







读paper的目的:
自己在使用DDPG解决问题时,会遇到action space很大的情况,会导致算法不收敛或者收敛得很慢。如何解决这种Large Discrete Action Spaces,即大规模离散动作空间得问题。
启发:
使用 k-nearest-neighbor mapping 可以将 DDPG中 policy network 输出的action 映射到K个相近的action,从而帮助收敛。
[1]G. Dulac-Arnold et al., ‘Deep Reinforcement Learning in Large Discrete Action Spaces’. arXiv, Apr. 04, 2016. Accessed: Dec. 27, 2023. [Online]. Available: http://arxiv.org/abs/1512.07679
code:(挖个坑,code下载下来run有问题,后续会补上部分code解析)
要解决的问题:
对于通用的RL的框架以及DDPG算法不再赘述。
对于RL中action space比较大/连续的情况,一般是采取DDPG或者PPO。
DDPG是输出的一个连续的值,即一个/组确定性的动作。因此,对于大规模离散动作空间,需要将DDPG输出的连续值 映射到 离散的动作。 即使使用DDPG,大规模问题还是很难收敛。
采取的方案:Wolpertinger Architecture
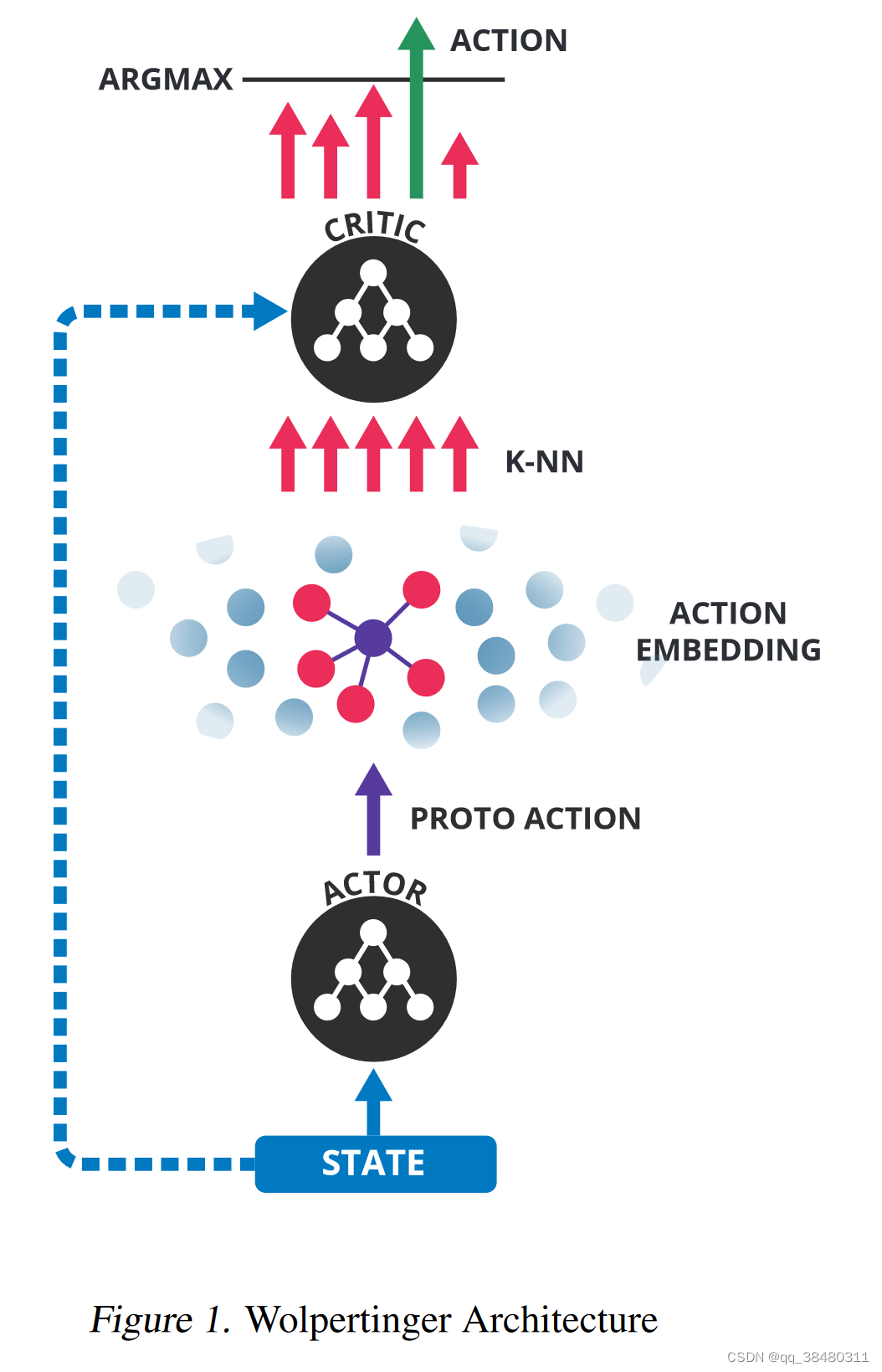

Wolpertinger Architecture 的核心是采用approximate nearest-neighbor methods 来泛化动作。
具体来说,正常的DDPG 在从policy network 得到输出动作之后,执行动作并转到下一个新的状态。 但是, 加入Wolpertinger policy之后,从policy network 输出的动作并不直接执行,而是先映射到 K 组动作
,再根据 critic network评价这K 组 action的Q值,选取Q值最大的action执行。
Action generation:
那么问题又来了?既然要 把 映射到 K组动作?怎么映射呢?


is a k-nearest-neighbor mapping from a continuous space to a discrete set. It returns the k actions in A that are closest to
by
distance.
Action refinement:
根据动作表示的结构化程度,即使在大部分动作具有高Q值的空间中,具有低Q值的动作也可能和距离很近。
算法的第二阶段,如图1的上半部分所述,通过根据Q选择得分最高的动作来细化动作的选择:

复杂度分析:随K线性增长。
Time-complexity of the above algorithm scales linearly in the number of selected actions, k.















 4170
4170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











