有,侵权必究! */ package com.earl.common.xss; import com.earl.common.exceptions.RRException; import org.apache.commons.lang.StringUtils; /** * SQL过滤 * * @author Mark sunlightcs@gmail.com */ public class SQLFilter { /** * SQL注入过滤 * @param str 待验证的字符串 */ public static String sqlInject(String str){ if(StringUtils.isBlank(str)){ return null; } //去掉'|"|;|\字符 str = StringUtils.replace(str, "'", ""); str = StringUtils.replace(str, "\"", ""); str = StringUtils.replace(str, ";", ""); str = StringUtils.replace(str, "\\", ""); //转换成小写 str = str.toLowerCase(); //非法字符 String[] keywords = {"master", "truncate", "insert", "select", "delete", "update", "declare", "alter", "drop"}; //判断是否包含非法字符 for(String keyword : keywords){ if(str.indexOf(keyword) != -1){ throw new RRException("包含非法字符"); } } return str; } } -
涉及自定义异常类
/** * Copyright (c) 2016-2019 人人开源 All rights reserved. * * https://www.renren.io * * 版权所有,侵权必究! */ package com.earl.common.exceptions; /** * 自定义异常 * * @author Mark sunlightcs@gmail.com */ public class RRException extends RuntimeException { private static final long serialVersionUID = 1L; private String msg; private int code = 500; public RRException(String msg) { super(msg); this.msg = msg; } public RRException(String msg, Throwable e) { super(msg, e); this.msg = msg; } public RRException(String msg, int code) { super(msg); this.msg = msg; this.code = code; } public RRException(String msg, int code, Throwable e) { super(msg, e); this.msg = msg; this.code = code; } public String getMsg() { return msg; } public void setMsg(String msg) { this.msg = msg; } public int getCode() { return code; } public void setCode(int code) { this.code = code; } } -
分页数据封装工具类
/** * Copyright (c) 2016-2019 人人开源 All rights reserved. * * https://www.renren.io * * 版权所有,侵权必究! */ package com.earl.common.utils; import com.baomidou.mybatisplus.core.metadata.IPage; import java.io.Serializable; import java.util.List; /** * 分页工具类 * * @author Mark sunlightcs@gmail.com */ public class PageUtils implements Serializable { private static final long serialVersionUID = 1L; /** * 总记录数 */ private int totalCount; /** * 每页记录数 */ private int pageSize; /** * 总页数 */ private int totalPage; /** * 当前页数 */ private int currPage; /** * 列表数据 */ private List<?> list; /** * 分页 * @param list 列表数据 * @param totalCount 总记录数 * @param pageSize 每页记录数 * @param currPage 当前页数 */ public PageUtils(List<?> list, int totalCount, int pageSize, int currPage) { this.list = list; this.totalCount = totalCount; this.pageSize = pageSize; this.currPage = currPage; this.totalPage = (int)Math.ceil((double)totalCount/pageSize); } /** * 分页 */ public PageUtils(IPage<?> page) { this.list = page.getRecords(); this.totalCount = (int)page.getTotal(); this.pageSize = (int)page.getSize(); this.currPage = (int)page.getCurrent(); this.totalPage = (int)page.getPages(); } public int getTotalCount() { return totalCount; } public void setTotalCount(int totalCount) { this.totalCount = totalCount; } public int getPageSize() { return pageSize; } public void setPageSize(int pageSize) { this.pageSize = pageSize; } public int getTotalPage() { return totalPage; } public void setTotalPage(int totalPage) { this.totalPage = totalPage; } public int getCurrPage() { return currPage; } public void setCurrPage(int currPage) { this.currPage = currPage; } public List<?> getList() { return list; } public void setList(List<?> list) { this.list = list; } }
-
-
分页查询的使用方法
-
参数格式
不需要的比如排序字段、排序方式、key等属性可以不写
{ page: 1,//当前页码 limit: 10,//每页记录数 sidx: 'id',//排序字段 order: 'asc/desc',//排序方式 key: '华为'//检索关键字 } -
查询方式
【控制器方法】
/** * @param params * @param catelogId * @return {@link R } * @描述 根据商品分类id查询属性分组 ,@RequestParam注解能获取到get请求请求路径中的参数并封装对对应名字的参数中,如果是Map, * 会将参数封装到Map集合中 * @author Earl * @version 1.0.0 * @创建日期 2024/02/29 * @since 1.0.0 */ @RequestMapping("/list/{catelogId}") //@RequiresPermissions("product:attrgroup:list") public R list(@RequestParam Map<String, Object> params, @PathVariable("catelogId") Long catelogId){ PageUtils page = attrGroupService.queryPage(params,catelogId); return R.ok().put("page", page); }【分页查询代码】
/** * @param params * @param catelogId * @return {@link PageUtils } * @描述 分页查询请求的参数中有一个key字段,key字段就是检索关键字,分页查询参数和key都是连接在请求url后的, * 这个key是renren-generator封装在自动生成的前端列表组件中的搜索框的,因为这个搜索框只有一个,想要尽可能多的展示 * 数据,需要对该key进行模糊匹配 * 带搜索框的查询条件为select * from pms_attr_group where catelog_id=? and (attr_group_id=key or * attr_group_name like %key% * 即查询属性分组表中商品分类id为指定值且属性分组id为搜索框内容或者属性分组的名字模糊匹配搜素内容的属性分组 * Spring中有一个工具类StringUtils.isEmpty(str)方法能判断str是否空字符串,自5.3版本起,isEmpty(Object)已建议弃用, * 使用hasLength(String)或hasText(String)替代。 * QueryWrapper的and方法可以接受函数式接口Consumer,自动传参QueryWrapper,可以在函数式接口中连续添加查询条件 * @author Earl * @version 1.0.0 * @创建日期 2024/02/29 * @since 1.0.0 */ @Override public PageUtils queryPage(Map<String, Object> params, Long catelogId) { QueryWrapper<AttrGroupEntity> wrapper = new QueryWrapper<AttrGroupEntity>(); String key = (String) params.get("key"); if (StringUtils.hasLength(key)) { wrapper.and(obj->{ obj.eq("attr_group_id",key). or().like("attr_group_name",key) .or().like("descript",key) ; }); } if(catelogId!=0){ wrapper.eq("catelog_id", catelogId); } IPage<AttrGroupEntity> page = this.page( new Query<AttrGroupEntity>().getPage(params), wrapper ); return new PageUtils(page); } -
响应结果格式
{ "msg": "success", "code": 0, "page": { "totalCount": 0, "pageSize": 10, "totalPage": 0, "currPage": 1, "list": [{ "attrGroupId": 0, //分组id "attrGroupName": "string", //分组名 "catelogId": 0, //所属分类 "descript": "string", //描述 "icon": "string", //图标 "sort": 0 //排序 "catelogPath": [2,45,225] //分类完整路径 }] } }
-
-
将查询列表数据处理成自定义封装的列表数据
-
实例
/** * @param params * @return {@link PageUtils } * @描述 带条件分页查询所有属性和属性关联的属性分组和商品分类名称 * 从page中取出数据二次封装以后传递个PageUtils的list属性 * @author Earl * @version 1.0.0 * @创建日期 2024/03/05 * @since 1.0.0 */ @Override public PageUtils queryPage(Map<String, Object> params,Long catelogId) { String key = (String) params.get("key"); QueryWrapper<AttrEntity> wrapper = new QueryWrapper<>(); if (StringUtils.hasLength(key)){ wrapper.and(obj->{ obj.eq("attr_id",key).or().like("attr_name",key); }); } if(catelogId!=0){ wrapper.eq("catelog_id",catelogId); } IPage<AttrEntity> page = this.page( new Query<AttrEntity>().getPage(params), wrapper ); PageUtils pageUtils = new PageUtils(page); //将分页数据从page中取出来再加工 List<AttrListVo> responseVo = page.getRecords().stream().map(attrEntity -> { AttrListVo attrListVo = new AttrListVo(); BeanUtils.copyProperties(attrEntity, attrListVo); AttrAttrgroupRelationEntity relation = attrAttrgroupRelationService.getOne(new QueryWrapper<AttrAttrgroupRelationEntity>().eq("attr_id", attrEntity.getAttrId())); if (relation != null && relation.getAttrGroupId() != null) { attrListVo.setGroupName(attrGroupDao.selectById(relation.getAttrGroupId()).getAttrGroupName()); } if (attrEntity.getCatelogId() != null) { attrListVo.setCatelogName(categoryDao.selectById(attrEntity.getCatelogId()).getName()); } return attrListVo; }).collect(Collectors.toList()); pageUtils.setList(responseVo); return pageUtils; }
-
事务
-
在配置类上使用注解
@EnableTransactionManagement开启事务只有在配置类上使用了该注解才能在需要控制事务的方法上使用
@Transactional注解控制事务@Configuration //@EnableTransactionManagement开启事务 @EnableTransactionManagement @MapperScan("com.earl.mall.product.dao")//指定Mapper接口的位置 public class MPPagePluginConfig { @Bean//引入分页插件 public PaginationInterceptor paginationInterceptor(){ PaginationInterceptor paginationInterceptor = new PaginationInterceptor(); //设置请求页码大于最后一页的操作,true表示调回到首页,false表示继续请求,默认为false paginationInterceptor.setOverflow(true); //设置最大单页限制数量,默认为500条,设置为-1表示不受限制 paginationInterceptor.setLimit(1000); return paginationInterceptor; } } -
在目标方法上使用注解
@Transactional控制操作的事务@Override @Transactional public void updateRelatedData(BrandEntity brand) { this.updateById(brand); if(StringUtils.hasLength(brand.getName())){ categoryBrandRelationService.updateBrandNameByBrandId(brand.getBrandId(),brand.getName()); } //TODO 品牌名称更新时更新相应的冗余数据 }
配置自动填充字段
-
向Spring容器注入组件
-
代码实例
/** * @author Earl * @version 1.0.0 * @描述 Mp的字段自动填充组件 * @创建日期 2024/03/27 * @since 1.0.0 */ @Component public class MyMetaObjectHandler implements MetaObjectHandler { /** * @param metaObject * @描述 设置生成记录时需要自动填充的字段 * @author Earl * @version 1.0.0 * @创建日期 2024/03/27 * @since 1.0.0 */ @Override public void insertFill(MetaObject metaObject) { this.setFieldValByName("createTime", new Date(), metaObject); this.setFieldValByName("updateTime", new Date(), metaObject); } /** * @param metaObject * @描述 设置更新记录时需要自动填充的字段 * @author Earl * @version 1.0.0 * @创建日期 2024/03/27 * @since 1.0.0 */ @Override public void updateFill(MetaObject metaObject) { this.setFieldValByName("updateTime", new Date(), metaObject); } }
-
-
在实体类指定字段上设置填充策略
-
配置实例
@Data @TableName("pms_spu_info") public class SpuInfoEntity implements Serializable { private static final long serialVersionUID = 1L; /** * 商品id */ @TableId private Long id; /** * 商品名称 */ private String spuName; /** * 商品描述 */ private String spuDescription; /** * 所属分类id */ private Long catelogId; /** * 品牌id */ private Long brandId; /** * 商品重量 */ private BigDecimal weight; /** * 上架状态[0 - 下架,1 - 上架] */ private Integer publishStatus; /** * 记录创建时间 */ @TableField(fill = FieldFill.INSERT) private Date createTime; /** * 记录更新时间 */ @TableField(fill = FieldFill.INSERT_UPDATE) private Date updateTime; }
-
Junit
-
引入Junit依赖
非maven项目引入junit依赖需要在本地仓库找到junit.junit-4.12和org.hamcrest.hamcrest-core-1.3,同时导入才不会报错,同时需要添加测试目录才能生效
-
Junit依赖
junit的依赖已经被spring-boot-starter-test依赖了
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> -
单元测试格式
注意,没有
@RunWith(SpringRunner.class)老版本的SpringBoot涉及到自动注入的对象就会报空指针异常,新版本的SpringBoot单元测试没有这个注解@RunWith(SpringRunner.class)//指定使用Spring的驱动来跑单元测试,这是老版本SpringBoot的写法,新版本已经不这么写了 @SpringBootTest public class MallProductApplicationTests { @Autowired BrandService brandService; @Test public void contextLoads() { BrandEntity brandEntity = new BrandEntity(); brandEntity.setName("华为"); System.out.println(brandService.save(brandEntity)); } } -
异常情况
在IDEA使用默认的SpringBoot初始化工具初始化的项目可能单元测试是以下结构
这种结构在更换SpringBoot和SpringCloud的版本后无法直接进行单元测试,需要添加注解
@RunWith(SpringRunner.class)和将测试类和方法上添加public前缀@SpringBootTest class MallOrderApplicationTests { @Test void contextLoads() { } }
-
Lombok
- 使用Lombok需要添加对应的Lombok依赖,而且IDEA需要安装Lombok插件,作用是简化JavaBean开发
-
依赖导入
<!--lombok--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.8</version> </dependency> -
API详解
@Data:在程序编译的时候自动为标注了@Data注解的实体类的所有非final字段添加@setter、@AllArgsConstructor、@NoArgsConstructor注解、为所有字段添加@ToString、@EqualsAndHashCode注解、@Getter注解@TableName("pms_attr"):标注当前实体类对应的数据库表名@NoArgsConstructor:为当前实体类填充无参构造方法@AllArgsConstructor:为当前实体类填充全参构造方法@ToString:重写当前实体类的toString方法@Getter:自动生成Getter方法@Setter:自动生成Setter方法
-
用法综合示例
import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import lombok.ToString; @Data//为属性自动填充getter和setter方法 @NoArgsConstructor//无参构造 @AllArgsConstructor//全参构造 @ToString//重写实体类的toString方法 public class Product { private Long id;//商品唯一标识 private String title;//商品名称 private String category;//分类名称 private Double price;//商品价格 private String images;//图片地址 }
Logback
- 引入Logback依赖可以使用slf4j来打印日志,slf4j是接口,logback是该接口的一种实现
-
引入依赖
<dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>1.2.3</version> </dependency> -
logback配置文件
logback.xml【类路径下】<?xml version="1.0" encoding="UTF-8"?> <configuration xmlns="http://ch.qos.logback/xml/ns/logback" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://ch.qos.logback/xml/ns/logback logback.xsd"> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>%date{HH:mm:ss} [%t] %logger - %m%n</pattern> </encoder> </appender> <logger name="c" level="debug" additivity="false"> <appender-ref ref="STDOUT"/> </logger> <root level="ERROR"> <appender-ref ref="STDOUT"/> </root> </configuration> -
常用API
@Slf4j(topic="c.Test2")- 标注该注解类中产生的日志都会在线程信息后面紧跟注解中的topic属性值,一般用作日志的记录位置区分标识
log.debug("{}",task.get());- log对象的日志函数中字符串中的大括号叫占位符,占位符的数据来自于后面紧跟着的参数,可以使用多个占位符和多个参数,依次按顺序填充
HttpCore
内含包
org.apache.httpcomponents,是Apache用java代码实现的使用java代码发送HTTP请求的一个工具类
<!--httpCore-->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.12</version>
</dependency>
Servlet-api
在SpringBoot中使用Servlet相关的东西【如ServletRequest】需要在项目中引入依赖servlet-api,但是tomcat自带了servlet-api依赖,将scope改为provided,表示目标环境已经存在
<!--servlet-api-->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>2.5</version>
<scope>provided</scope>
</dependency>
Commons-lang
- apache的
Commons-lang工具包,关注一下commons-lang包和commons-lang3包的不同
<!--commons-lang-->
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
gson
-
依赖引入
<dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.8.5</version> </dependency>
validation-api
validation-api是javax旗下的,引入后可以在项目中使用JSR303规范的数据校验功能以及自定义校验注解;在SpringBoot2.3.x以前是随web-starter的hibernate-validator一起引入的
-
依赖引入
<!--validation-api--> <dependency> <groupId>javax.validation</groupId> <artifactId>validation-api</artifactId> <version>2.0.1.Final</version> </dependency>
JSR303数据校验
-
使用JSR303【Java Specification Requests,即Java规范提案】,JSR303规定了数据校验的相关标准;
-
SpringBoot从2.3.x版本开始其中不再内置校验了,从依赖关系上来看SpringBoot的
web starter引入了校验注解相关的依赖hibernate-validator,包括javax.validation.contraints包也是hibernate-validator下的,高版本SpringBoot似乎不再包含该依赖了,注意甄别
基础校验
-
用法
- 通过在实体类的属性上使用校验注解来对数据指定校验规则
- 此外在
Controller中要在参数列表中参数前面使用@Valid注解进行标注,只在实体类上标注数据校验注解不在Controller中对应位置标注@Valid注解是不会主动对数据进行校验的 - 响应状态码是
400,提示Bad Request,说明服务端数据校验是不通过的,校验错误信息封装在响应数据的errors属性中,errors.defaultMessage是校验错误信息、errors.field是发生校验错误的属性、errors.rejectValue是发生校验错误的属性值,但是这个校验错误信息返回格式不规范,实际开发中都需要专门封装成统一响应格式返回 - 多个校验注解可以一起使用
-
常见数据校验相关的注解
这些注解全部可以在包
javax.validation.contraints下找到,具体含义看每个注解的注释,注释还规定了注解能放在哪些参数类型上-
@Email- 作用:被该注解标注的属性值必须是邮箱
-
@NotNull- 作用:被该注解标注的属性值不能为
null - 补充说明:该注解可以标注在任意类型的属性上
- 作用:被该注解标注的属性值不能为
-
@Future- 作用:被该注解标注的属性值必须是未来时间
-
@Min()-
作用:被该注解标注的属性值必须比
value属性的指定值大 -
配置实例:
@Min(value = 0,message = "排序数字必须大于等于0") private Integer sort;
-
-
@Max- 作用:被该注解标注的属性值必须比指定值小
-
@NotEmpty- 作用:被该注解标注的属性值不能为
null或者空字符串,但是可以是空格字符串 - 补充说明:
@NotEmpty只支持放在字符串、集合、Map和数组类型的属性上
- 作用:被该注解标注的属性值不能为
-
@Size- 作用:被该注解标注的属性值必须满足长度要求
-
@NotBlank- 作用:被该注解标注的属性值不能为null、空字符串、空格字符串,字符串至少包含一个非空格字符
-
@Pattern-
作用:自定义校验规则
-
补充说明:
- 该注解中有一个
regexp属性,需要写一个字符串正则表示式【注意正则表达式再Java中需要去掉两边的斜杠,经过本地测试有斜杠偶尔能成功,但是肯定会出问题】,通过正则表达式来指定自定义的校验规则; message属性仍然为校验错误的错误提示信息- 该注解不支持
Integer类型进行正则表达式校验,报错500 @Pattern注解仅支持有值情况下的正则表达式校验,值为null或者空字符串的情况下默认是校验正确的,注意啊,因为空值情况下有专门的非空注解来进行校验,所以基本上注解是不会对空值情况还进行相应的校验,也就是会默认校验正确,因为一个实体类针对不同的操作比如新增和修改可能涉及到指定多组校验,此时某些字段修改时可能会提交修改也可能不会提交修改,此时分组内的校验规则没指定非空校验,此时就会默认触发对应有值情况下需要校验的规则返回为正确,这样能同时实现空值情况下不进行入参校验【或者说空值默认校验结果为真】,有值的情况下严格执行入参校验规则
- 该注解中有一个
-
配置实例:
@Pattern(regexp = "/^[a-zA-Z]$/",message = "检索首字母必须是一个字母") private String firstLetter;
-
-
@Length-
作用:限定入参长度,
min属性限定入参长度最小值,max属性限定入参长度最大值 -
配置实例:
-
-
-
第三方校验注解
@URL- 作用:被该注解标注的属性值必须为一个
url,入参该参数为空会默认不进行校验 - 补充说明:这个注解是
org.hibernate.validator.constraint包提供的,是hibernate对JSR303的额外实现,从依赖关系上来看SpringBoot的web starter引入了校验注解相关的依赖hibernate-validator,包括javax.validation.contraints包也是hibernate-validator下的,高版本SpringBoot似乎不再包含该依赖了,注意甄别
- 作用:被该注解标注的属性值必须为一个
-
自定义返回服务端校验错误信息
-
每个校验规则中都有一个message属性,如果没有自定义message信息就会默认使用
ValidationMessage.properties文件中的对应校验错误的message消息,中文地区会使用ValidationMessage_zh_CN.properties文件中的校验错误信息对默认消息不满意就自己指定校验注解的message信息
-
自定义校验信息响应格式
-
在被校验的Bean参数后面紧跟
BindingResult类型的参数,SpringBoot会自动将校验结果封装到该对象中, -
该
bindingResult对象的hasErrors布尔类型属性中封装了本次校验的结果,如果为true表示校验失败,为false表示校验成功 -
可以从
bindingResult中获取到错误的信息,封装成一个Map进行返回,校验错误信息封装见以下示例- 注意写了
bindingResult,校验异常会被自动处理,将错误信息封装到bindingResult,这种情况是不会抛校验异常的;不写bindingResult出现异常是会抛异常信息的,每个控制器方法中都写校验错误处理代码显得太冗余,使用全局异常专门处理校验异常能省去很多冗余代码 - 弹幕说会有重复key的问题,同一个属性上使用俩个验证的话,任何一项不满足,
BindingResult中会封装两个fieldError对象,但是这两个对象的field属性是相同的,但是defaultMessage属性分别是两个校验注解校验错误的对应提示信息,封装到Map中就会出现一个重复key不同value的情况
@RequestMapping("/save") public R save(@Valid @RequestBody BrandEntity brand, BindingResult bindingResult){ if(bindingResult.hasErrors()){ //1. 准备封装错误校验信息的容器 Map<String,String> bingErrors = new HashMap<>(); //2. 获取所有的错误校验结果并封装进Map bindingResult.getFieldErrors().forEach(item->{ //获取校验错误的属性名字 String field = item.getField(); //获取对应错误属性的错误校验信息 String msg = item.getDefaultMessage(); bingErrors.put(field,msg); }); return R.error(400,"提交的数据不合法").put("data",bingErrors); }else{ brandService.save(brand); } return R.ok(); } - 注意写了
-
-
-
自定义校验处理全局统一处理
使用
@ControllerAdvice+@ExceptionHandler的方式定义全局的数据校验异常处理,注意有全局参数校验异常处理的前提下,在控制器方法中对异常进行了捕获是不会触发这个全局异常的,即数据校验个别方法还可以通过控制器方法捕获的方式进行个性化处理-
实例
@Slf4j //@ResponseBody //@ControllerAdvice(basePackages = "com.earl.mall.product.controller") @RestControllerAdvice(basePackages = "com.earl.mall.product.controller") public class MallControllerExceptionHandler { @ExceptionHandler(MethodArgumentNotValidException.class) public R handleValidException(MethodArgumentNotValidException e){ //特定异常类型可以通过发生异常后对应异常的getClass方法获取 log.error("数据校验错误:{},异常类型:{}",e.getMessage(),e.getClass()); //1. bindingResult可以通过e.getBindingResult()获取 BindingResult bindingResult = e.getBindingResult(); //1. 准备封装错误校验信息的容器 Map<String,String> bingErrors = new HashMap<>(); //2. 获取所有的错误校验结果并封装进Map bindingResult.getFieldErrors().forEach(item->{ //获取错误属性名字 String field = item.getField(); //获取对应错误属性的错误校验信息 String msg = item.getDefaultMessage(); bingErrors.put(field,msg); }); //StatusCode.VALID_EXCEPTION是自定义异常枚举类型 return R.error(StatusCode.VALID_EXCEPTION.getCode(), StatusCode.VALID_EXCEPTION.getMsg()).put("data",bingErrors); } }
-
分组校验
-
校验注解分组
对于一个品牌实体类,新增品牌和修改品牌的参数很可能是不一样的,比如新增不需要携带品牌ID,但是修改必须要带品牌ID、新增品牌和修改品牌时品牌名都不能为空。但是此时实体类的校验规则只有一套,此时就需要使用JSR303分组校验功能
-
每一种校验注解都有一个
groups属性,group属性是一个接口【Classs<?>】数组,这个接口是自定义的接口,比如在包valid下创建两个接口AddGroup和UpdateGroup,这是两个空接口,标注在不同的校验注解中分别表示在新增的时候才调用新增的校验,修改的时候才调用修改的校验,只是作为一种校验组合的区分在控制器方法中进行区分 -
如果一个校验规则新增和修改都需要校验,则在group属性同时指定
AddGroup和UpdateGroup两个接口 -
实例:
/** * 品牌 * * @author Earl * @email 18794830715@163.com * @date 2024-01-27 08:45:26 */ @Data @TableName("pms_brand") public class BrandEntity implements Serializable { private static final long serialVersionUID = 1L; /** * 品牌id */ @TableId @NotNull(message = "品牌ID不能为空",groups = {UpdateGroup.class}) private Long brandId; /** * 品牌名 */ @NotBlank(message = "必须填写品牌名",groups = {AddGroup.class,UpdateGroup.class}) private String name; /** * 品牌logo地址 */ @URL(message = "请输入合法的logo地址",groups = {AddGroup.class,UpdateGroup.class}) @NotBlank(groups = {AddGroup.class}) private String logo; /** * 介绍 */ private String descript; /** * 显示状态[0-不显示;1-显示] */ @ListValue(vals={0,1},groups = {AddGroup.class,UpdateGroup.class, UpdateSingleFieldGroup.class}) @NotNull(groups = {AddGroup.class,UpdateGroup.class}) private Integer showStatus; /** * 检索首字母 */ @NotBlank(groups = {AddGroup.class}) @Pattern(regexp = "^[a-zA-Z]$",message = "检索首字母必须是一个字母",groups = {AddGroup.class,UpdateGroup.class}) private String firstLetter; /** * 排序 */ @Min(value = 0,message = "排序数字必须大于等于0",groups = {AddGroup.class,UpdateGroup.class}) @NotNull(groups = {AddGroup.class}) private Integer sort; }
-
-
分组校验的使用
制定好校验规则后在控制器方法中将原来validation中的校验注解换成spring框架提供的
@Validated注解,该注解中的value属性也是接口数组,即在其中指定校验分组,用来实现多场景情况下的复杂校验-
🔎:
@validated如果指定了分组,那么Bean中只校验属于该分组注解标注的值是否合法,没有指定分组的注解不会进行校验,如果@validated没有标注group,就会校验bean中所有没有分组的校验注解,此时被分组的注解反而不会生效 -
🔎:因为空值情况下有专门的非空注解来进行校验,所以基本上注解是不会对空值情况还进行相应的校验,也就是会默认校验正确,因为一个实体类针对不同的操作比如新增和修改可能涉及到指定多组校验,此时某些字段修改时可能会提交修改也可能不会提交修改,此时分组内的校验规则没指定非空校验,此时就会默认触发对应有值情况下需要校验的规则返回为正确,这样能同时实现空值情况下不进行入参校验【或者说空值默认校验结果为真】,有值的情况下严格执行入参校验规则
-
实例:
@RequestMapping("/save") //@RequiresPermissions("product:brand:save") public R save(@Validated(AddGroup.class) @RequestBody BrandEntity brand){ brandService.save(brand); return R.ok(); } @RequestMapping("/update") //@RequiresPermissions("product:brand:update") public R update(@Validated(UpdateGroup.class) @RequestBody BrandEntity brand){ brandService.updateById(brand); return R.ok(); }
