






第一篇:personlized federated learning for intelligent IoT application: a cloud-edge based framework
- 摘要
论文要解决的问题:IoT环境中的异构性问题
解决方法:提出了个性化联邦学习方法,来缓解异构性带来的消极影响 - 背景介绍
联邦学习所面临的3种异构性挑战
- 设备异构性:不同的设备具有不同的存储、计算和通信能力
- 统计异构性:数据的non-IID性质
- 模型异构性:不同的设备想要制定自己的模型来适应它们的应用环境
传统联邦学习vs 个性化联邦学习
| 传统联邦学习 | 个性化联邦学习 | |
|---|---|---|
| 目标 | 训练一个高质量的全局模型 | 捕捉每台设备的个性化信息 |
| 性能 | 在单个客户端上性能较差 | 提高了各个客户端的性能 |
目前比较流行的几种实现个性化联邦学习的方法
- 联邦迁移学习
- 联邦多任务学习
- 联邦蒸馏
- 作者提出的方法: PerFit
采用边缘计算解决通信和算力成本–>cloud-edge框架
实现个性化: 在对全局模型进行训练后, 在设备端采用不同类型的个性化联邦学习方法,针对不同设备的不同需求实现个性化模型部署。具体实现方法:联邦迁移学习、联邦精馏
个性个性化联邦学习框架-智能IoT应用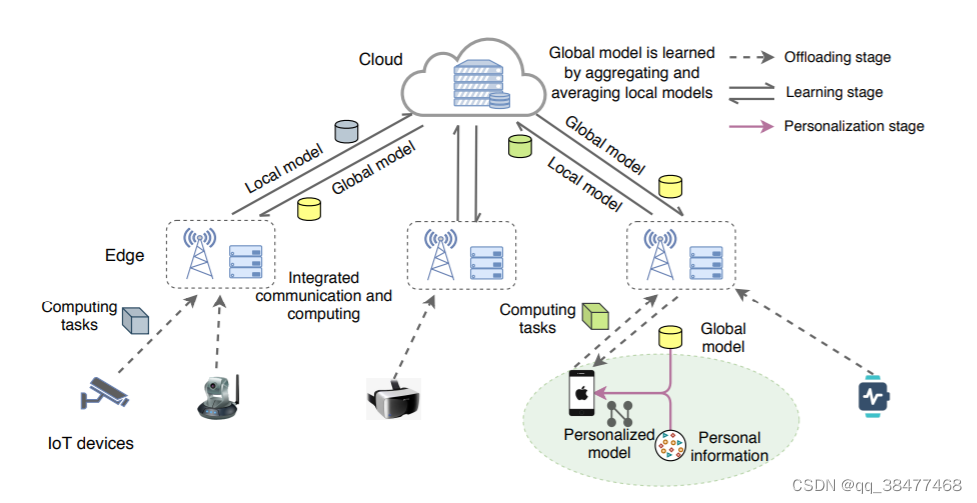
联邦迁移学习
有两种主要的方法来实现个性化
1)首先通过传统联邦学习训练全局模型, 然后将全局模型迁移到每个设备,并且本地设备可以利用自己数据已经结合全局模型来fun-tuning 本地模型。为了减少训练开销,仅需要微调深层参数(学习到更具体的特征), 浅层参数(共同的和低水平特征)则直接使用全局模型的参数 。如下图a所示:
参考文献:联邦迁移学习
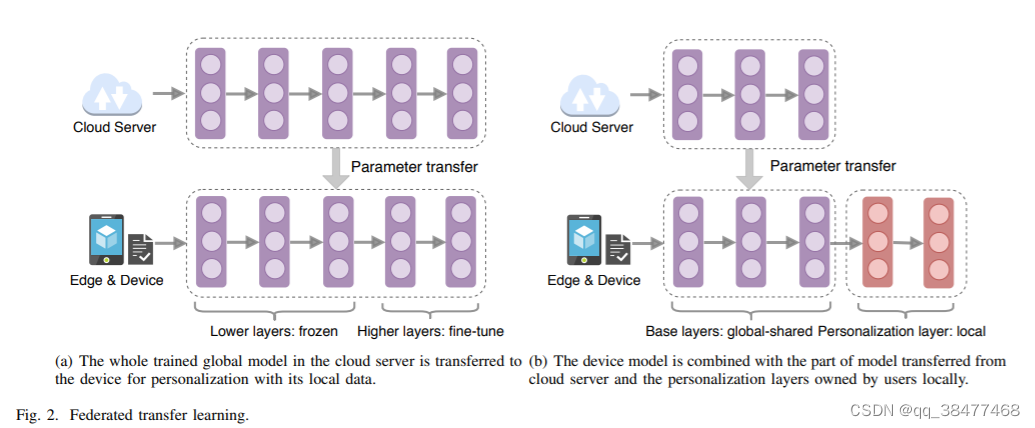
- base layer + personalization layer 如上图b所示, 可参考文献Federated Learning with Personalization Layers
base lyer: global-shared
personalization layer: local
联邦知识蒸馏
知识蒸馏可用于减少分布式的联邦学习训练时所占用的带宽,它在联邦学习的各个阶段,通过减少部分参数或者样本的传输方式实现成本压缩。
联邦元学习
可以解决统计异构问题, 比如non-IID 和数据不平衡。联邦多任务学习旨在同时学习不同设备的不同任务,并试图在不存在隐私风险的情况下捕获它们之间的模型关系。通过模型关系,每个设备的模型可以获取其他设备的信息。此外,为每个设备学习的模型总是个性化的。
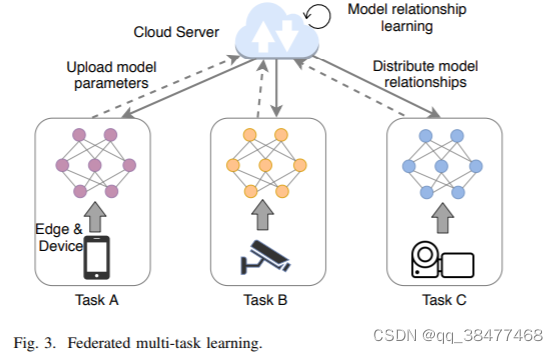
联邦多任务学习
联邦多任务学习旨在同时学习不同设备的不同任务,并试图在不存在隐私风险的情况下捕获它们之间的模型关系。通过模型关系,每个设备的模型可以获取其他设备的信息。此外,每个设备学习的模型总是个性化的。
- 总结
这篇文章采用了cloud-edge 框架,将一些计算成本较高的任务放在了边缘设备上,前提时假设边缘设备时安全可靠的。同时,作者采用了联邦迁移学习以及联邦蒸馏的方法来实现个性化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









