







问题定义
kCP(k-core pattern):对于给定的core pattern上进行频繁子图挖掘,获得基于该模式扩展出的topK的频繁子图。
与传统的基于支持度域值的贫乏子图挖掘略有不同,这里需要的时支持度最大的k个模式。
本文采用的支持度为MNI,下文中支持度默认是MNI。
简要流程
用min堆对topk的模式进行存储。每个新的模式只需要与堆顶元素(最小值)进行比较,大于堆顶的元素则可以进行pop 堆顶,插入新的模式。
在计算支持度时,由于需要获得topk ,所以需要采用精确计算。对于新产生的模式,根据支持度的先验规则,其支持度比然小于等与其父模式。所以对于每个候选子图,根据其父模式可以给出其支持度的上限,如果小于堆顶元素,则无需进行下一步计算。
本文是基于GRAMI进行改进的,关于GRAMI的部分不再赘述。
主要创新 基于join的子图同构求解
将每条边时为一个表(table,数据库中的概念),模式中每新加一条边,则等价与进行一次join。
下图给出计算模式P支持度时进行的join。首先进行SC边和CV进行join,得到SCV,SCV再和VS进行join,得到最终的结果。
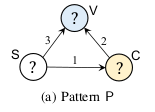
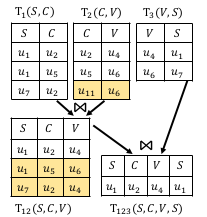
但直接进行join,会出现大量冗余,最终的结果的行数远大于MNI值。为解决该问题,提出一种两步的join。
首先对每条边对应的表进行“缩表”。一条边e上有两个顶点A、B,e对应的边表为T,选择支持度较小的,假设为A,对应的支持度为a(a<b)。从T中找出a行,每行中的A是不同的,sql表示如下:
select DISTINCT A as T1 from T
此时,T1有a行,每行中的A是不同的。再将B填入表T1中,使得B的支持度也达到a。sql如下:
select DiSTINCT B as T2 from T where T.A not in T1;#
insert into T1 select * from T2 where {select count DISTINCT from T1.B}<a; # 将结果合并
通过以上缩表操作,得到新的表T1,该表中A和B的支持度都为a,且行数最多为2*a行。这样不但保留了支持度的信息,也减少了行数。
所有边都进行以上缩表。然后进行连接,计算模式的支持度,获得模式支持度的下限。
第二步是向上一步的结果中添加值,得到最终的支持度。确保表T中的每行都被检查或添加到T1中。















 738
738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