-
自定义校验注解
现有的校验注解可能无法满足需求,比如校验排序字段必须为非负整数,此时能想到使用
@Pattern注解使用正则表达式对字段进行校验,但是该字段类型为Integer类型,@Pattern注解不能使用在Integer类型上【正则只能校验字符串】,此时就需要考虑使用自定义校验注解了自定义校验的实现需要三步:编写一个自定义校验注解,编写一个自定义检验器,关联自定义校验器和自定义校验注解
-
自定义校验注解要求
-
一个自定义校验注解必须满足JSR303规范,必须包含3个属性
message、groups、payload- message是校验出错以后的默认提示消息去哪儿获取
- groups是注解必须支持分组校验功能
- payload是自定义校验注解还可以自定义一些负载信息
-
自定义校验注解必须标注指定的元信息数据【标注指定的注解并配置源信息数据】
-
@Target({METHOD,FIELD,ANNOTATION_TYPE,CONSTRACTOR,PARAMTER,TYPE_USE})@Target注解指定该注解可以标注的位置 -
@Retention(RUNTIME)@Retention(RUNTIME)指定该注解运行时可被获取 -
Constraint(validatedBy={})Constraint(validatedBy={})指定该注解关联的校验器,这个地方不指定就需要在系统初始化的时候进行指定 -
@Repeatable(List.calss)@Repeatable(List.calss)表示该注解是一个可重复注解 -
@Documented
-
-
-
自定义校验注解实例
自定义校验注解
@Documented // validatedBy要指定一个ConstraintValidator的子类数组,我们可以指定自定义校验器, // 以自定义校验器ListValueConstraintValidator为例 // 一个校验器只能适配一种参数类型,如果还需要适配其他参数类型,需要再定义一个校验器,并在同一个自定义校验注解使用validatedBy属性 // 进行多个校验器的关联,校验注解会自动根据注解标注参数的类型自动地选出对应类型的校验器进行校验 @Constraint( validatedBy = {ListValueConstraintValidator.class} ) @Target({ElementType.METHOD, ElementType.FIELD, ElementType.ANNOTATION_TYPE, ElementType.CONSTRUCTOR, ElementType.PARAMETER, ElementType.TYPE_USE}) @Retention(RetentionPolicy.RUNTIME) //可重复注解,ListValue.List是校验注解内部自定义的可重复注解容器 @Repeatable(ListValue.List.class) public @interface ListValue { //JSR303规范中message消息都统一在ValidationMessages.properties //我们也可以创建一个和该文件名一样的文件,在其中写对应的消息,Spring找不到会自动到自定义的同名文件中查找 //消息的属性名一般都使用注解全类名.message String message() default "{com.earl.common.validate.annotation.ListValue.message}"; Class<?>[] groups() default {}; Class<? extends Payload>[] payload() default {}; int[] vals() default {}; //java8新特性,定义可重复注解,一个注解可能对多种情况进行分组标注,可能使用多个相同注解,这是校验注解的重复注解定义 @Target({ElementType.METHOD, ElementType.FIELD, ElementType.ANNOTATION_TYPE, ElementType.CONSTRUCTOR, ElementType.PARAMETER, ElementType.TYPE_USE}) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface List { ListValue[] value(); } } -
创建
ValidationMessages.properties同名文件并配置默认消息提示这个属性配置文件properties文件可能中文读取会乱码,这个地方需要修改IDEA的File–Setting–Editor–File Encodings–将Properties Files中的Transparent native-to-ascii conversion勾选上并重新创建文件【最好将File Encodings中的所有编码格式都改成UTF-8】
com.earl.common.validate.annotation.ListValue.message=必须提交指定的值 -
自定义校验器
/** * @author Earl * @version 1.0.0 * @描述 * 自定义注解需要实现ConstraintValidator接口 * ConstraintValidator<A extends Annotation, T>有两个泛型,第一个泛型是关联的注解@ListValue,第二个 * 泛型是@ListValue注解能标注的地方,该接口中有两个抽象方法 * @创建日期 2024/02/28 * @since 1.0.0 */ public class ListValueConstraintValidator implements ConstraintValidator<ListValue,Integer> { private Set<Integer> set=new HashSet<>(); /** * @param constraintAnnotation * @描述 该方法能获取到ListValue注解中的属性值,该属性值能在isValid中对数据进行校验,遍历vals中的值封装到set集合中供 * initialize方法对实际传参进行判断 * @author Earl * @version 1.0.0 * @创建日期 2024/02/28 * @since 1.0.0 */ @Override public void initialize(ListValue constraintAnnotation) { int[] vals = constraintAnnotation.vals(); for (int val:vals) { set.add(val); } } /** * @param value 要检验的实际入参 * @param context * @return boolean * @描述 判断是否校验成功 * @author Earl * @version 1.0.0 * @创建日期 2024/02/28 * @since 1.0.0 */ @Override public boolean isValid(Integer value, ConstraintValidatorContext context) { return set.contains(value); } }
Elasticsearch-Rest-Client
- 业务中ES检索请求的处理逻辑是前端发起检索请求给后端Java服务器,Java服务器向ES服务器发起检索请求获取数据并响应给前端,Java客户端操作ES的方式有两种
- 第一种方式是使用
spring-data-elasticsearch:transport-api.jar通过ES的TCP端口9300,也即节点间的通信端口;这种方式SpringBoot版本不同,对应的transport-api.jar也不同,更换ES的版本就要更换对应的transport-api.jar和SpringBoot的版本,而且ES版本对应的transport-api.jar根本就没出或者SpringBoot压根还没整合,这样不好;其次7.x版本已经不建议使用transport-api.jar,8以后就直接准备废弃了通过9300端口操作ES的jar包 - 第二种方式是通过HTTP协议走9200端口发送请求操作ES,市面上通过这种方式操作ES的产品有
- JestClient:非官方,更新慢,从maven仓库可以查询到最近版本的更新时间,比较慢,落后ES好几个小版本
- RestTemplate:这个产品只是模拟发送HTTP请求,ES很多操作需要自己进行封装,封装起来很麻烦
- HttpClient:该产品也只是模拟发送HTTP请求,ES的相关请求和响应数据处理需要自己封装,很麻烦;像这些只能用来发送HTTP请求的如OKHTTP等等都可以操作ES,但是DSL语句和响应结果需要自己封装工具进行处理
- Elasticsearch-Rest-Client:官方RestClient,封装了ES操作,API层次比较分明,官方的ES发布到哪个版本,这个工具也会同时更新相应的版本,本项目就使用该客户端
- 据说有个开源的ebatis,用起来也非常爽
- Elasticsearch-Rest-Client的官方文档在ES的Docs中的Elasticsearch Clients章节,里面列举了各种语言对ES的操作API,其中还有JavaScript客户端,但是ES一般属于后台服务器集群中一部分,一般不直接对外暴露,暴露可能会被公网恶意利用;使用js操作也不需要使用ES官方的工具,直接用js发送请求即可;Java API是基于9300端口操作ES的【而且文档标记7.0版本已经过时,在8.0版本将移除,在文档中推荐使用Java High Level REST Client,Java High Level REST Client是Java REST Client中两个工具的一种,还有一种是Java Low Level REST Client,两者的关系相当于mybatis和JDBC的关系;现在8.13版本都过时了,现在只有一个
Java Client了】,Java REST Client是基于9200端口操作ES的- ❓:为什么不用js发送查询请求,由nginx进行转发呢,还是因为安全的原因吗?反正就是用后端服务器调用来查询,以后再去看实际的情况
- 创建一个单独的模块
mall-search来使用Elasticsearch-Rest-Client中的Java High Level REST Client来操作ES服务器集群
-
搭建操作ES的模块
-
1️⃣:创建模块
mall-search,勾选整合Web中的Spring Web- 说明:NoSQL中有个Spring Data Elasticsearch因为最新只整合到6.3版本的ES【当时ES的最新版本是7.4】,所以就不考虑SpringData Elasticsearch,如果ES使用的版本不是那么新,选择SpringData Elasticsearch其实也是很好的选择,相比于官方的Elasticsearch-Rest-Client做了更简化的封装
-
2️⃣:导入
Java High Level REST Client的maven依赖,将版本号改为对应ES服务器的版本号,将ES服务器的版本号在properties标签中进行重新指定- 注意通过右侧的maven依赖树能够看到elasticsearch-rest-high-level-client虽然版本是7.4.2,但是子依赖中的部分版本还是6.8.5,这是因为SpringBoot对ES的版本进行了默认仲裁,SpringBoot2.2.2.RELEASE当引入SpringData Elasticsearch会自动仲裁Elasticsearch的版本为6.8.5【点开父依赖中的
spring-boot-starter-parent的父依赖的spring-boot-dependencies能够看见相关的版本信息】
<!--导入es的rest-high-level-client--> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.4.2</version> </dependency>-
更改SpringBoot对Elasticsearch的版本自动仲裁,刷新maven直到依赖树中的相关依赖版本全部变成7.4.2
<properties> <elasticsearch.version>7.4.2</elasticsearch.version> </properties>
- 注意通过右侧的maven依赖树能够看到elasticsearch-rest-high-level-client虽然版本是7.4.2,但是子依赖中的部分版本还是6.8.5,这是因为SpringBoot对ES的版本进行了默认仲裁,SpringBoot2.2.2.RELEASE当引入SpringData Elasticsearch会自动仲裁Elasticsearch的版本为6.8.5【点开父依赖中的
-
3️⃣:对
rest-high-level-client进行配置-
🔎:如果使用SpringData Elasticsearch对ES操作,配置就非常简单,这个在ES的整合SpringData Elasticsearch中已经实现了,这里要配置我们自己选择的
rest-high-level-client会稍微复杂一些 -
编写配置类
MallElasticsearchConfig并注入IoC容器,这个配置类参考ES的官方文档Java High Level REST Client中的Getting started中的Initialization- 需要创建一个
RestHighLevelClient实例client,通过该实例来创建ES的操作对象
【单节点集群的创建客户端实例】
/** * @author Earl * @version 1.0.0 * @描述 对Java High Level REST Client进行配置,配置ES操作对象 * @创建日期 2024/05/24 * @since 1.0.0 */ @Configuration public class MallElasticSearchConfig { /** * @return {@link RestHighLevelClient } * @描述 通过单节点集群的ip地址和端口以及通信协议名称来创建RestHighLevelClient对象 * @author Earl * @version 1.0.0 * @创建日期 2024/05/24 * @since 1.0.0 */ @Bean public RestHighLevelClient esRESTClient(){ RestHighLevelClient client = new RestHighLevelClient( RestClient.builder(new HttpHost("192.168.56.10", 9200, "http")) ); return client; } }【多节点集群下的创建客户端实例】
- 多节点集群就在
RestClient.builder(HttpHost...)方法中的可变长度参数列表中输入各个节点的IP信息
@Bean public RestHighLevelClient esRESTClient(){ RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("localhost", 9200, "http"), new HttpHost("localhost", 9201, "http") ) ); return client; } - 需要创建一个
-
-
4️⃣:导入模块
mall-common引入注册中心【这里面引入的其他依赖挺多的,包含mp、Lombok、HttpCore、数据校验、Servlet API等】,配置配置中心、注册中心,服务名称在主启动类上使用注解@EnableDiscoveryClient开启服务的注册发现功能,在主启动类使用@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)排除数据源【配置中心
bootstrap.properties配置】- 注意
bootstrap.properties文件必须在引入nacos的配置中心依赖后才会展示出小叶子图标
spring.application.name=mall-stock spring.cloud.nacos.config.server-addr=127.0.0.1:8848 spring.cloud.nacos.config.namespace=9c29064b-64f8-4a43-9375-eceb6e3c7957 - 注意
-
5️⃣:编写测试类检查ES操作对象是否创建成功
- 只要能打印出client对象,说明成功连接并创建ES操作对象,后续只需要参考官方文档使用对应的API即可,对应的文档也在Java High Level REST Client中的所有APIs部分
@RunWith(SpringRunner.class)//指定使用Spring的驱动来跑单元测试,这是老版本SpringBoot的写法,新版本已经不这么写了 @SpringBootTest public class MallSearchApplicationTests { @Autowired private RestHighLevelClient esRESTClient; @Test public void contextLoads() { System.out.println(esRESTClient);//org.elasticsearch.client.RestHighLevelClient@3c9c6245 } }
-
fastjson
-
引入依赖
<dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.47</version> </dependency>-
🔎:注意nacos注册中心
spring-cloud-alibaba-nacos-discovery的父依赖nacos-client的父依赖nacos-api的父依赖中自带fastjson<!--nacos注册中心--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-nacos-discovery</artifactId> </dependency>
-
API
-
String--->JSON.toJSONString(Object object)- 功能解析:将对象
object转换为json格式字符串 - 使用示例:
String userJSONStr = JSON.toJSONString(user);- 示例含义:将user对象转换为json格式字符串
- 功能解析:将对象
-
T--->JSON.paseObject(String jsonStr,Class T.class)- 功能解析:将Json格式字符串jsonStr转换为指定对象T
- 使用示例:``
- 示例含义:将商品文档json数据转换为Product对象
-
使用fastjson的TypeReference指定要将Map类型的键值对转换为指定的数据类型,
- 原理是先将Map转换成json,再用fastjson将json字符串转成通过泛型指定的实体类
- 这种用法一般用在如服务调用,调用方拿到数据默认会将属性对应的json对象【包含多个属性】转换成LinkedHashMap,这是因为json格式的k-v数据天然符合Map类型的数据组织形式,默认转换成Map方便数据的读取,但是这样就无法将Map类型的数据强转为我们的目标类型如To类,这时候就可以使用fastjson的TypeReference来将Map转成json,再将json转成我们指定的目标数据类型
【响应类封装转换数据类型的fastjson的TypeReference】
public class R extends HashMap<String, Object> { private static final long serialVersionUID = 1L; //使用泛型需要声明泛型,方法中使用的泛型在方法名前面声明<T> T public <T> T getData(TypeReference<T> typeReference){ //接收到的Object类型里面的对象被自动反序列化成Map了,因为互联网传输过程中使用JSON天然符合Map特性 //系统底层默认转成Map是为了更方便数据的读取,R里面data存的数据的数据类型默认是LinkedMap类型的,LinkedHashMap无法被强转为我们自定义的To类 //需要使用fastjson的TypeReference先将Map转换成json,再用fastjson将json字符串转成通过泛型指定的实体类 Object data =get("data"); String dataJSONStr = JSON.toJSONString(data); T t = JSON.parseObject(dataJSONStr, typeReference); return t; } public R setData(Object data){ put("data",data); return this; } public R() { put("code", 0); put("msg", "success"); } public static R error() { return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, "未知异常,请联系管理员"); } public static R error(String msg) { return error(HttpStatus.SC_INTERNAL_SERVER_ERROR, msg); } public static R error(int code, String msg) { R r = new R(); r.put("code", code); r.put("msg", msg); return r; } public static R ok(String msg) { R r = new R(); r.put("msg", msg); return r; } public static R ok(Map<String, Object> map) { R r = new R(); r.putAll(map); return r; } public static R ok() { return new R(); } public R put(String key, Object value) { super.put(key, value); return this; } /** * @return {@link Integer } * @描述 获取响应的响应码判断响应状态 * @author Earl * @version 1.0.0 * @创建日期 2024/03/26 * @since 1.0.0 */ public Integer getCode(){ return (Integer) this.get("code"); } }【在调用者解析并将数据转换为指定类型】
Map<Long, Boolean> stockStatus = null; try{ //远程服务调用获取数据并将数据利用fastjson的TypeReference转换成指定目标数据类型List<SkuStockExistTo> List<SkuStockExistTo> skuStockExistTos = stockFeignClient.isStockExist(skuIds).getData(new TypeReference<List<SkuStockExistTo>>() { }); //将该集合skuStockExistTos转成Map准备属性对拷 stockStatus = skuStockExistTos.stream().collect(Collectors.toMap(SkuStockExistTo::getSkuId, SkuStockExistTo::getIsExist)); }catch (Exception e){ log.error("远程调用库存服务异常,原因:{}",e); }
dev-tools
-
引入依赖
- 引入以后修改文件还是需要重新编译整个项目或者重新编译当前资源【Ctrl+Shift+F9】才能在前端看到对应效果,据说使用jrebel插件可以更高效地大道热部署效果
- 如果是配置更改推荐还是重启项目,避免出现各种问题
<!--不重启服务器实现代码动态更新dev-tools,本质是修改代码自动触发重新启动--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <optional>true</optional> </dependency>
Thymeleaf
-
集中修改首页中对静态资源的超链接方法[给所有静态资源的uri添加前缀static],这个要根据具体情况具体分析啊,链接的写法很多样,比如很多喜欢以当前路径开始,此时这么修改就是错误的,这里只是展示所有的链接标签,实际修改要根据链接的情况来确定
href="替换为href="/static,<script src="替换为<script src="static/,<img src="替换为<img src="static/<src="index替换为<src="static/index
-
注意如果属性值是常量字符串,比如
action="/registry",此时使用Thymeleaf来处理该属性可能会报错,比如th:action="/registry"此时后端就会报错Thymeleaf渲染出错 -
通过
Thymeleaf来从error这个Map中获取错误校验信息,在没有发生校验错误的情况下error会为null,此时仍然从error中获取错误校验信息就会出现空指针异常,只有在error不为null的情况下才去执行从error中获取对应参数的错误校验信息- 注意即使
Map类型的error不为null,但是Map中没有指定的属性如username,此时仍然使用error.get("username"),Thymeleaf仍然会报错,即Map不包含指定key的数据但是仍然进行取值Thymeleaf会直接报错,我们还需要通过Thymeleaf对Map处理的API#maps.containsKey(map,key)来判断Map类型的error中是否包含key为username的数据,包含才进行取值,不包含就不取值
- 注意即使
-
在商品模块引入Thymeleaf依赖做首页渲染
-
pom.xml
<!--模板引擎Thymeleaf--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-thymeleaf</artifactId> </dependency> -
将首页用到的静态资源目录index拷贝到类目录下的static目录下,将首页模板页面放在类路径目录
template目录下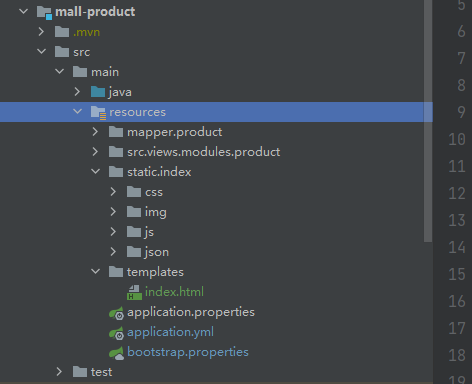
-
-
Thymeleaf相关配置
-
在
application.yml使用下列配置关闭Thymeleaf的缓存- 关闭Thymeleaf缓存,这样开发期间就能看见实时的更改效果
- Thymeleaf的前缀默认配置
spring.thymeleaf.prefix="classpath:/templates/" - 后缀默认配置是
spring.thymeleaf.suffix=".html"
Spring: thymeleaf: cache: false #关闭Thymeleaf缓存,这样开发期间就能看见实时的更改效果 -
在项目包
com.earl.product目录下创建web包用来专门放商城前台的控制器方法 -
静态资源目录
-
静态资源放在默认的
static目录下可以通过路径如http://127.0.0.1:9000/index/css/GL.css直接访问【访问不到可能是target目录没有载入】,静态页面模板index.html放在template目录下此时可以直接通过http://127.0.0.1:9000直接访问,注意默认不能通过http://127.0.0.1:9000/index.html访问【默认情况下没有做对应URI为index.html的映射】 -
注意项目里的前端静态资源统一加了
static前缀,即http://127.0.0.1:10000/static/index/css/GL.css,此时对应的静态资源需要放在目录static/static下,使用下列配置让SpringBoot忽略static前缀,这样将静态资源放在static目录下即可访问Spring: thymeleaf: cache: false #关闭Thymeleaf缓存,这样开发期间就能看见实时的更改效果 mvc: static-path-pattern: /static/** #这里前端所有的静态资源路径加了static前缀,使用该配置让SpringBoot处理过程中去掉该前缀,这样仍然将index目录放在static目录下即可,而不需要放在static/static目录下
-
-
-
业务逻辑演示
-
设置URI路径数组跳转的首页视图
-
引入
Thymeleaf就是要做视图渲染的,因为才需要控制器方法来获取数据并存入视图,如果只是访问页面不需要视图数据渲染,不需要控制器方法也能根据路径匹配到对应的index.html -
注意使用
Thymeleaf渲染页面,控制器方法要响应对应的页面,不能在控制器方法上加@ResponseBody注解,这样会直接导致响应对象 -
❓:注意一下这里有点问题,在不配置控制器方法的情况下,浏览器只能通过
search.earlmall.com/直接访问到templates/index.html,竟然连search.earlmall.com/index.html都访问不到,而且将index.html转移到SpringBoot的静态文件默认路径static下也不行,真让人摸不着头脑,复习SpringBoot的时候注意一下这个地方
-
-
@Controller
public class IndexController {
/**
* @return {@link String }
* @描述 匹配uri为"/"和"/index.html"都跳转首页视图
* 1. Thymeleaf的前缀默认配置spring.thymeleaf.prefix="classpath:/templates/"
* 2. 后缀默认配置是spring.thymeleaf.suffix=".html"
* 3. 返回视图地址,视图解析器会自动对视图地址进行拼串 前缀+返回值+后缀 即视图地址
* @author Earl
* @version 1.0.0
* @创建日期 2024/06/03
* @since 1.0.0
*/
@GetMapping({"/","/index.html"})
public String urisToIndexPage(){
return "index";
}
}
-
跳转页面后需要查询到所有商品的一级分类。模板中数据是写死的,使用
ModelAndView来缓存数据并从视图中取出相应的数据- 从表
pms_category中查询出所有一级分类商品,特征是字段cat_level字段属性值为1 - 使用
Thymeleaf从ModelAndView中获取数据渲染到视图中需要使用Thymeleaf的语法,[Thymeleaf官方文档-英文](Documentation - Thymeleaf),点击Using Thymeleaf下的链接可以下载对应版本的说明文档,包括PDF、EPUB、MOBI等等版本 - 使用
Thymeleaf的优点是渲染以html为后缀的文件,浏览器可以直接打开,和前端沟通起来成本小,使用JSP浏览器打不开且前端不好做优化
【获取一级分类数据并存入
ModelAndView】model.addAttribute("firstLevelCategories",firstLevelCategories);需要指明变量的名称,否则只有打断点才知道对应变量的名称
@Controller public class IndexController { @Autowired private CategoryService categoryService; /** * @return {@link String } * @描述 匹配uri为"/"和"/index.html"都跳转首页视图 * 1. Thymeleaf的前缀默认配置spring.thymeleaf.prefix="classpath:/templates/" * 2. 后缀默认配置是spring.thymeleaf.suffix=".html" * 3. 返回视图地址,视图解析器会自动对视图地址进行拼串 前缀+返回值+后缀 即视图地址 * 4. 在跳转首页的过程中将数据查询出来放在ModelAndView中等待渲染 * @author Earl * @version 1.0.0 * @创建日期 2024/06/03 * @since 1.0.0 */ @GetMapping({"/","/index.html"}) public String urisToIndexPage(Model model){ List<CategoryEntity> firstLevelCategories=categoryService.getAllFirstLevelCategory(); model.addAttribute("firstLevelCategories",firstLevelCategories); return "index"; } }【使用Thymeleaf语法需要在渲染视图引入Thymeleaf的名称空间
xmlns:th="http://www.thymeleaf.org"】- 注意:
<!DOCTYPE html>是H5的标头
<html lang="en" xmlns:th="http://www.thymeleaf.org"> ... </html>【获取变量并渲染成标签的文本内容】
th:text="${}"表示获取变量并将其渲染成文本填充到当前标签
<div th:text="${}"> </div>【表格遍历语法】
<tr th:each="prod : ${prods}">的作用是循环遍历指定元素prods,并根据元素集合中元素的个数决定循环创建多少个当前tr标签及其子标签,${prods}是要遍历的元素,prod是当前元素,使用th:text来展示当前元素的各个属性变量【如果标签已经有文本,会使用当前变量值直接进行替换】,th:each表示有多少个子元素就会生成多少个tr标签和其子标签,这个标签也可以是其他html标签
<table> <tr> <th>NAME</th> <th>PRICE</th> <th>IN STOCK</th> </tr> <tr th:each="prod : ${prods}"> <td th:text="${prod.name}">Onions</td> <td th:text="${prod.price}">2.41</td> <td th:text="${prod.inStock}? #{true} : #{false}">yes</td> </tr> </table> - 从表
-
使用Thymeleaf渲染商品一级分类列表
- Thymeleaf自定义属性
th:attr="ctg-data=${category.catId},渲染后的展示效果是ctg-data=商品分类id,该属性是用来查询该分类id下的二三级商品分类的
<ul> <li th:each="category : ${firstLevelCategories}"> <a href="#" class="header_main_left_a" th:attr="ctg-data=${category.catId}"> <b th:text="${category.name}"></b> </a> </li> </ul> - Thymeleaf自定义属性
语法
-
获取请求路径中的参数并渲染到页面中
${param.keyword}中param表示请求路径中的所有参数,param.keyword表示从所有请求路径的参数中获取keyword这个参数的参数值,如果该参数没有参数则显示placeholder属性的值
<div class="header_form"> <input type="text" id="keyword_input" placeholder="手机" th:value="${param.keyword}"/> <a href="javascript:specifySearchParamKeyword()">搜索</a> </div> -
Thymeleaf在字符串中拼接变量的写法th:href="|http://item.earlmall.com/${product.skuId}.html|"即用两个竖线将字符串框起来 -
Thymeleaf的#lists.contains(list,elements)能判断list集合中是够含有某个元素 -
Thymeleaf提供对两个数字之间的所有整数进行遍历的numbers.sequence函数,使用方法是th:each="i:${#numbers.sequence(1,totalPages)}",作用是对数字1和总页数totalPages之间的所有整数进行遍历,i是每次取出的整数 -
Thymeleaf的Numbers章节的Formatting decimal Numbers展示了格式化api,其中${#numbers.formatDecimal(num,3,2)}表示num整数位保留3位,小数位保留2位,整数位超出3位也能正常显示 -
th:each="val:${#strings.listSplit(String str,',')}"将字符串用逗号分隔返回字符串片段数组 -
th:if="${!#strings.isEmpty(skuImage.imgUrl)}",其中的#strings.isEmpty(skuImage.imgUrl)是判断字符串是否为空值
Redis
整合Redis
-
安装
redis以及构建集群见Linux指南中的安装redis部分 -
SpringBoot配置
-
引入场景启动器依赖
<!--redis做缓存操作,搜索RedisAutoConfiguration能找到redis相关配置对应的属性类,所有相关配置都在该属性类中--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> -
SpringBoot对redis的配置
- host指定redis所在主机地址,
- port指定redis在主机上的端口号,默认就是6379
- 如果指定了用户和密码还可以在配置文件中指定用户和密码,默认安装没有密码和用户名
Spring: redis: host: 192.168.56.10 port: 6379
-
操作Redis
-
redis的自动配置类
- redis的自动配置类给容器中添加了
RedisTemplate<Object,Object>对象【对应k-v键值对的数据】,用于操作redis对数据进行CRUD操作 - 一般操作k-v键值对都是字符串较多,因此自动配置类还专门给容器添加了一个
StringRedisTemplate对象,该类继承自RedisTemplate<String,String>,对应的key和value是用String的序列化来做的- 🔎:
StringRedisTemplate对象和RedisTemplate<Object,Object>对象的区别是序列化器不一样,RedisTemplate<Object,Object>对象默认使用的是JDK的序列化器defaultSerializer=new JdkSerializationRedisSerializer,意为着如果我们使用RedisTemplate<Object,Object>对象来操作Redis,写入redis中的数据都是二进制的,没有可读性,即便服务器写入字符串,存入redis中的数据也会变成二进制的数据,在redis客户端上根本无法浏览;如果要使用RedisTemplate<Object,Object>对象需要设置对应的序列化器为String或者json的序列化器; - 🔎:
StringRedisTemplate对象就是使用的String的序列化器,RedisSerializer.string()就是给StringRedisTemplate对象设置Sting序列化器的方法,使用StringRedisTemplate对象存放的时候数据是怎么样的,读取出来就是怎么样的,使用该对象操作Redis可读性非常高,操作字符串k-v键值对直接使用StringRedisTemplate对象即可
- 🔎:
【
StringRedisTemplate的源码】- 注意这个
RedisSerializer.string()
public class StringRedisTemplate extends RedisTemplate<String, String> { public StringRedisTemplate() { setKeySerializer(RedisSerializer.string()); setValueSerializer(RedisSerializer.string()); setHashKeySerializer(RedisSerializer.string()); setHashValueSerializer(RedisSerializer.string()); } public StringRedisTemplate(RedisConnectionFactory connectionFactory) { this(); setConnectionFactory(connectionFactory); afterPropertiesSet(); } protected RedisConnection preProcessConnection(RedisConnection connection, boolean existingConnection) { return new DefaultStringRedisConnection(connection); } } - redis的自动配置类给容器中添加了
-
RedisTemplate的使用
-
代码示例
@RunWith(SpringRunner.class) @SpringBootTest public class MallProductApplicationTests { @Autowired StringRedisTemplate stringRedisTemplate; @Test public void testStringRedisTemplate(){ //RedisTemplate下有很多opsXXX,这主要牵扯到redis中不同的数据类型,本项目基本使用以下五种类型,更多后面复习redis再说 //1. stringRedisTemplate.opsForValue() 这是存放简单类型 //拿到ops操作对象 ValueOperations<String, String> ops = stringRedisTemplate.opsForValue(); //保存数据 ops.set("Hello","world_"+ UUID.randomUUID()); //从redis中查询对应key的数据 String hello = ops.get("Hello"); System.out.println("Hello:"+hello);//Hello:world_46a44c4e-8436-4eb0-9dc6-86f49e6aa2e2 //stringRedisTemplate.opsForHash() 这是value类型也是一个Map类型 //stringRedisTemplate.opsForList() 这是value类型是一个数组 //stringRedisTemplate.opsForSet() 这是value类型是一个Set集合 //stringRedisTemplate.opsForZSet() 这是value类型是一个ZSet带排序集合类型 } } -
redis中的存入的数据
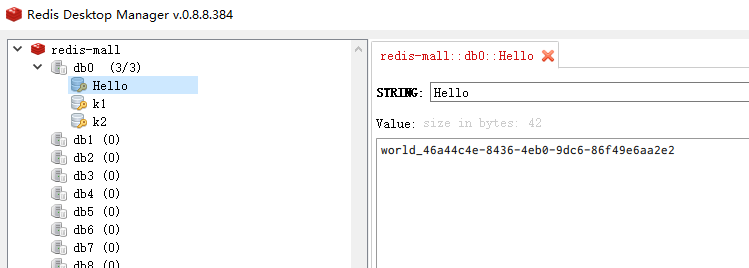
-
