







 1、准备工作阿里云服务器或者Linux 虚拟机 (至少8G内存,作者使用的是 阿里云CentOS 8.2 64位2 核 8 GiB) Windows 环境下 装了IDEA的电脑 Linux 安装了 java8 环境 阿里云开放了可能用到的端口安全组策略2、配置服务2.1 logback 整合 Flume创建 Springboot WEB 项目引入下列依赖, Springboot start Web 省略 <dependencies> ...
1、准备工作阿里云服务器或者Linux 虚拟机 (至少8G内存,作者使用的是 阿里云CentOS 8.2 64位2 核 8 GiB) Windows 环境下 装了IDEA的电脑 Linux 安装了 java8 环境 阿里云开放了可能用到的端口安全组策略2、配置服务2.1 logback 整合 Flume创建 Springboot WEB 项目引入下列依赖, Springboot start Web 省略 <dependencies> ...
前言:
我就是一个小白,学spark过程中,遇到很多坑,写个博客记录下来,如果有初学的同学,可以按照我的思路实现一遍。
然后再按照自己需求,进行改造。
1、准备工作
- 阿里云服务器或者Linux 虚拟机 (至少8G内存,作者使用的是 阿里云 CentOS 8.2 64位 2 核 8 GiB)
- Windows 环境下 装了IDEA的电脑
- Linux 安装了 java8 环境
- 阿里云开放了可能用到的端口安全组策略
2、配置服务
2.1 logback 整合 Flume
创建 Springboot WEB 项目
引入下列依赖, Springboot start Web 省略
<dependencies>
<dependency>
<groupId>com.teambytes.logback</groupId>
<artifactId>logback-flume-appender_2.11</artifactId>
<version>0.0.9</version>
</dependency>
<!-- https://mvnrepository.com/artifact/ch.qos.logback/logback-classic -->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
</dependency>
</dependencies>配置 logback.xml , 替换 阿里云公网IP ,4141 端口可替换, 要与 flume 监听的一致
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<!-- encoders are by default assigned the type
ch.qos.logback.classic.encoder.PatternLayoutEncoder -->
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<appender name="flumeTest" class="com.teambytes.logback.flume.FlumeLogstashV1Appender">
<flumeAgents>
阿里云公网IP:4141
</flumeAgents>
<flumeProperties>
connect-timeout=4000;
request-timeout=8000
</flumeProperties>
<batchSize>100</batchSize>
<reportingWindow>1000</reportingWindow>
<additionalAvroHeaders>
myHeader = myValue
</additionalAvroHeaders>
<application>Gloria's Application</application>
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>%d{yyyy-MM-dd} %d{HH:mm:ss} %msg%n</pattern>
</layout>
</appender>
<root level="WARN">
</root>
<logger name="FlumeLogger" level="INFO" addtivity="false">
<appender-ref ref="flumeTest"/>
</logger>
</configuration>创建业务 controller 调用 logger
package com.gloria.Logger;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.*;
@Controller
public class LoggerController {
public static Logger logger = LoggerFactory.getLogger(LoggerController.class);
@ResponseBody
@RequestMapping(value = "/api/Logger", method = RequestMethod.GET)
public String apiLogger(LoggerEntity entity) {
//打印行为日志内容并被flume采集到kafka上
logger.info(entity.toString());
return "succ";
}
}
}
创建行为日志实体类
package com.gloria.Logger;
import org.apache.commons.lang3.StringUtils;
import org.hibernate.validator.constraints.NotBlank;
public class LoggerEntity {
/*
省略 get/set ,tostring ,构造方法
*/
int accessType = 0; // 访问类型 0是点击 1是搜索
String userId = ""; // 用户主键
String bussinessId = ""; // 点击商品的业务外键
String bussinessType = ""; // 业务类型
String networkType = ""; // 网络类型
String latitude = "";// 纬度
String longitude = "";// 经度
String city = ""; // 登录城市
String gender = ""; // 性别
String visitTime = ""; // 浏览时间
String searchContent = ""; // 搜索内容
}
2.2 Flume 采集框架
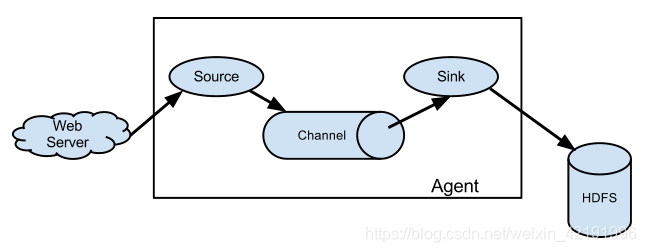
Flume 可以通过配置,从多种数据源中采集日志,如:
- 监听某个文件夹下所有的文件,产生新的就采集
- 监听某个网络端口
- 执行 tail -f 命令,采集输出信息
通过多种通道(保证采集过程数据可靠性),如:
- 在内存中 memory-channel
- 在数据库中 JDBC-channel
- 在文件中 File-channel
采集到多种数据平台,如:
- HDFS(Hadoop生态圈)
- Mysql (采集到数据库)
- Kafka (采集到中间件)
对于分析用户行为日志来说,我们可以直接向Kafka 推送数据,为什么需要Flume采集呢?
下面简单解释一下为什么不建议直接将业务日志直接推到kafka,我们说flume是kafka的producer,那么写过java实现producer的就会知道,我们需要在程序中设置埋点,从而出发send操作将埋点数据发送到指定的topic,如果在业务系统中有很多日志产生的地方,这样做就不太合适,每个部分都要设置个producer。那么相对来说,flume就方便很多,只需要填入相关的配置,指定对于的文件夹就能完成日志的收集,你可以把flume臆想为封装了一系列的操作。至于为什么会出现flume、Scribe等日志收集系统,可以自行查找并对比各个工具之间的优劣。
2.2.1 下载并解压Flume

(1)可以直接点击链接进行下载,然后传给linux 服务器 , http://www.apache.org/dyn/closer.lua/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
(2)也可以使用命令,个人习惯放在 /opt 目录下, (PS:推荐使用这种方式,很快)
# 安装在 /opt 目录下 并解压
cd /opt
wget https://mirror.bit.edu.cn/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
tar -xzvf apache-flume-1.9.0-bin.tar.gz 2.2.2 配置 Flume
- 修改配置文件, 指定 source 为 avro , chanel 为 memory , sink 为 kafka ,命名的配置文件
cd /opt/apache-flume-1.9.0-bin/conf vim test-avro-memory-kafka.conf - 配置文件内容 source: 监听本地4141端口,与logback中配置的需要对应一致 chanel : 不设置持久化,在内存中传递 sink: Kafka 采集到消息中间件上
avro-memory-kafka.sources = avro-source avro-memory-kafka.sinks = kafka-sink avro-memory-kafka.channels = memory-channel avro-memory-kafka.sources.avro-source.type = avro avro-memory-kafka.sources.avro-source.bind= 0.0.0.0 avro-memory-kafka.sources.avro-source.port= 4141 avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink avro-memory-kafka.sinks.kafka-sink.kafka.bootstrap.servers = 0.0.0.0:9092 avro-memory-kafka.sinks.kafka-sink.kafka.topic
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