jol-core
- jol-core用来查看java对象的对象头信息,这是openjdk提供的
-
引入依赖
<!-- https://mvnrepository.com/artifact/org.openjdk.jol/jol-core --> <dependency> <groupId>org.openjdk.jol</groupId> <artifactId>jol-core</artifactId> <version>0.17</version> </dependency> -
使用方法
- 这里老师修改了原来的jar包重新打包的,里面的api是他自定义的,B站没有相关教程,后续看文档补充,后续更改使用jol-core自身的api以后成功运行
package cn.itcast.n4; import lombok.extern.slf4j.Slf4j; import org.openjdk.jol.info.ClassLayout; import java.io.IOException; import java.util.Vector; import java.util.concurrent.locks.LockSupport; // -XX:-UseCompressedOops -XX:-UseCompressedClassPointers -XX:BiasedLockingStartupDelay=0 -XX:+PrintFlagsFinal //-XX:-UseBiasedLocking tid=0x000000001f173000 -XX:BiasedLockingStartupDelay=0 -XX:+TraceBiasedLocking @Slf4j(topic = "c.TestBiased") public class TestBiased { /* [t1] - 29 00000000 00000000 00000000 00000000 00011111 01000101 01101000 00000101 [t2] - 29 00000000 00000000 00000000 00000000 00011111 01000101 11000001 00000101 */ public static void main(String[] args) throws IOException, InterruptedException { test1(); } private static void test5() throws InterruptedException { log.debug("begin"); for (int i = 0; i < 6; i++) { Dog d = new Dog(); log.debug(ClassLayout.parseInstance(d).toPrintable()); Thread.sleep(1000); } } static Thread t1, t2, t3; private static void test4() throws InterruptedException { Vector<Dog> list = new Vector<>(); int loopNumber = 39; t1 = new Thread(() -> { for (int i = 0; i < loopNumber; i++) { Dog d = new Dog(); list.add(d); synchronized (d) { log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintable()); } } LockSupport.unpark(t2); }, "t1"); t1.start(); t2 = new Thread(() -> { LockSupport.park(); log.debug("===============> "); for (int i = 0; i < loopNumber; i++) { Dog d = list.get(i); log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintable()); synchronized (d) { log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintable()); } log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintable()); } LockSupport.unpark(t3); }, "t2"); t2.start(); t3 = new Thread(() -> { LockSupport.park(); log.debug("===============> "); for (int i = 0; i < loopNumber; i++) { Dog d = list.get(i); log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintable()); synchronized (d) { log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintable()); } log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintable()); } }, "t3"); t3.start(); t3.join(); log.debug(ClassLayout.parseInstance(new Dog()).toPrintable()); } private static void test3() throws InterruptedException { Vector<Dog> list = new Vector<>(); Thread t1 = new Thread(() -> { for (int i = 0; i < 30; i++) { Dog d = new Dog(); list.add(d); synchronized (d) { log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintable()); } } synchronized (list) { list.notify(); } }, "t1"); t1.start(); Thread t2 = new Thread(() -> { synchronized (list) { try { list.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug("===============> "); for (int i = 0; i < 30; i++) { Dog d = list.get(i); log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintable()); synchronized (d) { log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintable()); } log.debug(i + "\t" + ClassLayout.parseInstance(d).toPrintable()); } }, "t2"); t2.start(); } // 测试撤销偏向锁 private static void test2() throws InterruptedException { Dog d = new Dog(); Thread t1 = new Thread(() -> { synchronized (d) { log.debug(ClassLayout.parseInstance(d).toPrintable()); } synchronized (TestBiased.class) { TestBiased.class.notify(); } }, "t1"); t1.start(); Thread t2 = new Thread(() -> { synchronized (TestBiased.class) { try { TestBiased.class.wait(); } catch (InterruptedException e) { e.printStackTrace(); } } log.debug(ClassLayout.parseInstance(d).toPrintable()); synchronized (d) { log.debug(ClassLayout.parseInstance(d).toPrintable()); } log.debug(ClassLayout.parseInstance(d).toPrintable()); }, "t2"); t2.start(); } // 测试偏向锁 private static void test1() { Dog d = new Dog(); log.debug(ClassLayout.parseInstance(d).toPrintable()); try { Thread.sleep(4000); } catch (InterruptedException e) { e.printStackTrace(); } log.debug(ClassLayout.parseInstance(new Dog()).toPrintable()); } } class Dog { }
commons-lang3
- 工具包,包括字符串处理工具类
StringUtils等功能
-
引入依赖
<dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> </dependency>
API
StringUtils
boolean--->StringUtils.equals(CharSequence cs1, CharSequence cs2)-
功能解析:比较两个字符序列
cs1、cs2是否相等,如果相等该方法返回true,如果不相等返回false;该方法区分字符串的大小写,如StringUtils.equals("abc","ABC") = false -
使用示例:
queryWrapper.eq(dadAge,momAge);- 示例含义:检查字符串变量
dadAge和字符串变量momAge的字符内容和次序是否相等
- 示例含义:检查字符串变量
-
补充说明:
- 🔎:
String类型实现了CharSequence接口 - 🔎:该
StringUtils.equals(CharSequence cs1, CharSequence cs2)方法的参数列表的任意参数传参null都不会抛异常,如StringUtils.equals(null, null) = true,StringUtils.equals(null, "abc") = false,StringUtils.equals("abc",null) = false
- 🔎:
-
boolean ---> StringUtils.startsWith(final CharSequence str, final CharSequence prefix)- 功能解析:判断字符串
str是否以字符串prefix作为前缀,如果是则返回true,否则返回false - 使用示例:
StringUtils.startWith(str,"lock-")- 示例含义:判断字符串
str是否以lock-作为前缀,是返回true,否则返回false
- 示例含义:判断字符串
- 功能解析:判断字符串
String ---> StringUtils.substringAfterLast(final String str, final String separator)- 功能解析:截取字符串
str中最后一个separator字符或字符串后面的内容,不包含separator字符或字符串 - 使用示例:
StringUtils.substringAfterLast(str,"/")- 示例含义:截取字符串
str最后一个/后面的内容
- 示例含义:截取字符串
- 功能解析:截取字符串
DigestUtils
-
String ---> DigestUtils.md5Hex(String data)- 功能解析:将文本数据转换成16进制格式的MD5值
- 使用示例:
String s=DigestUtils.md5Hex("123456")- 示例含义:将字符串转换为对应的16进制MD5值
- 补充说明:
- 这是基本的MD5加密算法,不是加盐版本,计算出的密文大部分都可以通过彩虹表还原出原文
-
String ---> DigestUtils.md5Crypt(Bytes bytes)- 功能解析:在文本数据data前加上盐
$1$+8位随机字符然后一起计算MD5值 - 使用示例:
String s=DigestUtils.md5Crypt("123456".getBytes())- 示例含义:将字符串数据前加上随机盐值后再整体计算MD5值
- 补充说明:
- 这里的盐值是随机的,格式为
$1$+8位随机字符,添加位置是我猜的,后面验证一下
- 这里的盐值是随机的,格式为
- 功能解析:在文本数据data前加上盐
-
String ---> DigestUtils.md5Crypt(Bytes bytes,String salt)- 功能解析:在文本数据data前加上盐
$1$+8位随机字符然后一起计算MD5值 - 使用示例:
String s=DigestUtils.md5Crypt("123456".getBytes(),"$1$qqqqqqqq")- 示例含义:将字符串数据
123456前加上盐值$1$qqqqqqqq后再整体计算MD5值
- 示例含义:将字符串数据
- 补充说明:
- 我们可以使用随机盐值对用户密码进行加密,同时保存加密使用的盐值,验证的时候再取出盐值进行验证
- 功能解析:在文本数据data前加上盐
zookeeper客户端
- Zookeeper官方提供的Java客户端,用于在Java应用程序中实现对Zookeeper服务器的操作
-
使用官方Zookeeper客户端
-
引入依赖
-
在zookeeper的客户端中已经引入了
slf4j-log4j12,如果已经在其他地方也引入就会有Slf4j日志标红提示,老师的解决办法是从zookeeper的依赖中移除slf4j-log4j12-
我认为这里老师讲的是错误的,因为maven会自动处理重复的依赖项,除非两个相同依赖的版本不一致,另一方面从依赖树形结构图中没有找到期望被移除的
slf4j-log4j12,从报错信息上来看是logback-classic1.2.11中的org.slf4j.impl.StaticLoggerBinder.class和slf4j-reload4j.1.7.36中的org.slf4j.impl.StaticLoggerBinder.class两个类发生了冲突,通过网络搜索发现网上那个和slf4j-log4j12冲突的报错信息确实是slf4j-log4j12-1.7.25.jar,总之就是logback和log4j之间关于org/slf4j/impl/StaticLoggerBinder.class这个类发生的冲突,不同jar包下的相同的全限定类名的类在不破坏JVM的双亲委派模型类加载机制情况下全限定类名相同的类只会加载被先加载的jar包中的对应类,jar包的加载顺序和classpath参数有关,包路径越靠前越先被加载,加载顺序靠后的jar包中的全限定类名相同的类会被直接忽略掉不会再被加载,SpringBoot的默认日志是logback,log4j是以前的主流日志,很多第三方工具包都使用的是log4j,解决办法是排除logback或者log4j的其中一个,让整个项目使用其中的一种日志;【具体原因还需要深入分析】【报错信息】
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/D:/maven-repository/ch/qos/logback/logback-classic/1.2.11/logback-classic-1.2.11.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/D:/maven-repository/org/slf4j/slf4j-reload4j/1.7.36/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [ch.qos.logback.classic.util.ContextSelectorStaticBinder]【springboot排除logback依赖实例】
- 排除
logback就要把项目中所有的logback都排除,只使用log4j
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> <exclusions> <!-- 排除自带的logback依赖 --> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <exclusions> <!-- 排除自带的logback依赖 --> <exclusion> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-logging</artifactId> </exclusion> </exclusions> </dependency> - 排除
-
【正常依赖】
<dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.7.0</version> </dependency>【老师的排除
slf4j-log4j12示例】- 🔎:这个方式是有效的
<dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.7.0</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> </exclusions> </dependency>【实测排除
slf4j-reload4j也行】<dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.7.0</version> <exclusions> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-reload4j</artifactId> </exclusion> </exclusions> </dependency> -
-
-
zookeeper客户端对象的获取
Zookeeper对象通过构造方法创建,构造方法只能是有参构造,必须传参连接字符串connectString、连接超时时间sessionTimeOut、监听器watcher,该对象使用完以后必须调用close方法来手动关闭连接- 连接字符串
connectString:格式必须为"127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002",参数值是Zookeeper服务器集群的地址- 用逗号分隔各地址,注意逗号两边不能有空格
- 连接超时时间
sessionTimeOut:参数为int类型,单位是毫秒 - 监听器
Watcher:Watcher是一个接口,需要使用匿名内部类的方式重写process方法来实例化对象,process方法会在连接建立时和连接关闭时各执行一次 - 注意调用完Zookeeper的构造方法以后还在获取连接程序就会执行后续的代码,此时zookeeper对象只是赋值了对象地址因为建立连接较慢还没有完成初始化,其中的功能是无法正常使用,此时需要使用闭锁
CountdownLatch来实现对zookeeper初始化进行等待的效果
- 连接字符串
- zookeeper对象的API简介
zookeeper.create()方法能创建节点zookeeper.exist()方法能判断某个节点是否存在zookeeper.getChildren()方法能获取节点的子节点和数据内容
public static void main(String[] args) { ZooKeeper zooKeeper = null; try { //Zookeeper操作对象可以直接通过构造方法创建,构造方法只能是有参构造,必须传参连接字符串connectString、sessionTimeOut、watcher //连接字符串connectString的格式必须为"127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002",参数值是Zookeeper服务器集群的地址,用逗号分隔各地址,注意逗号两边不能有空格 //参数sessionTimeOut是int类型的连接超时时间,单位是毫秒 //监听器Watcher是一个接口,需要使用匿名内部类的方式来实例化对象 //使用完客户端对象以后调用close方法来关闭该客户端 zooKeeper = new ZooKeeper("192.168.200.132:2181", 30000, new Watcher() { @Override public void process(WatchedEvent event) { System.out.println("此时才真正获取连接进行回调process方法,该方法会在获取Zookeeper连接和关闭Zookeeper连接的时候分别调用一次,因此一共会调用两次"); } }); //Zookeeper对象的Api //zookeeper.create方法能创建节点 //zookeeper.exist方法能判断某个节点是否存在 //zookeeper.getChildren方法能获取节点的子节点和数据内容 //注意,Zookeeper在获取连接的时候,调用获取Zookeeper对象的方法后续代码就已经在执行了 //这里经过测试zookeeper不是null,这里是老师讲错了,根据以往JUC里面学到的知识认为是赋值操作已经完成,但是还没有初始化好,实际该对象虽然不是null但是需要在建立好连接后才能使用 System.out.println("此时还在建立连接,Zookeeper仍然为null但是这里已经能够执行了"); System.out.println(zooKeeper==null); /**执行效果 * 此时还在建立连接,Zookeeper仍然为null但是这里已经能够执行了 * false * 此时才真正获取连接进行回调process方法,该方法会在获取Zookeeper连接和关闭Zookeeper连接的时候分别调用一次,因此一共会调用两次 * 此时才真正获取连接进行回调process方法,该方法会在获取Zookeeper连接和关闭Zookeeper连接的时候分别调用一次,因此一共会调用两次 * */ //Zookeeper客户端中引入了Slf4j } catch (IOException e) { e.printStackTrace(); }finally { if (zooKeeper != null) { try { zooKeeper.close(); } catch (InterruptedException e) { e.printStackTrace(); } } } }-
使用闭锁
CountdownLatch等待zookeeper对象初始化完成- 注意,两次process方法回调时传参的
WatchedEvent对象的state属性值是不同的,第一次获取连接是SyncConnected,关闭连接时是Closed,可以根据两个属性值来区分是获取连接还是关闭连接,该属性值的类型是枚举Event.keeperState,可以通过该属性值和枚举值对比决定是否需要放行countDownLatch.await()从而继续执行获取到zookeeper连接后的动作- ❓:不是异步获取连接吗为什么这里属性值是同步连接
/**执行效果 * 此时才真正获取连接进行回调process方法,该方法会在获取Zookeeper连接和关闭Zookeeper连接的时候分别调用一次,因此一共会调用两次 * 此时还在建立连接,Zookeeper已赋值对象地址但是对象还没完成初始化,此时这里已经能够执行了 * false * WatchedEvent state:SyncConnected type:None path:null * 此时才真正获取连接进行回调process方法,该方法会在获取Zookeeper连接和关闭Zookeeper连接的时候分别调用一次,因此一共会调用两次 * WatchedEvent state:Closed type:None path:null * */ public static void main(String[] args) { CountDownLatch countDownLatch = new CountDownLatch(1); ZooKeeper zooKeeper = null; try { zooKeeper = new ZooKeeper("192.168.200.132:2181", 30000, new Watcher() { @Override public void process(WatchedEvent event) { countDownLatch.countDown(); System.out.println("此时才真正获取连接进行回调process方法,该方法会在获取Zookeeper连接和关闭Zookeeper连接的时候分别调用一次,因此一共会调用两次"); System.out.println(event); } }); try { countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("此时还在建立连接,Zookeeper以赋值对象地址但是对象还没完成初始化,此时这里已经能够执行了"); System.out.println(zooKeeper==null); } catch (IOException e) { e.printStackTrace(); }finally { if (zooKeeper != null) { try { zooKeeper.close(); } catch (InterruptedException e) { e.printStackTrace(); } } } }【优化后的通用模板代码】
public static void main(String[] args) { CountDownLatch countDownLatch = new CountDownLatch(1); ZooKeeper zooKeeper = null; try { zooKeeper = new ZooKeeper("192.168.200.132:2181", 30000, new Watcher() { @Override public void process(WatchedEvent event) { if(Event.KeeperState.SyncConnected.equals(event.getState())){ countDownLatch.countDown(); } } }); try { countDownLatch.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("业务操作"); } catch (IOException e) { e.printStackTrace(); }finally { if (zooKeeper != null) { try { zooKeeper.close(); } catch (InterruptedException e) { e.printStackTrace(); } } } } - 注意,两次process方法回调时传参的
-
上述代码还不够完善,因为节点事件的监听回调依然会执行
process()方法,此时process方法传参的event和获取连接时回调process方法的event分别为WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/earl[1]和WatchedEvent state:SyncConnected type:None path:null;注意这些event中的state属性为SyncConnected,和关闭连接时的WatchedEvent state:Closed type:None path:null该state属性Closed不同,由此区分关闭连接和其他事件;可以通过event参数的type属性来区分事件类型从而执行不同的回调逻辑,在state属性为SyncConnected的前提下,当type为None时表明回调由成功获取连接发起,当type属性为事件类型时表明回调由事件发起;此外注意event中的path存储了事件监听节点的路径,通过该路径可以制定不同节点的事件回调逻辑;由此可以将节点事件回调分成获取连接、关闭连接、节点事件三个大类执行对应的回调逻辑,对节点事件可以通过事件节点路径来区分执行不同的回调逻辑,示例代码如下- 在Zookeeper对象的构造方法传参watcher对象中通过
event对象的state属性、type属性和path属性来分区获取连接回调、关闭连接回调和不同类型不同节点的节点事件回调 - 节点事件回调直接在Zookeeper构造方法传参中写一起不优雅,不方便读和改,判断逻辑复杂;业界常用的方式是在节点事件监听方法中传参
Watcher匿名实现重写process方法来自定义节点事件的回调逻辑,连续回调需要对节点事件方法进行封装,通过在回调方法中递归调用该方法来实现连续回调
public static void main(String[] args) { CountDownLatch countDownLatch = new CountDownLatch(1); ZooKeeper zooKeeper = null; try { zooKeeper = new ZooKeeper("192.168.200.132:2181", 30000, new Watcher() { @Override public void process(WatchedEvent event) { Event.KeeperState eventState = event.getState(); if (Event.KeeperState.SyncConnected.equals(eventState) && Event.EventType.None.equals(event.getType())) { //获取连接回调逻辑,通常让闭锁计数减1来放行主业务执行或者其他逻辑 countDownLatch.countDown(); } else if (Event.KeeperState.Closed.equals(eventState)) { //关闭连接后的回调业务逻辑 } else { //节点事件回调逻辑,可以根据事件类型和节点路径进一步区分具体节点不同事件类型的回调逻辑,这些事件回调都是一次性的,后续相同事件发生不会再回调,想要后续继续回调可以在回调事件中再调用对应的事件比如getChildren("/earl",true)来实现,但是这种在一个process方法中写完所有回调逻辑的方式不优雅;回调的业务逻辑一般不写在该process方法中,一般是在业务方法中通过重载方法getChildren("/earl",watcher)传参一个Watcher类型的匿名实现来替换布尔类型的watch变量,在匿名实现需要重写的process方法中去自定义回调逻辑,这种方式更方便代码的组织和修改,读起来也更容易,如下业务代码所示 } } }); countDownLatch.await(); System.out.println("业务操作"); //常用的事件监听和回调方式 List<String> children = zooKeeper.getChildren("/earl", new Watcher() { @Override public void process(WatchedEvent event) { System.out.println("节点/earl的子节点发生变化触发的回调"); //如果需要多次回调,回调的方式一般是把该监听方法封装成一个单独的方法,在该方法的回调中递归调用方法本身,如果只是一次回调则只需要这种实现即可 } }); //这个等待回调的方式有点野蛮,感觉JUC里面的保护性暂停用在这里很不错 System.in.read(); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } finally { if (zooKeeper != null) { try { zooKeeper.close(); } catch (InterruptedException e) { e.printStackTrace(); } } } } - 在Zookeeper对象的构造方法传参watcher对象中通过
API
String ---> zookeeper.create(final String path,byte[] data,List<ACL> acl,CreateMode createMode) throws KeeperException, InterruptedException- 功能解析:创建指定数据、指定数据下的节点,返回值为被创建节点的路径
- 使用示例:
zooKeeper.create("/earl/testJavaClient", "Hello zookeeper".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);- 示例含义:创建一个路径为
/earl/testJavaClient,数据内容为Hello zookeeper,允许所有客户端对该节点进行任何操作的永久节点
- 示例含义:创建一个路径为
- 补充说明:
- 数据内容
data要求传参一个byte数组,可以通过字符串.getBytes()方法获取对应的byte数组 - 权限
List<ACL>有专门的枚举类ZooDefs.Ids,常用的三种权限包括ZooDefs.Ids.OPEN_ACL_UNSAFE:所有客户端都可以对创建的节点做任何操作ZooDefs.Ids.CREATOR_ALL_ACL:创建节点的客户端可以对节点做任何操作ZooDefs.Ids.READ_ACL_UNSAFE:所有客户端都能对创建的节点做读取操作
- 节点类型
createMode也使用专门的枚举类CreateMode,对应节点类型有以下四种CreateMode.PERSISTENT:创建的节点是永久节点CreateMode.EPHEMERAL:创建的节点是临时节点,这种方式创建的临时节点在调用zookeeper.close()方法后节点会直接被zookeeper服务器秒删CreateMode.EPHEMERAL_SEQUENTIAL:创建的节点是序列化临时节点CreateMode.PERSISTENT_SEQUENTIAL:创建的节点是序列化永久节点
- 数据内容
Stat ---> zookeeper.exists(String path, boolean watch) throws KeeperException, InterruptedException- 功能解析:判断指定路径节点是否存在,如果返回值为
null说明对应节点不存在,如果返回值不为null说明对应的节点存在;第一个参数是指定节点路径,第二个参数是指定是否要监听,指定true表示要监听时间,指定false表示不监听 - 使用示例:
zooKeeper.exists("/earl/testJavaClient", false);- 示例含义:查询路径为
/earl/testJavaClient的节点是否存在
- 示例含义:查询路径为
- 补充说明:
exists方法相当于zookeeper中的stat指令,可以通过该方法的重载方法来做对节点删除和节点创建事件的监听
- 功能解析:判断指定路径节点是否存在,如果返回值为
byte[] ---> zookeeper.getData(String path, boolean watch, Stat stat) throws KeeperException, InterruptedException- 功能解析:查询已经存在的指定路径节点的内容数据,这里传参
stat是zooKeeper.exists("/earl/testJavaClient", false);的返回值,暂时认为要查询指定节点的内容数据必须先查询该节点是否存在。第二个参数是指定是否要监听,指定true表示要监听时间,指定false表示不监听 - 使用示例:
zooKeeper.getData("/earl/testJavaClient", false, exists);- 示例含义:查询已经存在节点
/earl/testJavaClient的数据内容
- 示例含义:查询已经存在节点
- 补充说明:
getData方法相当于zookeeper中的get指令,可以通过该方法的重载方法来做对节点的数据变化监听
- 功能解析:查询已经存在的指定路径节点的内容数据,这里传参
List<String> ---> zookeeper.getChildren(String path, boolean watch) throws KeeperException, InterruptedException- 功能解析:查询一个指定节点下的全部子节点
- 使用示例:
zooKeeper.getChildren("/earl", false);- 示例含义:查询节点
/earl下的所有子节点
- 示例含义:查询节点
- 补充说明:
getChildren方法相当于zookeeper中的ls指令,可以通过该方法的重载方法来做对子节点的创建、删除、数据内容变化监听
Stat ---> zookeeper.setData(final String path, byte[] data, int version) throws KeeperException, InterruptedException- 功能解析:更新一个指定节点的数据内容,第三个参数
version需要使用exists方法查询获取Stat返回值,用stat.getVersion()来获取指定路径节点的版本号,如果更新时发现当前数据版本号和传参不一致,更新操作就会失败;即更新操作也需要事先查询指定节点是否存在且获取Stat返回值作为更新方法传参 - 使用示例:
zooKeeper.setData("/earl/testJavaClient", "hello earl".getBytes(), exists.getVersion())- 示例含义:把节点
/earl/testJavaClient下的数据内容更新为hello earl
- 示例含义:把节点
- 补充说明:
- 版本号也可以指定为-1,表示更新操作不关心版本号,本次更新操作一定会成功
- 功能解析:更新一个指定节点的数据内容,第三个参数
void ---> zookeeper.delete(final String path, int version) throws InterruptedException, KeeperException- 功能解析:删除指定路径节点,如果当前版本号和指定版本号不一致则删除失败
- 使用示例:
zooKeeper.delete("earl/testJavaClient",exists.getVersion());- 示例含义:删除节点
/earl/testJavaClient
- 示例含义:删除节点
- 补充说明:
- 版本号也可以指定为-1,表示删除操作不关心版本号,本次删除操作一定会成功
- 如果要删除的节点不存在仍然执行了该方法会抛出异常,注意凡是涉及到事件监听的方法调用,调用事件监听方法的线程在事件发生前不能提前结束执行,事件发生时线程运行结束会导致无法执行事件监听成功后的回调,因此调用事件监听方法的线程不能在事件发生前结束,不能在等待期间发生异常,发生了异常如果没有捕获处理也会直接结束当前线程
slf4j-log4j12
Curator
- Curator是Netflix贡献给Apache的,目前属于Apache的顶级项目,Curator针对Zookeeper提供了很多高级工具的封装,比如分布式锁、还解决了Zookeeper官方客户端诸如失败重连、多次反复事件监听很多缺陷
- Curator主要解决了Zookeeper官方客户端的三类问题
- 封装
ZooKeeper client与ZooKeeper server之间的连接处理 - 提供了一套Fluent风格的操作API
- 提供基于
ZooKeeper各种应用场景实现, 比如分布式锁服务、集群领导选举、共享计数器、缓存机制、分布式队列等抽象封装,这些实现都遵循Zookeeper的最佳实践,并考虑了各种极端情况
- 封装
- Curator由核心框架
curator-framework和curator-recipes两部分组成,curator-framework主要对Zookeeper的底层做了许多封装,便于用户更方面操作Zookeeper;curator-recipes对一些Zookeeper典型应用场景比如分布式锁做了封装
-
引入依赖
- 使用Curator需要分别引入
curator-framework和curator-recipes,注意这两个依赖中都含有zookeeper官方客户端依赖,使用zookeeper客户端需要与服务端的版本相同,实际上也没这么严格,我这里使用zookeeper3.5.7的服务器使用zookeeper3.7.0的客户端也没有出现任何问题,使用Curator并不需要使用zookeeper客户端,因此为了避免版本冲突问题,最好将zookeeper客户端从curator-framework和curator-recipes中排除出去,有需要的时候再单独进行引入
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>4.3.0</version> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>4.3.0</version> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.14</version> </dependency> - 使用Curator需要分别引入
-
编写配置类初始化
curator-framework的客户端CuratorFrameWork,该客户端对象类似于Redis客户端中的RedisTemplate,Redisson中的RedissonClient-
配置类
CuratorFramework是一个接口,该接口有一个子接口WatcherRemoveCuratorFramework和一个子实现类CuratorFrameworkImpl,子实现类CuratorFrameworkImpl有两个子类NamespaceFacade和WatcherRemovalFacade,一般常用工厂类的newClient方法来初始化CuratorFramework组件,该方法有两个重载方法CuratorFramework. newClient()- Zookeeper官方客户端是不具备连接重试功能的,这就是Curator对Zookeeper官方客户端做出的优化之一
- 其中
newClient(String connectString, RetryPolicy retryPolicy)方法不需要指定会话和连接超时时间- 第一个参数是指定Zookeeper服务器地址,参数格式为
192.168.200.132:2181,注释说这是一个服务器地址列表,虽然注释没指明具体格式,猜测使用逗号分隔多个服务器地址 - 第二个参数
retryPolicy是指定重试策略,RetryPolicy是一个接口,有两个直接子类分别是SleepingRetry和RetryForever,前者表示有间歇的重试,后者表示持续重试,持续重试可能导致服务器浪费大量的资源,一般不推荐使用该策略;可以使用SleepingRetry的子类RetryNTime,该策略可以指定每隔多少时间重试一次,最多重试多少次;一般使用SleepingRetry的子类ExponentialBackoffRetry指数补偿重试,除了可以指定重试次数,还可以指定一个初始间隔时间,第一次在初始间隔时间重试,以后每次重试的间隔时间会递增,重试次数越多间隔时间越长,这样的策略设计更符合节省服务器资源的标准
- 第一个参数是指定Zookeeper服务器地址,参数格式为
- 第二个重载方法
CuratorFramework newClient(String connectString, int sessionTimeoutMs, int connectionTimeoutMs, RetryPolicy retryPolicy)需要额外指定会话和连接超时时间
- 初始化
CuratorFramework对象以后需要使用start方法手动启动一下,否则Curator底层很多方法或者功能都是不工作的,即使调用了也无法使用,Curator的大多功能都通过该对象进行调用
/** * @author Earl * @version 1.0.0 * @描述 CuratorFramework的配置类 * @创建日期 2024/08/30 * @since 1.0.0 */ @Configuration public class CuratorConfig { @Bean public CuratorFramework curatorFramework(){ //初始化一个重试策略,这里使用的是指数补偿策略 //初始重试间隔10s钟,最大重试次数3次,这种参数声明更喜欢使用多态的方式来进行声明 RetryPolicy retryPolicy = new ExponentialBackoffRetry(10000, 3); CuratorFramework curatorFrameworkClient = CuratorFrameworkFactory.newClient("192.168.200.132", retryPolicy); //手动启动curatorFrameworkClient curatorFrameworkClient.start(); return curatorFrameworkClient; } }
-
分布式锁解决方案
- 相关内容参见后端–分布式锁
Redisson
- Redisson类似于Jedis,功能封装相较于Jedis更加丰富,Jedis只是一个性能很好的Redis客户端,功能太弱;Redisson中封装了很多类似分布式锁、Java常用分布式对象【BitSet, Set, Multimap, SortedSet, Map, List, Queue, BlockingQueue, Deque, BlockingDeque, Semaphore, Lock, AtomicLong, CountDownLatch, Publish / Subscribe, Bloom filter】,常用分布式服务的实现;
- 这些分布式对象或者集合和单机版的一些对象集合在设计上考虑的点不一样,都是分布式场景下的Set、Map、List集合、队列,双端队列、双端阻塞队列、阻塞队列、信号量、分布式锁、原子整数等等
- 此外还有一些基于Redis实现的分布式远程服务
- Redisson提供了很多使用Redis最方便简单的方法,和Jedis的设计理念不同,jedis的目的就是在客户端使用Redis指令,Redisson的目的是让用户不要关注redis本身和对应的指令,只关注使用Redisson实现业务逻辑
- Redisson是一个在Redis的基础上实现的Java驻内存数据网格,内存数据网格的意思就是给内存做格式化,格式化的意思是给存储介质画格子,可以向格子中写入数据;格式化达到清空数据的效果是一种表面现象,实际动作是画格子【解释的一坨】,早期的U盘购买以后不能直接用,需要下驱动格式化才能使用,这个步骤就是给U盘画格子;格式化看上去清空了数据,实际上是在重新画格子【猜测是移除旧的寻址数据,设置新的写入空间,写入数据的时候设置新的寻址规则】
- Redisson的官方文档:https://github.com/redisson/redisson/wiki
配置Redisson
-
引入依赖
-
pom.xml- 🔎:
我严重怀疑有场景启动器,这里的配置是使用原生redisson的配置【经过后期确认,Maven仓库确实有对应的场景启动器依赖org.redisson.redisson-spring-boot-starter,可以在pringBoot的默认配置文件中对Redisson进行配置,配置示例后面遇到再补充】
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.17.1</version> </dependency> - 🔎:
-
-
配置
-
Properties中没有提供对应的Redisson相关的配置项,不能在SpringBoot的默认配置文件中对Redisson进行配置,具体的配置方法可以参考文档的Configuration【配置方法】章节,可以通过代码、文件的方式对Redisson进行配置
-
Redisson可以通过用户提供的YAML格式的文本文件来进行配置,该YAML文件需要通过调用静态方法
Config.fromYAML(new File("config-file.yaml"))来创建Config配置类对象,通过配置类对象调用静态方法Redisson.create(Config config)来实例化RedissonClient对象,这个RedissonClient对象就类似于操作Redis的StringRedisTemplate,Redisson通过该对象实现对Redis的所有操作,配置示例如下Config config = Config.fromYAML(new File("config-file.yaml")); RedissonClient redisson = Redisson.create(config); -
YAML的文件配置方式比较麻烦,程序化配置相对简单方便,程序化配置的方法是构造一个Config对象,调用对象的实例方法为该对象设置指定的参数,配置示例如下,推荐使用程序化配置方式
- Redis地址必须以
redis://开头,后面跟redis服务器的ip和端口号;如果Redis启用了安全连接,则需要在开头使用rediss://启动SSL连接标识启用安全连接
Config config = new Config(); config.setTransportMode(TransportMode.EPOLL); config.useClusterServers() //可以用"rediss://"来启用SSL连接 .addNodeAddress("redis://127.0.0.1:7181"); - Redis地址必须以
-
-
配置Redis集群的模式
-
针对Redis以不同模式构建,RedissonClient的配置方式不同,但是也是大同小异,Redis常见的构建模式包括集群模式、云托管模式、单Redis节点模式、哨兵模式、主从模式、分片模式;配置对应模式的代码如下
【单机模式】
Config config = new Config(); config.useSingleServer();【分片模式】
- 参数
addresses是一个可变长度字符串类型参数,在分片模式下要传递多个Redis节点的地址
Config config = new Config(); config.useClusterServers().addNodeAddress(String... addresses);【自定义模式】
Config config = new Config(); config.useCustomServers();【主从模式】
Config config = new Config(); config.useMasterSlaveServers();【副本模式】
Config config = new Config(); config.useReplicatedServers();【哨兵模式】
Config config = new Config(); config.useSentinelServers(); - 参数
-
-
单Redis节点模式下的程序化配置方式
-
如果redis在本机,Redisson可以直接使用create方法以默认连接地址
127.0.0.1:6379初始化RedissonClient,示例如下// 默认连接地址 127.0.0.1:6379 RedissonClient redisson = Redisson.create(); -
如果redis不在本机,配置redis的模式、配置redis服务器地址和端口并用
Redisson.create(config)方法初始化RedissonClient,示例如下Config config = new Config(); //设置配置对应的Redis模式并设置对应的Redis地址 config.useSingleServer().setAddress("myredisserver:6379"); RedissonClient redisson = Redisson.create(config); -
常用配置示例
@Configuration public class RedissonConfig{ @Bean public RedissonClient redissonClient(){ Config config = new Config();//初始化一个Redisson配置对象 config.useSingleServer()//使用单机模式 .setAddress("redis://192.168.200.132:6173")//指定Redis服务器地址 .setDatabase(0)//Redis默认有16个数据库,Redisson可以通过`setDatabase(int database)`方法进行指定,默认传参0表示使用第一个数据库 .setUsername(String username) .setPassword()//设置用户名和密码,当redis设置了用户名和密码,对应的Config也需要配置 .setConnectionMinimumIdleSize(10)//设置连接池最小空闲连接数,生产环境最好设置,开发环境无需设置 .setConnectionPoolSize(50)//设置连接池最大线程数[这里怀疑是连接数不是线程数,因为连接池不一定需要使用线程池] .setIdleConnectionTimeout(60000)//设置连接池线程的最大空闲时间,单位是毫秒,连接池线程空闲超过该时间就会被销毁直到线程数小于连接池最小空闲数 .setConnectionTimeout()//设置客户端程序获取redis连接的超时时间,如果超过该时间客户端还没有获取到redis连接就会快速失败 .setTimeout();//设置响应超时时间,如果超过指定时间还没有响应就快速失败 RedissonClient redisson = Redisson.create(config); return redisson; } } -
最小配置示例
-
这只是最简单的配置,定制化的配置还有很多,需要翻阅文档,在该配置下可以使用Redisson提供的:
- 🔎:同时也意味着其他的配置都是可选配置,但是老师说生产环境上面的常用配置项都需要进行配置
- 基于Redis的分布式锁RLock
-
Redisson是接口RedissonClient的实现类,Redisson的构造方法使用protected修饰,不能在包以外的地方调用,用户无法使用该构造方法;用户需要使用create方法来创建RedissonClient对象- 无参的
create()方法默认写死了本机的6379作为redis服务器地址,也是调用有参的create方法创建RedissonClient对象 - 有参的
create(Config config)方法通过调用Redisson的构造方法传参config来创建RedissonClient对象
@Configuration public class RedissonConfig{ @Bean(destoryMethod="shutdown")//@Bean注解的destoryMethod属性能指定应用程序关闭前调用自定义shutdown方法来销户该容器组件 public RedissonClient redissonClient(){ Config config = new Config(); config.useSingleServer().setAddress("redis://192.168.200.132:6173"); RedissonClient redisson = Redisson.create(config); return redisson; } } - 无参的
-
-
分布式锁解决方案
- 相关内容参见后端–分布式锁
SpringCache
-
从Spring3.1开始定义了
org.springframework.cache.Cache和org.springframework.cache.CacheManager两个接口来统一不同的缓存技术,Cache接口是来操作增删改查数据的,CacheManager接口是来管理各种各样的缓存的,支持使用**JCache[JSR-107]**注解通过注解的方式来简化开发,SpringCache属于Spring的部分,不属于SpringBoot -
官方文档:https://docs.spring.io/spring-framework/docs/5.3.39/reference/html/integration.html#cache
- 步骤1
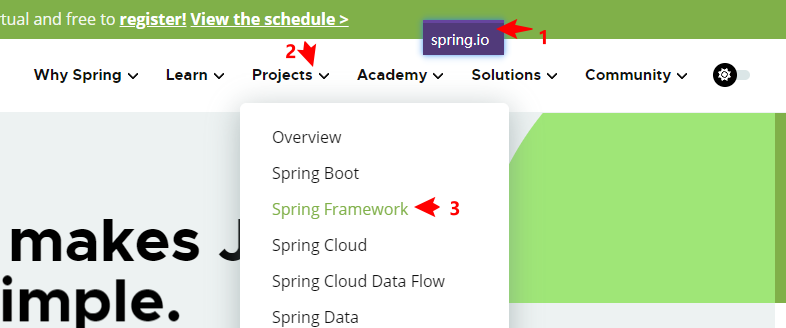
- 步骤2
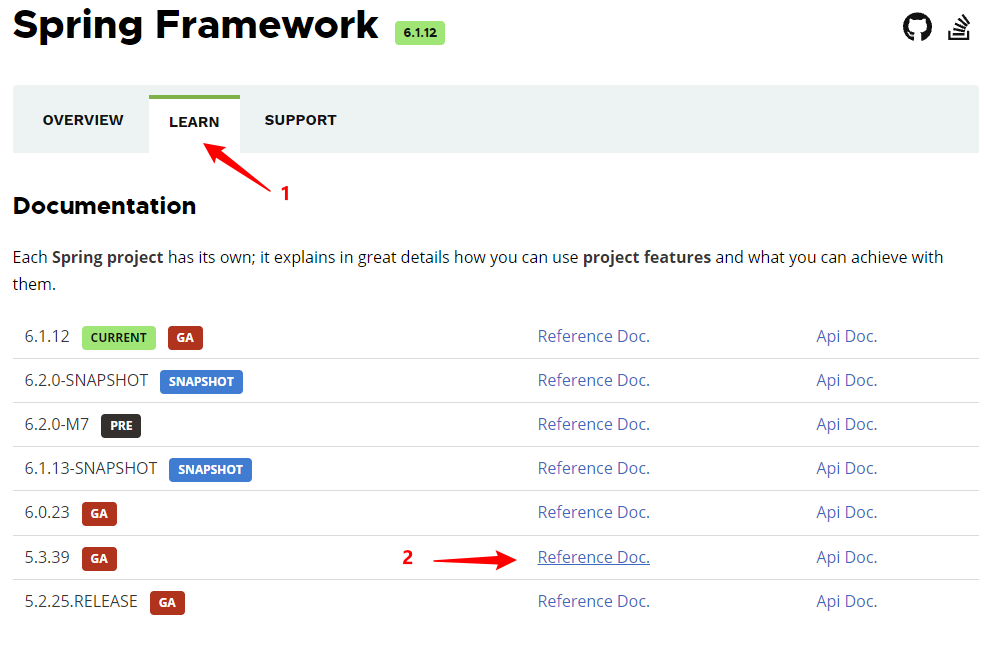
-
步骤3

-
步骤4

配置使用
-
引入依赖
-
引入缓存场景启动器
spring-boot-starter-cache<!--引入缓存相关的场景启动器--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-cache</artifactId> </dependency>-
想要使用Redis作为缓存需要引入redis的场景启动器
spring-boot-starter-data-redis,使用基于netty的lettuce-core做网络通信,吞吐量极大,但是老版本的lettuce-core存在以下问题 -
🔎:netty没有指定堆外内存,会默认使用-Xmx100m作为堆外内存,在并发处理过程中,获取数据的量特别大【比如一次就是69K】,数据在传输、转换过程中都需要占用内存,导致内存分配不足,出现堆外内存溢出问题;当-Xmx调大成1G的时候,发现不会瞬间发生堆外内存溢出,甚至还能测出吞吐量好一会儿以后才会发生该异常;即使将该值调整到很大的值,也只能延迟该堆外内存溢出的情况,但是该异常永远都会出现,根本原因是源码中netty在运行过程中会判断需要使用多少内存,计数一旦超过常量
DIRECT_MEMORY_LIMIT【直接内存限制】就会抛OutOfDirectMemoryError异常,调用操作完以后应该还要调用释放内存的方法并计数释放的内存使用量,但是在操作的过程中没有及时地调用减去已释放内存导致报错堆外内存溢出,直接内存限制使用的是虚拟机运行参数设置-Dio.netty.maxDirectMemory
<!--redis做缓存操作,搜索RedisAutoConfiguration能找到redis相关配置对应的属性类,所有相关配置都在该属性类中--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> <exclusions> <exclusion> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> </exclusion> </exclusions> </dependency> <!-- https://mvnrepository.com/artifact/io.lettuce/lettuce-core --> <dependency> <groupId>io.lettuce</groupId> <artifactId>lettuce-core</artifactId> <version>5.2.0.RELEASE</version> </dependency> -
-
配置示例
- 指定缓存的类型为redis即可
#指定缓存的类型 spring.cache.type=redis #指定缓存的名字,在CacheProperties中的cacheNames属性上有注释说明,缓存名字可以以逗号分隔的list集合来表示,缓存管理器会根据 #这里配置的名字来自动创建对应名字的缓存组件,但是在配置文件指定了缓存名字会禁用掉根据代码中自定义的缓存名字自动创建缓存组件的功能, #我们希望一边使用一边生成缓存组件,所以不对该项进行配置 #spring.cache.cache-names= #这种方式会指定所有缓存在Redis中的有效时间,不太好,一个是缓存有效时间粒度太大,一个是容易造成缓存雪崩 spring.cache.redis.time-to-live=3600000 #spring.cache.redis.key-prefix=CACHE_ spring.cache.redis.use-key-prefix=true -
开启缓存功能
- 在启动类上添加注解
@EnableCaching来开启缓存功能
@EnableCaching @EnableFeignClients("com.earl.mall.product.feign") @EnableDiscoveryClient @MapperScan("com/earl/mall/product/dao") @SpringBootApplication public class MallProductApplication { public static void main(String[] args) { SpringApplication.run(MallProductApplication.class, args); } } - 在启动类上添加注解
-
自动配置原理
-
CacheAutoConfigurationCacheAutoConfiguration在RedisAutoConfiguration后面才会配置,CacheAutoConfiguration根据默认配置文件配置的缓存类型redis来选择RedisCacheConfiguration对缓存进行配置,RedisCacheConfiguration会给容器注入一个RedisCacheManager,缓存管理器RedisCacheManager会按照我们定义的缓存名字调用this.customizerInvoker.customize(builder.build())来帮助用户初始化所有缓存,初始化缓存前会调用方法determineConfiguration(resourceLoader.getClassLoader())决定缓存初始化使用的配置,如果redisCacheConfiguration不为空即有Redis的缓存配置就拿到Redis的缓存配置redisCacheConfiguration,如果没有就使用默认配置,默认的缓存配置都是从RedisProperties中获取的,调用cacheDefaults方法构建RedisCacheManagerBuilder对象准备构造RedisCacheManager组件并根据缓存名字调用initialCacheNames方法来初始化缓存组件,自动配置类中的RedisCacheConfiguration是容器组件,而且只有有参构造方法,初始化org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration时所有的参数都来自于容器组件,对象ObjectProvider<org.springframework.data.redis.cache.RedisCacheConfiguration>从容器中获取我们自定义的org.springframework.data.redis.cache.RedisCacheConfiguration,如果我们没有提供自定义的redisCacheConfiguration组件这里就赋不上值,如果redisCacheConfiguration为空值就会使用默认的redisProperties中的配置,想改缓存的配置需要给容器中添加一个redisCacheConfiguration组件,该配置就会应用到当前RedisCacheManager管理的所有缓存组件[缓存分区]中,注意org.springframework.data.redis.cache.RedisCacheConfiguration不是当前类,当前类是org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration,org.springframework.data.redis.cache.RedisCacheConfiguration中的属性ttl、cacheNullValues、keyPrefix、keySerializationPair、valueSerializationPair分别指定缓存的有效时间、是否缓存空数据、是否加前缀、key的序列化方式和value的序列化方式;如果不指定自定义的RedisCacheConfiguration,会调用defaultCacheConfig()设置默认配置,该方法上的注释指明了默认redis缓存配置,分别为没有指定过期时间、支持缓存空值、缓存的key支持添加前缀、默认前缀为当前缓存的名字、key的序列化器使用的是StringRedisSerializer,value的序列化器使用的JdkSerializationRedisSerializer,涉及到的时间日期格式转化使用的是DefaultFormattingConversionService,如果不使用默认的redis缓存配置,需要我们向容器中自定义一个org.springframework.data.redis.cache.RedisCacheConfiguration容器组件
spring-boot-starter-cache2.1.8.RELEASE -------------------------------------------------------------------------------------------------- @Configuration @ConditionalOnClass(CacheManager.class) @ConditionalOnBean(CacheAspectSupport.class) @ConditionalOnMissingBean(value = CacheManager.class, name = "cacheResolver") @EnableConfigurationProperties(CacheProperties.class)//配置文件中能配置的缓存相关属性在类CacheProperties中封装 @AutoConfigureAfter({ CouchbaseAutoConfiguration.class, HazelcastAutoConfiguration.class, HibernateJpaAutoConfiguration.class, RedisAutoConfiguration.class })//在Redis开启自动配置以后才开启缓存的自动配置 @Import(CacheConfigurationImportSelector.class) public class CacheAutoConfiguration { @Bean @ConditionalOnMissingBean public CacheManagerCustomizers cacheManagerCustomizers(ObjectProvider<CacheManagerCustomizer<?>> customizers) { return new CacheManagerCustomizers(customizers.orderedStream().collect(Collectors.toList())); } @Bean public CacheManagerValidator cacheAutoConfigurationValidator(CacheProperties cacheProperties, ObjectProvider<CacheManager> cacheManager) { return new CacheManagerValidator(cacheProperties, cacheManager); } @Configuration @ConditionalOnClass(LocalContainerEntityManagerFactoryBean.class) @ConditionalOnBean(AbstractEntityManagerFactoryBean.class) protected static class CacheManagerJpaDependencyConfiguration extends EntityManagerFactoryDependsOnPostProcessor { public CacheManagerJpaDependencyConfiguration() { super("cacheManager"); } } /** * Bean used to validate that a CacheManager exists and provide a more meaningful * exception. */ static class CacheManagerValidator implements InitializingBean { private final CacheProperties cacheProperties; private final ObjectProvider<CacheManager> cacheManager; CacheManagerValidator(CacheProperties cacheProperties, ObjectProvider<CacheManager> cacheManager) { this.cacheProperties = cacheProperties; this.cacheManager = cacheManager; } @Override public void afterPropertiesSet() { Assert.notNull(this.cacheManager.getIfAvailable(), () -> "No cache manager could " + "be auto-configured, check your configuration (caching " + "type is '" + this.cacheProperties.getType() + "')"); } } /** * {@link ImportSelector} to add {@link CacheType} configuration classes. */ //使用CacheConfigurationImportSelector这个选择器又导入了很多缓存相关配置 static class CacheConfigurationImportSelector implements ImportSelector { @Override public String[] selectImports(AnnotationMetadata importingClassMetadata) { CacheType[] types = CacheType.values(); String[] imports = new String[types.length]; for (int i = 0; i < types.length; i++) { imports[i] = CacheConfigurations.getConfigurationClass(types[i]);//1️⃣ 从CacheConfigurations缓存配置类中根据缓存类型得到每一种缓存的配置,Redis类型的缓存从MAPPINGS中根据CacheType.REDIS获取到RedisCacheConfiguration.class。用户在默认配置文件中指明了缓存类型为redis就会导入跟Redis相关的缓存配置类RedisCacheConfiguration.class } return imports; } } } final class CacheConfigurations { //MAPPING在静态代码块中初始化,导入CacheType.REDIS对应导入的是RedisCacheConfiguration.class private static final Map<CacheType, Class<?>> MAPPINGS; static { Map<CacheType, Class<?>> mappings = new EnumMap<>(CacheType.class); mappings.put(CacheType.GENERIC, GenericCacheConfiguration.class); mappings.put(CacheType.EHCACHE, EhCacheCacheConfiguration.class); mappings.put(CacheType.HAZELCAST, HazelcastCacheConfiguration.class); mappings.put(CacheType.INFINISPAN, InfinispanCacheConfiguration.class); mappings.put(CacheType.JCACHE, JCacheCacheConfiguration.class); mappings.put(CacheType.COUCHBASE, CouchbaseCacheConfiguration.class); mappings.put(CacheType.REDIS, RedisCacheConfiguration.class);2️⃣ //根据CacheType.REDIS类型获取到Redis缓存的具体配置RedisCacheConfiguration.class mappings.put(CacheType.CAFFEINE, CaffeineCacheConfiguration.class); mappings.put(CacheType.SIMPLE, SimpleCacheConfiguration.class); mappings.put(CacheType.NONE, NoOpCacheConfiguration.class); MAPPINGS = Collections.unmodifiableMap(mappings); } private CacheConfigurations() { } 1️⃣ cacheConfigurations.getConfigurationClass(types[i]) //根据缓存的类型从MAPPING属性中获取每一种缓存 public static String getConfigurationClass(CacheType cacheType) { Class<?> configurationClass = MAPPINGS.get(cacheType); Assert.state(configurationClass != null, () -> "Unknown cache type " + cacheType); return configurationClass.getName(); } public static CacheType getType(String configurationClassName) { for (Map.Entry<CacheType, Class<?>> entry : MAPPINGS.entrySet()) { if (entry.getValue().getName().equals(configurationClassName)) { return entry.getKey(); } } throw new IllegalStateException("Unknown configuration class " + configurationClassName); } } 2️⃣ RedisCacheConfiguration中做的配置 @Configuration @ConditionalOnClass(RedisConnectionFactory.class) @AutoConfigureAfter(RedisAutoConfiguration.class) @ConditionalOnBean(RedisConnectionFactory.class) @ConditionalOnMissingBean(CacheManager.class) @Conditional(CacheCondition.class) class RedisCacheConfiguration { private final CacheProperties cacheProperties; private final CacheManagerCustomizers customizerInvoker; private final org.springframework.data.redis.cache.RedisCacheConfiguration redisCacheConfiguration; RedisCacheConfiguration(CacheProperties cacheProperties, CacheManagerCustomizers customizerInvoker, ObjectProvider<org.springframework.data.redis.cache.RedisCacheConfiguration> redisCacheConfiguration) { this.cacheProperties = cacheProperties; this.customizerInvoker = customizerInvoker; this.redisCacheConfiguration = redisCacheConfiguration.getIfAvailable(); }//对象ObjectProvider<org.springframework.data.redis.cache.RedisCacheConfiguration>从容器中获取我们自定义的redisCacheConfiguration,如果我们没有提供自定义的redisCacheConfiguration组件这里就赋不上值,如果redisCacheConfiguration为空值就会使用默认的redisProperties中的配置,想改缓存的配置需要给容器中添加一个redisCacheConfiguration组件,该配置就会应用到当前RedisCacheManager管理的所有缓存组件[缓存分区]中,注意org.springframework.data.redis.cache.RedisCacheConfiguration不是当前类,当前类是org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration,org.springframework.data.redis.cache.RedisCacheConfiguration中的属性ttl、cacheNullValues、keyPrefix、keySerializationPair、valueSerializationPair分别指定缓存的有效时间、是否缓存空数据、是否加前缀、key的序列化方式和value的序列化方式;如果不指定自定义的RedisCacheConfiguration,会调用defaultCacheConfig()设置默认配置,该方法上的注释指明了默认redis缓存配置,分别为没有指定过期时间、支持缓存空值、缓存的key支持添加前缀、默认前缀为当前缓存的名字、key的序列化器使用的是StringRedisSerializer,value的序列化器使用的JdkSerializationRedisSerializer,涉及到的时间日期格式转化使用的是DefaultFormattingConversionService,如果不使用默认的redis缓存配置,需要我们向容器中自定义一个容器组件 //给容器中放入了一个缓存管理器组件 @Bean public RedisCacheManager cacheManager(RedisConnectionFactory redisConnectionFactory, ResourceLoader resourceLoader) { RedisCacheManagerBuilder builder = RedisCacheManager.builder(redisConnectionFactory) .cacheDefaults(determineConfiguration(resourceLoader.getClassLoader()));//初始化缓存前会调用方法`determineConfiguration(resourceLoader.getClassLoader())`决定缓存初始化使用的配置,拿到Redis的缓存配置redisCacheConfiguration,调用cacheDefaults方法构建RedisCacheManagerBuilder对象准备构造RedisCacheManager组件 List<String> cacheNames = this.cacheProperties.getCacheNames(); if (!cacheNames.isEmpty()) { builder.initialCacheNames(new LinkedHashSet<>(cacheNames));2️⃣-1️⃣ //根据缓存名字调用initialCacheNames来初始化缓存组件 } return this.customizerInvoker.customize(builder.build()); } private org.springframework.data.redis.cache.RedisCacheConfiguration determineConfiguration( ClassLoader classLoader) { if (this.redisCacheConfiguration != null) { return this.redisCacheConfiguration;//如果redisCacheConfiguration不为空即有Redis的缓存配置就拿到Redis的缓存配置redisCacheConfiguration,如果没有就使用默认配置 } Redis redisProperties = this.cacheProperties.getRedis(); org.springframework.data.redis.cache.RedisCacheConfiguration config = org.springframework.data.redis.cache.RedisCacheConfiguration .defaultCacheConfig();//如果不指定自定义的RedisCacheConfiguration,会调用defaultCacheConfig()设置默认配置 config = config.serializeValuesWith( SerializationPair.fromSerializer(new JdkSerializationRedisSerializer(classLoader)));//序列化机制使用JDK默认的序列化 if (redisProperties.getTimeToLive() != null) { config = config.entryTtl(redisProperties.getTimeToLive());//从redisProperties中得到ttl过期时间,说实话,讲的一坨,唉;redisProperties是从当前类的cacheProperties属性中获取的, } if (redisProperties.getKeyPrefix() != null) {//每一个缓存的key有没有前缀 config = config.prefixKeysWith(redisProperties.getKeyPrefix()); } if (!redisProperties.isCacheNullValues()) {//是否缓存空数据 config = config.disableCachingNullValues(); } if (!redisProperties.isUseKeyPrefix()) {//是否使用缓存的前缀 config = config.disableKeyPrefix(); } return config; }//通过配置我们自己定义的`RedisCacheConfiguration`,会在`org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration`中的`determineConfiguration(ClassLoader classLoader)`方法中取消用`cacheProperties`中的配置修改`org.springframework.data.redis.cache.RedisCacheConfiguration`中的对应属性,因此我们所有配置在默认配置文件中的属性都会失效<font color=green>**[比如我们在默认配置文件配置的缓存有效时间]**</font>,因为在执行自动配置时发现我们自己配置了`RedisCacheConfiguration`,就会直接返回我们配置的组件,不会再继续执行`cacheProperties`的配置属性赋值操作了;因此使用自定义`RedisCacheConfiguration`组件还需要将配置文件中的所有`Redis`缓存相关配置都配置到该组件中,可以参考`org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration`中的`determineConfiguration(ClassLoader classLoader)`方法中的配置方式,这样我们仍然能通过配置文件指定对应的属性,缓存相关的配置类只是标注了注解`@ConfigurationProperties(prefix="spring.cache")`该注解只是声明该配置类和默认配置文件中以`spring.cache`为前缀的配置进行属性绑定,但是并没有将该配置类放入容器中,需要在配置使用类上标注`@EnableConfigurationProperties(CacheProperties.class)`导入该配置类,使用了该注解就能在配置使用类中通过`@Autowired`注解将配置类进行注入,此外给容器注入组件的方法的所有传参都会自动使用容器组件,因此我们不需要再使用`@Autowired`注解进行注入,直接给方法传参对应类型的组件即可,这就是完全模仿`org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration`中的`determineConfiguration(ClassLoader classLoader)`方法做的配置 } 2️⃣-1️⃣ redisCacheManager.initialCacheNames(new LinkedHashSet<>(cacheNames)) public RedisCacheManagerBuilder initialCacheNames(Set<String> cacheNames) { Assert.notNull(cacheNames, "CacheNames must not be null!"); Map<String, RedisCacheConfiguration> cacheConfigMap = new LinkedHashMap<>(cacheNames.size()); cacheNames.forEach(it -> cacheConfigMap.put(it, defaultCacheConfiguration));//对缓存名字进行遍历,将每个缓存名和默认缓存配置对应起来存入LinkedHashMap<String, RedisCacheConfiguration>类型的cacheConfigMap return withInitialCacheConfigurations(cacheConfigMap);2️⃣-1️⃣-1️⃣ //利用这个使用了默认配置的cacheConfigMap来初始化缓存 } 2️⃣-1️⃣-1️⃣ redisCacheManager.redisCacheManagerBuilder.withInitialCacheConfigurations(cacheConfigMap) public RedisCacheManagerBuilder withInitialCacheConfigurations( Map<String, RedisCacheConfiguration> cacheConfigurations) { Assert.notNull(cacheConfigurations, "CacheConfigurations must not be null!"); cacheConfigurations.forEach((cacheName, configuration) -> Assert.notNull(configuration, String.format("RedisCacheConfiguration for cache %s must not be null!", cacheName))); this.initialCaches.putAll(cacheConfigurations);//将cacheConfigMap存入LinkedHashMap<String, RedisCacheConfiguration>中 return this; } -
org.springframework.data.redis.cache.RedisCacheConfigurationspring-boot-starter-data-redis2.1.10RELEASED -------------------------------------------------------------------------------------------------- public class RedisCacheConfiguration { //通过自定义组件指定以下属性的方式可以自定义配置基于Redis的缓存过期时间、是否缓存空值、是否加前缀、key和value分别采用哪种序列化方式,如果不指定就会在org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration的determineConfiguration方法中使用这个类的defaultCacheConfig()方法 private final Duration ttl; private final boolean cacheNullValues; private final CacheKeyPrefix keyPrefix; private final boolean usePrefix; private final SerializationPair<String> keySerializationPair; private final SerializationPair<Object> valueSerializationPair; private final ConversionService conversionService; @SuppressWarnings("unchecked") private RedisCacheConfiguration(Duration ttl, Boolean cacheNullValues, Boolean usePrefix, CacheKeyPrefix keyPrefix, SerializationPair<String> keySerializationPair, SerializationPair<?> valueSerializationPair, ConversionService conversionService) { this.ttl = ttl; this.cacheNullValues = cacheNullValues; this.usePrefix = usePrefix; this.keyPrefix = keyPrefix; this.keySerializationPair = keySerializationPair; this.valueSerializationPair = (SerializationPair<Object>) valueSerializationPair; this.conversionService = conversionService; } /** * Default {@link RedisCacheConfiguration} using the following: * <dl> * <dt>key expiration</dt> * <dd>eternal</dd> * <dt>cache null values</dt> * <dd>yes</dd> * <dt>prefix cache keys</dt> * <dd>yes</dd> * <dt>default prefix</dt> * <dd>[the actual cache name]</dd> * <dt>key serializer</dt> * <dd>{@link org.springframework.data.redis.serializer.StringRedisSerializer}</dd> * <dt>value serializer</dt> * <dd>{@link org.springframework.data.redis.serializer.JdkSerializationRedisSerializer}</dd> * <dt>conversion service</dt> * <dd>{@link DefaultFormattingConversionService} with {@link #registerDefaultConverters(ConverterRegistry) default} * cache key converters</dd> * </dl> * * @return new {@link RedisCacheConfiguration}. * 该方法上的注释指明了默认redis缓存配置,分别为没有指定过期时间、支持缓存空值、缓存的key支持添加前缀、默认前缀为当前缓存的名字、key的序列化器使用的是StringRedisSerializer,value的序列化器使用的JdkSerializationRedisSerializer,涉及到的时间日期格式转化使用的是DefaultFormattingConversionService */ public static RedisCacheConfiguration defaultCacheConfig() { return defaultCacheConfig(null); }//defaultCacheConfig()方法的返回值还是RedisCacheConfiguration,而且更改其中配置的entryTtl(Duration ttl)方法的返回值还是RedisCacheConfiguration,说明我们可以通过链式调用的方式来更改RedisCacheConfiguration组件的属性配置,但是通过entryTtl(Duration ttl)方法我们可以发现,RedisCacheConfiguration更改配置的方式是将我们的目标值替换对应属性的旧值并以对应属性的新值和调用修改方法的原对象的属性旧值作为参数再构造一个全新的对象进行返回,因此我们可以先通过静态defaultCacheConfig()创建出一个默认配置的RedisCacheConfiguration对象,在默认配置的基础上调用serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))更改key的序列化方式为Redis的序列化器StringRedisSerializer(),调用serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()))来更改value的序列化方式使用Spring提供的基于Jackson的乐意将任意类型对象转换成json格式字符串的序列化器[这里key一般都是指定字符串,所以使用StringRedisSerializer将字符串转换成json格式即可,但是value一般都是各种各样的对象,因此需要使用Generic标识的json格式序列化器,该序列化器在转换过程中还会添加一个@Class属性指定json对象对应的全限定类名],org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration的determineConfiguration方法中也是通过这种方式将默认配置修改为redisProperties中的对应属性配置 /** * Create default {@link RedisCacheConfiguration} given {@link ClassLoader} using the following: * <dl> * <dt>key expiration</dt> * <dd>eternal</dd> * <dt>cache null values</dt> * <dd>yes</dd> * <dt>prefix cache keys</dt> * <dd>yes</dd> * <dt>default prefix</dt> * <dd>[the actual cache name]</dd> * <dt>key serializer</dt> * <dd>{@link org.springframework.data.redis.serializer.StringRedisSerializer}</dd> * <dt>value serializer</dt> * <dd>{@link org.springframework.data.redis.serializer.JdkSerializationRedisSerializer}</dd> * <dt>conversion service</dt> * <dd>{@link DefaultFormattingConversionService} with {@link #registerDefaultConverters(ConverterRegistry) default} * cache key converters</dd> * </dl> * * @param classLoader the {@link ClassLoader} used for deserialization by the * {@link org.springframework.data.redis.serializer.JdkSerializationRedisSerializer}. * @return new {@link RedisCacheConfiguration}. * @since 2.1 */ public static RedisCacheConfiguration defaultCacheConfig(@Nullable ClassLoader classLoader) { DefaultFormattingConversionService conversionService = new DefaultFormattingConversionService(); registerDefaultConverters(conversionService); return new RedisCacheConfiguration(Duration.ZERO, true, true, CacheKeyPrefix.simple(), SerializationPair.fromSerializer(RedisSerializer.string()), SerializationPair.fromSerializer(RedisSerializer.java(classLoader)), conversionService); } /** * Set the ttl to apply for cache entries. Use {@link Duration#ZERO} to declare an eternal cache. * * @param ttl must not be {@literal null}. * @return new {@link RedisCacheConfiguration}. */ public RedisCacheConfiguration entryTtl(Duration ttl) { Assert.notNull(ttl, "TTL duration must not be null!"); return new RedisCacheConfiguration(ttl, cacheNullValues, usePrefix, keyPrefix, keySerializationPair, valueSerializationPair, conversionService); } /** * Use the given prefix instead of the default one. * * @param prefix must not be {@literal null}. * @return new {@link RedisCacheConfiguration}. */ public RedisCacheConfiguration prefixKeysWith(String prefix) { Assert.notNull(prefix, "Prefix must not be null!"); return computePrefixWith((cacheName) -> prefix); } /** * Use the given {@link CacheKeyPrefix} to compute the prefix for the actual Redis {@literal key} on the * {@literal cache name}. * * @param cacheKeyPrefix must not be {@literal null}. * @return new {@link RedisCacheConfiguration}. * @since 2.0.4 */ public RedisCacheConfiguration computePrefixWith(CacheKeyPrefix cacheKeyPrefix) { Assert.notNull(cacheKeyPrefix, "Function for computing prefix must not be null!"); return new RedisCacheConfiguration(ttl, cacheNullValues, true, cacheKeyPrefix, keySerializationPair, valueSerializationPair, conversionService); } /** * Disable caching {@literal null} values. <br /> * <strong>NOTE</strong> any {@link org.springframework.cache.Cache#put(Object, Object)} operation involving * {@literal null} value will error. Nothing will be written to Redis, nothing will be removed. An already existing * key will still be there afterwards with the very same value as before. * * @return new {@link RedisCacheConfiguration}. */ public RedisCacheConfiguration disableCachingNullValues() { return new RedisCacheConfiguration(ttl, false, usePrefix, keyPrefix, keySerializationPair, valueSerializationPair, conversionService); } /** * Disable using cache key prefixes. <br /> * <strong>NOTE</strong>: {@link Cache#clear()} might result in unintended removal of {@literal key}s in Redis. Make * sure to use a dedicated Redis instance when disabling prefixes. * * @return new {@link RedisCacheConfiguration}. */ public RedisCacheConfiguration disableKeyPrefix() { return new RedisCacheConfiguration(ttl, cacheNullValues, false, keyPrefix, keySerializationPair, valueSerializationPair, conversionService); } /** * Define the {@link ConversionService} used for cache key to {@link String} conversion. * * @param conversionService must not be {@literal null}. * @return new {@link RedisCacheConfiguration}. */ public RedisCacheConfiguration withConversionService(ConversionService conversionService) { Assert.notNull(conversionService, "ConversionService must not be null!"); return new RedisCacheConfiguration(ttl, cacheNullValues, usePrefix, keyPrefix, keySerializationPair, valueSerializationPair, conversionService); } /** * Define the {@link SerializationPair} used for de-/serializing cache keys. * * @param keySerializationPair must not be {@literal null}. * @return new {@link RedisCacheConfiguration}. */ public RedisCacheConfiguration serializeKeysWith(SerializationPair<String> keySerializationPair) { Assert.notNull(keySerializationPair, "KeySerializationPair must not be null!"); return new RedisCacheConfiguration(ttl, cacheNullValues, usePrefix, keyPrefix, keySerializationPair, valueSerializationPair, conversionService); } /** * Define the {@link SerializationPair} used for de-/serializing cache values. * * @param valueSerializationPair must not be {@literal null}. * @return new {@link RedisCacheConfiguration}. */ public RedisCacheConfiguration serializeValuesWith(SerializationPair<?> valueSerializationPair) { Assert.notNull(valueSerializationPair, "ValueSerializationPair must not be null!"); return new RedisCacheConfiguration(ttl, cacheNullValues, usePrefix, keyPrefix, keySerializationPair, valueSerializationPair, conversionService); } /** * @return never {@literal null}. * @deprecated since 2.0.4. Please use {@link #getKeyPrefixFor(String)}. */ @Deprecated public Optional<String> getKeyPrefix() { return usePrefix() ? Optional.of(keyPrefix.compute("")) : Optional.empty(); } /** * Get the computed {@literal key} prefix for a given {@literal cacheName}. * * @return never {@literal null}. * @since 2.0.4 */ public String getKeyPrefixFor(String cacheName) { Assert.notNull(cacheName, "Cache name must not be null!"); return keyPrefix.compute(cacheName); } /** * @return {@literal true} if cache keys need to be prefixed with the {@link #getKeyPrefixFor(String)} if present or * the default which resolves to {@link Cache#getName()}. */ public boolean usePrefix() { return usePrefix; } /** * @return {@literal true} if caching {@literal null} is allowed. */ public boolean getAllowCacheNullValues() { return cacheNullValues; } /** * @return never {@literal null}. */ public SerializationPair<String> getKeySerializationPair() { return keySerializationPair; } /** * @return never {@literal null}. */ public SerializationPair<Object> getValueSerializationPair() { return valueSerializationPair; } /** * @return The expiration time (ttl) for cache entries. Never {@literal null}. */ public Duration getTtl() { return ttl; } /** * @return The {@link ConversionService} used for cache key to {@link String} conversion. Never {@literal null}. */ public ConversionService getConversionService() { return conversionService; } /** * Registers default cache key converters. The following converters get registered: * <ul> * <li>{@link String} to {@link byte byte[]} using UTF-8 encoding.</li> * <li>{@link SimpleKey} to {@link String}</li> * * @param registry must not be {@literal null}. */ public static void registerDefaultConverters(ConverterRegistry registry) { Assert.notNull(registry, "ConverterRegistry must not be null!"); registry.addConverter(String.class, byte[].class, source -> source.getBytes(StandardCharsets.UTF_8)); registry.addConverter(SimpleKey.class, String.class, SimpleKey::toString); } } -
自定义组件
org.springframework.data.redis.cache.RedisCacheConfigurationorg.springframework.data.redis.cache.RedisCacheConfiguration的defaultCacheConfig()方法的返回值还是RedisCacheConfiguration,而且更改其中配置的entryTtl(Duration ttl)方法的返回值还是RedisCacheConfiguration,说明我们可以通过链式调用的方式来更改RedisCacheConfiguration组件的属性配置,但是通过entryTtl(Duration ttl)方法我们可以发现,RedisCacheConfiguration更改配置的方式是将我们的目标值替换对应属性的旧值并以对应属性的新值和调用修改方法的原对象的属性旧值作为参数再构造一个全新的对象进行返回,因此我们可以先通过静态defaultCacheConfig()创建出一个默认配置的RedisCacheConfiguration对象,在默认配置的基础上调用serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))更改key的序列化方式为Redis的序列化器StringRedisSerializer(),调用serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()))来更改value的序列化方式使用Spring提供的基于Jackson的乐意将任意类型对象转换成json格式字符串的序列化器[这里key一般都是指定字符串,所以使用StringRedisSerializer将字符串转换成json格式即可,但是value一般都是各种各样的对象,因此需要使用Generic标识的json格式序列化器,该序列化器在转换过程中还会添加一个@Class属性指定json对象对应的全限定类名],org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration的determineConfiguration方法中也是通过这种方式将默认配置修改为redisProperties中的对应属性配置- 构造
Redis的序列化器需要通过方法RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())传参对应的Redis的序列化器RedisSerializer,接口RedisSerializer的直接实现类有十个,实现类中名字带Json的都是和json有关的序列化器,其中的GenericFastJsonRedisSerializer这种带Generic的实现类实现的是RedisSerializer<Object>支持转换任意类型的对象,该对象使用的是fastjson,如果系统中引入了fastjson就可以使用该序列化器,如果系统中没有引入就使用Spring提供的org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer,这两个序列化器效果都是一样的 - 通过配置我们自己定义的
RedisCacheConfiguration,会在org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration中的determineConfiguration(ClassLoader classLoader)方法中取消用cacheProperties中的配置修改org.springframework.data.redis.cache.RedisCacheConfiguration中的对应属性,因此我们所有配置在默认配置文件中的属性都会失效[比如我们在默认配置文件配置的缓存有效时间],因为在执行自动配置时发现我们自己配置了RedisCacheConfiguration,就会直接返回我们配置的组件,不会再继续执行cacheProperties的配置属性赋值操作了;因此使用自定义RedisCacheConfiguration组件还需要将配置文件中的所有Redis缓存相关配置都配置到该组件中,可以参考org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration中的determineConfiguration(ClassLoader classLoader)方法中的配置方式,这样我们仍然能通过配置文件指定对应的属性,缓存相关的配置类只是标注了注解@ConfigurationProperties(prefix="spring.cache")该注解只是声明该配置类和默认配置文件中以spring.cache为前缀的配置进行属性绑定,但是并没有将该配置类放入容器中,需要在配置使用类上标注@EnableConfigurationProperties(CacheProperties.class)导入该配置类,使用了该注解就能在配置使用类中通过@Autowired注解将配置类进行注入,此外给容器注入组件的方法的所有传参都会自动使用容器组件,因此我们不需要再使用@Autowired注解进行注入,直接给方法传参对应类型的组件即可,这就是完全模仿org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration中的determineConfiguration(ClassLoader classLoader)方法做的配置,配置示例如下例代码所示- ❓:在
org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration中也使用了cacheProerties,但是并没有使用下例所示的@EnableConfigurationProperties(CacheProperties.class)注解,而是使用了@Conditional(CacheCondition.class)注解,对应的配置类是通过该组件的构造方法传递进去的,思考以下@Conditional(CacheCondition.class)注解的作用,并思考能否采用这种方式来获取配置类
- ❓:在
- 使用其他缓存媒介也可以通过上述方法来自定义对应的缓存规则
/** * @author Earl * @version 1.0.0 * @描述 自定义缓存配置,该配置会自动在使用SpringCache相关功能时自动生效 * @创建日期 2024/09/03 * @since 1.0.0 */ @EnableConfigurationProperties(CacheProperties.class) @Configuration public class CustomCacheConfig { @Bean RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties){ RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig(); config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())) .serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer())); //下面完全是模仿`org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration`的`determineConfiguration`方法 CacheProperties.Redis redisProperties = cacheProperties.getRedis(); if (redisProperties.getTimeToLive() != null) { config = config.entryTtl(redisProperties.getTimeToLive()); } if (redisProperties.getKeyPrefix() != null) { config = config.prefixKeysWith(redisProperties.getKeyPrefix()); } if (!redisProperties.isCacheNullValues()) { config = config.disableCachingNullValues(); } if (!redisProperties.isUseKeyPrefix()) { config = config.disableKeyPrefix(); } return config; } }
相关注解
- 使用
SpringCache提供的以下几个注解@Cacheable,@CacheEvict,@CachePut,@Caching,@CacheConfig就能完成日常开发中缓存的大部分功能
-
@Cacheable:Triggers cache population.触发将数据保存到缓存的操作,标注在方法上表示当前方法的结果需要缓存;而且如果方法的返回结果在缓存中有,方法都不需要调用;如果缓存中没有,就会调用被标注的方法获取缓存并将结果进行缓存-
🔎:这种方式适用于读模式下添加缓存,存储同一种业务类型的数据,我们都将缓存指定为同一个分区,比如不管是一级商品分类数据还是全部商品分类数据,我们都划分为同一个缓存分区,这样就能方便地修改一个相关数据就能一下清除掉整个缓存分区
-
注意使用该注解重建缓存只需要加分布式锁
-
缓存数据建议按照业务类型来对缓存数据进行分区,该注解的
value属性和cacheNames属性互为别名,属性的数据类型均为String[],表示可以给一个或者多个缓存组件同时放入一份被标注方法的返回值,在Redis中缓存的key为Cache自动生成的category::SimpleKey []即缓存的名字::SimpleKey [];其中的缓存数据因为使用的是JDK的序列化方式,Redis客户端直接读取出来全是二进制码,但是读取到java客户端以后被反序列化以后就可以变成正常的字符串信息,示例如下:- 注意啊这种方式设置的缓存,默认是不设置有效时间的,即
ttl=-1,意味着缓存永远不会过期,这大部分情况下是不可接受的 - key也是系统默认自己生成而不是用户指定的,我们更希望这个key能由我们自己进行指定
- 使用默认的JDK来序列化缓存数据,不符合互联网数据大多以json形式交互的规范,如果一个PHP架构的异构系统想要获取缓存数据如果是经过JDK序列化就可能导致和异构系统不兼容,因此我们更希望使用json格式的缓存数据
@Cacheable({"category","product"})//将该方法的返回值同时给category和product缓存组件中各放入一份 @Override public List<CategoryEntity> getAllFirstLevelCategory() { List<CategoryEntity> firstLevelCategories = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("cat_level", 1)); return firstLevelCategories; } - 注意啊这种方式设置的缓存,默认是不设置有效时间的,即
-
存在问题分析
-
通过
@Cacheable注解的key属性,该属性的注释上标注了key属性值接受一个Spring Expression Language[SpEL表达式],意思是这个key可以不写死,可以通过#root.methodName获取当前的方法名作为key、#root.args[1]获取参数列表中的参数值来作为key等等 -
缓存的过期时间无法通过该注解的属性指定,但是可以在SpringBoot默认配置文件中通过
spring.cache.redis.time-to-live=3600000指定以毫秒为单位的过期时间,这里是指定缓存的过期时间为一个小时,不过这种方式很容易导致缓存雪崩-
除了以上介绍还可以通过属性
keyGenerator指定一个key的生成器、通过属性cacheManager指定缓存管理器、通过属性condition()还能指定添加缓存的条件[接受一个SpEL表达式]、通过属性unless指定在除非满足指定条件下才将方法返回值添加缓存、通过属性sync指定通过同步的方式添加缓存[使用同步的方式unless属性就无法使用] -
SpEL表达式:
- 官方文档:https://docs.spring.io/spring-framework/docs/5.3.39/reference/html/integration.html#cache-specific-config
- Location是定位使用的根对象
Name Location Description Example methodNameRoot object 使用方法名作为SpEl表达式 #root.methodNamemethodRoot object 使用方法名作为SpEl表达式 #root.method.nametargetRoot object The target object being invoked #root.targettargetClassRoot object The class of the target being invoked #root.targetClassargsRoot object 按顺序取出所有的参数,使用下标索引来获取指定的参数 #root.args[0]cachesRoot object 当前方法配置的value属性的第一个缓存组件名字 #root.caches[0].nameArgument name Evaluation context Name of any of the method arguments. If the names are not available (perhaps due to having no debug information), the argument names are also available under the #a<#arg>where#argstands for the argument index (starting from0).#ibanor#a0(you can also use#p0or#p<#arg>notation as an alias).resultEvaluation context The result of the method call (the value to be cached). Only available in unlessexpressions,cache putexpressions (to compute thekey), orcache evictexpressions (whenbeforeInvocationisfalse). For supported wrappers (such asOptional),#resultrefers to the actual object, not the wrapper.#result- 表达式中使用字符串需要使用单引号括起来
-
除了SpEL表达式还可以通过以下方式来自定义key,如下例所示
@Cacheable(value="users", key="#id") public User find(Integer id) { returnnull; } @Cacheable(value="users", key="#p0") public User find(Integer id) { returnnull; } @Cacheable(value="users", key="#user.id") public User find(User user) { returnnull; } @Cacheable(value="users", key="#p0.id") public User find(User user) { returnnull; }
-
【指定key的代码示例】
@Cacheable(value = {"category"},key="#root.method.name") @Override public List<CategoryEntity> getAllFirstLevelCategory() { List<CategoryEntity> firstLevelCategories = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("cat_level", 1)); return firstLevelCategories; }【指定过期时间的配置示例】
#这种方式会指定所有缓存在Redis中的有效时间,不太好,一个是缓存有效时间粒度太大,一个是容易造成缓存雪崩 spring.cache.redis.time-to-live=3600000【指定缓存的key前缀】
-
实际开发中更推荐使用缓存分区的名字作为缓存key的前缀,即不再指定
spring.cache.redis.key-prefix=CACHE_,使用默认的前缀配置,同时不要禁用使用key的前缀,这样做的好处是以缓存分区的名字作为前缀会在Redis中以缓存分区名字作为根目录,在根目录下跟完整key的缓存键值对,这样看起来分区逻辑更明了【自定义key前缀的缓存数据结构】
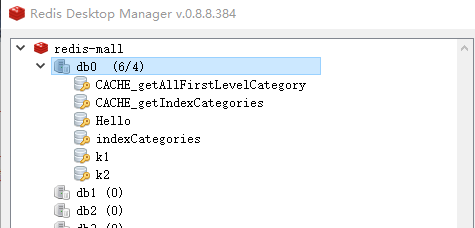
【默认缓存分区名字作为key前缀的缓存数据结构】
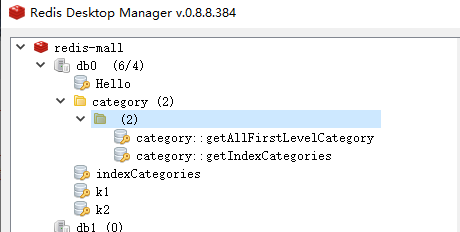
#在缓存的key前面加上一个前缀来作为某种标识,这里使用CACHE_前缀标识以CACHE_开头的键值对都是缓存,注意这个key指定了前缀是以我们`指定的前缀`+`_`+`指定的key`作为缓存的key,此时前缀会取代默认的缓存分区名字,缓存的key就不会再自动以缓存分区名字作为key的前缀了 spring.cache.redis.key-prefix=CACHE_ #该配置表示是否开启对key前缀配置的使用,默认值是true,如果不想使用前缀可以指定false来禁用掉,如果禁用掉前缀连默认的以缓存分区名字作为前缀都会被禁用掉,用户在@Cacheable注解中指定的key是什么样对应缓存的key就是一模一样的 spring.cache.redis.use-key-prefix=true【指定是否缓存空值】
#指定是否缓存空值,默认也是true,对于缓存穿透问题要求我们对不存在的结果进行空值缓存,这样能防止恶意请求对不存在的数据进行高频直接访问数据库来达到攻击数据库的目的,因此一般都要开启空值缓存,这样当使用SpringCache的相关注解功能时,如果查询到结果为null,也会将对应的空值缓存到缓存媒介中,缓存空值会使用一个NullValue对象来封装空值,缓存中能看到NullValue的全限定类名 spring.cache.redis.cache-null-values=true -
-
将数据保存为json格式就比较麻烦了,牵涉到自定义缓存管理器
- 原理见下面的自动配置说明,并结合谷粒商城项目的
P167-P170来进行理解,这一块讲的很妙啊,应该多次回味,市面上很少有SpringCache的相关教程
/** * @author Earl * @version 1.0.0 * @描述 自定义缓存配置,该配置会自动在使用SpringCache相关功能时自动生效 * @创建日期 2024/09/03 * @since 1.0.0 */ @EnableConfigurationProperties(CacheProperties.class) @Configuration public class CustomCacheConfig { @Bean RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties){ RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig(); config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())) .serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer())); //下面完全是模仿`org.springframework.boot.autoconfigure.cache.RedisCacheConfiguration`的`determineConfiguration`方法 CacheProperties.Redis redisProperties = cacheProperties.getRedis(); if (redisProperties.getTimeToLive() != null) { config = config.entryTtl(redisProperties.getTimeToLive()); } if (redisProperties.getKeyPrefix() != null) { config = config.prefixKeysWith(redisProperties.getKeyPrefix()); } if (!redisProperties.isCacheNullValues()) { config = config.disableCachingNullValues(); } if (!redisProperties.isUseKeyPrefix()) { config = config.disableKeyPrefix(); } return config; } } - 原理见下面的自动配置说明,并结合谷粒商城项目的
-
-
@CacheEvict:Triggers cache eviction.触发将数据从缓存中删除的操作,只是在调用方法以后删除指定键值对的缓存,下次对相关数据进行读操作时会由对应的读数据方法重建缓存-
🔎:这种方式适用于在写数据库的情况下使用失效模式在写数据库以后清空对应的缓存
-
通过注解
@CacheEvict的value属性能指定要清空缓存所在的缓存分区,通过key属性指定要清空的目标缓存的key,value属性都是String类型的参数值,key属性值需要填入SpEl表达式,如果key属性值不是SpEL表达式正常情况下项目启动控制台就会报错说取不出该属性值[不加单引号表示字符串的都会被认为是动态取值],但是编译不会报错@CacheEvict(value="category",key="'getAllFirstLevelCategory'") @Override @Transactional public void updateRelatedData(CategoryEntity category) { this.updateById(category); if(StringUtils.hasLength(category.getName())){ categoryBrandRelationDao.updateCategoryNameByCatId(category.getCatId(),category.getName()); } //TODO 商品分类名称变化更新对应的冗余字段 } -
在通过注解
@CacheEvict的value属性指定缓存分区后,将布尔类型的属性allEntries设置为true,此时每次执行@CacheEvict注解标注的方法都会直接将整个缓存分区的所有缓存数据删掉- 通过这种方式能批量直接删除一个缓存分区中的所有数据
@CacheEvict(value="category",allEntries = true) @Override @Transactional public void updateRelatedData(CategoryEntity category) { this.updateById(category); if(StringUtils.hasLength(category.getName())){ categoryBrandRelationDao.updateCategoryNameByCatId(category.getCatId(),category.getName()); } //TODO 商品分类名称变化更新对应的冗余字段 }
-
-
@CachePut:以不影响方法执行的方式更新缓存业务类型对缓存进行分区,即使有缓存数据也会去执行业务方法,并且在业务方法执行结束以后将方法的返回结果替换掉缓存中相同key的缓存数据 -
@Caching:组合@Cacheable,@CacheEvict,@CachePut多个缓存操作来一次执行-
@Caching注解中的属性类型分别是Cacheable[]、CachePut[]、CacheEvict[],即可以通过该注解指定多个@Cacheable,@CacheEvict,@CachePut操作,可以进行多缓存分区多种缓存操作类型@Caching(evict = { @CacheEvict(value = "category",key = "'getAllFirstLevelCategory'"), @CacheEvict(value = "category",key = "'getIndexCategories'") }) @Override @Transactional public void updateRelatedData(CategoryEntity category) { this.updateById(category); if(StringUtils.hasLength(category.getName())){ categoryBrandRelationDao.updateCategoryNameByCatId(category.getCatId(),category.getName()); } //TODO 商品分类名称变化更新对应的冗余字段 }
-
-
@CacheConfig:在类级别即一个类上共享缓存的相同配置
@Cacheable注解不生效
-
问题描述
-
使用@Cacheable注解时,一个方法A调同一个类里的另一个有缓存注解的方法B,这样是不走缓存的。例如在同一个service里面两个方法的调用,被调用方法加了缓存是不生效的
-
代码示例
// get 方法调用了 stockGive 方法,stockGive 方法使用了缓存 // 但是每次执行get 方法的时候,缓存都没有生成,也就是缓存没有被创建 public void get(){ stockGive(0L); } @Override @Cacheable(value = CacheConfig.COMMON, key = "'stock/give'+#memberId") public List<Map<String, Object>> stockGive(Long memberId) { // do something }
-
-
解决办法
- 1️⃣:不使用注解的方式,直接取 Ehcache 的 CacheManger 对象,把需要缓存的数据放到里面,类似于使用 Map,缓存的逻辑自己控制;或者可以使用redis的缓存方式去添加缓存;
- 2️⃣:把方法A和方法B放到两个不同的类里面,例如:如果两个方法都在同一个service接口里,把方法B放到另一个service里面,这样在A方法里调B方法,就可以使用B方法的缓存
-
缓存没有被正常创建的原因
- 因为
@Cacheable是使用AOP代理实现的 ,通过创建内部类来代理缓存方法,这样就会导致一个问题,类内部的方法调用类内部的缓存方法不会走代理,不会走代理,就不能正常创建缓存,所以每次都需要去调用数据库。
- 因为
-
使用
@Cacheable注解的一些注意点-
因为@Cacheable 由AOP 实现,所以,如果该方法被其它注解切入,当缓存命中的时候,则其它注解不能正常切入并执行,@Before 也不行,当缓存没有命中的时候,其它注解可以正常工作
-
@Cacheable 方法不能进行内部方法调用,否则缓存无法创建
-
@Cacheable标注的方法,如果其所在的类实现了某一个接口,那么该方法也必须出现在接口里面,否则cache无效。
具体的原因是, Spring把实现类装载成为Bean的时候,会用代理包装一下,所以从Spring Bean的角度看,只有接口里面的方法是可见的,其它的都隐藏了,自然课看不到实现类里面的非接口方法,@Cacheable不起作用。解决办法是把对应的方法定义在接口中,接口中的对应方法不需要标注@Cacheable注解,@Cacheable注解也不能放接口里面 -
如果某一个Bean并没有实现任何接口,@Cacheable标注的方法只需要满足权限修饰符为public即可,因为这种Bean被Spring产生了代理, 看得到的只有public方法,本质上是Spring代理的问题,很多的基础设施比如安全,事务,日志等等可能都会遇到类似的问题
-
相关概念
-
使用说明图
- 一个应用要使用
SpringCache要首先给当前应用配置一个或者多个缓存管理器CacheManager
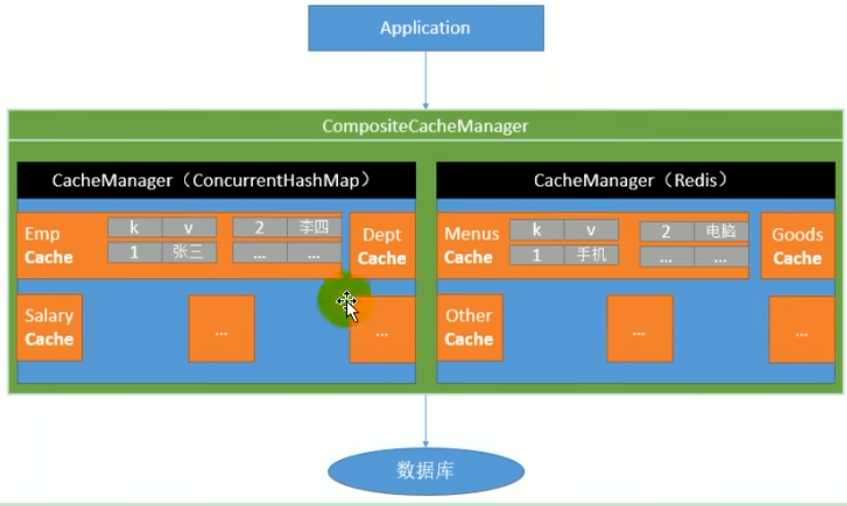
- 一个应用要使用
-
org.springframework.cache.CacheManager- 缓存管理器只有两个功能,第一个功能是按照String类型的名字获取缓存,第二个功能是获取当前缓存管理器管理的所有缓存的名字集合
CacheManager的实现非常多,直接实现类就有7个,比如ConcurrentMapCacheManager即该缓存管理器管理的所有缓存都是使用ConcurrentMap来做的,Redis对应也有缓存管理器RedisCacheManager,只要有对应的缓存管理器和缓存组件实现类,SpringCache就能兼容无限多种缓存场景- 老师说就把缓存管理器比作市政府,用来定制管理缓存组件即各个区的方法,比如缓存数据的过期时间是多少、缓存组件的缓存数据如何和具体的缓存媒介数据相互转换的,用缓存组件来保存缓存数据,每个缓存组件就相当于一个区,里面可以组织存放相关业务逻辑的缓存数据,只要清空一个缓存组件的缓存数据就能直接清空对应缓存媒介中关联的全部缓存
public interface CacheManager { @Nullable Cache getCache(String var1);//按照String类型的名字获取缓存 Collection<String> getCacheNames();//获取当前缓存管理器管理的所有缓存的名字集合 } -
org.springframework.cache.Cachepublic interface Cache { String getName();//获取当前缓存的名字 Object getNativeCache(); @Nullable Cache.ValueWrapper get(Object var1);//根据缓存的key从缓存中查询一个数据 @Nullable <T> T get(Object var1, @Nullable Class<T> var2); @Nullable <T> T get(Object var1, Callable<T> var2); void put(Object var1, @Nullable Object var2);//将key-value键值对保存至缓存中 @Nullable Cache.ValueWrapper putIfAbsent(Object var1, @Nullable Object var2); void evict(Object var1);//根据key从缓存中移除一个数据 void clear();//清空整个缓存 public static class ValueRetrievalException extends RuntimeException { @Nullable private final Object key; public ValueRetrievalException(@Nullable Object key, Callable<?> loader, Throwable ex) { super(String.format("Value for key '%s' could not be loaded using '%s'", key, loader), ex); this.key = key; } @Nullable public Object getKey() { return this.key; } } @FunctionalInterface public interface ValueWrapper { @Nullable Object get(); } } -
org.springframework.cache.concurrent.ConcurrentMapCacheManager- 缓存名字:缓存名字是缓存管理器要管理缓存组件,为了方便给每个组件起了一个名字,该名字就是缓存名字,一个缓存名字相当于给缓存数据划分了一个区,就像一个市里面的各个区,区里面的管理制度由市制定因此每个区的管理方法都是一样的,只是区里面的数据不一样;这样设计的好处是可以根据缓存名字一次性只清空某个区域下的全部缓存,这只是方便业务逻辑定义的一个缓存数据标识,不去指定也是可以的
public class ConcurrentMapCacheManager implements CacheManager, BeanClassLoaderAware { private final ConcurrentMap<String, Cache> cacheMap = new ConcurrentHashMap(16); private boolean dynamic = true; private boolean allowNullValues = true; private boolean storeByValue = false; @Nullable private SerializationDelegate serialization; public ConcurrentMapCacheManager() { } //ConcurrentMapCacheManager的构造方法要传参可变长度字符串缓存名字,缓存名字的概念是缓存管理器要管理缓存组件,为了方便给每个组件起了一个名字,该名字就是缓存名字,一个缓存名字相当于给缓存数据划分了一个区,就像一个市里面的各个区,区里面的管理制度由市制定因此每个区的管理方法都是一样的,只是区里面的数据不一样;这样设计的好处是可以根据缓存名字一次性只清空某个区域下的全部缓存,这只是方便业务逻辑定义的一个缓存数据标识,不去指定也是可以的 public ConcurrentMapCacheManager(String... cacheNames) { this.setCacheNames(Arrays.asList(cacheNames));1️⃣ //构造器会调用setCacheNames方法 } 1️⃣ //如果缓存不为空就会遍历每个缓存名字,以缓存名字作为key,以缓存Cache对象作为value,向ConcurrentMap<String,Cache>类型的cacheMap属性中添加缓存区域[这个Cache叫缓存组件],对应的缓存Cache通过方法createConcurrentMapCache(name)来创建, public void setCacheNames(@Nullable Collection<String> cacheNames) { if (cacheNames != null) { Iterator var2 = cacheNames.iterator(); while(var2.hasNext()) { String name = (String)var2.next(); this.cacheMap.put(name, this.createConcurrentMapCache(name));1️⃣-1️⃣ } this.dynamic = false; } else { this.dynamic = true; } } public void setAllowNullValues(boolean allowNullValues) { if (allowNullValues != this.allowNullValues) { this.allowNullValues = allowNullValues; this.recreateCaches(); } } public boolean isAllowNullValues() { return this.allowNullValues; } public void setStoreByValue(boolean storeByValue) { if (storeByValue != this.storeByValue) { this.storeByValue = storeByValue; this.recreateCaches(); } } public boolean isStoreByValue() { return this.storeByValue; } public void setBeanClassLoader(ClassLoader classLoader) { this.serialization = new SerializationDelegate(classLoader); if (this.isStoreByValue()) { this.recreateCaches(); } } public Collection<String> getCacheNames() { return Collections.unmodifiableSet(this.cacheMap.keySet()); } @Nullable public Cache getCache(String name) { Cache cache = (Cache)this.cacheMap.get(name); if (cache == null && this.dynamic) { synchronized(this.cacheMap) { cache = (Cache)this.cacheMap.get(name); if (cache == null) { cache = this.createConcurrentMapCache(name); this.cacheMap.put(name, cache); } } } return cache; } private void recreateCaches() { Iterator var1 = this.cacheMap.entrySet().iterator(); while(var1.hasNext()) { Entry<String, Cache> entry = (Entry)var1.next(); entry.setValue(this.createConcurrentMapCache((String)entry.getKey())); } } 1️⃣-1️⃣ //即初始化时根据传参的缓存名字创建一个缓存对象,对应ConcurrentMapCacheManager创建的Cache对象类型是ConcurrentMapCache,在该缓存组件会定义对缓存的增删改查操作 protected Cache createConcurrentMapCache(String name) { SerializationDelegate actualSerialization = this.isStoreByValue() ? this.serialization : null; return new ConcurrentMapCache(name, new ConcurrentHashMap(256), this.isAllowNullValues(), actualSerialization); } } -
org.springframework.cache.concurrent.ConcurrentMapCache- 该缓存组件会定义对缓存的增删改查操作
public class ConcurrentMapCache extends AbstractValueAdaptingCache { private final String name; private final ConcurrentMap<Object, Object> store;//store属性是缓存组件存储所有数据的地方,所有的缓存数据按照键值对的形式存入这个ConcurrentMap中,增删改查数据都是对store的增删改查操作 @Nullable private final SerializationDelegate serialization; public ConcurrentMapCache(String name) { this(name, new ConcurrentHashMap(256), true); } public ConcurrentMapCache(String name, boolean allowNullValues) { this(name, new ConcurrentHashMap(256), allowNullValues); } public ConcurrentMapCache(String name, ConcurrentMap<Object, Object> store, boolean allowNullValues) { this(name, store, allowNullValues, (SerializationDelegate)null); } protected ConcurrentMapCache(String name, ConcurrentMap<Object, Object> store, boolean allowNullValues, @Nullable SerializationDelegate serialization) { super(allowNullValues); Assert.notNull(name, "Name must not be null"); Assert.notNull(store, "Store must not be null"); this.name = name; this.store = store; this.serialization = serialization; } public final boolean isStoreByValue() { return this.serialization != null; } public final String getName() { return this.name; } public final ConcurrentMap<Object, Object> getNativeCache() { return this.store; } //lookup方法根据key从缓存组件中获取数据 @Nullable protected Object lookup(Object key) { return this.store.get(key); } @Nullable public <T> T get(Object key, Callable<T> valueLoader) { return this.fromStoreValue(this.store.computeIfAbsent(key, (k) -> { try { return this.toStoreValue(valueLoader.call()); } catch (Throwable var5) { throw new ValueRetrievalException(key, valueLoader, var5); } })); } public void put(Object key, @Nullable Object value) { this.store.put(key, this.toStoreValue(value)); } @Nullable public ValueWrapper putIfAbsent(Object key, @Nullable Object value) { Object existing = this.store.putIfAbsent(key, this.toStoreValue(value)); return this.toValueWrapper(existing); } public void evict(Object key) { this.store.remove(key); } public void clear() { this.store.clear(); } protected Object toStoreValue(@Nullable Object userValue) { Object storeValue = super.toStoreValue(userValue); if (this.serialization != null) { try { return this.serializeValue(this.serialization, storeValue); } catch (Throwable var4) { throw new IllegalArgumentException("Failed to serialize cache value '" + userValue + "'. Does it implement Serializable?", var4); } } else { return storeValue; } } private Object serializeValue(SerializationDelegate serialization, Object storeValue) throws IOException { ByteArrayOutputStream out = new ByteArrayOutputStream(); byte[] var4; try { serialization.serialize(storeValue, out); var4 = out.toByteArray(); } finally { out.close(); } return var4; } protected Object fromStoreValue(@Nullable Object storeValue) { if (storeValue != null && this.serialization != null) { try { return super.fromStoreValue(this.deserializeValue(this.serialization, storeValue)); } catch (Throwable var3) { throw new IllegalArgumentException("Failed to deserialize cache value '" + storeValue + "'", var3); } } else { return super.fromStoreValue(storeValue); } } private Object deserializeValue(SerializationDelegate serialization, Object storeValue) throws IOException { ByteArrayInputStream in = new ByteArrayInputStream((byte[])((byte[])storeValue)); Object var4; try { var4 = serialization.deserialize(in); } finally { in.close(); } return var4; } }
缓存相关问题分析
-
缓存分区组件操作缓存的过程
-
CacheManager[RedisCacheManager]创建Cache[RedisCache]负责缓存的读写 -
缓存未建立情况下首次查询数据并构建缓存流程
- 从第一次构建缓存的流程可以看出来,第一次调用
redisCache.lookup(key)方法查询缓存未命中和执行完业务方法对返回结果调用redisCache.put(key,value)方法进行缓存,期间的所有方法都是没有加锁的,RedisCache类中只有get(key)方法加了本地锁,因此默认重建缓存过程是没有加锁的,因此使用SpringCache是会存在缓存击穿问题的;- 解决方法一是不使用
SpringCache自己手写使用分布式双重检查锁重建缓存; - 解决方法二是将
SpringCache的@Cacheable注解的sync属性改为true,默认值为false,该属性的作用是同步潜在的几个调用该注解标注方法尝试获取同一个key的结果的线程,说人话就是缓存没命中构建缓存时让构建缓存的线程同步,注意这里加的是本地锁
- 解决方法一是不使用
spring-data-redis:2.1.10.RELEASE //CacheAspectSupport类是缓存切面支持器,缓存所有功能都是拿AOP做的 -------------------------------------------------------------------------------------------------- CacheAspectSupport.execute @Nullable private Object execute(CacheOperationInvoker invoker, Method method, CacheAspectSupport.CacheOperationContexts contexts) { if (contexts.isSynchronized()) { CacheAspectSupport.CacheOperationContext context = (CacheAspectSupport.CacheOperationContext)contexts.get(CacheableOperation.class).iterator().next(); if (this.isConditionPassing(context, CacheOperationExpressionEvaluator.NO_RESULT)) { Object key = this.generateKey(context, CacheOperationExpressionEvaluator.NO_RESULT); Cache cache = (Cache)context.getCaches().iterator().next(); try { return this.wrapCacheValue(method, cache.get(key, () -> { return this.unwrapReturnValue(this.invokeOperation(invoker)); })); } catch (ValueRetrievalException var10) { throw (ThrowableWrapper)var10.getCause(); } } else { return this.invokeOperation(invoker); } } else { this.processCacheEvicts(contexts.get(CacheEvictOperation.class), true, CacheOperationExpressionEvaluator.NO_RESULT); ValueWrapper cacheHit = this.findCachedItem(contexts.get(CacheableOperation.class));1️⃣ //第一次获取缓存,通过返回值是否有值来检查缓存是否命中 List<CacheAspectSupport.CachePutRequest> cachePutRequests = new LinkedList(); if (cacheHit == null) { this.collectPutRequests(contexts.get(CacheableOperation.class), CacheOperationExpressionEvaluator.NO_RESULT, cachePutRequests);// } Object cacheValue; Object returnValue; if (cacheHit != null && !this.hasCachePut(contexts)) { cacheValue = cacheHit.get(); returnValue = this.wrapCacheValue(method, cacheValue); } else { returnValue = this.invokeOperation(invoker);//这一步进去就是执行用户定义的目标方法即业务逻辑并获取返回值赋值给returnValue cacheValue = this.unwrapReturnValue(returnValue);//将方法返回值包装成缓存数据对象 } this.collectPutRequests(contexts.get(CachePutOperation.class), cacheValue, cachePutRequests);2️⃣ //在这一步中将方法的返回值调用RedisCache.put()方法将缓存放入缓存媒介中,这儿一步到位跳到RedisCache的put方法 Iterator var8 = cachePutRequests.iterator(); while(var8.hasNext()) { CacheAspectSupport.CachePutRequest cachePutRequest = (CacheAspectSupport.CachePutRequest)var8.next(); cachePutRequest.apply(cacheValue); } this.processCacheEvicts(contexts.get(CacheEvictOperation.class), false, cacheValue); return returnValue; } } 1️⃣ CacheAspectSupport.findCachedItem(contexts.get(CacheableOperation.class)) @Nullable private ValueWrapper findCachedItem(Collection<CacheAspectSupport.CacheOperationContext> contexts) { Object result = CacheOperationExpressionEvaluator.NO_RESULT; Iterator var3 = contexts.iterator(); while(var3.hasNext()) { CacheAspectSupport.CacheOperationContext context = (CacheAspectSupport.CacheOperationContext)var3.next(); if (this.isConditionPassing(context, result)) { Object key = this.generateKey(context, result); ValueWrapper cached = this.findInCaches(context, key);1️⃣-1️⃣ //调用findInCaches第一次查询缓存,如果不是空直接返回查询到的缓存,如果是空检查是否需要打印日志并返回空值 if (cached != null) { return cached; } if (this.logger.isTraceEnabled()) { this.logger.trace("No cache entry for key '" + key + "' in cache(s) " + context.getCacheNames()); } } } return null; } 2️⃣ redisCache.put() /* * (non-Javadoc) * @see org.springframework.cache.Cache#put(java.lang.Object, java.lang.Object) */ @Override public void put(Object key, @Nullable Object value) { Object cacheValue = preProcessCacheValue(value); if (!isAllowNullValues() && cacheValue == null) { throw new IllegalArgumentException(String.format( "Cache '%s' does not allow 'null' values. Avoid storing null via '@Cacheable(unless=\"#result == null\")' or configure RedisCache to allow 'null' via RedisCacheConfiguration.", name)); } cacheWriter.put(name, createAndConvertCacheKey(key), serializeCacheValue(cacheValue), cacheConfig.getTtl()); } 1️⃣-1️⃣ CacheAspectSupport.findInCaches(context, key) @Nullable private ValueWrapper findInCaches(CacheAspectSupport.CacheOperationContext context, Object key) { Iterator var3 = context.getCaches().iterator(); Cache cache; ValueWrapper wrapper; do { if (!var3.hasNext()) { return null; } cache = (Cache)var3.next(); wrapper = this.doGet(cache, key);1️⃣-1️⃣-1️⃣ //调用doGet方法从缓存媒介中拿缓存赋值给wrapper,如果wrapper不为null则直接返回,如果为null,检查是否需要打印日志,然后直接返回null } while(wrapper == null); if (this.logger.isTraceEnabled()) { this.logger.trace("Cache entry for key '" + key + "' found in cache '" + cache.getName() + "'"); } return wrapper; } 1️⃣-1️⃣-1️⃣ AbstractCacheInvoker.doGet(cache, key) @Nullable protected ValueWrapper doGet(Cache cache, Object key) { try { return cache.get(key);1️⃣-1️⃣-1️⃣-1️⃣ //根据缓存的key尝试获取缓存 } catch (RuntimeException var4) { this.getErrorHandler().handleCacheGetError(var4, cache, key); return null; } } 1️⃣-1️⃣-1️⃣-1️⃣ AbstractValueAdaptingCache.get(key) @Nullable public ValueWrapper get(Object key) { Object value = this.lookup(key);1️⃣-1️⃣-1️⃣-1️⃣-1️⃣ //从这儿进入Cache组件的lookup方法尝试获取缓存数据 return this.toValueWrapper(value); } 1️⃣-1️⃣-1️⃣-1️⃣-1️⃣ redisCache.lookup(key) /* * (non-Javadoc) * @see org.springframework.cache.support.AbstractValueAdaptingCache#lookup(java.lang.Object) */ @Override protected Object lookup(Object key) {//查询缓存的方法 byte[] value = cacheWriter.get(name, createAndConvertCacheKey(key));//先从缓存中获取对应key的缓存数据,当缓存中没有数据时该方法会返回null,这是构建缓存执行业务方法前第一次尝试从缓存媒介中获取缓存 if (value == null) { return null;//返回null的情况下lookup方法就执行结束了 } return deserializeCacheValue(value); } - 从第一次构建缓存的流程可以看出来,第一次调用
-
开启
@Cacheable注解的sync功能后的缓存未建立情况下首次查询数据并构建缓存流程sync注解只有@Cacheable注解有,其他的SpringCache注解中是没有的,通过指定sync=true给重建缓存加本地锁解决缓存击穿问题,加的不是完整的分布式锁,老师说加本地锁就足够使用了,但是这里还是感觉不完美,第一个问题是可能有双重检查锁但是源码分析没看见第一次检查的影子,如果没有双重检查锁那不是开启了sync的缓存查询每次查缓存都会上锁,因此这里倾向于使用了双重检查锁但是目前还没看出来;第二个问题是锁的粒度非常大,直接锁单例组件redisCache,相当于直接锁服务实例,只要缓存重新构建就直接锁所有开启了sync的缓存的缓存重建过程- ❓:这里有没有使用双重检查锁要好好验证一下,对性能影响挺大的
spring-data-redis:2.1.10.RELEASE -------------------------------------------------------------------------------------------------- cacheAspectSupport.execute() @Nullable private Object execute(CacheOperationInvoker invoker, Method method, CacheAspectSupport.CacheOperationContexts contexts) { if (contexts.isSynchronized()) {//这里是判断@Cacheable注解的属性sync是否开启 CacheAspectSupport.CacheOperationContext context = (CacheAspectSupport.CacheOperationContext)contexts.get(CacheableOperation.class).iterator().next(); if (this.isConditionPassing(context, CacheOperationExpressionEvaluator.NO_RESULT)) { Object key = this.generateKey(context, CacheOperationExpressionEvaluator.NO_RESULT); Cache cache = (Cache)context.getCaches().iterator().next(); try { return this.wrapCacheValue(method, cache.get(key, () -> { return this.unwrapReturnValue(this.invokeOperation(invoker));//1️⃣ 封装一个异步查询业务方法结果的任务Callable<T>到execute方法的调用者,该调用者在调用redisCache.get()方法时将该任务传参进去了,并在缓存未命中的情况下发起异步任务,这个查询业务方法结果的方法其实上面未开启sync功能的流程已经说过了,就是这个方法下面的invokeOperation(invoker);并在此处通过cache.get(key,Callable<T>)调用RedisCache中的get方法 })); } catch (ValueRetrievalException var10) { throw (ThrowableWrapper)var10.getCause(); } } else { return this.invokeOperation(invoker); } } else { this.processCacheEvicts(contexts.get(CacheEvictOperation.class), true, CacheOperationExpressionEvaluator.NO_RESULT); ValueWrapper cacheHit = this.findCachedItem(contexts.get(CacheableOperation.class)); List<CacheAspectSupport.CachePutRequest> cachePutRequests = new LinkedList(); if (cacheHit == null) { this.collectPutRequests(contexts.get(CacheableOperation.class), CacheOperationExpressionEvaluator.NO_RESULT, cachePutRequests); } Object cacheValue; Object returnValue; if (cacheHit != null && !this.hasCachePut(contexts)) { cacheValue = cacheHit.get(); returnValue = this.wrapCacheValue(method, cacheValue); } else { returnValue = this.invokeOperation(invoker); cacheValue = this.unwrapReturnValue(returnValue); } this.collectPutRequests(contexts.get(CachePutOperation.class), cacheValue, cachePutRequests); Iterator var8 = cachePutRequests.iterator(); while(var8.hasNext()) { CacheAspectSupport.CachePutRequest cachePutRequest = (CacheAspectSupport.CachePutRequest)var8.next(); cachePutRequest.apply(cacheValue); } this.processCacheEvicts(contexts.get(CacheEvictOperation.class), false, cacheValue); return returnValue; } } 1️⃣ redisCache.get() //这个有锁的get方法和我们以前写的逻辑是一样的,但是没有看到双重检查锁的影子,而且锁的粒度非常大,锁整个缓存的构建,而且如果外部没有第一次检查,这里每个开启sync的缓存查询都会被上锁,这肯定是没讲到 public synchronized <T> T get(Object key, Callable<T> valueLoader) { ValueWrapper result = get(key);1️⃣-1️⃣ //第一次尝试从缓存中获取数据,注意因为是首次构建缓存,此时缓存中没有数据,该方法调用的是上面未开启功能时调用的从父类AbstractValueAdaptingCache继承来的1️⃣-1️⃣-1️⃣-1️⃣ AbstractValueAdaptingCache.get(key),这个方法实际上调用的是上面的1️⃣-1️⃣-1️⃣-1️⃣-1️⃣ redisCache.lookup(key)尝试去从缓存媒介获取缓存,但是因为是首次构建,所以此处会返回空值 //如果缓存被命中直接返回 if (result != null) { return (T) result.get(); } //如果缓存没有命中就去执行业务方法,获取返回值并调用将键值对存入调用redisCache.put(key,value)方法缓存媒介中 T value = valueFromLoader(key, valueLoader);1️⃣-2️⃣ //执行业务方法获取返回值 put(key, value);1️⃣-3️⃣ //调用redisCache.put方法将缓存数据键值对存入缓存媒介 return value; } 1️⃣-1️⃣ AbstractValueAdaptingCache.get(key) @Nullable public ValueWrapper get(Object key) { Object value = this.lookup(key);1️⃣-1️⃣-1️⃣ //从这儿进入Cache组件的lookup方法尝试获取缓存数据 return this.toValueWrapper(value); } 1️⃣-2️⃣ redisCache.valueFromLoader(key, valueLoader) private static <T> T valueFromLoader(Object key, Callable<T> valueLoader) { try { return valueLoader.call(); // 通过方法参数列表传参一个有返回结果的异步线程Callable的方式来调用业务方法,这里获取的返回值就是业务方法的返回值,该返回值返回给get方法 } catch (Exception e) { throw new ValueRetrievalException(key, valueLoader, e); } } 1️⃣-3️⃣ redisCache.put(key, value) @Override public void put(Object key, @Nullable Object value) { Object cacheValue = preProcessCacheValue(value); if (!isAllowNullValues() && cacheValue == null) { throw new IllegalArgumentException(String.format( "Cache '%s' does not allow 'null' values. Avoid storing null via '@Cacheable(unless=\"#result == null\")' or configure RedisCache to allow 'null' via RedisCacheConfiguration.", name)); } cacheWriter.put(name, createAndConvertCacheKey(key), serializeCacheValue(cacheValue), cacheConfig.getTtl());//将key和value序列化以后将数据存入缓存媒介 } 1️⃣-1️⃣-1️⃣ redisCache.lookup(key) /* * (non-Javadoc) * @see org.springframework.cache.support.AbstractValueAdaptingCache#lookup(java.lang.Object) */ @Override protected Object lookup(Object key) {//查询缓存的方法 byte[] value = cacheWriter.get(name, createAndConvertCacheKey(key));//先从缓存中获取对应key的缓存数据,当缓存中没有数据时该方法会返回null,这是构建缓存执行业务方法前第一次尝试从缓存媒介中获取缓存 if (value == null) { return null;//返回null的情况下lookup方法就执行结束了 } return deserializeCacheValue(value); }
-
-
读取构建缓存时会涉及到缓存穿透、缓存雪崩、缓存击穿的问题
- 缓存穿透:恶意高并发查询一个不存在的数据,将查询压力给到数据库导致数据库崩掉,
SpringCache给出了缓存空值的解决方案 - 缓存雪崩:大量的key同时过期,同时大量的并发请求因为获取不到缓存同时打到服务器上,此时就会发生缓存雪崩,自己管理缓存,我们通过加随机时间的方式来解决这个问题,但是老师说这种方式很容易弄巧成拙,老师给出的解释是不同有效期加上随机时间可能导致大量的缓存有效时间相同,我觉得这个解释有点牵强;
SpringCache中只要为每个数据指定有效期,每个缓存建立的时间是分散随机的,在有效期相同情况下,即使在大量分散并发请求下重建缓存的时间点也是随机的,因此不需要考虑给有效期加随机时间,而且老师说只有超大型系统才可能存在这种情况,在一般的系统中,只要不是十几万个key同时过期,即使是key同时过期了,而且所有key的请求都访问数据库重建缓存,就不会对数据库造成不可挽回的压力,因此一般系统中根本不需要考虑该问题- 🔎:而且这里的有效时间设置的太粗暴,直接把所有缓存的有效时间都设置成一样的了
- 缓存击穿,大量并发请求同时来查询一个正好过期的数据,解决办法是加锁,但是这里暂时还没有处理添加了
SpringCache以后的逻辑,应该加个双重检查锁也一样的,但是如何保证使用SpringCache以后判断完双重检查锁直接拿缓存且避免用拿到的缓存再更新缓存的问题呢
- 缓存穿透:恶意高并发查询一个不存在的数据,将查询压力给到数据库导致数据库崩掉,
-
写数据库时考虑缓存数据一致性的问题
- 🔎:对于写数据库时缓存数据的一致性问题,SpringCache根本没管,需要根据业务场景自己设置,还是提供了一个很垃圾的缓存有效时间来实现缓存数据的最大更新间隔时间来解决写模式的数据一致性问题,常规数据使用SpringCache主要优势在简化开发、方便缓存管理,像缓存分区这种相关功能都是很好用的,自己实现起来就比较麻烦,对于特殊数据再考虑单独设计
- 对要求数据强一致性的读多写少场景直接加分布式读写锁
- 引入Canal感知
mysql的更新去更新缓存 - 读多写多的场景直接去查询数据库
-
总结
- 常规数据[读多写少,实时性、缓存数据一致性要求不高的数据],可以直接使用
SpringCache,常规数据的写模式数据一致性通过SpringCache的缓存有效时间简单控制即可 - 特殊数据[实时性、一致性要求高的数据],想要通过加缓存提升速度,还想要保证一致性,就需要特殊设计**[比如引入Canal、加读写锁、公平锁、可重入锁、信号量、闭锁等结合业务单独设计]**
- 对于商品分类菜单数据,我们只需要考虑解决读模式下的缓存穿透、雪崩和击穿问题,即使用
SpringCache管理缓存即可
- 常规数据[读多写少,实时性、缓存数据一致性要求不高的数据],可以直接使用
SpringCloud生态
SpringCloud Alibaba
SpringCloud Alibaba需要和SpringCloud、SpringBoot三者相互进行版本配合,版本要求在SpringCloud的官方文档可以查看
-
SpringBoot微服务引入SpringCloud Alibaba依赖的版本控制
-
公共服务或者父工程做依赖版本控制【依赖管理】
使用SpringCloud Alibaba组件会自动仲裁组件【nacos、Seata、Sentinel、RocketMQ】依赖为2.1.0.RELEASE版本
<dependencyManagement> <dependencies> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.1.0.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
-
整合Nacos
注册中心
-
引入nacos服务注册发现的依赖
<!--nacos--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-nacos-discovery</artifactId> </dependency> -
启动nacos服务器nacos-server,通过8848端口可以访问nacos,如
http://localhost:8848/nacos默认账户和密码都是nacos
-
在每个微服务的配置文件中通过属性
Spring.cloud.nacos.discovery.server-addr=localhost:8848指定nacos-server的地址,通过属性Spring.application.name=mall_coupon指定服务的名字,服务名使用横岗和下划线都可以Spring: cloud: nacos: discovery: server-addr: localhost:8848 application: name: mall-coupon -
在每个微服务的启动类上使用注解
@EnableDiscoveryClient开启服务注册与发现功能不太清楚注解
@EnableDiscoveryClient的作用,因为有案例我没加该注解一样能服务注册和服务发现,没加作为服务调用方一样能成功调用到服务@EnableDiscoveryClient @SpringBootApplication public class MallCouponApplication { public static void main(String[] args) { SpringApplication.run(MallCouponApplication.class, args); } }
配置中心
如果没有配置中心,修改配置文件需要每个微服务都要修改重新打包编译测试部署非常麻烦;有了配置中心就能实时同步并让微服务自动更新
以前SpringBoot任何从配置文件中获取属性值的注解都能使用,如@Value、@ConfigurationProperties,而且配置中心有的配置优先于本地配置
-
引入Nacos Config Starter
<!--nacos配置中心--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId> </dependency> -
在类路径即resources目录下创建bootstrap.properties文件
在该配置文件中配置nacos 配置中心元数据,该配置文件是SpringBoot的文件,会优先于application.properties先加载,从这里面获取配置中心的地址并获取到对应的配置文件
需要配置当前应用的名字并指定配置中心即nacos服务器的地址
高版本SpringBoot使用bootstrap必须加spring-cloud-starter-bootstrap依赖
spring.application.name=mall-coupon spring.cloud.nacos.config.name=.server-addr=localhost:8848 -
在使用读取配置文件属性值的类上添加注解@RefreshScope注解能同步更新配置文件上的实时更改数据
@RefreshScope注解只加在启动类上是不起作用的,必须添加到使用@Value注解注入对应属性值的类上面,如下所示
如果配置中心和当前应用的本地配置文件中都配置了相同的属性,优先使用配置中心的对应属性配置
@RestController @RequestMapping("coupon/coupon") @RefreshScope public class CouponController { @Autowired private CouponService couponService; @Value("${coupon.user.name}") private String username; @Value("${coupon.user.age}") private int age; } -
配置中心配置命名空间
基于环境做隔离:命名空间的目的就是做环境配置隔离,区分开发、测试、生产环境;默认不在bootstrap中配置属性
spring.cloud.nacos.config.namespace默认使用的是public命名空间,属性值为命名空间的id基于微服务做隔离:也可以给每个微服务创建命名空间,避免所有的微服务配置都放在一个命名空间下以区分微服务避免导致配置文件混乱,命名空间可以配置任意多个
配置集概念:一个微服务应用的所有配置文件集合就是配置集,一个微服务可以有无数个配置文件,配置集ID就是DataID
spring.cloud.nacos.config.namespace=a88106bf-1518-42a8-935e-bde7b0039596 -
配置分组
默认所有的配置集都属于配置集:DEFAULT_GROUP;效果是随意定义一组完整配置,在需要的情况下整组切换配置,如双十一用一组配置,双十二用一组配置;组的创建只需要在配置中心创建配置文件的时候自定义组名即可,然后在bootstrap中通过属性
spring.cloud.nacos.config.group进行配置,不写会使用默认组DEFAULT_GROUP也可以用这种方式来区分运行环境
#这个就可以表示双十一使用的配置组 spring.cloud.nacos.config.group=1111 -
拆分配置文件
一般不会让所有的配置写在一个文件中,这样会导致文件的不好管理;一般都拆分成数据源写入datasource.yml、MybatisPlus的配置放在mybatisplus.yml中,这里只是演示,实际上不需要变更的配置一般放本地,需要热更新的配置才会放在配置中心
依然会读取默认DataId的配置文件
这个特性周阳老师没讲过
#配置加载除了默认的dataId配置文件,还需要额外加载哪些DataId的配置文件,这个属性是一个数组,可以配置多个, # 每个不同的配置文件使用下标0,1,2...进行区分 # 配置额外加载dataId为datasource.yml的配置文件 spring.cloud.nacos.config.ext-config[0].data-id=datasource.yml #配置加载配置分组1111下的dataId为datasource.yml的配置文件 spring.cloud.nacos.config.ext-config[0].group=1111 #配置dataId为datasource.yml的配置文件是否能动态刷新,默认是false spring.cloud.nacos.config.ext-config[0].refresh=true spring.cloud.nacos.config.ext-config[1].data-id=mybatisplus.yml spring.cloud.nacos.config.ext-config[1].group=1111 spring.cloud.nacos.config.ext-config[1].refresh=true spring.cloud.nacos.config.ext-config[2].data-id=others.yml spring.cloud.nacos.config.ext-config[2].group=1111 spring.cloud.nacos.config.ext-config[2].refresh=true -
配置nacos的日志打印级别
- nacos经常频繁打印一些不重要的日志信息,打印
com.alibaba.nacos.client.naming相关的可以通过以下代码调高nacos对应信息的日志级别
logging: level: com.alibaba.nacos.client.naming: WARN - nacos经常频繁打印一些不重要的日志信息,打印
整合OpenFeign
-
引入OpenFeign的依赖
-
引入SpringCloud相关组件的版本控制
<properties> <spring-cloud.version>Greenwich.SR3</spring-cloud.version> </properties> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring-cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> -
引入OpenFeign依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>
-
-
在调用服务下定义一个调用指定服务的接口
服务调用接口统一写在feign包下,这个接口对应被调用服务有对应的实现,有参数需要传递参数
- OpenFeign处理参数为对象,参数前带
@RequestBody注解发起请求的逻辑- 如果Feign接口的请求参数是一个对象且请求参数前面带
@RequestBody注解,Feign会将该对象转成json字符串 - 通过Feign接口上的
@FeignClient注解标注的value属性根据服务名去注册中心找到对应的服务地址,向对应地址发起请求,因为参数为对象且有@RequestBody注解会自动将json字符串放在请求体中 - 对象服务接收到请求体,发现请求体中有json字符串,且对应的控制器方法参数前有
@RequestBody注解,就会尝试使用参数类型的对象去接收json串,只要属性名一致,不论参数类型是什么类型都能进行匹配,即接收请求的对象和发起请求转换为json的DT对象即使不是同一种类型的对象,只要有相同的属性名就能尝试解析【即只要json数据模型是兼容的,双方服务发起远程调用时传输和接收数据无需使用同一种TO类型】
- 如果Feign接口的请求参数是一个对象且请求参数前面带
@FeignClient("mall-coupon")//指定远程被调用服务的服务名 public interface CouponFeign { /** * @return {@link R } * @描述 指定目标服务被调用的方法,方法需要声明返回值类型、对应的方法名和请求uri * @author Earl * @version 1.0.0 * @创建日期 2024/01/27 * @since 1.0.0 */ @RequestMapping("/coupon/coupon/user/list") public R queryUserCouponList(); } - OpenFeign处理参数为对象,参数前带
-
在调用服务的启动类上添加@EnableFeignClients注解并指定服务调用接口所在的包
- 开启OpenFeign的服务调用功能并指定服务调用接口所在的包
- 🔎:注意没有这个注解
EnableFeignClients即使标注了@FeignClient注解组件也无法被注入IoC容器
@EnableFeignClients("com.earl.mall.user.feign") @SpringBootApplication public class MallUserApplication { public static void main(String[] args) { SpringApplication.run(MallUserApplication.class, args); } } -
在业务方法中使用远程调用接口
@Resource private CouponFeign couponFeign; /** * @return {@link R } * @描述 查询用户账户下的可用优惠券 * @author Earl * @version 1.0.0 * @创建日期 2024/01/27 * @since 1.0.0 */ @GetMapping("/coupon/list") public R queryUserCouponList(){ return couponFeign.queryUserCouponList(); } -
对服务调用超时的降级处理
整合GateWay网关
网关需要一个单独的服务,一般都在基础依赖配置好了SpringBoot和OpenFeign,也会配置服务注册与发现,spring-boot-starter-web不一定,因为网关不能配置这个,网关使用的是webflux,和springMVC会发生冲突,完整的网关依赖只需要nacos注册中心依赖和gateway依赖
-
需要引入服务注册与服务发现依赖
其实分布式项目一般都把这个配置写在基础依赖或者父pom中,作为系统的基础设置
<!--nacos注册中心--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-nacos-discovery</artifactId> </dependency>【网关单独配置】
网关需要配置spring-cloud-starter-gateway
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-gateway</artifactId> </dependency>-
在网关启动类上添加注解@EnableDiscoveryClient开启服务注册与发现
这样网关才能知道服务的位置来路由请求
@EnableDiscoveryClient @SpringBootApplication(exclude = {DataSourceAutoConfiguration.class}) public class MallGatewayApplication { public static void main(String[] args) { SpringApplication.run(MallGatewayApplication.class, args); } } -
在配置文件配置注册中心和配置中心的位置
注册中心写在application.yml中,配置中心地址写在bootstrap中
【配置中心】
Spring.application.name=mall-gateway spring.cloud.nacos.config.server-addr=localhost:8848 spring.cloud.nacos.config.namespace=7a52f0fa-5dcf-467d-a285-2ea2c382697b spring.profiles.active=dev【注册中心】
bootstrap中写了应用的名称,可以不在application.yml中配置应用名称
server: port: 88 spring: cloud: nacos: discovery: server-addr: localhost:8848 -
配置Gateway路由第三方网站功能
【application.yml】
spring: cloud: gateway: routes: - id: baidu_route uri: https://www.baidu.com predicates: ##如果请求的参数中含有url=baidu就路由到百度 - Query=url,baidu - id: qq_route uri: https://www.qq.com predicates: - Query=url,qq - id: admin_route uri: lb://renren-fast predicates: #Path断言意思是uri为指定路径就路由到该路由上来,这个表示请求路径的uri以/api开始都路由到renren-fast中 - Path=/api/** filters: #filters过滤器对请求uri进行重写,RewritePath=/api/(?<segment>.*),/renren-fast/$\{egment}表示将api换成renren-fast - RewritePath=/api/(?<segment>.*),/renren-fast/$\{segment}
-
云服务
对象存储
对象存储【Object Storage Service】适合存放任意类型的文件,阿里云的对象存储每个月免费5个G
控制台界面右边:常用入口–API文档–文档中心打开可以找到对象存储的官方文档
-
专业术语
- Bucket:Bucket就是文件存储的一个容器,推荐一个项目创建一个Bucket
- 对象/文件:就是存储的一个个文件
- 地域:创建一个Bucket时会选择所在地域,相同区域内的服务器可以内网互通,比如同一区域服务器和对象存储内网互通是不计入流量费用的
- Endpoint:访问域名,文件访问的域【URL除去URI的部分】
- AccessKey:包含
AccessKeyId和AccessKeySecret,存储文件对用户身份进行验证
-
注意事项
- 读写权限
- 公共读:表示对象存储的文件,写入需要密码可以被随意访问
- 私有:表示文件的读取和写入需要进行身份验证
- 公共读写:任何人在没有账号密码的请款下都可以操作Bucket
- 服务端加密不需要,日志查询也不需要
- 存储类型访问量大使用标准存储【高可靠、高可用、高性能】,一般项目低频访问就行
- 上传的文件会自动生成一个https地址,可以在任意地方通过该地址对文件进行访问;通过后台服务整合sdk可以通过程序进行文件上传并获取到文件的访问地址
- 帮助文档在Bucket中的右上角通过SDK管理文件–JavaSDK
- 读写权限
-
文件存储方式
-
方式一:用户文件上传,服务端拿到用户的文件流,使用Java代码将文件上传到OSS
但是这种方式不好,文件需要经过用户自己的服务器,还会经过网关,消耗系统性能,用户量大的情况下会带来瓶颈
但是安全,因为账号密码由服务器自己控制
- 让用户直传阿里云服务器需要将账号密码写在js代码中让浏览器直接发送请求给阿里云服务器,但是这种方式不安全,存在账号密码泄露的问题
- 人数一多服务器文件上传非常占用带宽,服务器就无法处理别的请求了
-
方式二:服务端签名后直传
上传前请求应用服务器获取防伪签名令牌,浏览器带着防伪令牌和文件直接访问阿里云服务器
- 用户上传前先向应用服务器请求上传策略、应用服务器使用阿里云的账号密码生成一个防伪签名,签名信息包括用户访问阿里云的授权令牌,文件上传到阿里云的哪个位置等信息,防伪签名中不含账号密码【和https非对称加密原理是一样的,请求由公钥加密,私钥解密;响应由私钥加密,公钥解密;公钥加密的内容公钥无法解密】,保证了服务器使用公钥加密的令牌只能被阿里云服务器的私钥进行解密,阿里云返回的数据即便能被泄露的公钥解密也无伤大雅,因为阿里云服务器已经实现了服务器的认证工作
-
阿里云OSS
文档位置经常变,目前的参考文档路径首页–对象存储–开发参考–SDK参考–Java,且不好找到对应需要的内容,直接在OSS文档界面搜索需要的文档内容
原生文件上传
纯粹的使用Maven工程的JavaWeb程序
-
实现流程
-
在发起签名的服务端的Maven工程中加入依赖项安装OSS Java SDK
<dependency> <groupId>com.aliyun.oss</groupId> <artifactId>aliyun-sdk-oss</artifactId> <version>3.15.1</version> </dependency>Java 9及以上的版本,还需要添加JAXB相关依赖
<dependency> <groupId>javax.xml.bind</groupId> <artifactId>jaxb-api</artifactId> <version>2.3.1</version> </dependency> <dependency> <groupId>javax.activation</groupId> <artifactId>activation</artifactId> <version>1.1.1</version> </dependency> <!-- no more than 2.3.3--> <dependency> <groupId>org.glassfish.jaxb</groupId> <artifactId>jaxb-runtime</artifactId> <version>2.3.3</version> </dependency> -
参考官方文档的上传文件编写文件上传代码
【原生的文件上传代码】
文件上传使用上传文件流的示例代码,这个代码是服务端上传文件流的代码
这个
accessKeyId,accessKeySecret官网为了安全显示一次以后就查不到了,一定要保存好@Test public void testFileUploadOss() throws FileNotFoundException { //EndPoint根据Bucket的实际填写 String endPoint="oss-cn-chengdu.aliyuncs.com"; //操作阿里云的子账户,因为这里填写账号密码很容易丢失,这是避免阿里云账号丢了所以专门弄的一个针对bucket操作的账号密码,丢了可以直接在RAM界面禁用删除重新生成 String accessKeyId="<yourAccessKeyId>"; String accessKeySecret="<yourAccessKeySecret>"; //使用以上三个信息创建对象存储操作的ossClient实例 OSS ossClient = new OSSClientBuilder().build(endPoint, accessKeyId, accessKeySecret); //拿到文件流 FileInputStream inputStream = new FileInputStream("E:\\1.jpg"); //上传文件 //yourBucketName是存储空间的名字即自定义Bucket的名字 //yourObjectName就是上传文件的名字,文件名字要带后缀 //ossClient.putObject("<yourBucketName>","yourObjectName",inputStream) ossClient.putObject("demo2-mall","1.jpg",inputStream); ossClient.shutdown(); System.out.println("上传完成"); } -
点击主账号-AccessKey-用户新建一个子用户,访问方式选择编程访问【通过API和开发工具访问】
创建以后能看到用户列表和对应的accessKeyId和accessKeySecret,默认创建的账户没有任何权限,点击添加权限为用户添加OSS完全访问权限【上传文件需要完全访问权限】,使用这个用户的账号密码给阿里云OSS上传文件
-
alicloud-oss starter
SpringCloud Alibaba整合对象存储,这个starter中整合了各自上传方法,不需要再像原生依赖一样每种上传方式自己写上传代码,只需要导入starter,提供accessKeyId和accessKeySecret以及endPoint调用方法即可实现文件上传
-
实现流程
-
导入alicloud-oss starter
该starter会自动导入原生的aliyun-sdk-oss
</dependencies> <!--对象存储--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alicloud-oss</artifactId> </dependency> </dependencies> <dependencyManagement> <dependencies> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.1.0.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> -
在配置文件中配置OSS服务对应的accessKeyId和accessKeySecret以及endPoint
Spring: cloud: alicloud: access-key: <yourAccessKeyId> secret-key: <yourAccessKeySecret> oss: endpoint: <你的Bucket所在地> -
使用方法
自动注入直接使用
@Autowired private OSSClient ossClient; @Test public void testFileUploadOss() throws FileNotFoundException { //拿到文件流 FileInputStream inputStream = new FileInputStream("E:\\1.jpg"); //上传文件 //ossClient.putObject("<yourBucketName>","yourObjectName",inputStream) ossClient.putObject("demo2-mall","1.jpg",inputStream); //这一步存疑,应该不需要关闭才对 ossClient.shutdown(); System.out.println("上传完成"); }
-
服务端签名直传
服务端不带回调版浏览器直传文件到阿里云OSS服务器,文件流不经过应用服务器;流程为浏览器发送文件前先请求应用服务器拿到服务端颁发的签名,浏览器直接拿着签名和文件请求阿里云服务器
前端文件上传组件和对服务端签名处理的代码见前端–前端常用组件
-
服务端不带回调版流程
-
浏览器上传文件数据前向应用服务端发起请求获取签名
-
官方Java服务端签名代码
@Test protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { //这还是JavaWeb的签名证书代码,实际上SpringBoot直接从配置中心拉取Oss的配置,封装成ossClient自动注入, // 所以从下面到String bucket = "examplebucket";相关代码可以删除 // 从环境变量中获取访问凭证。运行本代码示例之前,请确保已设置环境变量OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET。 EnvironmentVariableCredentialsProvider credentialsProvider = null; try { //这是从环境变量中获取OSS_ACCESS_KEY_ID和OSS_ACCESS_KEY_SECRET的代码 credentialsProvider = CredentialsProviderFactory.newEnvironmentVariableCredentialsProvider(); } catch (ClientException e) { e.printStackTrace(); } // Endpoint以华东1(杭州)为例,其他Region请按实际情况填写。 String endpoint = "oss-cn-hangzhou.aliyuncs.com"; // 填写Bucket名称,例如examplebucket。默认的alicloud oss starter中没有bucket属性,可以自己配置在配置文件中 String bucket = "examplebucket"; // 填写Host名称,格式为https://bucketname.endpoint。 String host = "https://examplebucket.oss-cn-hangzhou.aliyuncs.com"; // 设置上传回调URL,即回调服务器地址,用于处理应用服务器与OSS之间的通信。OSS会在文件上传完成后,把文件上传信息通过此回调URL发送给应用服务器。 // 上传回调暂时不用 String callbackUrl = "https://192.168.0.0:8888"; // 设置上传到OSS文件的前缀,可置空此项。置空后,文件将上传至Bucket的根目录下。一般都设置每一天都产生一个新目录,方便管理 //String dir = "exampledir/"; //使用java8新特性根据日期以2024/2/27/的格式生成目录 String dir = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy/MM/dd")) + "/"; // 创建OSSClient实例。 OSS ossClient = new OSSClientBuilder().build(endpoint, credentialsProvider); try { long expireTime = 30; long expireEndTime = System.currentTimeMillis() + expireTime * 1000; Date expiration = new Date(expireEndTime); // PostObject请求最大可支持的文件大小为5 GB,即CONTENT_LENGTH_RANGE为5*1024*1024*1024。 PolicyConditions policyConds = new PolicyConditions(); policyConds.addConditionItem(PolicyConditions.COND_CONTENT_LENGTH_RANGE, 0, 1048576000); policyConds.addConditionItem(MatchMode.StartWith, PolicyConditions.COND_KEY, dir); String postPolicy = ossClient.generatePostPolicy(expiration, policyConds); byte[] binaryData = postPolicy.getBytes("utf-8"); String accessId = credentialsProvider.getCredentials().getAccessKeyId(); String encodedPolicy = BinaryUtil.toBase64String(binaryData); String postSignature = ossClient.calculatePostSignature(postPolicy); Map<String, String> respMap = new LinkedHashMap<String, String>(); respMap.put("accessid", accessId); respMap.put("policy", encodedPolicy); respMap.put("signature", postSignature); respMap.put("dir", dir); respMap.put("host", host); respMap.put("expire", String.valueOf(expireEndTime / 1000)); // respMap.put("expire", formatISO8601Date(expiration)); /**雷神补充:上面给Map中放了一些属性数据,这些属性统一最后以跨域的方式响应出去, * 由于跨域最后在网关统一解决,设置头信息等,下面这部分代码直接删除 * 自己注:这儿可能是由于跨域的问题没有相应的包,现有的所有JSONObject类都不适配该代码块 * 1. 因为下面是转换签名信息为json格式数据,实际上SpringBoot会自己通过响应数据处理器自动将Map转成json,所以 * JSONObject相关代码可以删除 * 2. 第二个是该代码示例中包含了该服务对跨域问题的处理,在响应头中添加对所有请求的跨域支持,实际上这部分代码已经在 * 网关中通过过滤器解决了,响应也不需要用户再手动处理,直接把Map返回给DispatchServlet即可 */ JSONObject jasonCallback = new JSONObject(); jasonCallback.put("callbackUrl", callbackUrl); jasonCallback.put("callbackBody", "filename=${object}&size=${size}&mimeType=${mimeType}&height=${imageInfo.height}&width=${imageInfo.width}"); jasonCallback.put("callbackBodyType", "application/x-www-form-urlencoded"); String base64CallbackBody = BinaryUtil.toBase64String(jasonCallback.toString().getBytes()); respMap.put("callback", base64CallbackBody); JSONObject ja1 = JSONObject.fromObject(respMap); // System.out.println(ja1.toString()); response.setHeader("Access-Control-Allow-Origin", "*"); response.setHeader("Access-Control-Allow-Methods", "GET, POST"); response(request, response, ja1.toString()); } catch (Exception e) { // Assert.fail(e.getMessage()); System.out.println(e.getMessage()); } finally { ossClient.shutdown(); } } -
SpringBoot服务端签名实例
SpringBoot引入alicloud-oss starter的服务端签名实例
【alicloud-oss starter依赖】
<!--对象存储--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alicloud-oss</artifactId> </dependency>【yml相关配置】
spring: cloud: alicloud: access-key: <yourAccessKeyId> secret-key: <yourAccessKeySecret> bucket: <bucketName> oss: endpoint: <yourEndpoint>【完整签名发布代码】
@RestController @RequestMapping("/oss") public class OssController { /** *注意ossClient注入容器是以接口类型OSS进行注入的,这个组件是通过Oss相关的AutoConfiguration进行配置的 * OssContextAutoConfiguration是OSS的环境配置,ossClient组件的配置在OssContextAutoConfiguration中 * 第一个组件就是以OSS接口类型对ossClient进行配置,所以自动注入的时候,ossClient的类型要写成OSS、 * 不能写成OSSClient,注意OSS中是有OSSClient这个类的,OSSClient是OSS的一种实现类型 * 弹幕说使用@Resource注解不会产生该问题,因为@Resource注解会自动强转,确实有效,原因是@Autowired注解默认是通过类型注入,而@Resource注解默认是通过名字进行注入,@Resource注解会拿着名字去匹配组件的名字 * */ @Resource private OSSClient ossClient; @Value("${spring.cloud.alicloud.oss.endpoint}") private String endpoint; @Value("${spring.cloud.alicloud.access-key}") private String accessId; @Value("${spring.cloud.alicloud.bucket}") private String bucket; @GetMapping("/policy") public Map<String,String> policy(){ // 填写Host名称 String host = "https://"+bucket+"."+endpoint; //使用java8新特性根据日期以2024/2/27/的格式生成目录 String dir = LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy/MM/dd")) + "/"; //封装签名信息 Map<String, String> respMap = new LinkedHashMap<String, String>(); try { long expireTime = 30; long expireEndTime = System.currentTimeMillis() + expireTime * 1000; Date expiration = new Date(expireEndTime); // PostObject请求最大可支持的文件大小为5 GB,即CONTENT_LENGTH_RANGE为5*1024*1024*1024。 // 设置文件上传策略policyConds,包括文件最大大小和文件路径,该策略将和有效时间一起生成postPolicy // postPolicy使用Base64编码后通过ossClient生成客户端签名 PolicyConditions policyConds = new PolicyConditions(); policyConds.addConditionItem(PolicyConditions.COND_CONTENT_LENGTH_RANGE, 0, 1048576000); policyConds.addConditionItem(MatchMode.StartWith, PolicyConditions.COND_KEY, dir); String postPolicy = ossClient.generatePostPolicy(expiration, policyConds); byte[] binaryData = postPolicy.getBytes("utf-8"); String encodedPolicy = BinaryUtil.toBase64String(binaryData); String postSignature = ossClient.calculatePostSignature(postPolicy); //传递给浏览器的内容包括操作Oss的用户ID、编码策略、服务端签名[签名中包含了AccessKeySecret]、文件上传的bucket地址和签名有效时间 //Oss用户的Id respMap.put("accessid", accessId); //编码策略 respMap.put("policy", encodedPolicy); //签名 respMap.put("signature", postSignature); //文件上传目录 respMap.put("dir", dir); //文件上传地址 respMap.put("host", host); //有效期30s respMap.put("expire", String.valueOf(expireEndTime / 1000)); // respMap.put("expire", formatISO8601Date(expiration)); } catch (Exception e) { // Assert.fail(e.getMessage()); System.out.println(e.getMessage()); } finally { ossClient.shutdown(); return respMap; } } }【签名效果】

-
-
短信验证码
阿里云短信验证码服务
-
阿里云云市场提供了很多比如短信发送、物流查询、实名认证查询等等接口,这些接口需要付费使用,阿里云的发送短信验证码服务都是外包的,有很多商家,可以选择合适的自己进行使用,根据产品文档介绍自己抽取组价使用就行了,主要三个方面,一个是抽取组件注入容器按需使用,第二是凡是需要自己配置的参数全部抽取到配置文件进行配置方便管理和修改,第三是短信发送业务使用服务器来进行请求防止暴露身份验证信息导致出现安全问题
-
短信接口阿里云有0元五次的短信接口,正常情况下一条短信大概五分钱一次,测试可以使用该免费服务,购买成功可以在管理控制台看到对应的商品信息,购买界面下方有接口使用方法介绍,选择短信验证码接口
-
这里使用的接口调用地址【GET】
http,通过APPCODE的方式进行调用者的身份权限验证APPCODE在我们管理控制台购买的服务中可以看到对应的AppCode,发起请求时需要携带该AppCode- 在请求中
AppCode会在请求头信息中的Authorization字段中指定,格式为APPCODE+半角空格+APPCODE值,不添加该请求头信息请求会报错401 - 这种方式意味着直接通过用户客户端发起短信请求不安全,因为用户可以获取到我们的
APPCODE,高频发起请求对我们的短信服务造成金钱攻击,一般的做法是用户向我们的服务器发起请求,我们生成一个随机验证码并通过服务器向短信接口发起请求向用户手机发起指定验证码
-
请求时需要在请求参数中携带以下四个String类型的参数
- GET请求请求参数直接拼接在请求路径后面
名称 描述 是否必须 code 要发送的验证码 必选 phone 接收人的手机号 必选 sign 签名编号
签名是短信抬头括号中的内容,一般用来标记短信的发送者
签名如果默认的编号1对应的签名为消息秘书
这个自定义签名需要添加客服来申请编号和自定义签名的对应关系才能使用自定义签名可选 skin 短信模板编号
短信模板是短信服务提供商提供的一系列短信模板
可以通过skin顺序整数编号来指定用户希望使用的模板可选 -
短信接口的Java代码示例购买界面的文档中也有
- 可能需要一些短信服务商的工具类比如
HttpUtils来处理请求参数需要到指定地址下载并拷贝到自己的项目中 - 需要引入的依赖文档中也有
- 可能需要一些短信服务商的工具类比如
-
配置
SpringBoot配置
服务基础配置
-
服务端口配置
Server: port: 7000 -
服务名配置
spring.application.name = mall-search
全局异常处理
@ControllerAdvice
-
@ControllerAdvice简介-
@ControllerAdvice标注的类本质上是一个Component,该注解定义上标注了``@Component`注解 -
该注解标注的类的作用是为注解中
basePackages属性指定的包下所有Controller提供使用注解@ExceptionHandler、@InitBinder或@ModelAttribute标注的方法如使用
@ExceptionHandler注解对控制器方法中抛出的指定异常进行全局处理,就是aop思想的一种实现,用户通过这个注解标注的类指定拦截规则,执行过程抛出对应异常自动拦下来,具体用户的拦截异常筛选和拦截之后的处理,用户通过@ExceptionHandler、@InitBinder或@ModelAttribute这三个注解以及被其标注的方法来自定义 -
@ControllerAdvice指定Controller的范围- 默认
@ControllerAdvice注解什么都不写,则默认适用于全体的Controller - 指定
@ControllerAdvice注解的value属性,比如写成@ControllerAdvice("org.my.pkg")意思是适用于org.my.pkg包及其子包下的所有Controller,写成@ControllerAdvice(basePackages={"org.my.pkg", "org.my.other.pkg"})的形式是以数组的形式指定多个包下的Controller,basePackages属性是value属性的别名; annotations属性是匹配标注了指定注解的Controller,@ControllerAdvice(annotations={CustomAnnotation.class})是匹配所有被这个注解@CustomAnnotation修饰的Controller,属性值可以为数组,同时还可以是自定义注解
- 默认
-
-
@ControllerAdvice实现全局异常处理@ControllerAdvice标注的类中配置@ExceptionHandler标注的方法实现对控制器方法指定异常进行全局处理-
@ExceptionHandler注解的value属性是Throwable的子类数组,Throwable是所有异常的父类,即通过指定异常类数组来指明方法对应处理的被控制器抛出的指定异常类 -
@ExceptionHandler注解标注的对全局异常处理的返回值应该是ModelAndView,这个返回值和控制器方法的返回值的用法是一样的,也可以封装自定义的响应数据格式如R,如果该方法要返回json格式的数据需要像控制器方法一样给该方法标注@ResponseBody注解,该注解可以被移到定义该方法的被@ControllerAdvice注解标注的类上,此时又有一个@RestControllerAdvice注解是@ControllerAdvice注解和@ResponseBody注解的合体 -
实例:
这个异常信息处理很粗糙,按需要自己写异常处理
@Slf4j //@ResponseBody //@ControllerAdvice(basePackages = "com.earl.mall.product.controller") @RestControllerAdvice(basePackages = "com.earl.mall.product.controller") public class MallControllerExceptionHandler { @ExceptionHandler(Exception.class) public R handleValidException(Exception e){ log.error("数据校验错误:{},异常类型:{}",e.getMessage(),e.getClass()); return R.error(); } }
-
预设全局数据
@ControllerAdvice
-
@ControllerAdvice标注的类中配置@ModelAttribute标注的方法实现预设全局数据【就是在model中放数据,在指定的控制器方法中可以拿出来】@ModelAttribute的作用是绑定一些变量到被@ModelAttribute标注的方法的返回值或者方法参数列表中的Model类型参数中供被指定的Controller中注有@RequestMapping的方法进行使用,类似与@GetMapping这种注解都被@RequestMapping注解标注了@ModelAttribute的value属性是指定当被标注方法有返回值时返回值的key,没有指定时以返回值的变量名作为key
-
全局参数绑定
-
方式一
向被
@ModelAttribute注解标注的方法的参数列表中的model中使用addAttribute方法添加键值对,可以添加多个键值对@ControllerAdvice public class MyGlobalHandler { @ModelAttribute public void presetParam(Model model){ model.addAttribute("globalAttr","this is a global attribute"); } } -
方式二
被
@ModelAttribute注解标注的方法返回一个Map,Map中存放键值对当
@ModelAttribute不传任何参数时会以返回值的变量名作为Map的key,如果value有值就使用该值作为Map的key,这个value作为map的名字我没看懂,从全局参数的使用上来说完全没有看到Map参数名需要使用的影子@ControllerAdvice public class MyGlobalHandler { @ModelAttribute() public Map<String, String> presetParam(){ Map<String, String> map = new HashMap<String, String>(); map.put("key1", "value1"); map.put("key2", "value2"); map.put("key3", "value3"); return map; } }
-
-
全局参数的使用
-
实例
@RestController public class AdviceController { @GetMapping("methodOne") public String methodOne(Model model){ Map<String, Object> modelMap = model.asMap(); return (String)modelMap.get("globalAttr"); } @GetMapping("methodTwo") public String methodTwo(@ModelAttribute("globalAttr") String globalAttr){ return globalAttr; } @GetMapping("methodThree") public String methodThree(ModelMap modelMap) { return (String) modelMap.get("globalAttr"); } }
-
请求参数预处理
@ControllerAdvice
@ControllerAdvice标注的类中配置@InitBinder标注的方法实现请求参数的预处理
//TODO 此处@ControllerAdvice下的内容需要整理
-
@IniiBinder源码/** * Annotation that identifies methods which initialize the * {@link org.springframework.web.bind.WebDataBinder} which * will be used for populating command and form object arguments * of annotated handler methods. * 粗略翻译:此注解用于标记那些 (初始化[用于组装命令和表单对象参数的]WebDataBinder)的方法。 * 原谅我的英语水平,翻译起来太拗口了,从句太多就用‘()、[]’分割一下便于阅读 * * Init-binder methods must not have a return value; they are usually * declared as {@code void}. * 粗略翻译:初始化绑定的方法禁止有返回值,他们通常声明为 'void' * * <p>Typical arguments are {@link org.springframework.web.bind.WebDataBinder} * in combination with {@link org.springframework.web.context.request.WebRequest} * or {@link java.util.Locale}, allowing to register context-specific editors. * 粗略翻译:典型的参数是`WebDataBinder`,结合`WebRequest`或`Locale`使用,允许注册特定于上下文的编辑 * 器。 * * 总结如下: * 1. @InitBinder 标识的方法的参数通常是 WebDataBinder。 * 2. @InitBinder 标识的方法,可以对 WebDataBinder 进行初始化。WebDataBinder 是 DataBinder 的一 * 个子类,用于完成由表单字段到 JavaBean 属性的绑定。 * 3. @InitBinder 标识的方法不能有返回值,必须声明为void。 */ @Target({ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface InitBinder { /** * The names of command/form attributes and/or request parameters * that this init-binder method is supposed to apply to. * <p>Default is to apply to all command/form attributes and all request parameters * processed by the annotated handler class. Specifying model attribute names or * request parameter names here restricts the init-binder method to those specific * attributes/parameters, with different init-binder methods typically applying to * different groups of attributes or parameters. * 粗略翻译:此init-binder方法应该应用于的命令/表单属性和/或请求参数的名称。默认是应用于所有命 * 令/表单属性和所有由带注释的处理类处理的请求参数。这里指定模型属性名或请求参数名将init-binder * 方法限制为那些特定的属性/参数,不同的init-binder方法通常应用于不同的属性或参数组。 * 我至己都理解不太理解这说的是啥呀,我们还是看例子吧 */ String[] value() default {}; }我们来看看具体用途,其实这些用途在
Controller里也可以定义,但是作用范围就只限当前Controller,因此下面的例子我们将结合ControllerAdvice作全局处理。 -
参数处理
@ControllerAdvice public class MyGlobalHandler { @InitBinder public void processParam(WebDataBinder dataBinder){ /* * 创建一个字符串微调编辑器 * 参数{boolean emptyAsNull}: 是否把空字符串("")视为 null */ StringTrimmerEditor trimmerEditor = new StringTrimmerEditor(true); /* * 注册自定义编辑器 * 接受两个参数{Class<?> requiredType, PropertyEditor propertyEditor} * requiredType:所需处理的类型 * propertyEditor:属性编辑器,StringTrimmerEditor就是 propertyEditor的一个子类 */ dataBinder.registerCustomEditor(String.class, trimmerEditor); //同上,这里就不再一步一步讲解了 binder.registerCustomEditor(Date.class, new CustomDateEditor(new SimpleDateFormat("yyyy-MM-dd"), false)); } }这样之后呢,就可以实现全局的实现对
Controller中RequestMapping标识的方法中的所有String和Date类型的参数都会被作相应的处理。【Controller】
@RestController public class BinderTestController { @GetMapping("processParam") public Map<String, Object> test(String str, Date date) throws Exception { Map<String, Object> map = new HashMap<String, Object>(); map.put("str", str); map.put("data", date); return map; } }从Map的响应结果可以看出,
str和date这两个参数在进入Controller的test的方法之前已经被处理了,str被去掉了两边的空格(%20在Http url 中是空格的意思),String类型的1997-1-10被转换成了Date类型。 -
参数绑定
参数绑定可以解决特定问题,那么我们先来看看我们面临的问题
class Person { private String name; private Integer age; // omitted getters and setters. } class Book { private String name; private Double price; // omitted getters and setters. } @RestController public class BinderTestController { @PostMapping("bindParam") public void test(Person person, Book book) throws Exception { System.out.println(person); System.out.println(book); } }我们会发现
Person类和Book类都有name属性,那么这个时候就会出先问题,它可没有那么智能区分哪个name是哪个类的。因此@InitBinder就派上用场了:@ControllerAdvice public class MyGlobalHandler { /* * @InitBinder("person") 对应找到@RequstMapping标识的方法参数中 * 找参数名为person的参数。 * 在进行参数绑定的时候,以‘p.’开头的都绑定到名为person的参数中。 */ @InitBinder("person") public void BindPerson(WebDataBinder dataBinder){ dataBinder.setFieldDefaultPrefix("p."); } @InitBinder("book") public void BindBook(WebDataBinder dataBinder){ dataBinder.setFieldDefaultPrefix("b."); } }因此,传入的同名信息就能对应绑定到相应的实体类中:
p.name -> Person.name b.name -> Book.name
还有一点注意的是如果 @InitBinder(“value”) 中的 value 值和 Controller 中 @RequestMapping() 标识的方法的参数名不匹配,则就会产生绑定失败的后果,如:
@InitBinder(“p”)、@InitBinder(“b”)
public void test(Person person, Book book)
上述情况就会出现绑定失败,有两种解决办法
第一中:统一名称,要么全叫p,要么全叫person,只要相同就行。
第二种:方法参数加 @ModelAttribute,有点类似@RequestParam
@InitBinder(“p”)、@InitBinder(“b”)
public void test(@ModelAttribute(“p”) Person person, @ModelAttribute(“b”) Book book)
日期格式
-
配置SpringBoot接口响应json字符串将日期转化为指定格式
-
yml配置
时区不对的,数据连接时加上时区就行了;
url: jdbc://localhost:3306/databasename?useSSL=false&serverTimezone=Asia/Shanghai【这是决定插入数据库转换成对应时区的时间】或者配置
jackson time-zone: GMT+8设置时区,经过测试两个同时配置不会出问题Spring: jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8
-
配置多例
- 在保证多例模式下的并发线程安全的前提下,使用多例模式只需要简单更改配置就能实现系统并发性能的快速提升【比如方法中对数据库的所有操作只使用一条SQL】
- 但是对于无法保证多例模式并发线程安全问题的情况如使用JVM本地锁切换多例模式就可能导致并发线程安全问题
- 配置IoC容器组件为多例模式
- SpringBoot中的service等IoC组件一般默认都是单例的,通过在组件类名上添加注解
@Scope(value="prototype",proxyMode=ScopedProxyMode.TARGET_CLASS)能够将组件从单例模式改成多例模式 - 默认该注解
@Scope的value属性值是单例即singleton,但是单独将value属性设置为prototype是无法将组件设置为多例模式的,还需要配置proxyMode属性,proxyMode属性的默认值是ScopedProxyMode.DEFAULT,是枚举类ScopedProxyMode中的一个枚举值DEFAULT,等价于同一个枚举类ScopedProxyMode中的另一个枚举值NO,相当于默认情况下没有指定代理模式,该枚举类下还有两个枚举值INTERFACES和TARGET_CLASS,如果想使用JDK代理【基于接口的代理】需要将@Value注解的proxyMode属性设置为ScopedProxyMode.INTERFACES,如果想使用CGLIB代理【基于类的代理】需要将@Value注解的proxyMode属性设置为ScopedProxyMode.TARGET_CLASS- 🔎:原生的Spring默认是JDK代理,这种代理方式使用Service一般要先定义Service接口再写对应的实现类,在SpringBoot2.x以后默认使用的是CGLib代理,所以使用Service一般不用写接口直接写实现类即可,但是注意,如果没有写Service接口,切换使用Service组件多例模式时就只能指定
@Value注解的proxyMode属性为ScopedProxyMode.TARGET_CLASS,否则需要补充对应Service组件的接口
- 🔎:原生的Spring默认是JDK代理,这种代理方式使用Service一般要先定义Service接口再写对应的实现类,在SpringBoot2.x以后默认使用的是CGLib代理,所以使用Service一般不用写接口直接写实现类即可,但是注意,如果没有写Service接口,切换使用Service组件多例模式时就只能指定
- SpringBoot中的service等IoC组件一般默认都是单例的,通过在组件类名上添加注解
单体事务
- 通过在方法上添加
@Transactional注解来控制单体服务同一个方法下对数据库的组合操作的原子性,提交成功则全部多个对数据库操作同时提交成功,失败则全部提交失败- 事务注解
@Transactional是通过AOP的思想来实现事务控制的,在方法之前开启事务,在方法之后提交事务或者回滚事物,这种方式在使用JVM本地锁的情况下可能会发生线程安全问题,详见分布式锁–Synchronized解决方案优缺点分析
- 事务注解
- 事务指定隔离级别
- 通过注解
@Transactional(isolation=Isolation.READ_UNCOMMITTED)指定数据库的事务隔离级别为读未提交,默认隔离级别是Isolation.DEFAULT即数据库的实际隔离级别,使用读未提交能够解决@Transactional注解使用JVM本地锁导致的多线程并发线程安全问题,因为JVM本地锁锁不住AOP方式实现的开始事务和提交事务,在不发生事务回滚的情况下读未提交确实能解决JVM本地锁失效的问题,但是在涉及支付等场景下不能为了解决线程安全问题就把数据库的隔离级别改成读未提交,一旦回滚就要爆炸,其他线程可能已经拿着回滚前的数据一泻千里了
- 通过注解
视图映射
-
视图映射配置
- 我们可以通过配置
WebMvcConfigurer的子实现配置类,通过重写addViewControllers(ViewControllerRegistry registry)方法,在该方法中通过多次调用registry.addViewController(String urlPath).setViewName(String viewName)来一次性设置多个视图路径映射关系,这样可以避免在控制器中写一堆只负责请求路径页面跳转的空方法- 默认使用的都是GET请求的方式来处理视图映射
- 以下配置了URI
/login.html对视图template/login.html,/registry.html对视图template/registry.html的映射
/** * @author Earl * @version 1.0.0 * @描述 认证服务自定义视图映射器 * 默认使用的都是GET请求的方式来处理视图映射 * @创建日期 2024/10/01 * @since 1.0.0 */ @Configuration public class CustomWebMvcConfigurer implements WebMvcConfigurer { @Override public void addViewControllers(ViewControllerRegistry registry) { registry.addViewController("/login.html").setViewName("login"); registry.addViewController("/registry.html").setViewName("registry"); } } - 我们可以通过配置
功能专题
定时任务调度
基于Timer
- 基于JDK的
java.util.Timer的定时任务实现- 🔎:从JDK1.3起就有一个
java.util.Timer类来实现延时、定时执行任务的功能;Timer的优点是简单易用,但是致命缺点是所有的任务都是被同一个线程执行的,同一时间只能有一个任务执行,剩下任务都得等,执行过程中如果有一个任务发生延迟或者异常都会影响后续其他任务的执行,异常甚至会导致后续任务作废,适合任务数不确定的短时定时任务、定时任务需要单独控制的场景比如分布式锁的有效时间续期,早期的Redisson框架就是基于Timer做的定时锁过期时间重置,随着版本更新也换成了netty的的时间轮实现io.netty.util.HashedWheelTimer
- 🔎:从JDK1.3起就有一个
-
java.util.Timer的使用-
void--->timer.schedule(TimerTask task, long delay, long period)-
功能解析:定义在定时任务线程创建以后在
delay毫秒以后开始间隔period时间执行一次的定时任务,task是任务对象,TimeTask是抽象类,需要实现抽象run方法;delay是相对于定时调度线程启动时的初始延迟时间,单位是毫秒,period是两次执行的间隔时间,单位是毫秒 -
使用示例:
/** * Thread[main,5,main]| 定时任务初始时间:172418119 1863 * Thread[Timer-0,5,main]| 定时任务执行时间:17241811 96874 * Thread[Timer-0,5,main]| 定时任务执行时间:17241812 06887 * Thread[Timer-0,5,main]| 定时任务执行时间:17241812 16889 * Thread[Timer-0,5,main]| 定时任务执行时间:17241812 26904 * */ public static void main(String[] args) { System.out.println(Thread.currentThread()+"| 定时任务初始时间:"+System.currentTimeMillis()); new Timer().schedule(new TimerTask() { @Override public void run() { System.out.println(Thread.currentThread()+"| 定时任务执行时间:"+System.currentTimeMillis()); } },5000,10000); }- 示例含义:定时线程启动后初始延时5秒钟开始每隔十秒打印定时任务执行时间
-
补充说明:
- 🔎:
TimerTask实现了Runnable接口,是一个抽象类,实例化对象需要实现其中的抽象run方法
- 🔎:
-
-
void--->schedule(TimerTask task, long delay)-
功能解析:定义在定时任务线程创建以后在
delay毫秒以后开始只执行一次的定时任务,task是任务对象,TimeTask是抽象类,需要实现抽象run方法;delay是相对于定时调度线程启动时的初始延迟时间,单位是毫秒,执行完一次定时任务线程就会销毁 -
使用示例:
public class DistributedRedisLock implements Lock { private StringRedisTemplate redisTemplate; private String lockName; private String hSetField; private long expire = 30; public DistributedRedisLock(StringRedisTemplate redisTemplate, String lockName, String uuid) { this.redisTemplate = redisTemplate; this.lockName = lockName; this.hSetField = uuid + ":" + Thread.currentThread().getId(); } @Override public void lock() { this.tryLock(); } @Override public void lockInterruptibly() throws InterruptedException { } //无参tryLock方法是使用默认有效时间30s作为锁的有效时间 @Override public boolean tryLock() { try { return this.tryLock(-1L, TimeUnit.SECONDS); } catch (InterruptedException e) { e.printStackTrace(); } return false; } /** * 加锁方法 * @param time * @param unit * @return * @throws InterruptedException */ @Override public boolean tryLock(long time, TimeUnit unit) throws InterruptedException { if (time != -1){ this.expire = unit.toSeconds(time); } String script = "if redis.call('exists', KEYS[1]) == 0 or redis.call('hexists', KEYS[1], ARGV[1]) == 1 " + "then " + " redis.call('hincrby', KEYS[1], ARGV[1], 1) " + " redis.call('expire', KEYS[1], ARGV[2]) " + " return 1 " + "else " + " return 0 " + "end"; while (!this.redisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Arrays.asList(lockName), hSetField, String.valueOf(expire))){ Thread.sleep(50); } // 加锁成功,返回之前,开启定时器自动续期 this.renewExpire(); return true; } /** * 解锁方法 */ @Override public void unlock() { String script = "if redis.call('hexists', KEYS[1], ARGV[1]) == 0 " + "then " + " return nil " + "elseif redis.call('hincrby', KEYS[1], ARGV[1], -1) == 0 " + "then " + " return redis.call('del', KEYS[1]) " + "else " + " return 0 " + "end"; Long flag = this.redisTemplate.execute(new DefaultRedisScript<>(script, Long.class), Arrays.asList(lockName), hSetField); if (flag == null){ throw new IllegalMonitorStateException("this lock doesn't belong to you!"); } } @Override public Condition newCondition() { return null; } //上锁以后延迟1/3锁有效时间去定时执行续期脚本;注意execute方法会自动将lua的返回值1转成true,将返回值0返回false,注意nil也会转成false;如果需要区分nil需要使用Long类型的返回值,对应nil转成null; //定时任务采用延时执行一次任务,执行完以后线程就销毁,如果续期成功再次执行该任务,续期失败说明锁已经不是当前线程的锁了,不再进行续期操作;如果不这么写就需要去解锁成功以后取消定时任务,需要考虑各种意外情况导致定时线程无法被取消导致的死锁的情况,实现起来比较复杂,但是这种实现在分布式锁比较多的情况下会占用很多的线程资源 //这里更改此前的getId方法是因为定时续期的execute方法也需要获取field字段,但是不能使用getId中的逻辑,因为定时任务需要开新的定时任务线程,但是field字段需要业务线程的线程id,因此这里只是改进将getId的逻辑放到了获取锁时的实例化锁对象的构造方法中,实际上锁重入只是key和Field字段相同,实际上锁重入并不是同一个DistributedRedisLock对象 private void renewExpire(){ String script = "if redis.call('hexists', KEYS[1], ARGV[1]) == 1 " + "then " + " return redis.call('expire', KEYS[1], ARGV[2]) " + "else " + " return 0 " + "end"; new Timer().schedule(new TimerTask() { @Override public void run() { if (redisTemplate.execute(new DefaultRedisScript<>(script, Boolean.class), Arrays.asList(lockName), hSetField, String.valueOf(expire))) { renewExpire(); } } }, this.expire * 1000 / 3); } }- 示例含义:
DistributedRedisLock是基于Redis+java.util.Timer+lua脚本来实现自动续期的可重入分布式锁实现,其中的renewExpire()方法就是使用Timer实现分布式锁自动续期的业务逻辑代码,这里面的又上一个续期任务执行成功唤醒下一个定时续期任务的思想值得借鉴,这样可以避免出现意外导致定时任务停不下来
- 示例含义:
-
补充说明:
- 🔎:该方法一般用在控制定时任务线程需要满足一定条件才能继续执行避免定时任务因为意外情况无法自动停止的场景,比如分布式锁的自动续期
-
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









